大模型发展实在是太快了,也太“卷”了,在ChatGPT发布大火之后,标志着人类开始已经进入大模型时代... 在这里时代了主要围绕大模型本身(参数,打榜)、多模态(视频、声音)、Agent(自动化)、提 2024-10-28 03:1:0 Author: mp.weixin.qq.com(查看原文) 阅读量:25 收藏
大模型发展实在是太快了,也太“卷”了,在ChatGPT发布大火之后,标志着人类开始已经进入大模型时代... 在这里时代了主要围绕大模型本身(参数,打榜)、多模态(视频、声音)、Agent(自动化)、提示词工程、RAG、微调等“生态”展开...
转眼之间,这些东西已经“卷”了不知道多少轮了,随着荣耀CEO演示通过语音助手直接调用美团APP实现点咖啡的演示,到Claude 3.5 Sonnet-20241022的“computer use”
https://www.anthropic.com/news/3-5-models-and-computer-use再到近日智谱官宣的AutoGLM实现了“Phone Use”,从官方文章里介绍的情况来看,前面提到的荣耀证实是通过集成AutoGLM来实现的:
「我们也与荣耀等手机厂商基于 AutoGLM 开展深度合作。」
由此我觉得大模型时代进入了AI Agent 2.0!
在之前我做内部培训的时候其中一个比较大的感受就是,大模型时代发展变化太快,倒是很多人认知、理解、思维都在不断被刷新。很可能今天我所表达的这些,很可能明天就被改变了!在Agent方向的生态应用,我个人觉得相比其他算是最早被看到,也是被肯定的一个方向,所以最开始很多人就在往这个方向发力,比如langchain,大家所思考的方向是通过实现各种现有产品服务的api或者Function Call等去实现自动化调动,最开始的某个单一的调用到多个应用或者服务之间协同调用的“工作流”,很长一段时间,我都可能认为这是一个比较成熟的过程了,而且手机上语音等接口输入有天然的优势,所以那个时候非常期待iphone与ChatGPT的深度结合,理论上讲操作系统去整合大模型能力应该是真正做到底层融合的效果。
说实话我在看到“荣耀CEO演示通过语音助手直接调用美团APP实现点咖啡的演示”那个视频的时候,我还在一度认为这个是结合了类似于adb shell调用activity的一些Agent实现,如:
打开浏览器
am start -n com.android.browser/com.android.browser.BrowserActivity
然后在进行处理文字输入及模拟点击就可以实现,这个就是典型的AI Agent 1.0时代的认知和思维,这个时候我认为的一切都是API化处理及调用,很显然这种模式在操作系统上去做集成可能是效果最好的,但是这个需要额外的Agent的开发去适配不同场景的任务或者需要不同的“剧本”提示词去告诉大模型各种Function Call,这个就有很大的通用局限性及开发成本...
直到看到Claude 3.5 Sonnet-20241022的“computer use”的发布才“恍然大悟”,这条路完全不用考虑AI Agent 1.0的那些“问题”,一个Agent就可以实现,充分发挥大模型的识别及推理能力,后面一细想这也是“理所当然”的一条路,因为在这之前,包括OpenAI、Claude都已经很好的支持了上传一个设计UI“草图”都可以完美实现编码多模态能力,所以对于现有大模型能力来说,对浏览器操作或者APP操作界面的理解完全是走得通的,所以也就“自然而然”了...
Claude computer-use 和 智谱的AutoGLM 目前都在Demo阶段,Claude开放了对应的computer-use的API :
https://docs.anthropic.com/en/docs/build-with-claude/computer-use如果你想体验应用可以参考:
https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo直接安装Dorker部署就行,如果你想看看具体调用实现方式,可以看看
https://github.com/corbt/agent.exe这个项目,如果你跟我一样懒得去具体看代码,可以直接打开cursor帮你通读下,并生成流程图如下(如果有错误不要怪我,怪大模型):
至于智谱的AutoGLM目前还只支持安卓手机,具体还在内测,我提交申请目前还没通过(历史经验告诉我,我这种从来就没有被第一时间通过,有时候我不得不怀疑我的人品问题)
从直观印象中Claude computer-use 和 智谱的AutoGLM 的实现思路其实都是差不多的,那他的实现完全依赖了大模型对现有OS应用的UI视觉理解及推理能力,额外的其他就只需要模拟人类点击就能完成了,这也标志着AI Agent 2.0时代来临!
某种角度上讲这也是根本上改变了游戏规则,会带来一系列的连锁反应,就好像之前我看到的大模型时代的搜索可能会慢慢改变用户习惯,从而进一步改变商业模式等。可能是基于职业病,我看到这个computer-use的时候在安全方向的第一反应,这个可能会改变基于爬虫的风控机制,在现在业务安全方向爬虫衍生的“生态”到目前还是主要重点方向,这类自动化应用也必然带来很多应用出于对核心数据资产等护城河保护目的而来带来的“阻力”。当然在具体的一些攻防方向,可能也会出现一些新的提示词注入攻击的新的应用场景。
还有一点就是我在朋友圈里提到的,到底是谁做的问题,是OS?大模型?应用自己?因为按传统的权限(边界)角度来看,OS层面做可能是做出来的效果是最好用也最方便的,但是从上面提到的“游戏规则”实际上发生变化,换个说法computer-use这种方式在某个角度或者程度上打破了这种传统权限(边界)的理解,对应风险模式也可能会发生对应的改变,所以一切都存在很大的变数~~ 当然对于网络安全研究者来说这种边界的改变可能是需要重新思考的一个方向...
「我多次引用的爱因斯坦名言“不改变思维模式,就无法解决当前的思维模式所创建的问题”的原始场景了,换句话说你遇到的问题是你当前的思维模式导致的,换个维度你这个问题可能压根不存在!」 heige,公众号:黑哥说安全领先一代的技术或早已出现
从AI Agent 1.0到AI Agent 2.0再一次印证了爱因斯坦这句话的威力!
“AI一天,人间一年”,在这段时间除了上面提到的,其实还有不少的“新”东西出来,但是很多人现在还在苦恼的是应用“场景”的寻找,还在期待“超级应用”的诞生,而忽视了大模型时代其实已经来临,是一种“润物细无声”的方式融合到了更多的人的工作生活的场景之中,我其实一直在强调大家需要改变的是思维习惯,全面拥抱大模型,通过不断学习体验,成为改变。黑哥尔说过:“大模型时代,即便是简单的资讯也可能成是一种竞争力”,这个核心其实是一种认知的时间差带来的优势!
比如之前我一直苦口婆心推荐的Cursor,看到我的推荐后,很多人都开始拥抱它,不过可能大部分人还是把它理解为IDE,实际上你可以理解它是一个大模型的客户端,可以做的事情很多不只是编码!Cursor本身的实现也不只是大模型官方API调用,而是Agent、RAG、知识库等应用结合体,所以很多人觉得OpenAI Canvas的这类的出现会导致Cursor的没落,实际上他们两者不完全一样的 ...
我记得在今年9月初还有很同行讲通过大模型在安全方向的应用,比如有自动化开发Poc/Exp,实际上这个算是非常基础的功能,我记得我在2022年底ChatGPT3.5的时代就让它自动写个PocSuite的Poc基本上就可以做到“一键生成”
其实在现在这个时候应该玩点高端点的了,毕竟大模型都进化好几个版本了,所以我想结合上面提到的Cursor做一点新的尝试:
是的这个是利用cursor直接把漏洞分析paper自动化生成了Poc,当然这个也算是比较基础的能力了,估计有人会说这个不算啥,之前有人直接通过CVE描述就生成Poc的尝试,对于这种我就不多说啥了。
当然不只是Poc生成,在代码审计方向,也有很好的应用场景的。说到代码审计方向,这里不得不提下前面我在朋友圈推荐的项目:
https://github.com/protectai/vulnhuntr 非常有意思的一个项目 算是真正意义上的大模型在漏洞挖掘(白盒静态审计)的落地项目 /:strong 详细报告:https://protectai.com/threat-research/vulnhuntr-first-0-day-vulnerabilities
虽然局限性很明显,但是我觉得算是一个真正的落地,至于那些漏洞是不是通过肉眼看出来,还有成本问题,这可能是另外一个话题了。
前面我关注的的方向还有一个就是搜索方向,OpenAI o1发布后CoT有点太火了,有一天突然看到很多自媒体开始吹Kimi:Kimi最新发布的探索版,实现o1的CoT方式。然后我去体验了下:
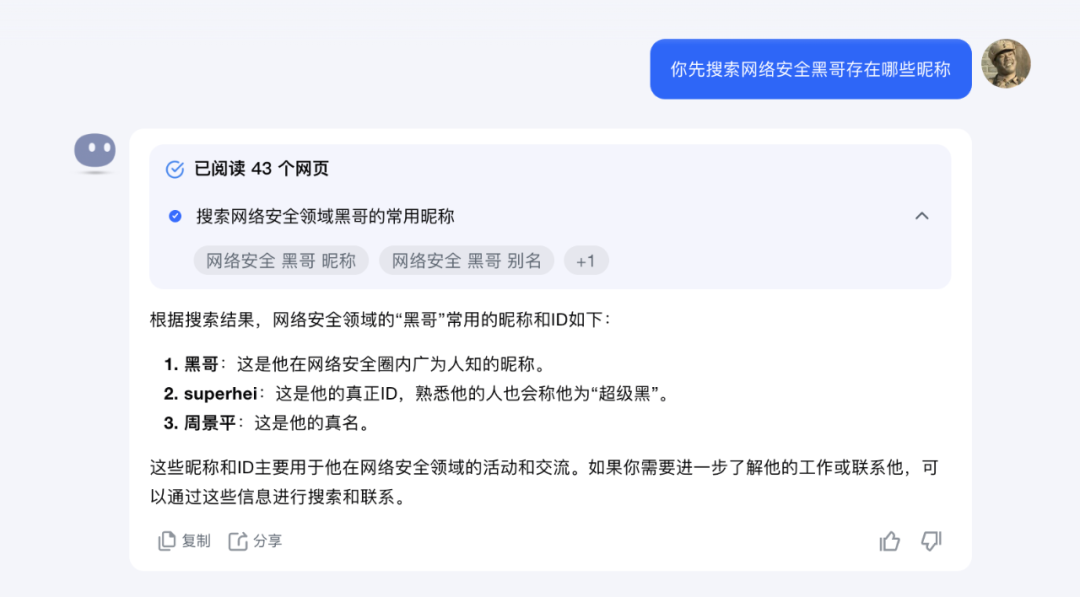
「体验了下Kimi的最新探索版,效果还是不错的,但是要说它是对标OpenAI o1的cot其实是不对的,Kimi这个更像是一个搜索版的工作流,模拟了下人使用搜索的流程,比如我搜索黑哥 然后匹配到周景平 然后继续搜索周景平的信息 最后得到总结答案...」
很可能有人会觉得黑哥太自恋了,每次都先搜索自己ID,其实我是通过这个问题来基本判断这个大模型的数据覆盖度及推理程度的,很好用:),虽然Kimi的探索版不是自媒体吹的那样,但是实际上还是给我很大的启发,因为我之前一直在纠结前美帝NSA的负责人加入OpenAI的目的,其中之一就是在大模型加持下的传统搜索引擎采集的数据在“情报”挖掘获取能力上的蜕变,于是我用Kimi做了个简单尝试:
可惜的是估计是成本的考虑,kimi探索版只支持5次深度搜索,你们可以想象一下前NSA负责人带领团队在OpenAI内部不记成本的各种乱搜 ... 如果再配合NSA的多年积累 ...
最后我想提下让人“惋惜”的项目,Google的 notebooklm 这个项目也是我之前大力推荐的,前面也火了一把,还有媒体称其为Google的ChatGPT时刻到了,但是非常可惜的从我使用到现在,完全感受不到它的改变,我期待的对中文播客的支持一直没看到,因为我一直觉得:
「notebooklm最大启示:大模型打破了语言对人类知识分享交流领域障碍」
我看到关于他们一篇采访后, 感觉更加无力了~
在ChatGPT火起来之初,我还是非常期待Google的爆发的,比较在OpenAI之前都是Google的天下,很可惜这2年来没看到太多的印象深刻的东西,好不容易来了个notebooklm感觉也不受重视,是不是Google在憋大招,从根本上否定现在GenAI的模式?!
还有一个就是腾讯的大模型,腾讯坐拥了优质的公众号数据资源(这里不得不佩服下腾讯对内容数据护城河的敏感度)但是看不到好的模型体验,从公众号的黑哥小马仔(可以通过公众号私信触发)还是前几天发布的ima.copilot https://ima.qq.com/ 给我的感觉是:不管是数据角度、还是应用场景角度都是非常值得期待的,但是核心的问题是大模型本身还差点意思,只能期待后续的进化了~
最后
大模型时代已来,需要进化的是我们!
如有侵权请联系:admin#unsafe.sh