IntroductionIn the ever-evolving landscape of cybersecurity, logs, that is informatio 2024-10-2 18:0:37 Author: securelist.com(查看原文) 阅读量:39 收藏
Introduction
In the ever-evolving landscape of cybersecurity, logs, that is information collected from various sources like network devices, endpoints, and applications, plays a crucial role in identifying and responding to threats. By analyzing this data, organizations can detect anomalies, pinpoint malicious activity, and mitigate potential cyberattacks before they cause significant damage. However, the sheer volume and complexity of logs often make them challenging to analyze effectively.
This is where machine learning (ML) comes into play. ML, a subset of artificial intelligence (AI), with its ability to process and analyze large datasets, offers a powerful solution to enhance threat detection capabilities. ML enables faster and more accurate identification of cyberthreats, helping organizations stay ahead of increasingly sophisticated attackers.
At Kaspersky, we have been using ML algorithms in our solutions for close on 20 years, and we have formulated ethical principles for the development and use of AI/ML. We utilize a variety of ML models and methods that are key to automating threat detection, anomaly recognition, and enhancing the accuracy of malware identification. In this post, we will share our experience hunting for new threats by processing Kaspersky Security Network (KSN) global threat data with ML tools to identify subtle new Indicators of Compromise (IoCs). We will also discuss challenges in implementing machine learning and interpreting threat hunting results.
The Kaspersky Security Network (KSN) infrastructure is designed to receive and process complex global cyberthreat data, transforming it into actionable threat intelligence that powers our products. A key source of threat-related data comes from voluntary contributions by our customers. To find out more, read about the principles of Kaspersky Security Network and our privacy policy.
The role of ML in global threat log analysis
Machine learning enables systems to learn from data and improve their performance over time without being explicitly programmed. When applied to cybersecurity logs, ML excels at analyzing large and complex datasets. It can automatically identify patterns, detect anomalies, and predict potential threats. When applied to our KSN global threat logs, ML can help predict and identify new threats.
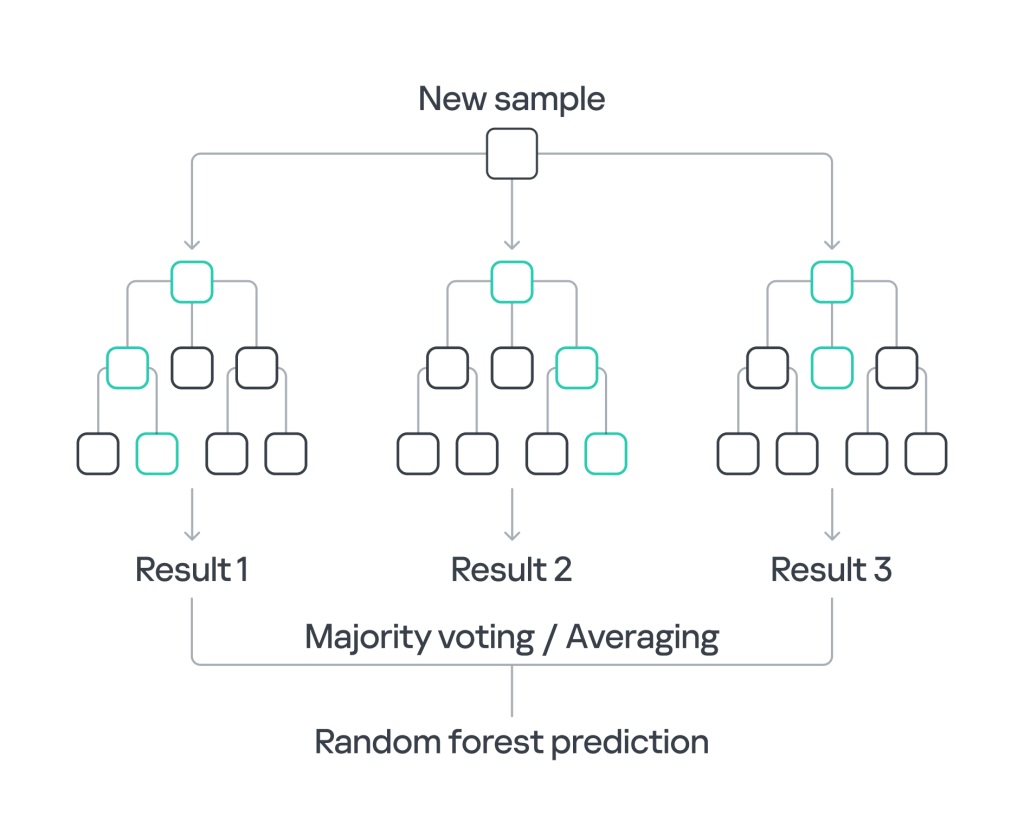
One of the ML algorithms particularly well-suited for this task is Random Forest. This algorithm works by constructing multiple decision trees during training and assigning classes by the majority vote of the trees during scanning. Random Forest is especially effective in handling non-linear data, reducing the risk of overfitting, and providing insights into the importance of various features in the dataset. Random Forest is highly effective at identifying patterns, but this strength can lead to challenges in interpretability, particularly with larger models. It may produce positive results that are difficult to understand or explain due to the complexity of the decision-making process. Nevertheless, the benefits make it an excellent choice for analyzing logs and uncovering hidden cyberthreats.
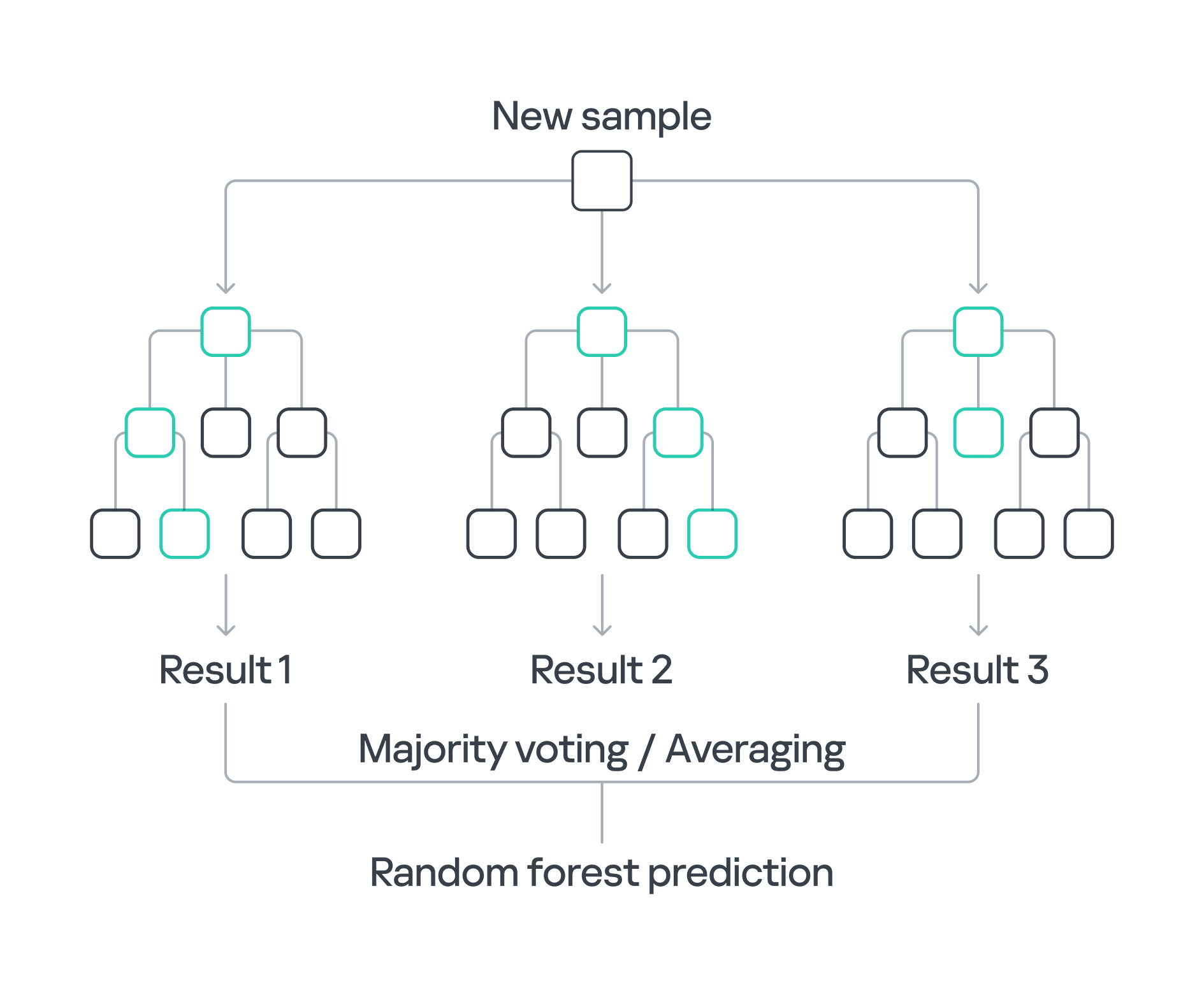
ML Random Forest process
Reconstructing reality: the benefits of using ML in cybersecurity
Continuous learning allows ML models to detect subtle and novel cyberthreats, providing more robust defense. ML then acts to “reconstruct the cyber-reality” by transforming raw telemetry data into actionable insights that reflect the true state of a network or system’s security.
Reconstructing reality using logs: a depiction
The ability of ML-powered technology to analyze vast amounts of data in real time ensures that potential threats are identified and addressed more quickly, minimizing the window of vulnerability. Additionally, the adaptability of ML means that as new attack vectors emerge, models can still provide some level of protection without requiring updates, unlike traditional systems that often need constant rule revisions. This leads to a more proactive and effective cybersecurity posture, allowing organizations to stay ahead of increasingly sophisticated cyberattacks.
Ultimately, the ability of ML to partially reconstruct the cyber-reality from logs helps organizations stay ahead of cyberthreats by offering a clearer, more precise view of their security posture, enabling faster and better informed decision-making.
Methodology and challenges
The goal of the ML model presented in this study is to evaluate new logs and identify anomalous behavior. For that to be done, a clean dataset should be prepared, and the model needs to be configured with the right options to best perform its objectives. The model is then trained and tested, before being deployed to examine larger amounts of data.
Nearly every organization possesses unique datasets that can be leveraged to enhance and improve services. However, with this opportunity comes the critical responsibility of adhering to compliance standards and legal requirements. This responsibility is a key reason why we cannot disclose all the details of the training process and algorithms involved. Below we discuss the steps we have taken to achieve the goal, as well as the challenges you might encounter while training and applying similar models.
The dataset
A machine learning dataset is a collection of data used to train, validate, and test ML models. A dataset consist of various examples, each containing features (input variables) and, in supervised learning tasks, corresponding labels (output variables or targets).
Our dataset has been collected from, and is representative of, a large variety of previously investigated incidents. It describes advanced malware activities that we have observed in attacks by a variety of threat actors. More information about APT threat actors we track can be found here. The dataset contains a variety of indicators of malicious activities that were verified manually after being automatically collected to reduce the risk of inaccuracy.
A well-prepared dataset is foundational to the success of any ML project. The choice of dataset, its quality, and how it is prepared and split into training, validation, and test sets can significantly impact the model’s ability to learn and generalize new data. The adage of “garbage in, garbage out” applies here: if the dataset is flawed or poorly curated, the ML model’s predictions will also be unreliable.
Preprocessing
Preprocessing is a crucial step in a machine learning pipeline where raw data is transformed into a format suitable for training an ML model. This process involves cleaning the data, handling missing values, transforming variables into a scaled and normalized numerical representation, and ensuring that the data is in a consistent and standardized format. Effective preprocessing can significantly improve the performance and accuracy of an ML model.
One popular method we used for this transformation is term frequency–inverse document frequency (TF–IDF), which is a statistical measure used in natural language processing to evaluate the importance of a word in a document relative to a collection of documents. TF–IDF transforms raw text data into a set of machine-readable numerical features, which can be then fed to an ML model.
Implementation and training of the model
When dealing with text data, a common approach is to first transform the raw text into numerical features using techniques like TF–IDF and then apply an ML algorithm such as Random Forest to classify or analyze the data. TF–IDF is known to be efficient and versatile, while Random Forest is known for accuracy, reduced overfitting, and an ability to capture complex, non-linear relationships between features. The combination of TF–IDF with Random Forest allows handling high-dimensional data, while also providing robustness and scalability, very much needed to handle data with millions of entries daily.
A machine learning model reaches maturity when it performs consistently well on the kind of tasks it was designed for, meeting the performance criteria set during its development. Maturity is typically indicated by the following factors:
- Stable performance: The model exhibits consistent and satisfactory performance on both training and validation datasets.
- Generalization: The model generalizes well to new, unseen data, maintaining performance levels similar to those observed during testing.
- Diminishing returns from more training: After a certain point, adding more training data or fine-tuning the model further does not lead to significant improvements.
It is worth noting that model training does not necessarily end when it achieves maturity. To maintain model maturity, incremental learning is often needed, which means an ongoing process of updating and refining the machine learning model by incorporating new data over time. This approach is particularly important in dynamic fields where data distributions and patterns can shift, leading to the need for models that can keep up with these changes, which is exactly the case with the cybersecurity threat landscape.
During the development of our model, a target accuracy of 99% was set as a primary performance goal. Once the model achieved this level of accuracy, additional steps were implemented to further refine the output. These steps involved classifying the outcome in specific cases that required manual investigation.
Deployment and computational costs
When a model is ready, it can be integrated into a production environment where it can start making predictions on new data. This could be through an API, embedded in an application, or as part of a larger system. Continuous monitoring of the model’s performance to detect issues such as “concept drift” is essential to avoid degradation in accuracy, ensure reliable predictions, and maintain the model’s relevance in changing environments.
At the same time, both choices of TF–IDF and Random Forest can be computationally intensive. TF–IDF vectorization can lead to very large and sparse matrices. Random Forest models can become demanding when dealing with high-dimensional data and large datasets.
However, with the right capacities and hyperparameter fine-tuning, an optimal ML framework can be reached to permit the model to achieve its potential without sacrificing accuracy or efficiency. Example TF–IDF parameters that we found useful include frequency thresholds to allow, maximum features to extract, ngram range to match. Example Random Forest parameters that we found useful include the number of estimators, depth of the trees, split and leaf samples, and quality and impurity measurements.
Interpretability of results
In ML, and depending on the algorithm used, interpreting the model to understand how it makes predictions could be possible. This could involve analyzing the importance of features, visualizing decision trees, or using other evaluation tools.
However efficient, each model has its limitations that are important to know. Random Forests can be less interpretable than other models, especially with large numbers of input features. TF–IDF by design tends to give higher importance to rare items, which can sometimes be noisy or irrelevant in real-world applications. These feature limitations were acknowledged during development and considered in model fine-tuning.
The outcomes of machine learning during model training play a crucial role in guiding the development, refinement, and optimization of the model. These outcomes provide valuable feedback that helps data scientists and ML engineers make informed decisions to improve the model’s performance, guide adjustments, and ensure the final model is robust, generalizes well, and meets the desired criteria.
Findings: new cyberthreats discovered
As we started this study, we kept in mind that the usage of ML in log analysis enables the discovery of previously unknown cyberthreats by analyzing vast amounts of data and uncovering patterns. The model can process and learn from millions of data points in real time, pointing out subtle indicators that may signal the presence of a new or advanced threat. However, the results we got exceeded our expectations: the model revealed thousands of new advanced threats. As of H1 2024, ML findings represented 25% added detections of APT-related activities.
Here are a few examples of indicators of compromise found using ML in the past year. Once inspected, these indicators were quickly revealed to be part of malicious activity. The incidents involving these IoCs are not further investigated here, but our analysis of these and similar findings has been published (for example, here and here) or will be, in other posts on this site or in private threat intelligence reports.
Future directions
The future of using ML for telemetry analysis holds exciting possibilities, with several advancements on the horizon that could further enhance threat detection capabilities. One promising area is the integration of deep learning techniques, which can automatically extract and learn complex patterns from raw data. We already use deep learning in some of our products, and applying it to threat hunting could potentially further improve detection accuracy and uncover even more sophisticated threats.
Another area of exploration is reinforcement learning, where models can continuously adapt and improve by interacting with dynamic cybersecurity environments. This could lead to more proactive defense mechanisms that not only detect but also respond to threats in real time.
Additionally, federated learning presents a significant opportunity for collaborative threat detection across organizations while preserving data privacy. By allowing models to learn from decentralized data without sharing the actual data, federated learning could facilitate the creation of more robust and generalizable threat detection models.
Conclusion
The integration of ML into cybersecurity has already demonstrated its transformative potential by enabling the detection of novel cyberthreats that traditional methods might overlook. Through the analysis of vast and complex logs, ML models can identify subtle patterns and IoCs, providing organizations with a powerful tool to enhance their security posture. The examples of cyberthreats discovered over the past year underscore the efficacy of ML in uncovering threats across various industries, from government to finance.
These technologies will not only improve detection accuracy but also enable more proactive and collaborative defense strategies, allowing organizations to stay ahead of the ever-evolving cyberthreat landscape.
In this post, we have evaluated the utilization of ML models on our KSN global threat data, which has led us to reveal thousands of new advanced threats. The journey of refining ML models through meticulous dataset preparation, preprocessing, and model implementation has highlighted the importance of leveraging these technologies to build robust, adaptable, and scalable solutions.
As we continue to explore and enhance these capabilities, the potential for machine learning to reshape cybersecurity and protect against increasingly sophisticated threats becomes ever more apparent. The future of cybersecurity lies in our ability to ethically harness these tools effectively, ensuring a safer digital environment for all.
如有侵权请联系:admin#unsafe.sh