一
基础知识
◆Module:一个源代码文件被编译后生成的IR代码。
◆Function:源代码文件中的函数。
◆BasicBlock:BasicBlock有且仅有一个入口点和一个出口点。入口点是指BasicBlock的第一个指令,而出口点是指BasicBlock的最后一个指令。BasicBlock中的指令是连续执行的,没有分支或跳转指令直接将控制流传递到BasicBlock内部以外的位置。
◆Instruction:指令。
二
Substitution混淆源码解读
runOnFunction函数
bool Substitution::runOnFunction(Function &F) {
// 检查sub混淆次数
if (ObfTimes <= 0) {
errs()<<"Substitution application number -sub_loop=x must be x > 0";
return false;
}
Function *tmp = &F;
// 先通过toObfuscate函数检查是否需要进行混淆
if (toObfuscate(flag, tmp, "sub")) {
//混淆的具体操作
substitute(tmp);
return true;
}
return false;
}
Substitution混淆,混淆的具体操作主要通过调用substitute函数进行的。substitute函数
bool Substitution::substitute(Function *f) {
Function *tmp = f;
// 混淆次数
int times = ObfTimes;
do {
// 遍历函数中的基本块
for (Function::iterator bb = tmp->begin(); bb != tmp->end(); ++bb) {
// 遍历基本块中的每条指令
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst) {
// 判断指令是否是二进制运算
if (inst->isBinaryOp()) {
//获取指令的操作码进行case判断
switch (inst->getOpcode()) {
case BinaryOperator::Add:
// 随机选择add混淆中的一个方案
(this->*funcAdd[llvm::cryptoutils->get_range(NUMBER_ADD_SUBST)])(
cast<BinaryOperator>(inst));
++Add;
break;
case BinaryOperator::Sub:
// 随机选择sub混淆中的一个方案
(this->*funcSub[llvm::cryptoutils->get_range(NUMBER_SUB_SUBST)])(
cast<BinaryOperator>(inst));
++Sub;
break;
...
} // End switch
} // End isBinaryOp
} // End for basickblock
} // End for Function
} while (--times > 0); // for times
return false;
}
llvm::cryptoutils->get_range获取随机数来指定某种混淆操作。Substitution混淆的介绍。addNeg混淆函数
// Implementation of a = b - (-c)
void Substitution::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;
// Create sub
if (bo->getOpcode() == Instruction::Add) {
//创建一个取反指令,生成bo指令中第二个操作数的负数,插入到bo指令的前面,返回创建的指令
op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
//创建一个sub指令,第一个操作数是bo指令中的第一个操作数,第二个操作数是刚才生成的op,然后插入到bo指令的前面,返回创建的指令
op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
//用op指令来替换原来的bo指令
bo->replaceAllUsesWith(op);
}
}
//打印基本块中的指令
void printBasicBlockInfo(BasicBlock* bb){
for (BasicBlock::iterator inst = bb->begin(); inst != bb->end(); ++inst){
inst->print(errs());
errs() << "\n";
}
}void Substitution::addNeg(BinaryOperator *bo) {
BinaryOperator *op = NULL;if (bo->getOpcode() == Instruction::Add) {
//新增
//current instruction
errs() << "current BinaryOperator:";
bo->print(errs());
errs() << "\n";
//get BasicBlock that current instruction located
BasicBlock* bb = bo->getParent();
//print Instruction in BasicBlock before CreateNeg
errs() << "BasicBlock before CreateNeg: " << "\n";
printBasicBlockInfo(bb);op = BinaryOperator::CreateNeg(bo->getOperand(1), "", bo);
//新增
//print Instruction in BasicBlock after CreateNeg and before Create
errs() << "BasicBlock after CreateNeg and before Create: " << "\n";
printBasicBlockInfo(bb);op = BinaryOperator::Create(Instruction::Sub, bo->getOperand(0), op, "", bo);
//新增
//print Instruction in BasicBlock after Create and before replaceAllUsesWith
errs() << "BasicBlock after Create and before replaceAllUsesWith: " << "\n";
printBasicBlockInfo(bb);bo->replaceAllUsesWith(op);
//新增
//print Instruction in BasicBlock after replaceAllUsesWith
errs() << "BasicBlock after replaceAllUsesWith: " << "\n";
printBasicBlockInfo(bb);
}
}
current Function: main//混淆操作
current BinaryOperator: %7 = add nsw i32 %5, %6 //在substitute函数中被选中要进行sub混淆的指令
BasicBlock before CreateNeg:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = add nsw i32 %5, %6
store i32 %7, i32* %2, align 4
ret i32 0
BasicBlock after CreateNeg and before Create:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4 // a
store i32 1, i32* %3, align 4 // b
store i32 2, i32* %4, align 4 // c
%5 = load i32, i32* %3, align 4 // %5 = b
%6 = load i32, i32* %4, align 4 // %6 = c
%7 = sub i32 0, %6// CreateNeg新增指令,对源指令中第二个操作数(c)进行取反指令
%8 = add nsw i32 %5, %6 // 源指令,%7变成%8
store i32 %8, i32* %2, align 4 // %7变成%8
ret i32 0
BasicBlock after Create and before replaceAllUsesWith:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = sub i32 0, %6 // CreateNeg新增指令
%8 = sub i32 %5, %7 // Create新增指令,源指令中第一个操作数(b)与CreateNeg新增指令的结果相加
%9 = add nsw i32 %5, %6 // 源指令, %8变成%9
store i32 %9, i32* %2, align 4 // %8变成%9
ret i32 0
BasicBlock after replaceAllUsesWith:
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %3, align 4
store i32 2, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = sub i32 0, %6
%8 = sub i32 %5, %7
%9 = add nsw i32 %5, %6
store i32 %8, i32* %2, align 4 // 这里发生更改,原本存储%9 (b+c),先在存储%8 (b-(-c))
ret i32 0
Create***等指令创建函数会影响后面的IR代码,即后续代码会进行相应的调整以保证IR代码的正确性,至于其具体过程,本篇博客不进行介绍。replaceAllUsesWith函数并不是真正的将源指令替换或删除,仅仅只是让后续IR代码中对源指令的结果的引用转变成对新指令的结果的引用,也就是说,源指令对后续的操作无任何作用,这样之后的优化应该会删除这种无效IR代码(如果指定了优化等级的话)。三
SplitBasicBlocks源码解读
runOnFunction函数
bool SplitBasicBlock::runOnFunction(Function &F) {
// 基本块拆分次数要在(1,10]区间中
if (!((SplitNum > 1) && (SplitNum <= 10))) {
errs()<<"Split application basic block percentage -split_num=x must be 1 < x <= 10";
return false;
}Function *tmp = &F;
// 检查当前函数是否需要进行split操作
if (toObfuscate(flag, tmp, "split")) {
split(tmp);//进行split操作
++Split;
}return false;
}
split函数。split函数
void SplitBasicBlock::split(Function *f) {
std::vector<BasicBlock *> origBB;
int splitN = SplitNum;
// 保存函数中所有的基本块到vector中
for (Function::iterator I = f->begin(), IE = f->end(); I != IE; ++I) {
origBB.push_back(&*I);
}
// 遍历所有基本块
for (std::vector<BasicBlock *>::iterator I = origBB.begin(),IE = origBB.end();I != IE; ++I) {
BasicBlock *curr = *I;
// 指令数<2的基本块和存在phi的基本块不进行分割操作
if (curr->size() < 2 || containsPHI(curr)) {
continue;
}
// 调整分割次数,以防止分隔次数大于基本块中的指令次数
if ((size_t)splitN > curr->size()) {//这不应该还有等于嘛?
splitN = curr->size() - 1;
}
//以下是生成分割点的操作
// 存储分割点([1,size-1])到vector中
std::vector<int> test;
for (unsigned i = 1; i < curr->size(); ++i) {
test.push_back(i);
}
if (test.size() != 1) {
shuffle(test);// 搅乱指令vector中的顺序
std::sort(test.begin(), test.begin() + splitN);//对前splitN个进行排序(从小到大),以便按顺序分割而不会出错
}
// 以下是进行分割的操作
BasicBlock::iterator it = curr->begin();
BasicBlock *toSplit = curr;
int last = 0;
for (int i = 0; i < splitN; ++i) {//分割次数
//it调整到分割点处的指令
for (int j = 0; j < test[i] - last; ++j) {//为什么要这么麻烦???
++it;
}
last = test[i];//分割后,记录新块的起始点
//当前基本块的指令数 > 2 则进行基本块分割
if(toSplit->size() < 2)
continue;
toSplit = toSplit->splitBasicBlock(it, toSplit->getName() + ".split");
}
++Split;
}
}
PHI节点,则不进行基本块拆分,同时调整分割次数以防止分割次数大于基本块中的指令数。接下来就是生成分割点,具体操作为对1~size-1的有序vetor打乱顺序,然后对前splitN个进行从小到大的排序,这样做的目的一是随机分割,二是重排序以防止分割不会出错。最后,调整分割点,调用splitBasicBlock进行分割。PHI节点是什么。PHI节点
LLVM指令都以静态单一赋值(SSA)形式表示。从本质上讲,这意味着任何变量只能分配给一次。因此就存在如下情况的问题:a = 1;
if (v < 10)
a = 2;
b = a;
v的值小于10,变量a就会被赋值为2,但是a已经被赋值了一次,由于SSA性质的约束,不能继续给a赋值了。为了解决这一问题,LLVM中引入了PHI节点(PHI Node),用于处理基本块之间的分支和合并。当一个基本块有多个前驱基本块时,PHI节点可以用来表示从不同的前驱基本块中接收的值,这在处理分支和合并的情况下非常有用。a1 = 1;
if (v < 10)
a2 = 2;
b = PHI(a1, a2);
if分支里面的赋值被转换成另一个变量,b的赋值也就在两个变量之间选择,通过添加一个PHI Node,让它来决定选择哪个变量赋值给b。splitBasicBlock
BasicBlock *BasicBlock::splitBasicBlock(iterator I, const Twine &BBName) {
assert(getTerminator() && "Can't use splitBasicBlock on degenerate BB!");
assert(I != InstList.end() && "Trying to get me to create degenerate basic block!");
//创建一个新的基本块,并插入到当前基本块的后面
BasicBlock *New = BasicBlock::Create(getContext(), BBName, getParent(), this->getNextNode());// 保存分割点处的指令的调试信息
DebugLoc Loc = I->getDebugLoc();
// 将当前基本块的指令(从I到end())转移到新的基本块中
New->getInstList().splice(New->end(), this->getInstList(), I, end());// 在当前基本块的末尾添加分支指令,跳转到新建基本块中
BranchInst *BI = BranchInst::Create(New, this);
BI->setDebugLoc(Loc);// 遍历新建基本块的后继基本块,更新后继基本块中的PHI nodes的前驱基本块为新的基本块而非原来的基本块
for (succ_iterator I = succ_begin(New), E = succ_end(New); I != E; ++I) {
BasicBlock *Successor = *I;
PHINode *PN;
// 遍历后继基本块中的PHINode(转型后)
for (BasicBlock::iterator II = Successor->begin(); (PN = dyn_cast<PHINode>(II)); ++II) {
//循环替换PHINOde(前驱基本块为当前基本块)的前驱基本块为新的基本块
int IDX = PN->getBasicBlockIndex(this);//获取PHINode所在当前基本块的索引值
while (IDX != -1) {
PN->setIncomingBlock((unsigned)IDX, New);//设置PHINode的前驱基本块为新的基本块(对应索引值为IDX)
IDX = PN->getBasicBlockIndex(this);
}
}
}
return New;
}
I为分割点,所有在分割点之前的指令保留在原来的基本快中,分割点处的指令以及之后的指令保留到新的基本块中,并且在原来的基本块后面增加跳转到新的基本块的br指令。之后是修正新基本块的后继基本块(同样也是分割之前的基本块的后继基本块)中的PHINode,具体操作为替换PHINode的前驱基本块(即分割之前的基本块)为新的基本块。四
Flattening源码解读
flatten函数
runOnFunction函数没啥好看的,直接看重点:flatten函数,将该函数分为以下几块进行讲解。(这一部分的理解可以参考Obfuscator-llvm源码分析 - 知乎 (https://zhuanlan.zhihu.com/p/39479793)中的CFG图)// SCRAMBLERchar scrambling_key[16];llvm::cryptoutils->get_bytes(scrambling_key, 16);// END OF SCRAMBLER
LowerSwitchPass并执行该Pass。// Lower switchFunctionPass *lower = createLowerSwitchPass();lower->runOnFunction(*f);
f的所有基本块存放一份到向量origBB中,同时检查基本块中的终止指令,如果终止指令是Invoke指令,则对整个函数f不进行平坦化混淆。如果函数f的基本块数量<1也不进行平坦化混淆。最后是将函数f的第一个基本块从向量origBB中删除。// Save all original BBfor (Function::iterator i = f->begin(); i != f->end(); ++i) {BasicBlock *tmp = &*i;origBB.push_back(tmp);BasicBlock *bb = &*i;if (isa<InvokeInst>(bb->getTerminator())) {return false;}}// Nothing to flattenif (origBB.size() <= 1) {return false;}// Remove first BBorigBB.erase(origBB.begin());
接下来引入3个问题。
第一个问题:什么是Terminator?
在LLVM的IR中,每个基本块必须以Terminator指令结尾,它标志着基本块的结束,用于控制接下来代码流进入到哪一个基本块中。Terminator指令,它可以是分支指令(如BranchInst)、返回指令(如ReturnInst)或者抛出异常的指令(如InvokeInst)等。
第二个问题:什么是InvokeInst?
InvokeInst是一种特殊的调用指令,用于调用有异常处理的函数。与普通的CallInst不同,如果函数调用期间抛出异常,则控制流会转移到指定的异常处理代码中,而不是继续执行后续的指令。InvokeInst指令,这个指令有两个后继,但是一个是正常的基本块处,另一个是跳转到unwind相关的逻辑中(异常处理),这个unwind基本块的开头必须为LandingPadInst,且只能通过InvokeInst指令来到达。
第三个问题:为什么基本块中含有InvokeInst就对所在函数不进行平坦化处理?
由于unwind基本块只能通过InvokeInst指令来到达。所以当LandingPadInst被插入到SwitchInst中去的时候,由于不是通过InvokeInst到达的,所以会报错。然而对所在函数不进行平坦化,感觉应该不太妥,对于这部分的优化可以参考OLLVM控制流平坦化的改进 - 知乎 (zhihu.com)。
// 获取函数f中的第一个基本块Function::iterator tmp = f->begin(); //++tmp;BasicBlock *insert = &*tmp;// 如果函数f中的第一个基本块的末尾为分支指令BranchInst *br = NULL;if (isa<BranchInst>(insert->getTerminator())) {br = cast<BranchInst>(insert->getTerminator());}// 最后一条指令是条件分支指令 或者 有多个后继基本块if ((br != NULL && br->isConditional()) || insert->getTerminator()->getNumSuccessors() > 1) {//获取基本块中最后一个指令作为分割点(end()获取的是最后一个指令的下一个节点)BasicBlock::iterator i = insert->end();--i;//如果基本块中的指令 > 1,那么分割点为倒数第二条指令if (insert->size() > 1) {--i;}//以指令i为分割点分割基本块,并返回新的基本块,然后将新的基本块插入到origBB中的第一个基本块之前BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");origBB.insert(origBB.begin(), tmpBB);}// 删除函数f中的第一个基本块(也就是分割之后的旧的基本块)的终止指令(末尾)insert->getTerminator()->eraseFromParent();
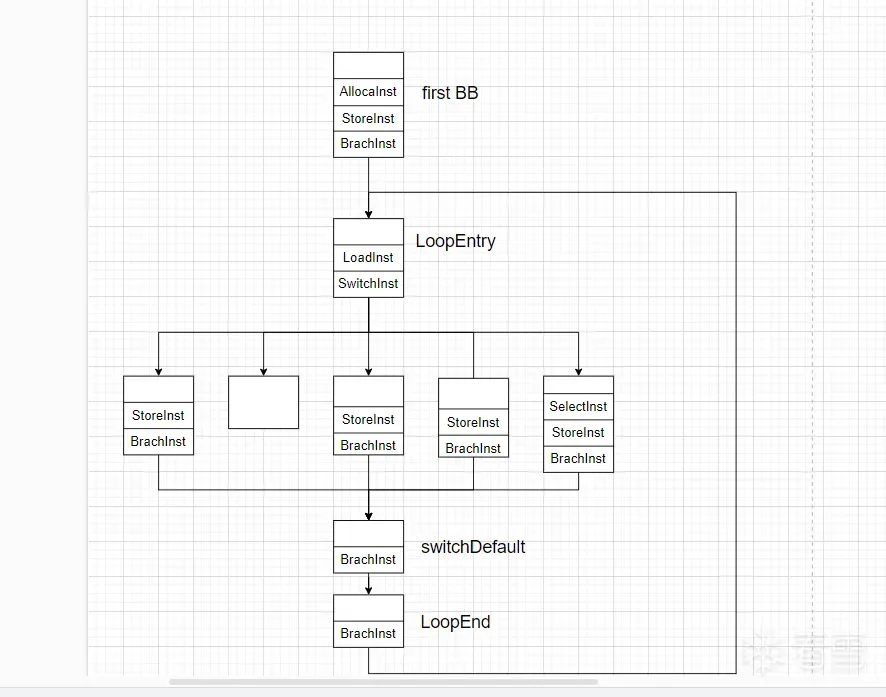
switch-case的框架,建立基本块之间的跳转连接。// Create switch variable and set as itswitchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);// Create main looploopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);load = new LoadInst(switchVar, "switchVar", loopEntry);// Move first BB on topinsert->moveBefore(loopEntry);// first BB jump to loopEntryBranchInst::Create(loopEntry, insert);// loopEnd jump to loopEntryBranchInst::Create(loopEntry, loopEnd);// create swDefault BBBasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);// swDefault jump to loopEndBranchInst::Create(loopEnd, swDefault);// Create switch instruction itself and set conditionswitchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);switchI->setCondition(load);// Remove branch jump from 1st BB and make a jump to the whilef->begin()->getTerminator()->eraseFromParent();BranchInst::Create(loopEntry, &*f->begin());
具体来说是,在函数f第一个基本块(拆分后)的末尾创建switchVar路由变量并赋予随机值。接着创建loopEntry、loopEnd、swDefault基本块。然后在loopEntry基本块的末尾加载switchVar路由变量,之后又在loopEntry基本块的末尾创建SwitchInst指令,设置默认分支为swDefault基本块,设置case分支数量为0,最后设置SwitchInst指令的路由变量为load指令加载的switchVar。其余的BranchInst则是建立基本块之间的跳转。
此时CFG图如下:
origBB中所有的基本块按照case索引值加入到switch-case分支中。// 遍历origBB的所有基本块for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end(); ++b) {BasicBlock *i = *b;ConstantInt *numCase = NULL;// 将基本块移动到loopEnd之前(位置意义上的,而非代码逻辑上的)i->moveBefore(loopEnd);// 生成numCase,并将基本块i加入到对应索引值的case分支处numCase = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)));switchI->addCase(numCase, i);}
看完整个Flattening源码后,我还在想源码中并没有通过设置switchVar来确保代码流在第一个基本块能够正确进入到原本的后续基本块中。后面我反复阅读源码后才发现,其实它们之间的跳转关系在这里就确定了!
注意看!!!初始switchVar的值为:
llvm::cryptoutils->scramble32(0, scrambling_key))llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)此时switchI->getNumCases()的值就是0,这么一来,初始switchVar的值恰好指向下一个正确的基本块。
此时CFG图如下:
switchVar(路由变量)的指令,使代码流能够进入正确的基本块中。//遍历origBB中的每个基本块for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end(); ++b) {BasicBlock *i = *b;ConstantInt *numCase = NULL;// return或exit基本块,不做处理if (i->getTerminator()->getNumSuccessors() == 0) {continue;}// 有一个后继基本块的基本块(以非条件跳转结尾的基本块)if (i->getTerminator()->getNumSuccessors() == 1) {//获取后继基本块,同时删除最后一条指令(跳转指令)BasicBlock *succ = i->getTerminator()->getSuccessor(0);i->getTerminator()->eraseFromParent();//找到后继基本块所在的case位置(是个索引值)numCase = switchI->findCaseDest(succ);//如果后继基本块是default基本块,则创建一个case索引值//不对呀,之前不是将所有的基本块都加入到case分支中嘛,怎么还会有numCase==Null的//就算是有后继基本块不在case中的,那也应该将它加入到case中,而这里没有,仅仅只是生成numCaseif (numCase == NULL) {numCase = cast<ConstantInt>( ConstantInt::get(switchI->getCondition()->getType(),llvm::cryptoutils->scramble32(->getNumCases() - 1, scrambling_key)));}//创建store指令,存储numCase到switchVar中,指令插入到基本块i中的最后面,这一步即更新switchVar的值new StoreInst(numCase, load->getPointerOperand(), i);BranchInst::Create(loopEnd, i);continue;}// 有两个后继基本块的基本块(以条件跳转结尾的基本块)if (i->getTerminator()->getNumSuccessors() == 2) {//获取这两个后继基本块ConstantInt *numCaseTrue = switchI->findCaseDest(i->getTerminator()->getSuccessor(0));ConstantInt *numCaseFalse = switchI->findCaseDest(i->getTerminator()->getSuccessor(1));// Check if next case == default case (switchDefault)if (numCaseTrue == NULL) {numCaseTrue = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),llvm::cryptoutils->scramble32(switchI->getNumCases() - 1, scrambling_key)));}if (numCaseFalse == NULL) {numCaseFalse = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),llvm::cryptoutils->scramble32(switchI->getNumCases() - 1, scrambling_key)));}// 获取基本块中的条件跳转指令,根据这个指令,创建Select指令,第一个参数是条件变量,// 第二个是条件为真的结果,第三个是条件为假的结果,并将指令插入到基本块i的条件跳转指令之前BranchInst *br = cast<BranchInst>(i->getTerminator());SelectInst *sel = SelectInst::Create(br->getCondition(), numCaseTrue, numCaseFalse, "", i->getTerminator());//删除基本块i的条件跳转指令i->getTerminator()->eraseFromParent();// 更新switchVar的值为sel,插入到基本块i中的末尾new StoreInst(sel, load->getPointerOperand(), i);BranchInst::Create(loopEnd, i);continue;}}
将基本块分为三种类型进行处理:
没有后续基本块的基本块:这种基本块通常以retn或者call exit结尾,统一称为Ret BB。对于这类基本块,不做处理。
有一个后续基本块的基本块:这种基本块以非条件跳转指令结尾。对于这类基本块,删除其与后续基本块的跳转关系,转而变成通过switch-case结构跳转,即通过store指令更新switchVar路由变量的值为后继基本块所在case的索引值,最后增加跳转到loopEnd基本块的指令。
有两个后续基本块的基本块:这种基本块以条件跳转指令结尾。对于这类基本块,删除其与后续基本块的跳转关系,转而变成通过switch-case结构跳转,即创建select指令,并通过store指令将select指令的结果作为新的switchVar路由变量的值,最后增加跳转到loopEnd基本块的指令。
此时CFG图如下:
fixStack(f);void fixStack(Function *f) {// Try to remove phi node and demote reg to stackstd::vector<PHINode *> tmpPhi;std::vector<Instruction *> tmpReg;BasicBlock *bbEntry = &*f->begin();do {tmpPhi.clear();tmpReg.clear();//遍历基本块for (Function::iterator i = f->begin(); i != f->end(); ++i) {//遍历基本块中的指令for (BasicBlock::iterator j = i->begin(); j != i->end(); ++j) {//如果该指令是PHI节点,则加入到tmpPhi中if (isa<PHINode>(j)) {PHINode *phi = cast<PHINode>(j);tmpPhi.push_back(phi);continue;}//指令不是位于入口基本块的alloca指令且该指令含有逃逸变量,加入到tmpReg中if (!(isa<AllocaInst>(j) && j->getParent() == bbEntry) &&(valueEscapes(&*j) || j->isUsedOutsideOfBlock(&*i))) {tmpReg.push_back(&*j);continue;}}}//对逃逸变量进行降级处理,从虚拟寄存器变量降级到堆栈上的局部变量for (unsigned int i = 0; i != tmpReg.size(); ++i) {DemoteRegToStack(*tmpReg.at(i), f->begin()->getTerminator());}//对phinode进行降级处理,从phinode降级为堆栈上的局部变量for (unsigned int i = 0; i != tmpPhi.size(); ++i) {DemotePHIToStack(tmpPhi.at(i), f->begin()->getTerminator());}} while (tmpReg.size() != 0 || tmpPhi.size() != 0);}
这个函数处理了两种类型的指令.
PHI 指令:
PHI 指令我们前面介绍过。因为PHI指令是基于前驱基本块的指令,前驱基本块被打乱了,PHI指令会出现错误,因此需要对PHI指令进行修复。
含有逃逸变量的指令:
逃逸变量指的是在当前基本块中被定义,在其他的基本块中被引用了的变量。这类逃逸变量在编译(LLVM IR->目标平台机器代码)时会出现分不清定义和引用顺序的问题,因此也需要进行修复。
DemoteRegToStack函数用于将存储指令结果值的虚拟寄存器替换为堆栈上的局部变量。具体而言,首先创建Alloca指令,插入到函数的入口基本块中,然后如果该指令是Invoke指令,则进行基本块分割,然后对于使用逃逸变量的基本块,采用Load指令从堆栈中加载变量的值,最后创建Store将逃逸变量的值存储到堆栈中。
DemotePHIToStack函数用于将存储PHI节点的结果值的虚拟寄存器替换为堆栈上的局部变量。具体而言是创建Alloca指令,插入到函数的入口基本块中,对于PHI节点的每一个前驱基本块,插入一个Store指令,将前驱基本块传递过来的值存储到堆栈中。之后在PHI节点所在的位置插入一个Load指令,将之前存储在堆栈中的值加载出来。
简而言之,DemotexxxToStack函数就是使用Alloca、Store、Load指令来代替这些需要待修复的指令。
五
BogusControlFlow源码解读
runOnFunction函数
runOnFunction函数入手看:virtual bool runOnFunction(Function &F){
// 混淆次数
if (ObfTimes <= 0) {
errs()<<"BogusControlFlow application number -bcf_loop=x must be x > 0";
return false;
}// 基本块的混淆概率
if ( !((ObfProbRate > 0) && (ObfProbRate <= 100)) ) {
errs()<<"BogusControlFlow application basic blocks percentage -bcf_prob=x must be 0 < x <= 100";
return false;
}
// If fla annotations
if(toObfuscate(flag,&F,"bcf")) {
bogus(F);
doF(*F.getParent());
return true;
}return false;
} // end of runOnFunction()
bogus函数进行虚假控制流混淆,然后调用doF函数替换在bogus函数中创建的永真条件跳转指令。我们先来看bogus函数然后再看doF函数。bogus函数
void bogus(Function &F) {
// For statistics and debug
++NumFunction;
int NumBasicBlocks = 0;
bool firstTime = true; // First time we do the loop in this function
bool hasBeenModified = false;
NumTimesOnFunctions = ObfTimes;
int NumObfTimes = ObfTimes;// 外面这个大循环是虚假控制流混淆次数
do{
// 将函数的所有基本块存储到basicBlocks中
std::list<BasicBlock *> basicBlocks;
for (Function::iterator i=F.begin();i!=F.end();++i) {
basicBlocks.push_back(&*i);
}while(!basicBlocks.empty()){
NumBasicBlocks ++;
// 基本块进行虚假控制流混淆的概率 <= ObfProbRate (也就是说在这区间内才进行混淆?)
if((int)llvm::cryptoutils->get_range(100) <= ObfProbRate){
hasBeenModified = true;
++NumModifiedBasicBlocks;
NumAddedBasicBlocks += 3;
FinalNumBasicBlocks += 3;
// Add bogus flow to the given Basic Block (see description)
BasicBlock *basicBlock = basicBlocks.front();//后面有basicBlocks.pop_front(),所以在循环中,这里是依次获取basicBlock中的所有基本块
addBogusFlow(basicBlock, F);
}
// remove the block from the list
basicBlocks.pop_front();if(firstTime){ // first time we iterate on this function
++InitNumBasicBlocks;
++FinalNumBasicBlocks;
}
} // end of while(!basicBlocks.empty())
firstTime = false;
}while(--NumObfTimes > 0);
}
while循环是循环虚假控制流混淆次数,对于每次混淆,先将函数的所有基本块加入到basicBlocks中,然后内层while循环遍历每个基本块,生成对应的混淆概率,如果满足预设混淆概率,就调用addBogusFlow函数进行混淆。addBogusFlow函数
originalBB。// 获取basicblock中第一个不是Phi、Dbg、Lifetime的指令
BasicBlock::iterator i1 = basicBlock->begin();
if(basicBlock->getFirstNonPHIOrDbgOrLifetime())
i1 = (BasicBlock::iterator)basicBlock->getFirstNonPHIOrDbgOrLifetime();
//分割基本块,新的基本块的名称为originalBB
Twine *var;
var = new Twine("originalBB");
BasicBlock *originalBB = basicBlock->splitBasicBlock(i1, *var);
CFG的情况如下:createAlteredBasicBlock函数(这个函数主要是根据传入的基本块fork出新的基本块,然后进行修正和垃圾指令填充)创建一个名为alteredBB基本块,删除alteredBB和basicBlock末尾的分支指令。// 创建一个名为alteredBB基本块
Twine * var3 = new Twine("alteredBB");
BasicBlock *alteredBB = createAlteredBasicBlock(originalBB, *var3, &F);
//删除alteredBB、basicBlock末尾的跳转指令
alteredBB->getTerminator()->eraseFromParent();
basicBlock->getTerminator()->eraseFromParent();
CFG的情况如下:Fcmp指令(因为1.0 == 1.0),并以该指令为条件码创建条件跳转指令,都插入到basicBlock的末尾,如果为True,跳转到originalBB,否则跳转到alteredBB。之后创建从alteredBB跳转到originalBB的跳转指令。// 创建两个值用于后续的比较指令,这两个值在doF函数中会变得复杂
Value * LHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);
Value * RHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);// 创建一个永真的FCmp指令,插入到basicBlock中的末尾,比较符左边的操作数为LHS,右边的为RHS
Twine * var4 = new Twine("condition");
FCmpInst * condition = new FCmpInst(*basicBlock, FCmpInst::FCMP_TRUE , LHS, RHS, *var4);// 创建跳转分支,插入到basicBlock的末尾。第一个参数为True跳转的基本块,第二个为false跳转的基本块,条件码为condition
BranchInst::Create(originalBB, alteredBB, (Value *)condition, basicBlock);// 创建从alteredBB跳转到originalBB的分支指令
BranchInst::Create(originalBB, alteredBB);
CFG的情况如下:originalBB的末尾跳转指令分割originalBB,新的基本块名为originalBBpart2,删除originalBB末尾的跳转指令(跳转到originalBBpart2),然后创建一个永真的Fcmp指令,并以该指令为条件码创建条件跳转指令,都插入到originalBB的末尾,如果为True,跳转到originalBBpart2,否则跳转到alteredBB。// 以originalBB的末尾跳转指令分割originalBB,新的基本块名为originalBBpart2
BasicBlock::iterator i = originalBB->end();
Twine * var5 = new Twine("originalBBpart2");
BasicBlock * originalBBpart2 = originalBB->splitBasicBlock(--i , *var5);
// 删除originalBB末尾的跳转指令(跳转到originalBBpart2)
originalBB->getTerminator()->eraseFromParent();
// 创建永真的Cmp指令,插入到originalBB的末尾
Twine * var6 = new Twine("condition2");
FCmpInst * condition2 = new FCmpInst(*originalBB, CmpInst::FCMP_TRUE , LHS, RHS, *var6);
// 创建跳转分支,插入到originalBB的末尾,cmp为True跳转到originalBBpart2,为false跳转到alteredBB,条件码为condition
BranchInst::Create(originalBBpart2, alteredBB, (Value *)condition2, originalBB);
CFG的情况如下:createAlteredBasicBlock函数
CloneBasicBlock函数从basicBlock中克隆alteredBB,这个basicBlock是待混淆的基本块通过splitBasicBlock函数分割出来的新的基本块。// Useful to remap the informations concerning instructions.
ValueToValueMapTy VMap;
BasicBlock * alteredBB = llvm::CloneBasicBlock (basicBlock, VMap, Name, F);
alteredBB,主要是重映射指令中的操作数和PHINode的前驱基本块。BasicBlock::iterator ji = basicBlock->begin();//基本块中的第一条指令
for (BasicBlock::iterator i = alteredBB->begin(), e = alteredBB->end() ; i != e; ++i){//遍历基本块中的指令
// 遍历指令中的操作数
for(User::op_iterator opi = i->op_begin (), ope = i->op_end(); opi != ope; ++opi){
// 通过VMap映射表得到操作数的值,值不为0,则进行重映射
Value *v = MapValue(*opi, VMap, RF_None, 0);
if (v != 0){
*opi = v;
}
}
// 恢复phi node的前驱基本块
if (PHINode *pn = dyn_cast<PHINode>(i)) {
for (unsigned j = 0, e = pn->getNumIncomingValues(); j != e; ++j) {
Value *v = MapValue(pn->getIncomingBlock(j), VMap, RF_None, 0);
if (v != 0){
pn->setIncomingBlock(j, cast<BasicBlock>(v));
}
}
}
// 恢复当前指令的metadata和DebugLoc
SmallVector<std::pair<unsigned, MDNode *>, 4> MDs;
i->getAllMetadata(MDs);
i->setDebugLoc(ji->getDebugLoc());
ji++;
} // The instructions' informations are now all correct
alteredBB中添加垃圾指令。// 遍历基本块中的指令
for (BasicBlock::iterator i = alteredBB->begin(), e = alteredBB->end() ; i != e; ++i){
// 如果指令是运算指令,进行垃圾指令添加
if(i->isBinaryOp()){
unsigned opcode = i->getOpcode();//获取运算符
BinaryOperator *op, *op1 = NULL;
Twine *var = new Twine("_");
// 整型运算符:Add、Sub、Mul、UDiv、SDiv、URem、SRem、Shl、LShr、AShr、And、Or、Xor
if(opcode == ...){
//随机次数、随机选择创建某种垃圾指令添加到当前指令之前或不操作
for(int random = (int)llvm::cryptoutils->get_range(10); random < 10; ++random){
switch(llvm::cryptoutils->get_range(4)){
case 0: //do nothing
break;
case 1:
op = BinaryOperator::CreateNeg(i->getOperand(0),*var,&*i);
op1 = BinaryOperator::Create(Instruction::Add,op, i->getOperand(1),"gen",&*i);
break;
case 2:
op1 = BinaryOperator::Create(Instruction::Sub, i->getOperand(0), i->getOperand(1),*var,&*i);
op = BinaryOperator::Create(Instruction::Mul,op1, i->getOperand(1),"gen",&*i);
break;
case 3:
op = BinaryOperator::Create(Instruction::Shl, i->getOperand(0), i->getOperand(1),*var,&*i);
break;
}
}
}
// 如果是浮点数运算符:FAdd、FSub、FMul、FDiv、FRem
if(opcode == ...){
...
}
// 如果是比较运算符ICmp(整型)
if(opcode == Instruction::ICmp){ // Condition (with int)
ICmpInst *currentI = (ICmpInst*)(&i);
switch(llvm::cryptoutils->get_range(3)){
case 0:
break;
case 1:
currentI->swapOperands();//交换比较运算符的两个操作数
break;
case 2:
switch(llvm::cryptoutils->get_range(10)){
case 0:
currentI->setPredicate(ICmpInst::ICMP_EQ);//修改指令的条件码
break; // equal
case 1:
currentI->setPredicate(ICmpInst::ICMP_NE);
break; // not equal
case 2:
currentI->setPredicate(ICmpInst::ICMP_UGT);
break; // unsigned greater than
case 3:
currentI->setPredicate(ICmpInst::ICMP_UGE);
break; // unsigned greater or equal
case 4:
currentI->setPredicate(ICmpInst::ICMP_ULT);
break; // unsigned less than
case 5:
currentI->setPredicate(ICmpInst::ICMP_ULE);
break; // unsigned less or equal
case 6:
currentI->setPredicate(ICmpInst::ICMP_SGT);
break; // signed greater than
case 7:
currentI->setPredicate(ICmpInst::ICMP_SGE);
break; // signed greater or equal
case 8:
currentI->setPredicate(ICmpInst::ICMP_SLT);
break; // signed less than
case 9:
currentI->setPredicate(ICmpInst::ICMP_SLE);
break; // signed less or equal
}
break;
}}
// 如果是比较运算符ICmp(浮点型)
if(opcode == Instruction::FCmp){ // Conditions (with float)
...
}
}
}
return alteredBB;
doF函数
x,y,初始值为0。// 创建两个全局变量x,y初始值为0
Twine * varX = new Twine("x");
Twine * varY = new Twine("y");
Value * x1 =ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
Value * y1 =ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
GlobalVariable * x = new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant * )x1,
*varX);
GlobalVariable * y = new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant * )y1,
*varY);
toEdit中,以及将对应的永真比较指令加入到toDelete中。std::vector<Instruction*> toEdit, toDelete;
BinaryOperator *op,*op1 = NULL;
LoadInst * opX , * opY;
ICmpInst * condition, * condition2;
// Looking for the conditions and branches to transform
for(Module::iterator mi = M.begin(), me = M.end(); mi != me; ++mi){//遍历模块中的函数
for(Function::iterator fi = mi->begin(), fe = mi->end(); fi != fe; ++fi){//遍历函数中的基本块
TerminatorInst * tbb= fi->getTerminator();//获取基本块中的终止符
if(tbb->getOpcode() == Instruction::Br){//如果是分支指令
BranchInst * br = (BranchInst *)(tbb);
if(br->isConditional()){//如果是条件分支指令
FCmpInst * cond = (FCmpInst *)br->getCondition();//获取分支条件部分,转成FCmp指令
unsigned opcode = cond->getOpcode();//获取FCmp指令的操作符
if(opcode == Instruction::FCmp){//如果是FCmp指令
if (cond->getPredicate() == FCmpInst::FCMP_TRUE){//如果是永真
toDelete.push_back(cond); // The condition
toEdit.push_back(tbb); // The branch using the condition
}
}
}
}
}
}
toEdit中存放的永真条件跳转指令,创建条件码x*(x-1)%2 == 0 || y < 10,以该条件码创建条件跳转分支,然后删除之前的永真条件跳转指令。最后删除toDelete中存放的永真比较指令。// 遍历toEdit中存放的永真条件跳转指令
for(std::vector<Instruction*>::iterator i =toEdit.begin();i!=toEdit.end();++i){
//if y < 10 || x*(x+1) % 2 == 0
opX = new LoadInst ((Value *)x, "", (*i));
opY = new LoadInst ((Value *)y, "", (*i));
//x - 1
op = BinaryOperator::Create(Instruction::Sub, (Value *)opX,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 1,
false), "", (*i));
// x*(x-1)
op1 = BinaryOperator::Create(Instruction::Mul, (Value *)opX, op, "", (*i));
// x*(x-1)%2
op = BinaryOperator::Create(Instruction::URem, op1,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 2,
false), "", (*i));
//创建条件码为 x*(x-1)%2 == 0
condition = new ICmpInst((*i), ICmpInst::ICMP_EQ, op,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false));
//创建条件码为 y < 10
condition2 = new ICmpInst((*i), ICmpInst::ICMP_SLT, opY,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 10, false));
// x*(x-1)%2 == 0 || y < 10
op1 = BinaryOperator::Create(Instruction::Or, (Value *)condition, (Value *)condition2, "", (*i));
// 创建条件跳转指令,ture进入第0个后继基本块,false进入第1个后继基本块,条件码为op1,即x*(x-1)%2 == 0 || y < 10
BranchInst::Create(((BranchInst*)*i)->getSuccessor(0),
((BranchInst*)*i)->getSuccessor(1),(Value *) op1,
((BranchInst*)*i)->getParent());
(*i)->eraseFromParent(); // 删除之前的永真条件分支
}
// 删除之前存储的Fcmp指令
for(std::vector<Instruction*>::iterator i =toDelete.begin();i!=toDelete.end();++i){
(*i)->eraseFromParent();
}
return true;
看雪ID:gal2xy
https://bbs.kanxue.com/user-home-985561.htm
# 往期推荐
2、BFS Ekoparty 2022 Linux Kernel Exploitation Challenge
3、银狐样本分析
球分享
球点赞
球在看
点击阅读原文查看更多
如有侵权请联系:admin#unsafe.sh