In web development, scraping dynamic websites has become both an art and a science. With tools like Puppeteer, Playwright, and Selenium, developers have powerful options at their disposal. But with great power comes great complexity. In a recent webinar, scraping veterans Dario Kondratiuk, Diego Molina, and Greg Gorlen shared pro tips to navigate this landscape. Whether you’re dealing with Single Page Applications (SPAs) or dodging anti-bot measures, here’s how to level up your scraping game.
Choosing Reliable Selectors
During the webinar, Dario Kondratiuk emphasized the significance of using robust selectors in web scraping. Fragile, deeply nested selectors often lead to maintenance headaches. Instead, Dario recommended using ARIA labels and text-based selectors, which are more resilient to changes.
For example:
javascriptCopy code// Using Playwright for ARIA and text selectors
await page.locator('text="Login"').click();
await page.locator('[aria-label="Submit"]').click();
This approach ensures that even if the underlying HTML changes, your scripts remain functional. As Dario pointed out, “Reliable selectors minimize maintenance and reduce script failures.”
Embrace API Interception
In the webinar, Greg Gorlen emphasized the power of API interception for more efficient data extraction. By targeting API calls instead of scraping the DOM, developers can directly access structured data in JSON format, bypassing the complexities of dynamically loaded content.
Why API Interception?
-
Speed: Accessing JSON data is generally faster than parsing HTML.
-
Reliability: JSON structures are less prone to changes compared to the DOM.
Greg shared an example using Playwright to intercept API responses:
javascriptCopy code// Using Playwright to intercept API responses
await page.route('**/api/data', route => {
route.continue(response => {
const data = response.json();
console.log(data); // Process or save the data
});
});
In this example, the script intercepts calls to a specific API endpoint, allowing developers to work with clean, structured data directly.
Practical Tip: Always check the network tab in your browser’s developer tools. Look for API calls that return the data you need. If available, this method can greatly simplify your scraping process.
“Intercepting APIs not only speeds up data extraction but also enhances reliability. Look for JSON endpoints—they often contain the data you want in a much more usable format.”
Handling Lazy Loading
Lazy loading, a common technique for optimizing web performance, can complicate scraping efforts. Content only loads when the user interacts with the page, such as scrolling or clicking. During the webinar, Dario Kondratiuk provided effective strategies to tackle this challenge.
Key Approaches:
-
Simulated Scrolling: Simulating user scrolls can trigger the loading of additional content. This is crucial for sites where content appears as the user scrolls down.
javascriptCopy code// Simulate scrolling with Playwright await page.evaluate(async () => { await new Promise(resolve => { let totalHeight = 0; const distance = 100; const timer = setInterval(() => { window.scrollBy(0, distance); totalHeight += distance; if (totalHeight >= document.body.scrollHeight) { clearInterval(timer); resolve(); } }, 100); // Adjust delay as necessary }); });Why It Works: This method mimics natural user behavior, allowing all lazily loaded content to render. Adjusting the scroll distance and delay helps control the speed and completeness of loading.
-
Request Interception: By intercepting API calls, you can directly access the data without relying on the visual rendering of content. This approach can significantly enhance the speed and reliability of data extraction.
javascriptCopy code// Intercepting API requests in Playwright await page.route('**/api/data', route => { route.continue(response => { const data = response.json(); console.log(data); // Process data as needed }); });Advantages:
- Speed: Directly retrieves data, bypassing the need for multiple page loads.
- Efficiency: Captures all relevant data without needing to render the entire page visually.
-
Element Visibility Checks: Dario suggested validating the visibility of specific elements to ensure the required content has loaded. This can be combined with scrolling to provide a comprehensive scraping strategy.
javascriptCopy code// Wait for specific elements to load await page.waitForSelector('.item-loaded', { timeout: 5000 });
Why These Techniques Matter: Lazy loading can make scraping challenging by hiding data until user interaction. Simulating interactions and intercepting requests allows developers to ensure that all necessary content is available for scraping.
Dario emphasized, “Capturing data in chunks not only helps manage infinite scrolling but also ensures that no content is missed.” By applying these methods, developers can effectively gather data from even the most dynamic websites.

Accessing Data within Shadow DOM
Shadow DOM components encapsulate parts of the website, making data extraction more complex. During the webinar, Dario Kondratiuk shared effective techniques for scraping within Shadow DOM elements.
Approaches:
-
Utilize Built-in Tools: Tools like Playwright and Puppeteer allow developers to pierce the Shadow DOM, enabling access to otherwise hidden elements.
javascriptCopy code// Accessing elements within Shadow DOM using Playwright const shadowHost = await page.locator('#shadow-host'); const shadowRoot = await shadowHost.evaluateHandle(node => node.shadowRoot); const shadowElement = await shadowRoot.$('css-selector-within-shadow'); -
Handling Open vs. Closed Shadow DOM:
- Open Shadow DOM: Easily accessible via JavaScript, allowing for straightforward data extraction.
- Closed Shadow DOM: More challenging, as it restricts direct access. Workarounds may include using specific browser tools or JavaScript injection.
Why It Matters: Understanding the structure of Shadow DOMs is crucial. As Dario noted, "Treat Shadow DOMs like iframes; navigate through shadow roots just as you would with iframe documents."
By leveraging these techniques, developers can effectively extract data from encapsulated elements, ensuring comprehensive scraping.
Capturing Full Page Screenshots
Capturing screenshots of dynamic content can be tricky, especially when the content doesn’t fit within a single viewport. Diego Molina shared strategies for taking accurate full-page screenshots.
Techniques:
-
Using Browser Capabilities:
- Firefox: Built-in support for full-page screenshots makes capturing entire pages straightforward.
javascriptCopy code// Full-page screenshot in Playwright with Firefox await page.screenshot({ path: 'fullpage.png', fullPage: true }); -
Chrome DevTools Protocol (CDP):
- Utilize CDP for capturing screenshots in Chrome, allowing more control over the screenshot process.
javascriptCopy code// Using CDP with Puppeteer for full-page screenshots const client = await page.target().createCDPSession(); await client.send('Page.captureScreenshot', { format: 'png', full: true }); -
Waiting for Content to Load: Diego emphasized the importance of waiting for specific elements to ensure that all dynamic content is fully loaded before capturing.
javascriptCopy code// Wait for content to load await page.waitForSelector('.content-loaded'); await page.screenshot({ path: 'dynamic-content.png', fullPage: true });
Why It Matters: Capturing comprehensive screenshots is crucial for debugging and record-keeping. Diego advised, “Always ensure that all elements, fonts, and images are fully loaded before taking screenshots to avoid missing content.”
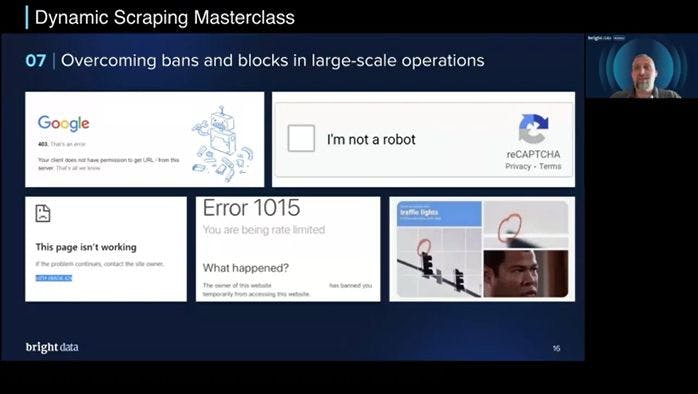
Bypassing Anti-Bot Measures
When scaling web scraping efforts, developers often encounter sophisticated anti-bot technologies designed to prevent automated data extraction. Jakub shared practical strategies to overcome these challenges:

-
Session Management: Utilizing tools like Bright Data's Scraping Browser can significantly simplify session management. This product manages cookies and sessions automatically, mimicking human-like browsing patterns to reduce the likelihood of being flagged.
-
IP Rotation: Implementing IP rotation is crucial for large-scale scraping. Services like Bright Data offer extensive proxy networks, enabling you to rotate IP addresses and simulate requests from various geographic locations. This helps avoid triggering anti-bot defenses that monitor repeated requests from single IPs.
-
Fingerprinting Techniques: Tools like Puppeteer Extra and Playwright Stealth can modify browser fingerprints to bypass detection. By altering elements like user agents, screen dimensions, and device types, these tools help scripts appear more like legitimate users.
-
Human-like Interaction: Selenium, Playwright, and Puppeteer provide platforms that allow for human-like interactions, such as realistic mouse movements and typing simulations. This can further reduce the likelihood of triggering anti-bot mechanisms.
Why It Matters: Navigating anti-bot measures is crucial for successful large-scale scraping. Jakub emphasized the importance of focusing on writing efficient scripts while leveraging tools that manage the complexities of session management, IP rotation, and fingerprinting.

Implementing these strategies and utilizing specialized tools, developers can effectively scale their scraping operations and minimize the risk of detection and blocking.
Q&A Insights: Expert Responses to Common Challenges
During the webinar's Q&A session, the panelists addressed several common challenges faced by developers in web scraping:
-
Intercepting Frontend API Calls: The panel emphasized using tools like Puppeteer and Playwright to intercept API calls directly. By monitoring network requests in the browser's developer tools, developers can identify and target the specific API endpoints that return the desired data, bypassing complex DOM structures.
-
Managing Basic Authentication: For handling basic authentication, it's crucial to automate the process using built-in functionalities in scraping tools. This ensures smooth access to data without manual intervention each time.
-
Writing Robust XPath Selectors: The consensus was clear: avoid XPath whenever possible. Instead, leverage the robust locator options provided by tools like Playwright, which offer various selectors such as text-based and ARIA role selectors, ensuring more resilient scraping scripts.
-
Standardizing Data Extraction: While a universal standard for bundling complete HTML doesn’t exist yet, developers can use tools like Mozilla Readability to simplify content extraction by converting pages into a more structured format, enhancing data accessibility.
-
Lazy Loading without User Interactions: The experts recommended using simulated scrolling or intercepting network requests to ensure all content loads without manual user interactions. This approach enables comprehensive data extraction even on complex, lazy-loaded pages.
-
Capturing Screenshots of Dynamic Content: When dealing with dynamic content, it’s essential to wait for all elements to load fully before capturing screenshots. Tools like Firefox’s native screenshot capabilities or using the Chrome DevTools Protocol (CDP) can facilitate accurate full-page captures.
-
Handling Dynamic Classes: To manage frequent changes in dynamic classes, the panel suggested focusing on relative selectors and data attributes. These elements are generally more stable and less likely to change, reducing the need for constant script adjustments.
Key Takeaways from the Webinar
The webinar provided a treasure trove of insights into mastering dynamic web scraping. With the expert guidance, developers gained valuable strategies for tackling complex challenges in web scraping.
What We Learned:
- Robust Selectors: Opt for ARIA labels and text-based selectors to create resilient scraping scripts.
- API Interception: Target API endpoints for faster, more reliable data extraction.
- SPA Management: Utilize event-driven predicates to handle dynamically loaded content in SPAs.
- Lazy Loading: Simulate user interactions or intercept network requests to ensure comprehensive data scraping.
- Shadow DOM: Access encapsulated elements effectively using the right tools and techniques.
- Anti-Bot Measures: Employ session management, IP rotation, and fingerprinting tools to scale scraping efforts while avoiding detection.
- Dynamic Classes: Focus on stable attributes and data attributes to maintain scraper robustness.
The panelists’ practical tips and shared experiences provided a solid foundation for developers to refine their web scraping techniques. By implementing these strategies, you can enhance your scraping capabilities, reduce maintenance efforts, and ensure successful data extraction across various website architectures.
Overall, the webinar was an invaluable resource, offering expert perspectives and actionable solutions to common scraping challenges. Whether you’re a seasoned developer or just starting out, these insights are sure to elevate your web scraping endeavors.
如有侵权请联系:admin#unsafe.sh