一. 引言
目前,网络流量多采用TLS协议进行加密数据传输,使用深度学习技术进行流量分类愈发成熟,通过自动提取流量特征,较好地实现分类。但是现有的模型通常在单一、静态的训练环境中表现优异,而一旦在不同的网络环境下分类性能便显著降低。其原因在于网络环境的多样性和动态变化导致TLS流量的包长度序列发生显著变化,使得模型难以稳定提取有效特征。
本文介绍一篇来自USENIX Security ’23的文章《Rosetta: Enabling Robust TLS Encrypted Traffic Classification in Diverse Network Environments with TCP-Aware Traffic Augmentation》[1],解决现有深度学习模型进行TLS加密流量时因环境改变而模型失效的问题。它利用TCP感知的流量增强机制和自监督学习来理解隐含的TCP语义,从而提取TLS流的鲁棒特征,最终在不同的网络环境中可以达到相似的流量分类效果。
二. 现有DL模型问题分析
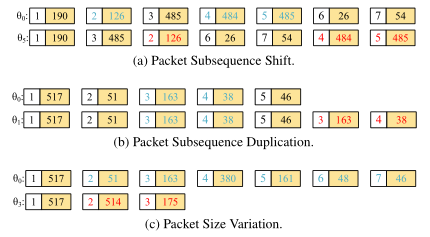
因网络环境的变化,深度学习模型无法理解不同环境下的两种不同数据包长度序列可能源自于同一条流。通常,在不同的网络环境下TCP机制可能会导致数据包长度序列的三种变化,即数据包子序列移位、数据包子序列重复和数据包大小变化,如图1。
图1 三类数据包长度变化
Rosetta模型的设计,能够意识到这些有规则的数据包序列变化与TCP语义关系,因此达到不同的网络环境中实现TLS流分类的效果。
三. Rosetta
3.1
总体框架
Rosetta,主要思想是从流量中学习隐式TCP语义,并生成有效的特征向量,表示不同网络环境中TLS流的鲁棒特征。
主要包括两个核心模块:TCP感知的流量增强(TCP-Aware Traffic Augmentation)和流量不变性提取器(Traffic Invariant Extractor,TIE)。如图2,显示了集成后的工作流程Rosetta。
图2 Rosetta系统框架图
3.2
TCP感知流量增强模块
Rosetta通过模拟不同网络环境下的TCP机制变化,生成大量具有代表性的流量变种,覆盖以下三种主要类型的变化:
1、分组子序列重复增强:
报文子序列重复通常在丢包场景下出现,这时TCP使用RTO(重传超时)机制和快速重传机制来处理。但两种机制对包长度的影响不同,因此分别设计了流量增强算法。
通过模拟具有丢包率的RTO和快速重传机制产生包子序列重复数据。通过设置不同的丢包率,分别输出大量包长度序列。
2、分组子序列移位增强
RTO和快速重传机制同样会导致分组子序列移位,设计了两种分组子序列移位增强算法,分别采用RTO和快速重传机制,产生大量TCP流的包长度序列的包子序列移位。
3、数据包大小变化增强
TCP端点与MTU(最大传输单元)之间的延迟会导致不同网络环境下TLS流的数据包大小发生变化。具体说,对于给定的RTT(往返时延)和MSS(最大报文段长度),在RTT期间发送的所有数据段将被缓冲在TCP堆栈中,直到发送方收到来自接收方的ACK数据包或TCP堆栈的大小大于MSS。
通过模拟具有MSS和RTT分布的可能的TCP传输,设计数据包大小变化增强算法。通过设置不同的MSS值和RTT分布,生成包含数据包大小变化的海量TCP流数据包长度序列。
3.3
流量不变性提取模块
流量不变性提取器模块从流的分组长度序列中提取鲁棒特征。它使用自监督学习技术,将流变体投射到一个隐藏空间中,使得同一流的流变体特征向量之间的距离尽可能小。
具体来说,流量不变性提取器通过以下步骤工作:
• 首先,它接收增强的流变体,并将它们输入到一个自监督学习模型中。自监督学习模型可以是现有的深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。
• 然后,自监督学习模型将流变体投射到一个隐藏空间中,生成特征向量。通过优化损失函数,使得同一流的流变体特征向量之间的距离尽可能小,不同流的特征向量之间的距离尽可能大。
• 最终,流量不变性提取器生成鲁棒特征向量,这些特征向量可以用于流量分类模型,实现鲁棒的TLS加密流量分类。
四. 实验评估
为了评估Rosetta的性能,研究团队在多个真实网络环境下进行了大量实验,包括使用不同的包丢失率、延迟和MTU设置来测试模型的分类性能和鲁棒性。
4.1
数据集和实验设置
实验使用了CIRA-CIC-DoHBrw-2020和ISCX-VPN的TLS加密流量数据集,且没有将任何关于流量分类数据集的先验知识馈送给Rosetta。通过在不同网络环境下重放这些流量,评估模型的分类性能。
4.2
鲁棒性评估
为了评估分类的鲁棒性,研究团队在不同的网络环境下设置了不同的包丢失率、延迟和MTU,并评估了DF模型在这些环境下的性能。
1、设置不同的包丢失率
图3显示了使用和不使用Rosetta时DF的性能,虽然单独使用DF可以在随着包丢失率的增加,丢包率较低的情况下达到99%以上的准确率,但当丢包率增加时,准确率会迅速下降。当丢包率增加到10%时,DF只能达到78%的准确率。
图3 不同丢包率下的鲁棒性
2、设置不同的延迟
图4显示了不同延迟的DF性能。通过对比实验发现,应用Rosetta后,现有DL模型在多样化网络环境中的分类性能显著提升。例如,DF模型在不同延迟环境下的分类准确率能够保持在86%以上,而未使用Rosetta时,当延迟从0增加到50毫秒时,准确率从99%下降至55%左右
图4 不同延迟下的分类鲁棒性
3、设置不同的MTU
实验还评估了不同MTU设置对分类性能的影响,当MTU从1500减小到700字节时,精确度会从99%减小到80%以下。这是因为一个MTU导致数据包大小的变化,从而导致流的数据包序列发生显著变化。
图5 不同MTU下的分类鲁棒性
4.3
局限性评估
尽管Rosetta在提高现有深度学习模型在多样化网络环境中的TLS加密流量分类性能方面表现出色,但仍存在一些局限性。某些情况下准确率会略有下降,这是由于Rosetta提取了鲁棒特征而忽略了不稳定特征。
五. 总结
本文深入探讨了Rosetta方法在提升深度学习模型在多样化网络环境中处理TLS加密流量分类的有效性。通过TCP感知的流量增强和自监督学习,Rosetta不仅显著提升了模型的性能,还有效解决了应用识别、恶意流量检测和流量分类中环境变化导致的挑战。这一技术的引入为未来网络安全研究者提供了新的思路和方法,希望能够激发更多关于深度学习在网络安全领域应用的深入探讨和创新。
参考文献
【1】Xie R, Cao J, Dong E, et al. Rosetta: Enabling Robust TLS Encrypted Traffic Classification in Diverse Network Environments with TCP-Aware Traffic Augmentation. USENIX Security ’23.
【2】https://github.com/sunskyXX/Rosetta.git.
内容编辑:创新研究院 薛甜
责任编辑:创新研究院 陈佛忠
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
如有侵权请联系:admin#unsafe.sh