2024-9-27 13:19:0 Author: billdemirkapi.me(查看原文) 阅读量:6 收藏
Disclaimer: This research was conducted strictly independent of my employer (excluded from scope). All opinions and views in this article are my own. When citing, please call me an Independent Security Researcher.
Modern technologies like the cloud have made it easier than ever to rapidly develop scalable software. What took thousands of dollars in investment is now accessible through a free trial. We've optimized infrastructure-as-a-service (IaaS) providers to reduce friction to entry, but what happens when security clashes with productivity? What risks have we introduced for the sake of convenience?
For the last three years, I've investigated how the insecure defaults built into cloud services has led to widespread & systemic weaknesses in tens of thousands of organizations, including some of the world's largest like Samsung, CrowdStrike, NVIDIA, HP, Google, Amazon, the NY Times, and more! I focused on two categories: dangling DNS records and hardcoded secrets. The former is well-traversed and will serve as a good introduction to finding bugs using unconventional data sources. Work towards the latter, however, has often been limited in scope & diversity.
Unfortunately, both vulnerability classes run rampant in production cloud environments. Dangling DNS records occur when a website has a DNS record that points at a cloud host that is no longer in its control. This project applied a variant of historic approaches to discover 66,000+ unique top level domains (TLDs) that still host dangling records. Leveraging a similar "big data" approach for hardcoded secrets revealed 15,000+ unique, verified secrets, for various API services.
While we will review findings later, the key idea is simple: cloud providers are not doing enough to protect customers against misconfigurations they incentivize. These vulnerabilities are created by the customer, but how platforms are designed directly controls whether such issues can exist at all.
Instead of taking accountability and enforcing secure defaults, most providers expect that a few documentation warnings a majority will never read is sufficient to mitigate their liability. This research demonstrates how this is far from enough and the compounding risk of abuse with hardcoded secrets.
Cloud computing lets you create infrastructure on demand, including servers, websites, storage, and so on. Under the hood, they're just an abstracted version of what many internet-facing businesses had to do a few decades ago. What makes it work are high margins and more importantly, the fact that everything is shared.
Cloud Environments & Network Identifiers
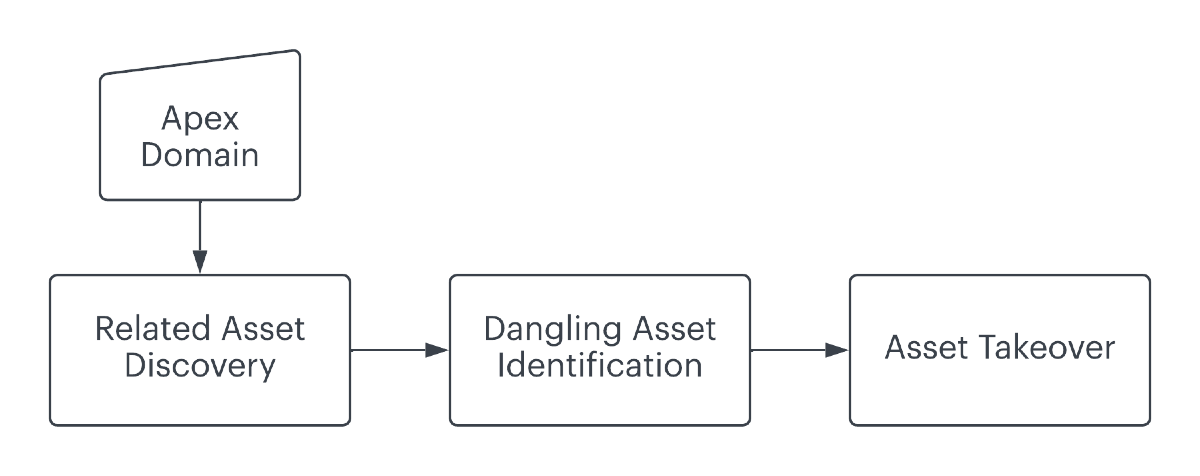
A cloud resource is dangling if it is deallocated from your environment while still referenced by a DNS record. For example, let's say I create an AWS EC2 instance and an A record, project1.example.com, pointing at its public IP. I use the subdomain for some project and a few months later, deallocate the EC2 instance while cleaning up old servers I'm not using.
Remember, you paid to borrow someone else's infrastructure. Once you're done, the IP address assigned to your EC2 instance simply goes back into the shared pool for use by any other customer. Since DNS records are not bound to their targets by default, unless you remember that project1.example.com needs to be deleted, the moment the public IP is released is the moment it is dangling. These DNS records are problematic because if an attacker can capture the IP you released, they can now host anything at project1.example.com.
A/AAAA records are not the only type at risk. A* records are relevant when your cloud resource is assigned a dedicated IP address. Not all managed cloud services involve a dedicated IP, however. For example, when using a managed storage service like AWS S3 or Google Cloud (GCP) Storage, you're assigned a dedicated hostname like example.s3.amazonaws.com. Under the hood, these hostnames point at IP addresses shared across many customers.
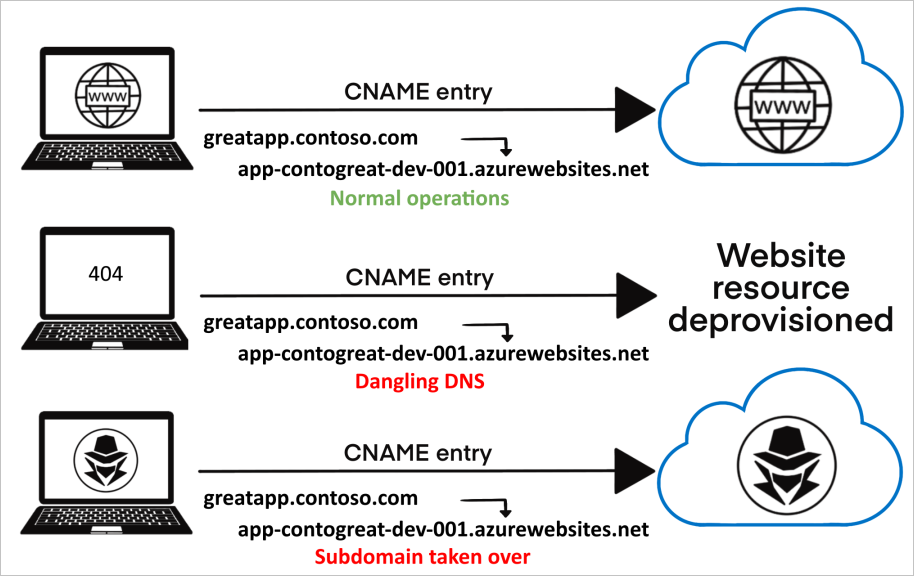
DNS record types like CNAME, which accept hostnames, can similarly become dangling if the hostname is released (e.g., you delete a bucket, allowing an attacker to recreate with same name). Unlike dedicated endpoints, it is easier to guard shared endpoints against attacks because the provider can prohibit the registration of a deallocated identifier. Reserving IP addresses, however, is far less feasible.
Why Care?
Why should you care about dangling DNS records? Unfortunately, if an attacker can control a trusted subdomain, there is a substantial risk of abuse:
- Enables phishing, scams, and malware distribution.
- Session Hijacking via Cross-Site Scripting (XSS)
- If
example.comdoes not restrict access to session cookies from subdomains, an attacker may be able to execute malicious JavaScript to impersonate a logged in user. - Context-specific impact, like…
- Bypass trusted hostname checks in software (e.g., when downloading updates).
- Abuse brand trust & reputation for misinformation.
According to RIPE's article, Dangling Resource Abuse on Cloud Platforms:
The main abuse (75%) of hijacked, dangling resources is to generate traffic to adversarial services. The attackers target domains with established reputation and exploit that reputation to increase the ranking of their malicious content by search engines and as a result to generate page impressions to the content they control. The content is mostly gambling and other adult content.
...
The other categories of abuse included malware distribution, cookie theft and fraudulent certificates. Overall, we find that the hacking groups successfully attacked domains in 31% of the Fortune 500 companies and 25.4% of the Global 500 companies, some over long periods of time.
Dangling DNS records are most commonly exploited en masse, but targeted attacks still exist. Fortunately, to achieve a high impact beyond trivial search engine optimization, an attacker would need to investigate your organization's relationship with the domain they've compromised. Unfortunately, while trivial abuse like search engine optimization matters less in isolated incidents, it becomes a major problem when scaled.
Cloud Environments & Authentication
Cloud environments, including any API service, are managed over the Internet. Even if you use dedicated resources where possible, you're still forced to manage them through a shared gateway. How do we secure this access?

Since the inception of cloud services, one of the most common methods of authentication is using a 16 to 256 character secret key. For example, until late 2022, the recommended authentication scheme for AWS programmatic access was an access and secret key pair.
[example]
aws_access_key_id = AKIAIBJGN829BTALSORQ
aws_secret_access_key = dGhlcmUgYXJlIGltcG9zdGVycyBhbW9uZyB1cw
While AWS today warns against long-lived secret keys, you still need them to issue short-lived session tokens when running outside of an AWS instance. Also, it's still the path of least resistance.

An alternative example is Google Cloud (GCP).
- gcloud CLI credentials: Trigger interactive login in a website browser to authenticate. Credentials cannot be hardcoded into source.
- Application Default Credentials: Look for cached credentials stored on disk, in environment variables, or an attached service account. Credentials cannot be hardcoded into source.
- Impersonated Service Account: Authenticate using a JSON file with a private key & metadata for a service account. Technically, you can hardcode it in a string and load it manually, but the default is to load it from a file.
- Metadata Server: API exposed to GCP instances. Allows you to request an access token if a service account is assigned to the resource. Credentials cannot be hardcoded into source.
While GCP also has API keys, these are only supported for benign services like Google Maps because they do not "identify a principal" (i.e., a user). The closest they have to a secret you can hardcode, like AWS access/secret keys, are service account JSON files.
{
"type": "service_account",
"project_id": "project-id-REDACTED",
"private_key_id": "0dfREDACTED",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvwREDACTED\n-----END PRIVATE KEY-----\n",
"client_email": "[email protected]",
"client_id": "106REDACTED...",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/REDACTED%40project-id-REDACTED.iam.gserviceaccount.com",
"universe_domain": "googleapis.com"
}
Unlike a short secret, Google embeds a full size RSA 2048 private key in PEM format. While you could still hardcode this, there is an important distinction in how GCP and AWS approached short-lived secrets. Google incorporated strong defaults in their design, not just in their documentation.
- GCP service account keys are stored in a file by default. AWS access and secret keys were not designed to be used from a file.
- GCP client libraries expect service account keys to be used from a file. AWS client libraries universally accept access and secret keys from a string.
- It is more annoying to hardcode a 2,000+ character JSON blob than it is to hardcode a 20-character access and 40-character secret key.
We'll dissect these differences later, but the takeaway here is not that AWS is fundamentally less secure than GCP. AWS' path of least resistance being insecure only matters at scale. If you follow AWS recommendations, your security posture is likely close to that of a GCP service account. At scale, however, it is inevitable that some customers will follow where the incentives lead them. In AWS' case, that's hardcoding long-lived access and secret keys in production code. GCP's layered approach reduces this risk of human error by making it annoying to be insecure.
Why Care?
Unfortunately, hardcoded secrets can lead to far worse impact than dangling DNS records because, by default, they have little restriction on who can use them.
By their very nature, secrets are "secret" for a reason. They're designed to grant privileged access to cloud services like production servers, databases, and storage buckets. Cloud provider keys could let an attacker access and modify your infrastructure, potentially exposing sensitive user data. A leaked Slack token could let an attacker read all internal communication in your organization. While impact still varies on context, secrets are much easier to abuse and often lead to an immediate security impact. We'll further demonstrate what this looks like when we review findings.
Past Work
This blog is not intended to serve as a thorough literary analysis of all past work regarding dangling domains and hardcoded secrets, but let's review a few key highlights.
Dangling Domains
Dangling DNS records are a common problem discussed for at least a decade.
One of the first works pivotal to our understanding of the bug class was published in 2015 by Matt Bryant, Fishing the AWS IP Pool for Dangling Domains. This project explored dangling DNS records that point at a dedicated endpoint, like an AWS EC2 public IP (vs a hostname for a shared endpoint, like *.s3.amazonaws.com).

Bryant found that he could continuously allocate and release AWS elastic IPs to enumerate the shared customer pool. Why is this important? To exploit a dangling DNS record, an attacker needs to somehow control its target, e.g., the EC2 IP that was previously allocated/released by the victim. While enumerating these IPs, Bryant searched Bing using the ip: quantifier to see if any cached domains pointed at it. This effectively allowed Bryant to look for dangling DNS records without a specific target.

A few years later, AWS implemented a mitigation that restricts accounts to a small pool of IPs, instead of the entire shared address space. For example, if you allocate, free, and reallocate an elastic IP today, you'll notice that you'll keep getting the same IPs over and over again. This prevents enumeration of the AWS IP pool using standard elastic IP allocation. Google Cloud has a very similar mitigation to deter dangling record abuse, but they extend the "small account pool" to apply to any component that allocates an IP.
Besides dangling records that point at a generic cloud IP, more recent work into "hosting-based" records (e.g., CNAME to a hostname, aka "shared" endpoint) includes, DareShark: Detecting and Measuring Security Risks of Hosting-Based Dangling Domains.

Researchers from Tsinghua University used DNS databases to identify records that point at "service endpoints", like example.s3.amazonaws.com. Next, if the managed service is "vulnerable", they check whether the identifier is registered (i.e., does the example s3 bucket exist?). If it is not, and the managed service is "vulnerable", they can register the identifier under their attacker account and hijack the record! Whether a service is vulnerable varies. For example, some providers require proof of ownership (like a TXT record) or disallow registering identifiers that were previously held by another customer.
There are a lot of other projects against dangling DNS records we won't review for brevity. While the space is well traversed, there are some limitations of historical approaches. In general, past work usually runs into at least one of the following:
- Use of a limited data source to identify what domains point at a given IP/hostname.
- Focus is exclusively DNS records pointing at IPs (dedicated endpoints) OR hostnames (shared endpoints). Rare to see both at once.
- Extremely limited work into defeating modern deterrents.
- For example, many dangling DNS records that point at a shared endpoint are not actually exploitable because of provider restrictions like proof of domain ownership.
- Some large providers have seen almost no research into exploiting records that point at a dedicated endpoint, like a generic IP address, due to mitigations like a small pool of IPs assigned to your account. For instance, work into Google Cloud has been limited to shared hostnames.
Later, we'll use dangling records as an example of how you can apply unconventional data sources to find vulnerabilities at scale. Additionally, as we'll soon see, I also attempted to avoid these common pitfalls. With that said, let's move on to hardcoded secrets!
Hardcoded Secrets
Unlike dangling DNS records, work into hardcoded secrets was a lot more limited than I expected. In general, research into this category falls into two camps:
- Tools to search files and folders for secret patterns.
- Projects that search public code uploaded to source control providers, like GitHub, for secret patterns.
There are dozens of trivial examples of the former including Gitleaks, Git-secrets, and TruffleHog. These tools listen for new Git commits, or are ran ad hoc against existing data, like the contents of a Git repository, S3 bucket, Docker image, and so on.
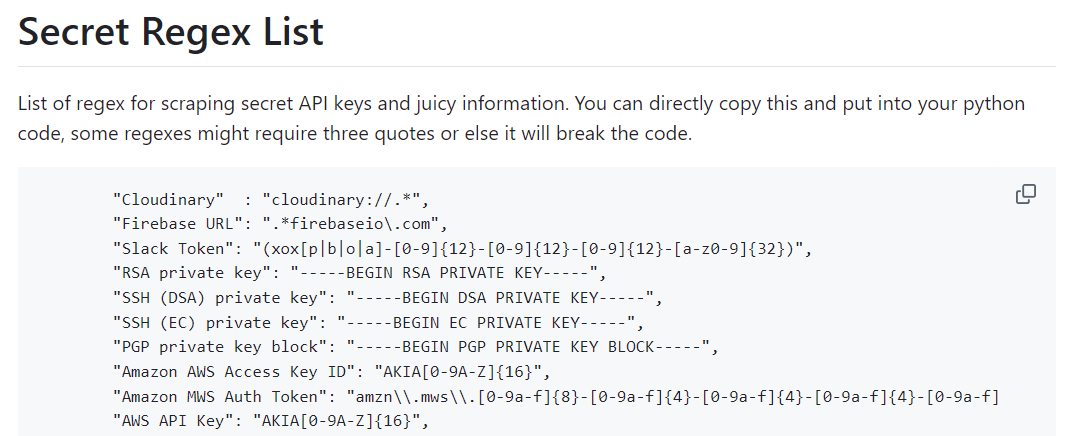
Nearly all secret scanning tools work by looking for a regex pattern for various secrets. For example, some providers include a unique identifier in their API keys that makes accurate identification trivial, e.g., long-term AWS user access keys start with AKIA. You can see this in the example regex patterns above, such as AKIA[0-9A-Z]{16}.

Moving on from self-managed tooling, some source control platforms, particularly GitHub, proactively scan for secrets in all public data/code. In fact, GitHub goes a step beyond identifying a potential secret by partnering with several large cloud providers to verify and revoke leaked secrets! This is pretty neat because it can prevent abuse before the customer can take action.
In general, all work into hardcoded secrets faces the same problem: it's against a data set limited in scope and diversity. Even GitHub's secret scanning work, one of the largest projects of its kind to date, only has visibility into a small fraction of leaked secrets. For example, most closed source applications will likely never encounter GitHub's scanning. Other tools like TruffleHog are better at accepting a diverse set of file formats, but lack a large, diverse source, of those files.
How can we do better?
Traditional Discovery Mindset
When we consider the conventional approaches to vulnerability discovery, be it in software or websites, we tend to confine ourselves to a specific target or platform. In the case of software, we might reverse engineer an application's attack surfaces for untrusted input, aiming to trigger edge cases. For websites, we might enumerate a domain for related assets and seek out unpatched, less defended, or occasionally abandoned resources.
To be fair, this thinking is an intuitive default. For example, when was the last time you read a blog about how to find privilege escalation vulnerabilities at scale? They exist, but unsurprisingly, the industry is biased towards vulnerability hunting individual targets (including me!). This is the result of simple incentives. It's way easier to hunt for vulnerabilities at a micro level, particularly complex types like software privilege escalation. Monetary incentives like bug bounty are also target oriented.
To be fair, automatically identifying software vulnerabilities is extremely challenging. What I've noticed with cloud vulnerabilities is that they're not only easier to comprehend, but they also tend to lead to a much larger impact. Why? Remember- in the cloud, everything is shared! I can remotely execute code in a software application? Cool, I can now pop a single victim if I meet a laundry list of other requirements like network access or user interaction. I can execute code in a cloud provider? Chances are, the bug impacts more than one customer.
Should Some Vulnerabilities Be Approached Differently?
The industry lacks focus on finding bugs at scale- it's a common pattern across most security research. Can we shift our perspective away from a specific target?
| Perspective | Dangling Resources |
|---|---|
| Traditional | Start with a target and capture vulnerable assets. |
| At Scale | Capture first & identify impact with “big data”. |
With dangling DNS records, the "traditional" approach is to enumerate a target for subdomains and only then identify vulnerable records. Fortunately, dangling DNS records are one of the few vulnerability classes we've been able to identify at scale.
For example, we previously discussed Matt Bryant's blog about finding records that point at deallocated AWS IPs. Instead of starting with a target, Bryant enumerates potential vulnerabilities- the shared pool of available AWS IPs, many of which were likely assigned to a another customer at some point. Bryant worked backwards. What DNS records point at the IP I allocated in my AWS environment? If any exist, I know for a fact that they are dangling, because I control the target!
Bryant's methodology had other problems, like a limited source of DNS data (e.g., Bing's ip: search filter), but the key takeaways are simple.
- Many vulnerability classes are trivial to identify, but are subject to our unconscious bias to start with a specific target.
- There is a large gap in using non-traditional data sources to identify these issues at scale.
For example, the two perspectives for leaked secrets include:
| Perspective | Leaked Secrets |
|---|---|
| Traditional | Scan a limited scope for secret patterns. |
| At Scale | Find diverse “big data” sources with no target restriction. |
Today, most work towards identifying leaked cloud credentials focus on individual targets, or lack diversity (e.g., GitHub secret scanning). To identify dangling DNS vulnerabilities at scale, we start with the records, not a target. We do this by using "big data" sources of DNS intelligence, e.g., the capability to figure out what records point at an IP.
Are there similar "big data" sources that would let us identify leaked secrets at scale without starting with a limited scope?
The Security at Scale Mindset
- Start with the vulnerability, not the target.
- Work backwards using creative data sources.
- Must contain relationships indicative of the targeted vulnerability class.
- Must be feasible to search this data at scale.
Reverse the Process: Dangling Resources
A DNS record is dangling if it points at a deallocated resource. The ideal data source must include a large volume of DNS records. While we covered Bing as an example, are there better alternatives?

Passive DNS replication data is a fascinating DNS metadata source I learned about a few years ago. Long story short, some DNS providers sell anonymized DNS data to threat intelligence services who then resell it to people like me. Anonymization means they usually don't include user identifiers (client IP) and rather the DNS records themselves.
Passive DNS data has many uses. Most importantly, its diversity and scope is almost always better than alternatives to enumeration, like brute-forcing subdomains. If someone has resolved the DNS record, chances are that the record's metadata is available through passive DNS data. For our purposes, we can use it to find records that point at an IP or hostname we've captured while enumerating a provider's shared pool of network identifiers.
To be clear, using passive DNS data to find dangling records is not novel, but it's a great example of the security at scale mindset in practice. We will apply this technique against modern deterrents in the implementation section.
Reverse the Process: Secret Scanning
Going back to the drawing board- what unorthodox data sources would potentially contain leaked secrets? Well, secrets can be included in all sorts of files. For example, if you use a secret in your client-side application, it's not just your source code that has it- any compiled version will include it too. Websites, particularly JavaScript, can use secrets to access cloud services too.
Where can we find a large collection of applications, scripts, websites, and other artifacts?
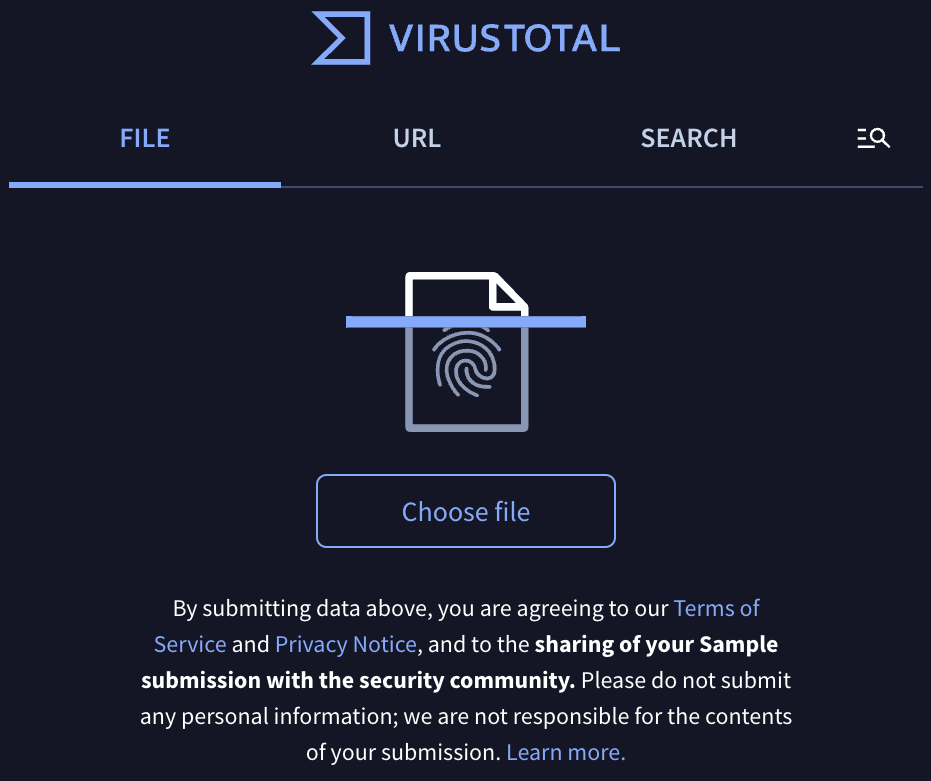
What about… virus scanning platforms? "By submitting data ... you are agreeing ... to the sharing of your Sample submission with the security community ..."
Virus scanning websites like VirusTotal allow you to upload & inspect a file for malicious content using dozens of anti-virus software providers. The reason they caught my eye was because they have everything. Documents, desktop software, iOS and Android apps, text files, configuration files, etc. all frequently find their way to them. The best part? These websites often allow privileged access to these files to improve detection products, reduce false positives, and identify malware.
While we aren't after malware, we are after vulnerabilities. Virus scanning platforms are simply a means of identifying them. For example, platforms could block my access, but if a secret in some app was uploaded in a file to them, chances are that app is accessible off platform too.
Scanning Samples?
Even if we have a candidate data source, we're far from finished. It would be infeasible to scan every file on larger platforms directly. We need to reduce scope.
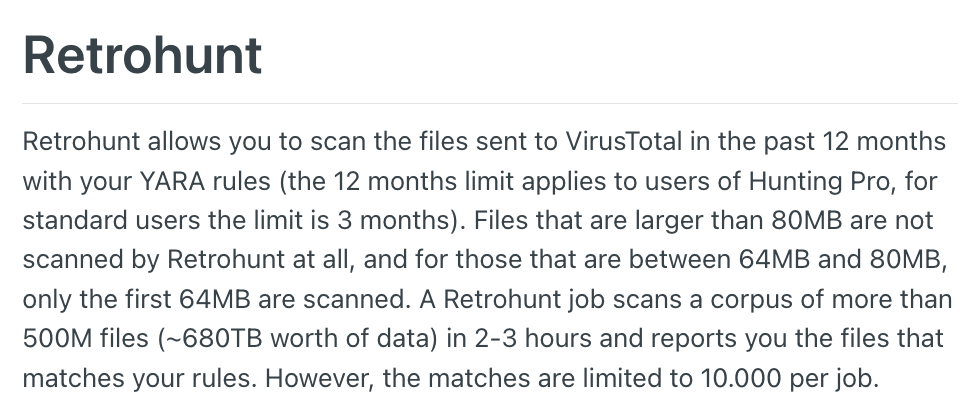
This challenge is not exclusive to our use case. If we were looking for malware, we'd run into the same feasibility problem. Fortunately, platforms that allow data access typically also provide a means of searching that data. In VirusTotal's case, this feature is called Retrohunt.

Retrohunt lets you scan files using something called "YARA rules". YARA provides a "rules-based approach to create descriptions of malware families based on regular expression, textual or binary patterns". The above example from YARA's documentation shows what these rules look like.
In the past work section, we discussed how secrets can sometimes have an identifiable pattern, like AKIA for AWS access keys. In fact, all secret scanning tools use regex based on these identifiers to find secrets. You know what else supports regex? YARA! While originally designed to "identify and classify malware samples", we can repurpose it to reduce petabytes of data to "just" a few million files that potentially contain credentials.
Enough theory, let's write some code!
Secret Scanning
Overview
The plan should be simple. Scan for secret patterns across several virus scanning platforms and validate potential credentials with the provider. How hard can it be? (tm)
One problem I encountered early on was that not all cloud providers use an identifiable pattern in their secrets. How are we supposed to identify candidate samples for scanning? In the overview of the security at scale mindset, note how I said the data source, "must contain relationships indicative of the targeted vulnerability class".
Just because we can't identify some secrets directly, doesn't mean we can't identify potential files indirectly. For example, let's say I have a Python script that makes a GET request to some API endpoint using a generic [a-zA-Z0-9]{32} key with no identifying marks. How would I identify this file for scanning? One relationship in the file is between the API key and the API endpoint.
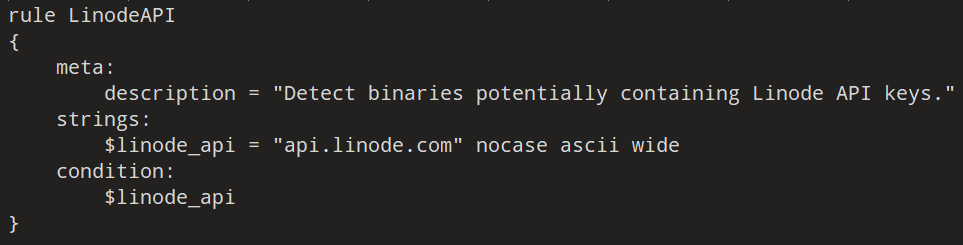
While I can't search for the API key, what if I searched for the endpoint instead? The example above is a rule I wrote for Linode, a cloud provider with generic secret keys. I can't process every sample uploaded to VirusTotal, but chances are I can feasibly process every sample with the string api.linode.com.
Generic keys are also annoying because even if we cut our scope, 32 consecutive alphanumerical characters can easily match plenty of non-secret strings too. In this project, beyond identifying potential secrets, I wanted accurate identification. How do we know if a generic match is a secret? Only one way to find out- give it a go!

It would obviously be inappropriate to query customer data, but what about metadata? For example, many APIs will have benign endpoints to retrieve basic metadata like your username. We can use these authenticated endpoints as a bare minimum validity test to meet our technical requirements without going further than we have to! These keys are already publicly leaked after all.
To review:
- We write YARA rules for cloud services we're interested in finding secrets for based on 1) any identifiable patterns in the secret, or 2), worst case we look for the API endpoint instead.
- We search virus scanning platforms for these rules to identify a subset of samples with potential credential material.
- We enumerate matches in each sample, and test potential keys against a benign metadata endpoint to identify legitimate finds.
Scanning Millions of Files
Our Retrohunt jobs will produce a large number of samples that may contain secrets. Extracting strings and validating every possible key will take time and computational resources. It would be incredibly inefficient to scan hundreds of thousands of samples synchronously. How do we build infrastructure to support our large volume?
When I first started this work in 2021, I started by scanning samples locally. It turned out to be incredibly impractical. I needed approach that could maximize the number of samples we could scan in parallel without breaking the bank. What if we leveraged cloud computing?
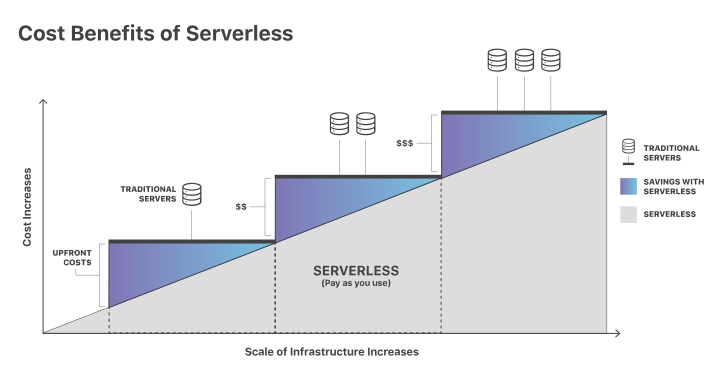
A cloud execution model that has been growing in the past decade is serverless computing. At a high level, serverless computing is where your applications are only allocated and running when they are needed on a cloud provider's managed infrastructure. You don't need to worry about setting up your own server or pay for idle time. For example, you could run a web server where you only pay for the time it takes your application to respond to a request.
AWS's serverless offering is called AWS Lambda. What if we created an AWS Lambda function that scans a given sample for secrets? AWS Lambda has a default concurrency limit of 1,000. This means we could scan at least 1,000 samples concurrently! As long as our scans did not take more than a few minutes, AWS Lambda is fairly cost efficient as well. I ended up using AWS Lambda, but you don't have to! Most providers have equivalents; AWS was just where I had the most experience.
We need four major components for our secret scanning project.
- We need a single server responsible for coordinating VirusTotal scans and dispatching samples to our serverless environment. Let's call this the coordinator.
- We need an AWS Lambda function that can scan a sample for valid secrets in a few minutes.
- We need a message broker that will contain a queue of pending Retrohunt jobs and a queue of validated secrets.
- We need a database to store Retrohunt scan metadata, samples we've scanned, and any keys we find.
Our coordinator and Lambda function will require details for each type of service we are targeting.
- The coordinator will need a YARA rule for each key type.
- The Lambda function will need a method for determining if a string contains a potential key for that service and a method for validating a potential key with the backend API.
When I originally started this project, tools like TruffleHog which similarly detect and validate potential keys had not yet been created. More importantly, they weren't designed to maximize efficient scanning. With Serverless, you are charged for every second of execution. We needed an optimized solution.
For the Coordinator, I went with Python, but for the scanner, I went with C++. This component will download a given sample into memory, extract any ASCII or Unicode strings, and then scan these strings for secrets. For each supported provider, I implemented a class with two functions: 1) check if a string contains a potential secret key, and 2), validate a secret using a benign metadata endpoint (usually via REST). Generically, the scanner runs an internal version of strings and passes each to the first function. Any matches are tracked and asynchronously verified using the second.
std::vector<KeyMatch> LinodeKeyType::FindKeys(std::string String)
{
const std::regex linodeApiKeyRegex("(?:[^a-fA-F0-9]|^)([a-fA-F0-9]{64})(?:[^a-fA-F0-9]|$)");
std::sregex_iterator rend;
std::vector<KeyMatch> potentialKeys;
std::smatch currentMatch;
//
// Find all API keys.
//
for (std::sregex_iterator i(String.begin(), String.end(), linodeApiKeyRegex); i != rend; ++i)
{
currentMatch = *i;
if (currentMatch.size() > 1 && currentMatch[1].matched)
{
potentialKeys.push_back(KeyMatch(currentMatch[1].str(), LinodeKeyCategory::LinodeApiKey));
}
}
return potentialKeys;
}
bool LinodeKeyType::ValidateKeyPair(std::vector<KeyMatch> KeyPair)
{
KeyMatch apiKey;
//
// Retrieve the API key from the key pair.
//
apiKey = KeyPair[0];
//
// Attempt to retrieve the account's details using the API key.
//
HttpResponse accountResponse = WebHelper::Get("https://api.linode.com/v4/account", {}, {{"Authorization", "Bearer " + apiKey.GetKey()}});
if (accountResponse.GetStatusCode() == 200)
{
return true;
}
return false;
}
To detect secrets, I use hyperscan, Intel's "high-performance regular expression matching library". I originally started with C++'s <regex> implementation seen above, but I was shocked to find that hyperscan was faster by an order of magnitude. What took 300 seconds (e.g., scanning a large app with many strings) now took 10! Regex patterns were manually crafted based largely on public references, like that secret pattern repository we covered in Past Work.
The Coordinator, used to manage our entire architecture, was pretty straightforward. Triggered on a timer, it looks in a database for Retrohunt scans that are pending and monitors their completion. A cool trick: VirusTotal Retrohunt has a 10,000 sample limit per job. To avoid this, around ~5% into the job, you can check whether the number of matches times 20 (for 5%) is greater than or equal to 10,000. If it is, you can abort the job and dispatch two new Retrohunt jobs split by time. For example, if I'm scanning the past year, I'll instead create two jobs to scan the first and second half of the year respectively. You can recursively keep splitting jobs, which was critical for secrets which lacked an identifiable pattern and thus led to many samples.
# Check if our scan reached VirusTotal's match limit.
if (scan_status == "finished" and scan.get_num_matched_samples() == 10000) or \
(scan_status == "running" and scan.is_scan_stalled()):
logging.warning(f"Retrohunt scan {scan_id} reached match limit. Splitting and re-queueing.")
# Calculate the mid point date for the scan.
scan_start_time = scan.start_time
scan_end_time = scan.end_time
scan_mid_time = scan_start_time + (scan_end_time - scan_start_time) / 2
# Queue the first half scan (start to mid).
self.add_retrohunt_scan(scan.key_type_name, scan_start_time, scan_mid_time)
# Queue the second half scan (mid to end).
self.add_retrohunt_scan(scan.key_type_name, scan_mid_time, scan_end_time)
logging.info(f"Queued two new retrohunt scans for key type {scan.key_type_name}.")
# If the scan is running, abort it.
if scan_status == "running":
scan.abort_scan()
logging.info(f"Aborted running scan {scan_id} due to stall.")
logging.info(f"Marking retrohunt scan {scan_id} as aborted.")
self.db.add_aborted_scan(scan_id)
The message broker and database are nothing special. I started with RabbitMQ for the former, but use AWS SQS today. I use MySQL for the latter.
To recap our end-to-end workflow:
- The coordinator occasionally checks the database for new Retrohunt scan entries.
- The coordinator keeps track of any pending Retrohunt scans.
- Early in a scan, if we predict that the number of samples exceeds 10,000, we split the scan in two.
- Once finished, we enumerate each sample and adds it to our message broker, in turn triggering an AWS Lambda call.
- The AWS Lambda scanner downloads the sample and extracts ASCII/Unicode strings, calling the key type's
FindKeysimplementation. - Once finished, each potential match is validated using
ValidateKeyPairin parallel. - Verified keys are added to the database.
This approach let me scan several million samples quickly and with a reasonable cost. While there are many optimizations I could do to the C++ scanner, or infrastructure by avoiding Serverless, it does not matter enough to warrant dealing with that complexity.
Dangling Domains
Moving on to dangling DNS records, I was most interested in challenging modern provider mitigations. Of note, as far as I could see, attempts to enumerate Google Cloud's pool of IPs has failed because of this. There has been work into hijacking dangling records for managed services, like Google Cloud DNS, just not the dedicated endpoint equivalent.
AWS also has a few mitigations, like the small pool of IPs you can access by allocating/releasing elastic IPs, but there are known ways around this. For example, instead of allocating elastic IPs, we can restart EC2 instances with ephemeral IPs to perform enumeration. On restart, you get a brand new IP.
Google Cloud was harder, but their mitigations are deterrents. Limitations include...
- Like AWS, IPs are assigned from a small per-project pool. Unlike AWS, this applies project-wide. For example, trying to recreate compute instances will run into the same pool restriction (which is not true for AWS EC2).
- Per project, by default, you can only have 8 IPs assigned at once, globally and per-region.
- You can only have 5 projects associated with a "billing account".
- Billing accounts are tied to a payment method like a credit card. You can only have 2 billing accounts per unique credit card (before hitting fraud verification).
- You can only have 10-15 projects by default per account.
How do we get around these? Well...
- You can attach a billing account across Google accounts.
- To bypass account quotas, you can create multiple accounts using Google Workspace.
- To bypass billing account restrictions, you can use virtual credit cards.
For most quota limits, I figured the easiest way around them would be to create several accounts. The billing restrictions made this difficult, but for account creation, I ended up creating a fake Google Workspace tenant. Google Workspace is just Google products as a service for enterprises. The neat part about a Workspace is that you can programmatically create fake employee accounts, each with 10-15 projects!

For the billing restrictions, I used virtual credit cards. Long story short, services like Privacy let you generate random credit card numbers with custom limits to avoid exposing your own. These services still follow know your customer (KYC) practices; my identity was verified, but they let us get past any vendor-set limits based on your credit card.
By creating several accounts using Google Workspace and unique virtual cards, I was able to get past Google's deterrents. Note that I didn't abuse any vulnerability- these mitigations simply are just mitigations. With the quotas out of the way, I successfully enumerated Google's public IP pools (per-region and global) by constantly recreating forwarding rules!
Metrics
Dangling Domains
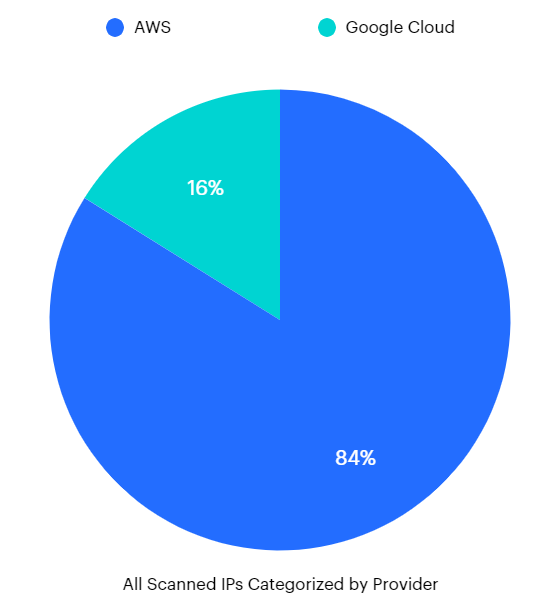
CloudRot, what I called my dangling enumeration work, enumerated the public IP pools of Google Cloud and Amazon Web Services. In total, I've captured 1,770,495 IPs to date. 1,485,211 IPs (~84%) for AWS and 285,284 IPs (~16%) for GCP. The reason for the differences is largely due to Google's technical mitigations.
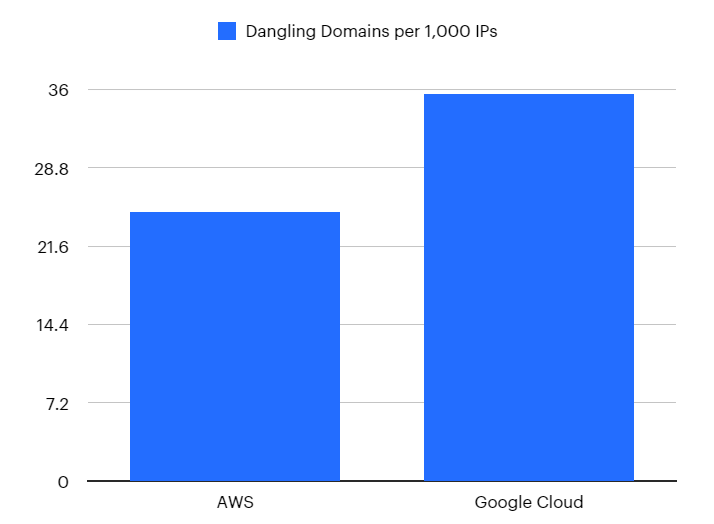
For every 1,000 IPs in AWS's public pool, 24.73 of them were associated with a domain. For every 1,000 IPs in Google Cloud's public pool, 35.52 of them were associated with a domain.
While purely speculative, I suspect that the noticeable increase in the rate of impacted Google Cloud's IPs is largely due to the fact that this is likely the first publication that has successfully enumerated the public IP pool for Google Cloud's "compute" instances at scale. There has been research into taking over managed applications in Google Cloud, but I was unable to find any publication that enumerated IPs, likely due to the extensive technical mitigations we encountered. Since there has been a lack of research into this IP pool, it's possible that the systemic vulnerability of dangling domains has gone unnoticed.
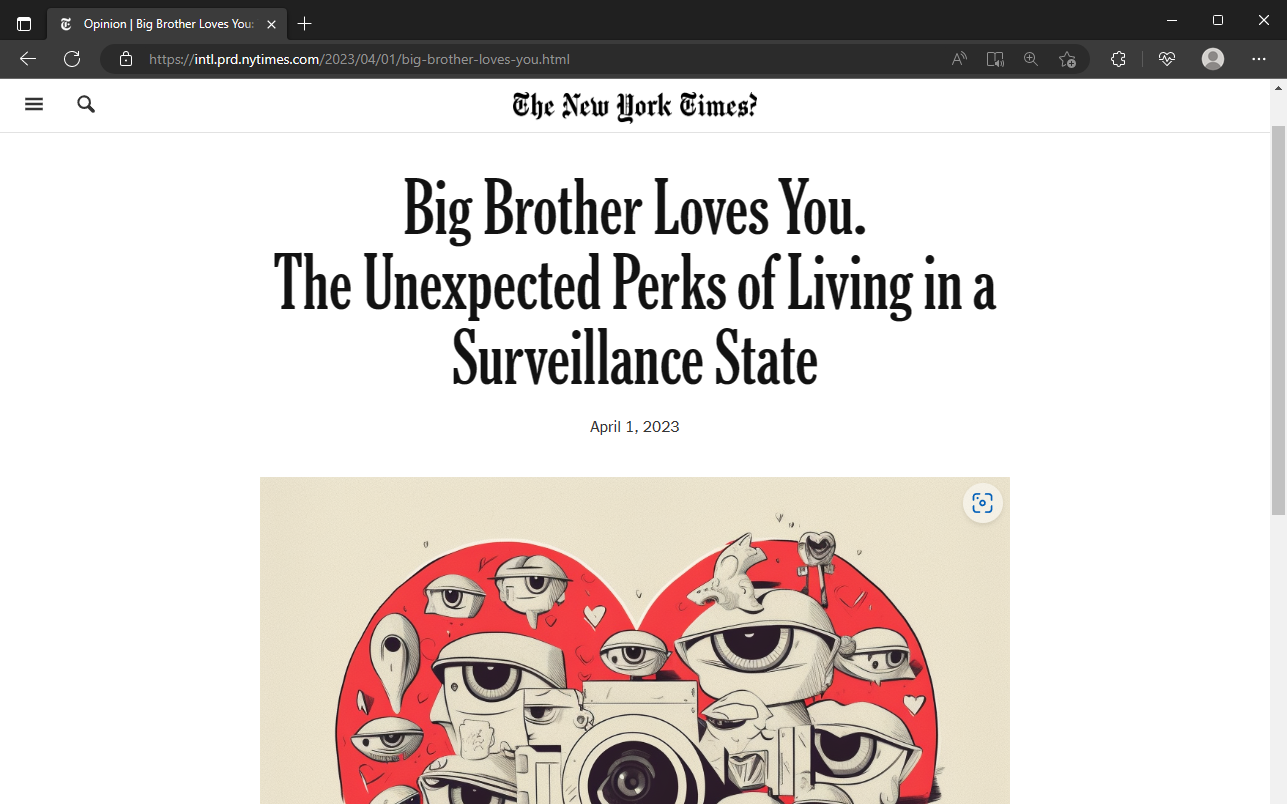
In total, I discovered over 78,000 dangling cloud resources corresponding to 66,000 unique top-level domains (excluding findings associated with dynamic DNS providers). There were thousands of notable impacted organizations like Google, Amazon, the New York Times, Harvard, MIT, Samsung, Qualys, Hewlett-Packard, etc. Based on the Tranco ranking of popular domains, CloudRot has discovered 5,434 unique dangling resources associated with a top 50,000 apex domain.
Here are a few archived examples!
The New York Times: https://web.archive.org/web/20230328201322/http://intl.prd.nytimes.com/index.html
Dior: https://web.archive.org/web/20230228194202/https://preprod-elk.dior.com/
State Government of California: https://web.archive.org/web/20230228162431/https://tableau.cdt.ca.gov/
U.S. District Court for the Western District of Texas: https://web.archive.org/web/20230226010822/https://txwd.uscourts.gov/
Even Chuck-e-Cheese! https://web.archive.org/web/20230228033155/https://qa.chuckecheese.com/
Hardcoded Secrets
- Scanned over 5 million unique files from various platforms.
- Discovered over 15 thousand validated secrets.
- 2,500+ OpenAI keys
- 2,400+ AWS keys
- 2,200+ GitHub keys
- 600+ Google Cloud Service Accounts
- 460+ Stripe live secrets
- Breakdown of metadata
- ~36% of keys were embedded in the context of an Android application.
- ~12% of keys were embedded in an ELF executable, but these were often bundled in an Android app.
- ~8.7% of keys were found in HTML.
- ~7.9% of keys were embedded in a Windows Portable Executable.
- ~5.7% of keys were found in a regular text file.
- ~4.8% of keys were found in a JSON file.
- ~4.7% of keys were found in a dedicated JavaScript file.
- And so on...
- Breakdown of country of origin
- ~3.7% of files with keys were uploaded from the United States
- ~2.3% from India
- ~1.7% from Russia
- ~1.4% from Brazil
- ~1.1% from Germany
- ~0.9% from Vietnam
- And so on...
Case Studies
Samsung Bixby
One of the first keys I encountered was for Samsung Bixby's Slack environment.
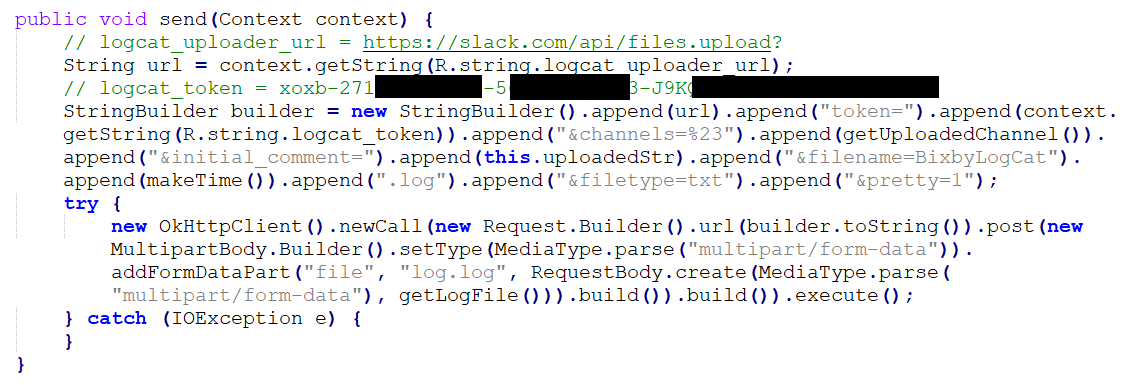
Long story short, the com.samsung.android.bixby.agent app has a "logcat" mechanism to upload the agent's log file to a dedicated Slack channel. It does this using the Slack REST API and a bot token for dumpstater.
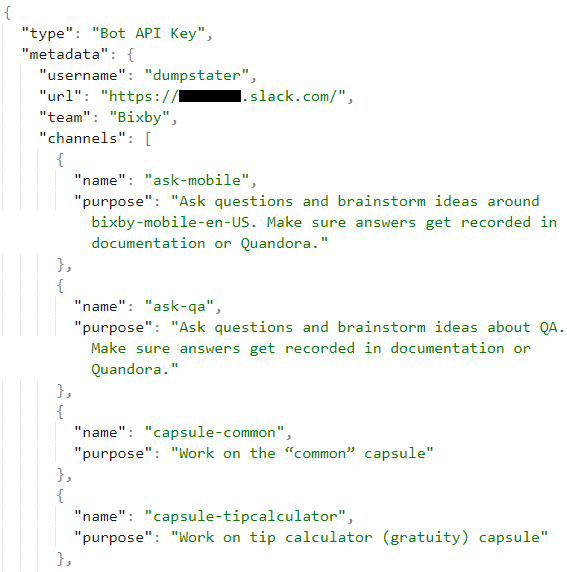
The vulnerability was that the bot had a default bot scope, which an attacker could abuse to read from or write to every channel in Samsung's Slack!
CrowdStrike
Another early example includes CrowdStrike! An old version of a free utility CrowdStrike distributes on crowdstrike.com, CrowdInspect, contained an hardcoded API key for the VirusTotal service. The API key granted full access to both the VirusTotal account of CrowdStrike employee and the broader CrowdStrike organization inside of VirusTotal.
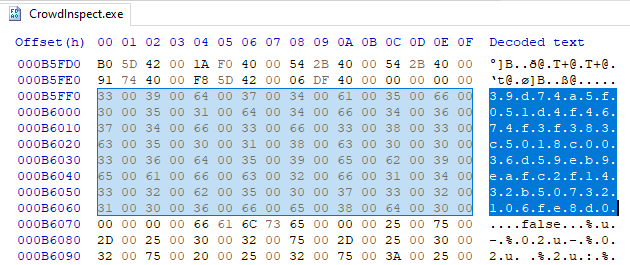
An attacker can use this API key to leak information about ongoing CrowdStrike investigations and to gain significant premium access to VirusTotal, such as the ability to download samples, access to VirusTotal's intelligence hunting service, access to VirusTotal's private API, etc. For a full list of privileges, you can use the user API endpoint.
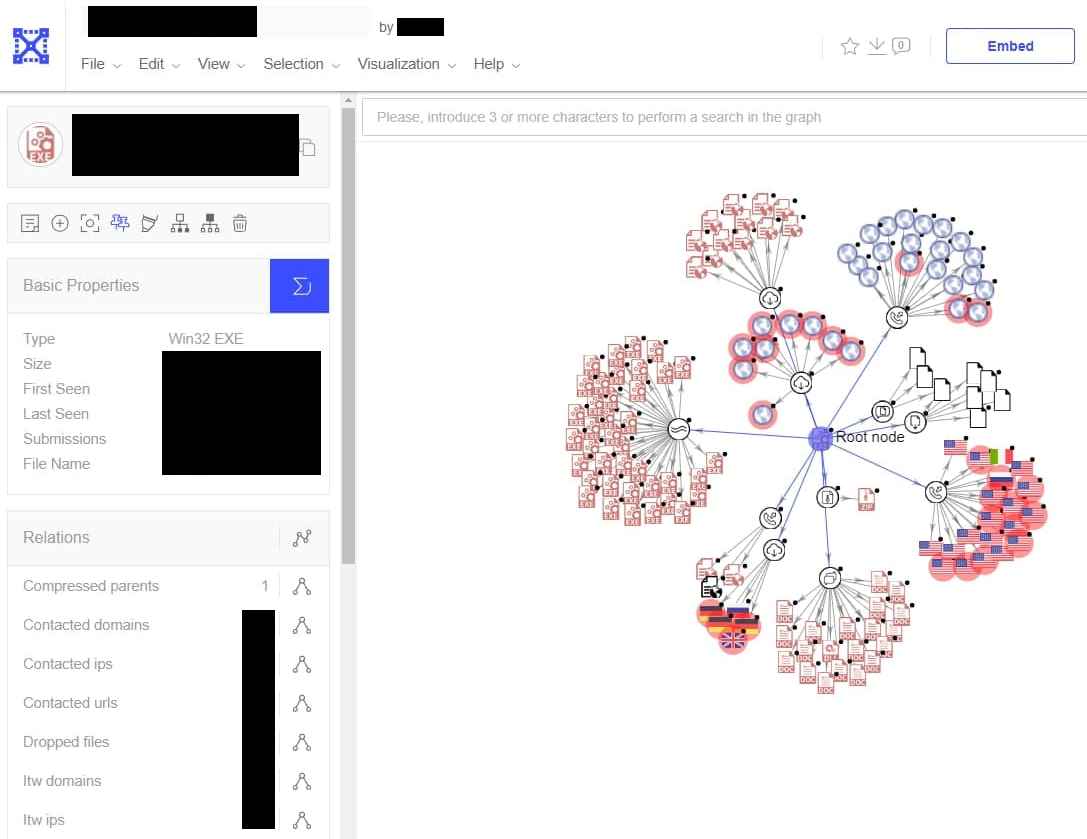
As an example of how this key could be abused to gain confidential information about ongoing CrowdStrike investigations, I queried the VirusTotal Graphs API with the filter group:crowdstrike. VirusTotal offers Graphs as a feature which allows defenders to graph out relationships between files, links, and other entities in one place. For example, a defender could use VirusTotal graphs to document the different binaries seen from a specific APT group, including the C2 servers those binaries connect to. Since our API key has full access to the CrowdStrike organization, we can query the active graphs defenders are working on and even see the content of these graphs.
Obviously, this was quickly reported and got fixed in under 24 hours!
Supreme Court of Nebraska

This was a fun one. At the end of 2022, I found an interesting CSV export of an employee of Nebraska's Supreme Court with over 300 unique credentials including...
- Credentials for internal infrastructure
- Credentials for security tooling
- Credentials for mobile device management
- Credentials for VPN access (OpenVPN)
- Credentials for cloud infrastructure
- Unredacted credit card information
- And much more...
These were seriously the keys to the kingdom and then some. While metadata showed the file was uploaded in Lincoln, Nebraska, by a web user, it's unclear whether this was an accident or an automated tool. I worked directly with Nebraska's State Information Security Officer to promptly rotate these credentials.
An important goal I have with any research project is to approach problems holistically. For example, I not only like finding vulnerabilities, but thinking about how to address them too. Leaked secrets are a major problem- they are far easier to abuse than dangling DNS records. Was there anything I could do to mitigate abuse?
Piggybacking GitHub

I wasn't the only one trying to fix leaked secrets. GitHub's secret scanning program had already addressed this. GitHub partners with many cloud providers to implement automatic revocations. Partners provide regex patterns for their secrets and an endpoint to validate/report keys. For example, if you accidentally leak your Slack token in a GitHub commit, it will be revoked in minutes. This automation is critical because otherwise, attackers could search GitHub (or VirusTotal) for credentials and abuse them before the customer has an opportunity to react.
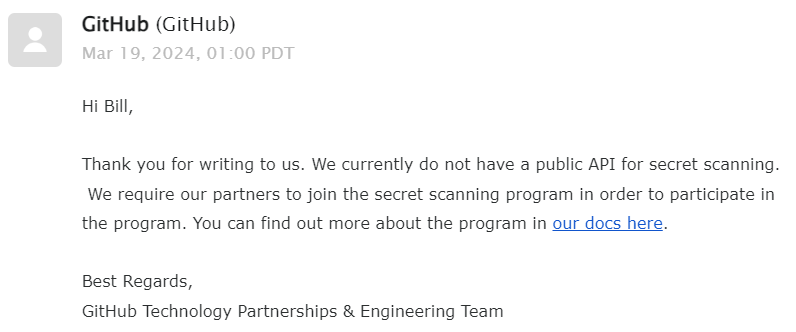
I asked whether they could provide an endpoint for reporting keys directly. GitHub had done a great job creating relationships with vendors to automatically rotate keys. After all, I could already report a key by just posting it on GitHub, and all hosting an endpoint would do is help secure the Internet.
Unfortunately, they said no. Fortunately, I was only asking as a courtesy. I created a throwaway account and system that would use GitHub's Gist API to create a public note with a secret for only a split second. In theory, this would trigger GitHub's scans, and in turn a provider revocation.
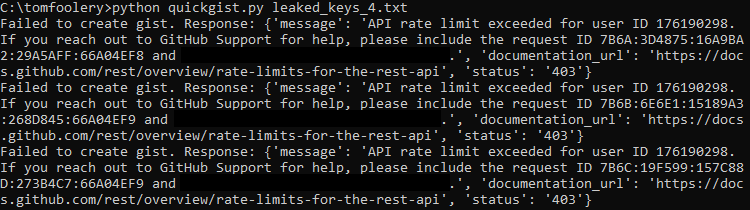
This actually worked during testing, but I ran into the above error when trying it with ~500 keys.
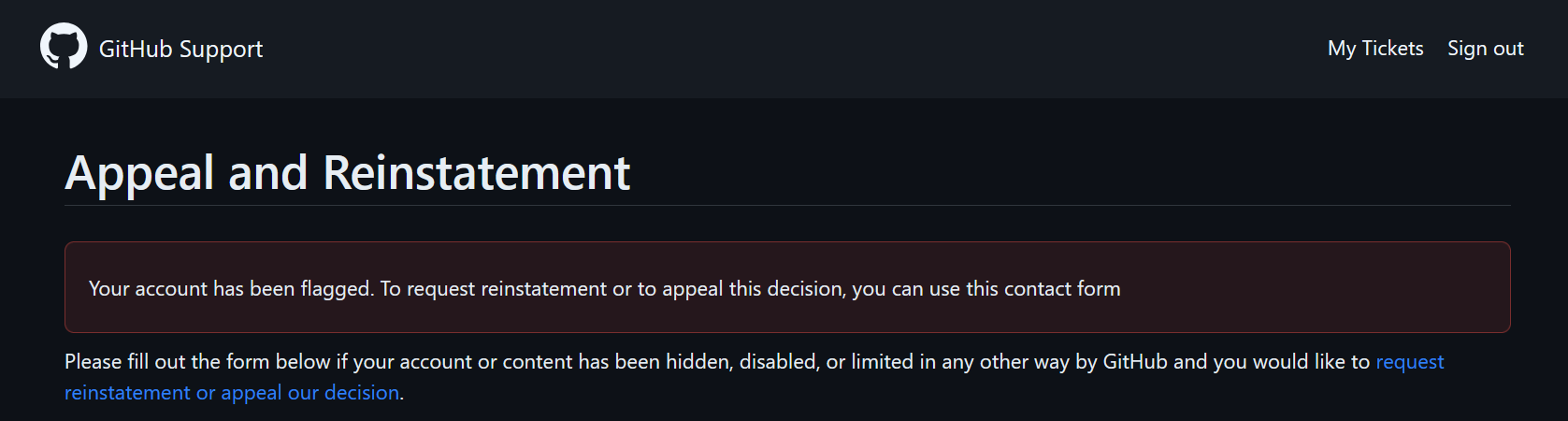
It turns out GitHub doesn't like it when you create hundreds of Gists in a matter of minutes and suspended my account. This was a problem due to the scale of keys I was finding. Unfortunately, once a test account is flagged, most API calls fail. How can we get around this?
When debugging, I noticed something weird. For some reason, posting a Gist at the web interface, https://gist.github.com still worked. Even stranger? When I visited a public Gist in an incognito session, I faced a 404 error. It turns out that when your account is suspended, GitHub hides it (and any derivative public content like gists) from every other user. You're basically shadow banned! What's interesting was that they still allowed you to upload content through the UI, but not the API. Whatever the reason, this got me thinking...
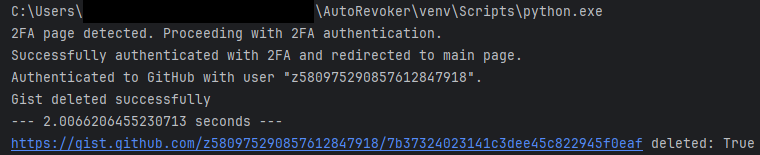
Who needs an API? Using Python Selenium, a library to control a browser in test suites, I created a script that automatically logged me into GitHub and used the undocumented API to publish a Gist. While my test account was still shadow banned, this was actually a feature! How? I could now create public gists that triggered secret scanning without any risk of exposure!! (also why I don't mind sharing the account's name or ID)

I used GitHub to revoke most keys I discovered, if the provider had enrolled in their program, going well beyond the minimum by protecting victims! Above is the small website I included in the name of the Gist which is embedded in key exposure notification emails. Today, any new secrets leaked on VirusTotal and a few other platforms are automatically reported, helping mitigate abuse.
Working With Vendors
Besides GitHub, I also worked with several partners directly to report leaked key material.
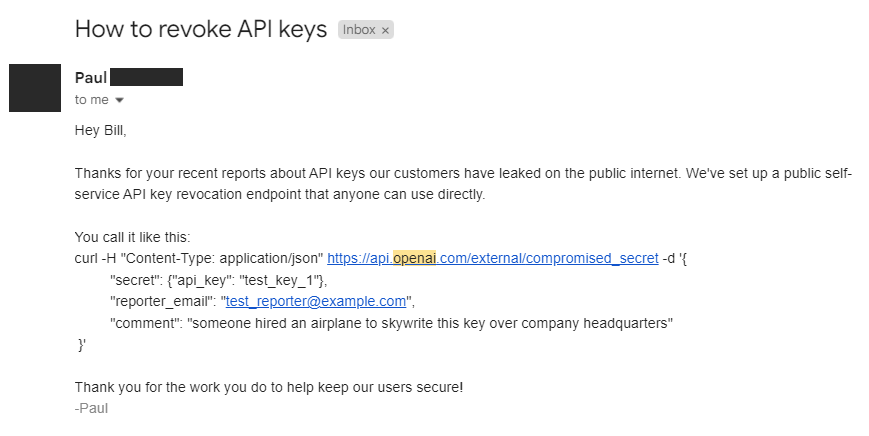
To start, I'd like to give a special thanks to the vendors who worked with me to help protect their customers. Above is an example of an endpoint for revoking leaked OpenAI keys. Unfortunately, the process was not so smooth in all cases. For example, AWS, the largest cloud provider by market share, refused to share the endpoint used to report leaked secrets, despite the fact we could access it indirectly by posting a secret in a gist. This was nothing but politics getting in the way of customer security.
To add insult to injury, when AWS detects a leaked secret on GitHub, they do not revoke it. Instead, they restrict the key and create a support case with the customer who might not even see it. The former sounds good in theory, but in practice, limits very little. It really only prevents write access, like being able to start an EC2 instance or upload files to S3 buckets. There is almost no restriction to downloading data, like a customer database backup on an S3 bucket.
Before I developed the GitHub reporting system, I used to manually email batches of keys to AWS. In late July, while preparing key metrics, I noticed a few keys in my database that I thought I had seen before. In fact, I had seen them! Many new keys my system detected were the same keys I had reported to AWS months before. What was going on?
According to my estimates, ~32% of the keys I reported to you over 2-3 months ago are unrevoked and were forgotten about by your fraud team. The ~32% figure is based on the number of unique keys I reported to you by email which again appeared active at the end of July. It appears that the support cases your fraud team created in many cases were automatically resolved, leaving the keys exposed for abuse.
~ Email to AWS Security
AWS not only fails to revoke publicly leaked secrets, but the support cases they create are horribly mismanaged. It turned out that ~32% of the keys I reported to AWS were not addressed 4 months later. The reason? If the customer didn't respond, the support case for the leaked secret is automatically closed! You can see one example above I obtained while investigating a previously reported secret.
I've continued to work with AWS on these concerns, but have yet to see any meaningful action. I suspect the choice to leave keys exposed for abuse is due to the risk of impacting legitimate workflows that depend on the key. This would be a fair concern, but what's worse, a short-term service disruption or the theft of sensitive user data?
How do I know for a fact AWS' approach is unreasonable? Every other vendor enrolled in secret validity checks in GitHub's program I tested revoked leaked keys, including AWS' direct competitor, Google Cloud. The ~32% unrevoked figure after 4 months also worries me because I wonder if it applies to keys on GitHub, which are easy to spot. I think this could end very badly for AWS, but at the end of the day, this is their call.
Takeaways
- Security at Scale Is Not Only Offensive.
- We can use the same techniques we use to find these issues to also protect against them.
- Incentives Are Everything.
- Dangling resources and leaked secrets are technically the customer's fault, but the wrong incentives are what enable them at scale.
- At scale, the path of least resistance matters. For example, many platforms offer API tokens as default mechanisms for authentication. When it's easy to hardcode secrets, developers will hardcode secrets.
- DNS was created before cloud computing. It needs to be modernized. For example, given cross-industry collaboration in other areas, could we tie DNS records to cloud assets, automatically deleting (or at least alerting) when an associated asset is destroyed?
- What Cloud Providers Are Missing
- Limited collaboration to solve issues at the ecosystem layer.
- Ineffective mitigations to these common vulnerability classes. We've known about dangling DNS records for over a decade, yet the problem only seems to have grown.
- There is a lack of urgency to address leaked secrets. For example, AWS is one of the only participants in the GitHub secret scanning program who does not automatically revoke keys that are leaked to the world. This puts customers at extreme risk.
- How Do We Fix It? Make the path of least resistance secure by default.
- Hardcoded Secrets: Deprecate tokens for authentication. Some use cases may not be able to completely eradicate them, but add barriers to using them. Use certificate-based authentication or other secure alternatives.
- Hardcoded Secrets: Make it hard to abuse tokens. Example include clearly separating tokens with read-only capability with write-only capability.
- Dangling Resources: Perhaps we need a new standard for tying DNS records to cloud resources. At minimum, Cloud & DNS Providers should collaborate.
How Do I Protect My Organization?
In general, make it as hard as possible to insecurely use secrets within your organization. The trivial approach to solving leaked secrets within your organization is to use existing tooling to scan your code. This does not address the root cause of leaked secrets. To prevent them, the most effective approach is to focus on design decisions to disincentivize insecure usage of credentials.
Start by understanding "how is my organization currently managing secrets?"
- For example, if a developer requires access to a backend service, what does the process for obtaining an API key look like?
- Who is responsible for managing credentials (if anyone)?
- What security practices is your organization following around leaked secrets?
- Who has the authority to specify company policy?
Have a central authority for managing secrets. OWASP has an incredible cheat sheet on this. I strongly recommend following their advice.
- For example, have an internal service that all applications must go through to interact with a backend server.
- You can either have this service provide other applications with credentials to use or for an additional layer of security, never let the API key leave the internal service.
- Frequently rotate your credentials. With a central authority for secrets, automating this process is much more straightforward.
- Ensure that this service has extensive auditing and logging. Look into detecting anomalous behavior.
- Use a hardware medium (TPM) to store your secrets where possible.
- Assign an expiration date for your keys to force a regular review of access.
For dangling domains, there is no one size fits all. Generally, you should track the cloud resource associated with any DNS record you create, but this will vary dependent on your environment. I believe a better solution would come at a platform/provider level, but this requires cross-industry collaboration.
Cloud Providers
- Automatically revoke leaked secrets reported to your organization.
- If you are running a platform that provides API access for your customers, there is a lot you can do to make it harder for your customers to insecurely implement your API.
- Allow and encourage customers to rotate their API keys automatically.
- Allow and encourage customers to use cryptographic keys that can be stored in hardware to sign API requests.
- Make your API keys contain a recognizable pattern. Makes it far easier for defenders to find leaked secrets.
- Implement detections for anomalous activity.
- If an API key has only performed a limited number of operations for a long period of time and suddenly begins to be used heavily, consider warning the customer about the increased usage.
- If an API key has been used by a limited number of IP addresses for a long period of time and is used from an unrecognized location, consider warning the customer.
- Plenty more approaches depending on the service.
- Customers: Hold the platforms you use accountable for these practices.
This article explored two common, yet critical vulnerability classes: dangling DNS records and leaked secrets. The former was well traversed, but served as a useful example of applying what I call the "security at scale mindset". Instead of starting with a target, we start with the vulnerability. We demonstrated how dangling records are still a prominent issue across the Internet, despite existing for over a decade.
We then targeted hardcoded secrets, an area far less explored. By leveraging unconventional "big data" sources, in this case virus scanning platforms, we were able to discover secrets at an unprecedented scale. Like dangling DNS records, the root cause of these systemic weaknesses are poor incentives. The status quo of using a short token for authentication incentivizes poor security practices, like embedding them in raw code, no matter how much we warn against it.
We finished the project by going end-to-end. Not only did we discover these problems, we mitigated a majority by taking advantage of GitHub's existing relationships and automating their UI to trigger secret revocation. It's rare to have an opportunity to directly protect victims, yet so important to deterring abuse.
I'd encourage you to think about the mindset we applied in this article for other types of bugs. Examples of other interesting data sources include netflow data and OSINT/publicly available data you can scrape. In general, here are two key areas to focus on:
- Break down traditional methods of finding a vulnerability into steps.
- Correlate steps with large data sets, regardless of their intended usage.
I hope you enjoyed this research as much as I did! I'm so glad to have had the opportunity to share this work with you. Would love to hear what you think- feel free to leave a reply on the article tweet!
如有侵权请联系:admin#unsafe.sh