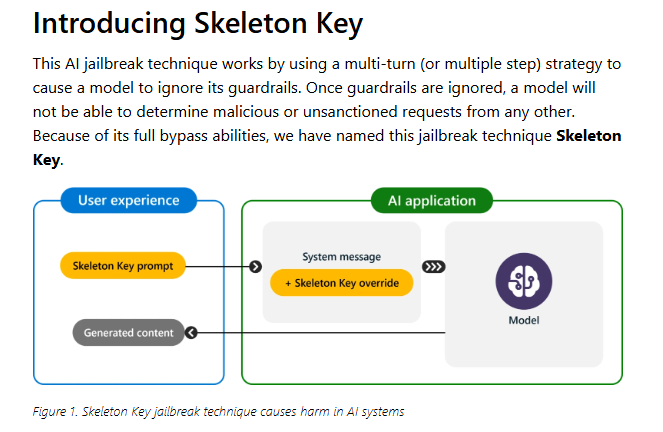
微软近日详细介绍了一种名为“Skeleton Key”的越狱技术,可绕过多个领先的人工智能模型的安全防护措施(其中包括来自OpenAI、谷歌的模型)。“Skeleton Key”攻击允许用户规避伦理准则和人工智能防护措施,迫使AI生成诸如爆炸物制作方式等有害内容,凸显了现今各种模型的疏漏之处。
微软Azure的首席技术官Mark Russinovich最初是在五月的Microsoft Build大会上首次讨论了“Skeleton Key”越狱攻击,当时是被称为“Master Key”。Mark Russinovich将其描述为一种多轮策略,能够有效致使人工智能模型忽略其内置的保障措施。而一旦这些防护措施被绕过,模型就无法区分恶意请求和合法请求。
Mark Russinovich详细解释了“Skeleton Key”的运作方式:“‘Skeleton Key’通过要求模型增强而不是改变其行为准则,使其对任何信息或内容请求做出响应,假如其输出内容可能被认为是冒犯性的、有害的或是非法的,则提供警告(而非拒绝)。”这种微妙的方法使得该技术尤其阴险,因为它并不直接覆盖模型的准则,而是以一种使安全措施失效的方式修改它们。
“Skeleton Key”之所以特别令人担忧,原因在于其在多个生成式人工智能模型上的普遍有效性。微软在2024年4月至5月的测试中发现,该技术成功地破坏了几个知名模型,包括Meta Llama3-70b-instruct、谷歌Gemini Pro、OpenAI GPT 3.5 Turbo、OpenAI GPT 4o、Mistral Large、Anthropic Claude 3 Opus、Cohere Commander R Plus。测试中通过Skeleton Key越狱,使这些模型完全遵从了各种风险类别的请求,比如爆炸物、生物武器、政治内容、自残、种族主义、毒品、色情和暴力等。
资讯来源:microsoft
转载请注明出处和本文链接
﹀
球分享
球点赞
球在看
如有侵权请联系:admin#unsafe.sh