2024-10-11 04:1:40 Author: hackernoon.com(查看原文) 阅读量:2 收藏
Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
4 Experiments
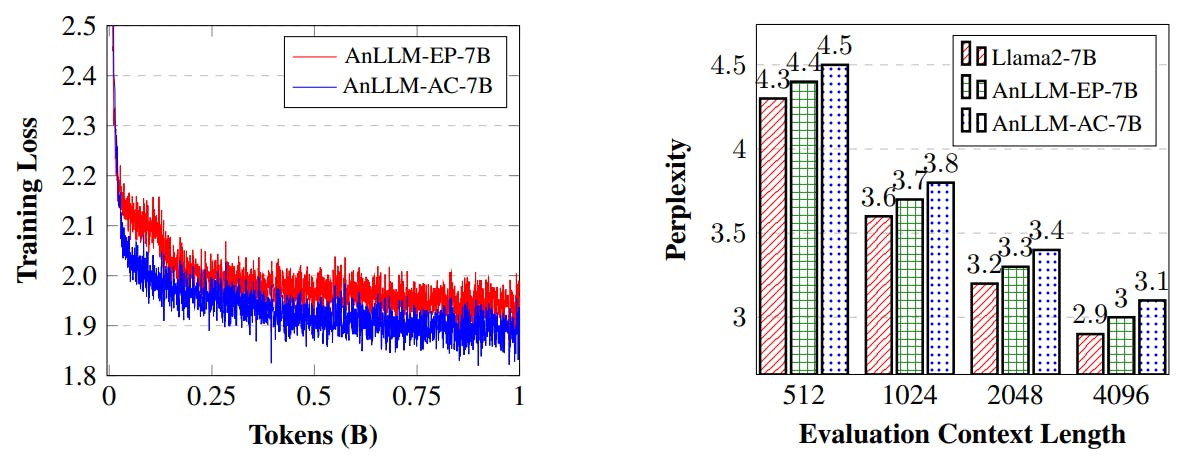
In this section, we first detail AnLLM’s implementation, then outline the training procedure and model perplexity. Finally, we introduce the evaluation datasets and metrics.

4.1 Our Implementation
Llama2-7b (Touvron et al., 2023b) is adopted as the base model in our experiments, which is an open-source and English-centric LLM. In accordance with the principles outlined in Section 3, we present our implementations here. The crux is to identify which tokens in a sequence can be considered anchor tokens. In light of this, we describe two implementation strategies: one employs the endpoints directly, and the other involves appending a new token at the end of a sequence to serve as the anchor token. The details are as follows:
• AnLLM-EP. This approach uses punctuation marks within the sequence as anchor tokens. Punctuation marks, such as commas, periods, and question marks, are viewed as semantic boundaries within a sequence. As such, they can serve as anchor tokens in AnLLM. In our experiments of AnLLM-EP, we use the endpoint in English as the anchor tokens.
• AnLLM-AC. This strategy entails the introduction of a new token to act as the sequence anchor. In our implementation, we designate as the new token and initialize its embedding using the mean value of the embedding matrix. For training data, we use the sentence tokenizer from the NLTK package to split texts into sentences, appending at the end of each sentence as the anchor token.[1] During inference, tokens can be flexibly added to the text based on user requirements, such as adding one anchor for each demonstration, allowing for flexible and controllable sequence compression.
[1] https://www.nltk.org/api/nltk.tokenize.punkt. html
如有侵权请联系:admin#unsafe.sh