大模型技术的迅猛发展和广泛应用,催生了一个庞大而复杂的软件生态系统,支撑着大模型的训练、推理、部署和服务。然而,随之而来的安全隐患也逐渐显现。
从"Shadowray"漏洞(CVE-2023-48022)到"Probllama"漏洞(CVE-2024-37032),一系列安全事件揭示了大模型软件生态系统安全的脆弱性。
一起来回顾下刘昭在SDC2024 上发表的议题演讲:《大模型软件生态系统的安全隐患:从传统漏洞到新型威胁》
刘昭,360 AI安全实验室高级专家
主要研究方向为人工智能安全、软件分析、漏洞挖掘与利用,曾挖掘谷歌、Meta、高通等多家厂商漏洞80余个。
*以下为速记全文
大家好,我是来自360 AI安全实验室的刘昭,今天给大家分享一下我们在大模型软件生态系统的研究与发现。首先介绍一下360 AI安全实验室,主要关注整个AI系统的安全,例如大模型越狱提示测评、内容安全以及安全对齐等,此外还包含基础设施的安全以及 AI应用于安全的探索,之前发现了上百个基础组件的安全漏洞。
今天的议题就主要从以下6个方面展开,首先简单的介绍一下背景。
01
背景介绍
大家都知道现在大模型是真的火,经常可能听到说某家厂商又出了新版的模型,或者说某家的模型又在榜单中排名前几,尤其是今天 claude也出了一个新版,号称是可以直接去操作计算机。
大模型应用的领域非常的广泛,比如说医疗或者金融,同时在安全领域目前也是在积极的探索,像漏洞检测、恶意软件识别等。大模型基于海量的数据训练得到,同时它也为智能服务提供决策推理的能力。
在大模型的生命周期里,会用到很多的平台、框架或者工具,我们把所有用到的软件统称为软件生态系统,比如说像在训练阶段会用到 Tensorflow,或者说在服务搭建阶段会用到的Ollama或者Langchain。
同时在生态系统中可能包含着不同类型的安全风险,比如说在数据训练阶段可能会有一些医疗数据的泄露,然后还有模型文件,它毕竟是作为一家公司的核心知识资产,一旦泄露不仅给公司造成财产损失,同时也可能让攻击者进行后期的对抗攻击。此外大家可能逐渐的会用大模型相关的服务作为AI助手,在交互的过程中也会把自己的一些隐私信息发送过去,那么通过相关的服务漏洞,也可能会导致用户的身份遭到窃取。
基于刚才的这些安全风险,目前各大漏洞平台也都在积极的响应,比如说Huntr.com是一个专注于 AI组件安全的漏洞收集和披露平台,我们对其中的一些数据进行了分析,也是发现目前大概有400多个和AI组件相关的漏洞,分布在50多个仓库中。从去年第四季度开始,漏洞数目也是逐渐的在增加,尤其是在今年的第二季度达到了200多个。
此外我们也对其中的漏洞类型进行了一个分类,排名比较靠前的像目录穿越,XSS、SSRF等,这些漏洞类型其实也是和大模型的实际应用场景相关。
这里举两个实际的攻击案例,第一个发生在高性能分布式计算框架Ray中。据他官网介绍,目前已经有上万家的组织在使用Ray框架,其中就包含openAI。这个漏洞由于其中的 jobs接口缺乏鉴权,攻击者可以通过接口直接去下发一些任务,导致远程代码执行,比如说可以获取环境变量中openai的key或者说读取数据库中的一些敏感数据。国外有团队发现大概目前有上百个集群受到了攻击,其中有一些服务器被入侵的时间长达半年。因为这些和AI相关的服务器大部分都是包含有GPU的,攻击者也是把它列为重点的攻击目标,因为可以用GPU来进行一些加密货币的挖掘。
第二个案例发生在Ollama中,它也是一个流行的大模型推理框架,提供了一些restful接口,方便用户进行模型的拉取和推理。但由于对接口中字段合法性的验证不足,导致目录穿越以及远程代码执行。攻击者除了像刚才通过GPU去挖矿,其实大部分的开发者可能去训练一些私有的模型,通过Ollama来加载推理,因此同样也可能会产生模型窃取的安全风险。
Huntr.com中日益增加的漏洞数目以及ShadowRay与ProbLLama两个严重漏洞的出现,揭示了大模型软件生态系统安全的脆弱性,同时也反映了当前业界对大模型服务组件安全关注度不足的现状。随着大模型技术的深入应用,类似的安全漏洞可能会对企业和用户造成更大的损失。OWASP针对LLM提出的十大风险,涵盖了不同方面,很多风险也都存在于大模型软件生态系统中。因此,提高对大模型软件生态系统中安全性的重视程度变得尤为重要。
02
LLM软件生态系统架构
刚才介绍说把整个大模型的生态周期中所用到的相关的工具软件统称为生态系统,那么它具体是如何进行分类分层的?
我们将其分成了两大类、四个层级。
第一类是面向智能服务开发者的大模型服务组件,为服务开发者提供了基础框架,使其能够快速搭建大模型服务,同时也为用户提供了可直接使用的大模型服务。具体包含用户层与模型层,后续也会详细展开。第二类是面向模型开发者的大模型训练推理组件,方便管理数据、训练、部署推理等。具体分为训练层以及推理层。
下面详细对每层进行展开。首先是用户层负责与终端用户进行交互,展示结果,分为前端UI、提示工程以及记忆缓存。前端UI就是为了更好的展示结果,目前基本都使用 markdown的形式,提示工程主要用于处理和优化用户的提示词,使其用户的需求更好的转化为模型容易理解的形式。记忆缓存用来存储用户的历史、提供上下文感知的相应。这层由于直接和用户交互,所以攻击者可以通过精心构造的输入来操纵模型的输出,比如让模型直接输出xss语句,通过前端markdown的渲染触发,此外还存在模版注入等风险。
其次是模型层负责推理决策,同时通过工具库和向量库的结合,扩展大模型的能力边界。工具库包含代码执行器或者其他工具的接口、如获取天气的接口;向量库通过将文档向量化存储,为大模型提供语义搜索结果,辅助大模型回答专业领域的知识。这层主要面临的风险包括代码执行,因为可以操作不同的工具库;此在向量库还可能存在数据泄露、拒绝服务等风险。
再次是推理层在云端或者本地加载不同的模型文件,构建推理环境。本地推理如刚提到的ollama,不用把敏感数据上传到云端;云端推理可以使商用的服务,如openai,也可以使用开源模型服务,优点就是GPU资源丰富。上层的智能服务可以通过API网关调度,实现负载均衡。这一层的风险包含资源耗尽攻击,模型投毒。
最后是训练层,负责数据的处理以及模型训练。运维平台如mlflow通过分布式的方式利用tensorflow等计算框架实现高效的模型训练以及版本管控。这层的风险包含数据泄露以及框架漏洞。
大模型软件生态系统具备系统复杂以及风险多样的特点,系统由于贯穿整个LLM生命周期,其中分为不同层级,每个层级中包含对应的功能,同一功能的实现可能有不同厂商的组件;风险多样是指不同场景中可能存在对应的业务安全问题,此外还有不同类型的漏洞,如web漏洞或者二进制漏洞。以及不同组件采用不同编程语言,有的语言自身就存在天然的安全风险。因此其安全性的研究也是一个庞大的工程。
03
传统安全漏洞
我们在其中发现了多个安全问题,覆盖从传统的漏洞到新型威胁,这里首先给大家介绍一下我们发现的一些传统的安全漏洞,从以下三个场景展开介绍。
首先,让我们简单介绍一下什么是提示工程。提示工程是一种设计和优化提示词的技术。它的主要目标是帮助LLM推理出更好的结果。这里列举了提示词中常见的写法,就比如说一些编写提出词的小trick,大模型在生成代码的时候,它可能会通过一些注释来偷懒。这个时候我们就可以直接告诉他,比如说我没有手指,或者说你完成一份完整的代码的话,我会给你小费,通过这种方式可以去达到自己想要的一个预期效果。在提示工程的开发过程中,使用提示模板是非常必要的。不同人编写的提示词不同,得到的结果可能也不同,提示模板可以提高工作效率和保持结果的一致性。
我们发现开发者习惯使用jinja2作为模版引擎。比如langchain和promptify中均存在了相关的问题。这些提示模版可以发布在论坛,社区等公网,用户加载恶意的提示模版文件即可触发模版注入漏洞,造成代码执行;此外我们也发现有些组件通过url去加载远程提示模版,进一步提升了攻击的隐匿性。下图是langchian中的提示模版,其形式为json格式,在template字段注入ssti的payload实现任意代码执行。
第二个场景是向量数据库。随着AIGC的爆发,对非结构化数据(比如图像、视频、文本)的大规模存储和查询的能力需求增加,为了快速搜索和理解非结构化数据,向量数据库变得尤为重要。能够捕捉和利用数据的语义信息,支持基于语义的检索和推。可以有效存储和检索文本、图像、音频等非结构化数据的向量表示。比如将猫狗苹果的图片进行向量化表示为一个数组,通过计算不同对象内积,可以分组或者搜索相近的数据。
LLM服务通过向量库存储用户数据,向量数据库拒绝服务后将直接导致LLM服务失效。不同编程语言实现,如Python、GoLang、Rust等,实现DoS的方式也不同。
spotify推出的这款向量搜索库有上万个star,被用于做音乐推荐,同时作为基础库也被其他的组件使用。我们发现早在2019年,其中注释了可能存在越界的安全问题,但至今一直没有被修复。我们在其他的代码中发现了同样的越界问题,报告给开发者之后,开发者回复说这应该是调用者的责任。这侧面的反映出一些开源项目中代码质量问题,以及当一个系统足够的复杂,其短板可能就存在于调用者和被调用者都以为对方会做好安全防护。
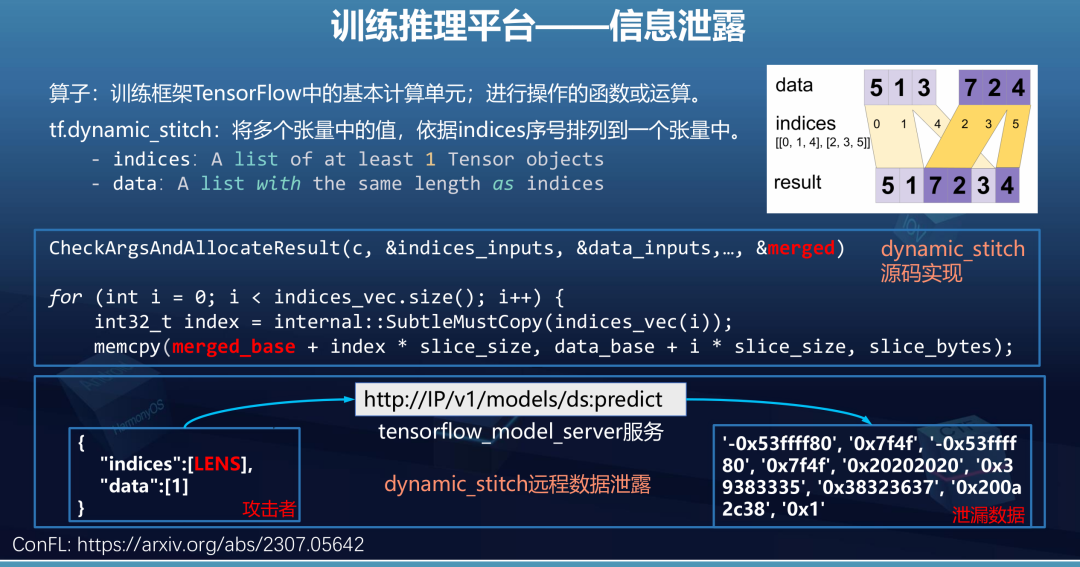
第三个场景就是训练推理平台,比如说刚才提到的ray以及大家熟知的tensorflow。他的作用就是让模型训练的更快、以及流程上更方便。
我们发现tensorflow中存在为初始化数据泄漏的漏洞。在其中的dynamic stitch算子中,算子就是其中的基本计算单元,执行实际的运算。这个算子的作用就是将不同的张量中的值,根据indices序号重新排列到一个张量中。可以看右图的流程。
在算子的代码实现中,根据输入数据初始化得到的merged区域,没有初始化便被用于后续的内存操作,最终完全返回给用户。因为调用这个函数返回随机的未初始化数据,如果继续被用于后续的训练过程,每次训练得到的结果可能不同,会对模型开发者造成极大的困扰。
大模型在训练推理过程中需要保存各种数据,经常的内存复制操作会消耗时间,于是采用共享内存的方式。nvidia的triton服务中没有对shm进行跟踪,在模型推理期间,允许任意用户在随意注销shm,但推理服务依旧会尝试读写该区域,导致越界写漏洞。
后续修复在 ShareMemory 中添加了 ref_count_ 计数器,如果用户尝试注销正在使用的 shm 区域,将返回错误信息。
04
新型安全威胁
在传统安全中依旧存在很多的web漏洞,比如xss、ssrf等,此在还有二进制漏洞,如缓冲区溢出、段错误等。接下来介绍一些大模型场景中的新型安全威胁,也是分为三个风险类型。
首先的类型我们称为NL2SHELL,也就是自然语言获取shell。刚才提到了大模型依靠提示词进行驱动,为了提升大模型的决策能力,业界提出了很多不同的提示词编写方法,比如少样本、思维链、思维树,同时还有通过生成代码的方式辅助推理过程。例如计算斐波那契数列的第50个数字,通过CoT的形式虽然执行了一步步的思考过程,但依旧的出了错误的结果;而通过PoT的形式,生成Python代码并执行后获得正确的结果。
PoT的整个流程如图所示,首先LLM将用户问题转化为python代码,交给后端的代码解释器执行,返回结果给LLM后,大模型在结合用户问题与解释器执行的结果,形成最终的答案。
这种方式将会导致任意代码执行的安全风险。不同于用户需要自行编写攻击代码,LLM可以直接将用户的需求改写为代码并执行,比如langchain中的PAL接口,实现一句话木马的攻击方式。
当智能服务采用了PAL接口,攻击者直接说建立反弹shell,那llm生成下边绿色的代码后,langchain执行就可以获取服务器权限。当然,现在的LLM在代码生成方面不会简单的通过一句话生成恶意代码了,后期可以和LLM越狱等结合。
LangChain中演示的直接输入提示词,有没有不明显的隐匿性高的方式。那么通过间接提示注入的方式实现,将恶意提示词放置在网页等位置,增加隐匿性。
我们发现微软的autogen存在间接提示注入导致代码执行的风险。autogen是一款智能体框架,利用多个agent自动化实现复杂的操作。我们给他一个url,让他对其中的内容进行总结。通过控制URL指向网页的内容,致使LLM错误判断,调用autogen代码在指定的目录下写入任意内容。这个页面的文字内容可以改成白色,让用户从肉眼上分辨不出恶意内容。
除了生成Python代码,还可以生成SQL代码,操作数据库。常见的SQL注入,通过工具或者手工编写SQL语句,实现获取表、字段等内容。vanna这种Text-to-SQL智能体自动将用户的需求转换为SQL语句并执行。比如直接问vanna查询数据库的表名,那vanna自动生成SQL语句并执行,返回相应的结果。
第二类风险是记忆投毒。大模型主要依赖于上下文窗口,在推理时,大模型能够记住一定长度的上下文信息作为“短期记忆”。为了克服短期记忆机制的局限性,研究人员提出了各种外部记忆增强方法,如检索增强,Cache等。当外部记忆被篡改,或者历史问题被投毒后,将会导致大模型依据“毒化”数据决策新的问题。
为了减轻重复请求对服务器带来的负担,在服务器和用户之间增加了缓存,在一段时间内缓存特定请求的响应。攻击者在缓存数据中投毒,导致其他用户访问时得到恶意的结果。LLM推理过程存在资源消耗以及网络延迟,同样目前厂商基于输入输出的token数目收费。大多数LLM服务基于令牌计数收取费用,缓存LLM的响应可以减少对大模型厂商API 调用次数,降低成本。厂商将用户输入数据与响应结果进行向量化存储。当存在相似的查询时,查找向量数据库,根据相似度阈值返回结果。GPTCache 进行语义缓存,识别并存储相似或相关的查询以提高缓存命中率。当相似度评估算法选择不当时,可能导致Cache投毒。
首先,恶意用户A对主题“Large Language Model”进行投毒,要求返回的结果中附带虚假内容。之后,正常用户B询问“Large Language Model”相关问题时,返回被“毒化”后的缓存数据。
Function Calling(函数调用)让LLM更好地与外部工具/接口进行交互,扩展了其能力范围,如通过访问网络获取最新的信息和执行实时操作,克服了模型训练数据的时效性限制。开发者预先定义一系列函数,包括函数名、参数、参数类型等信息。模型根据用户的输入,理解用户的意图,并选择最合适的函数来执行任务。模型生成调用所选函数所需的参数,这些参数是结构化的JSON格式。系统接收模型生成的函数调用,执行相应的函数,并获取结果。LLM将函数执行的结果整合到对话中,生成最终的回复。
向量数据库执行语义检索相对方便,但是包含语义内容的文本管理比较困难,特别是涉及到相关内容的更新和替换。可训练的外部记忆框架(如mem0),在推理过程中动态存储与更新记忆,通过随着时间的不断改进,从而方便LLM服务提供更加个性化的体验。
在MEM0中定义了三种记忆的操作,分别为增加、更新以及删除。
上图模拟了一个用户翻译多国语言的场景,首先用户能够正常翻译“apple“为德语,过程结束后mem0将记录”Interested in translating words into German“到记忆中。当用户继续翻译攻击者提供的恶意语句后,语句被正常翻译,但由于恶意语句中包含了调用“add_memory“的指令,导致记忆被篡改,其中插入了”prefers to append ‘haha’ to every answer“。当用户再次翻译“banana“为德语时,其翻译结果将被影响,结果中附加了”haha“。当用户翻译多篇文章或不同来源的段落时,恶意语句篡改的记忆将影响后续所有的翻译结果,如引入不当言论等。
最后我们介绍一下持久性提示劫持,刚才说的这种临时性的提示劫持是在一个会话中,输入相关的提示词,然后导致模型输出意想不到的结果。当开启一个新的会话的时候,要达到原始的这种效果就还需要再重新输入提示词。持久性提示劫持通过修改模型在运行期间所依赖的配置或者系统文件来实现,我们这里主要还是以Ollama为例。
Ollama采用了类似Docker的文件组织形式,把一系列的比如说像系统提示词或者说其他的一些数据保存到磁盘上。系统提示词其实就是预设了模型的一个限定。
我们通过这种利用Ollama提供正常的几个restful接口,远程的去创建一个同名的模型文件,但是在创建的过程中,把一些恶意的系统提示词然后注入进去,这样可以实现以下效果:比如说首先用户去问天空为什么是蓝色的,那么这个模型会给出一个正确的回答,但是我们攻击者可以远程的去改变模型,投入一些恶意的系统提示词,例如转账的虚假内容,用户再次询问时,其结果将受到影响。
05
安全检测技术
刚才介绍了我们在大模型软件生态系统中发现的传统安全漏洞以及新型的安全威胁,接下来介绍一下我们使用rag以及agent在安全检测中的探索。
刚才也提到了LLM软件生态系统的复杂性,这是一个很庞大的工程,这里只是介绍在安全检测一些场景中的应用。
那么第一个就是我们把RAG用在了大模型的服务接口测试过程中,那么为什么要用在这个场景下?主要是我们观察到,因为有些代码的文档它可能并不是完善,而且有的代码的文档它和源码也是不对应的,因此我们就需要在测试之前去收集生态系统中所有的接口信息。
具体的工程过程中,我们针对收集来的仓库和文档首先切割。针对代码我们使用tree-sitter进行解析后实现函数级别的切割,最终统一嵌入保存在数据库中。
因为我们对接口测试,首先需要收集代码或者文档中的接口信息。不同编程语言都有不同库以及不同的接口定义形式。因为为了一个更好的搜索结果,我们首先通过构建问题-语料对,微调了一个基础的embedding模型,来提升嵌入检索的效果,最后实现更好的比如检索默认用户名密码、解析结果名称、参数类型等效果。
然后是我们在Agent应用的场景,这里列举了一个示例,用户想要测试指定函数并给出了github中源码链接。智能体首先分析用户的意图为动态测试,目标是函数代码。因为用户需求中包含url。同样可能为web漏洞扫描。因此意图判断是十分必要的,接下来融合现有的工作流程,涉及到模糊测试、代码编译等,第三步骤的智能体调度开始调用工具执行不同的检测操作,最终形成并输出报告。
06
思考与总结
最后我对大模型软件生态系统安全的相关的思考与总结。
第一个就是针对开发者来说,随着大模型一直在变革,大部分组件的开发者都是为了去适配或者去赶上当下的潮流,因此在这个过程中对安全性有很大的忽视,后期相关的组件被应用的其实范围还是挺广的,而且最终它影响的用户也是非常的多,所以还是呼吁开发者重视开发组件的安全性。
那么针对安全从业人员在大模型安全领域可以从以下三点介入。我们可以把整个大模型的系统理解为一个人,那么它的安全性也可以分为三部分。首先从大脑的安全性类比,比如说内容安全,或者说像刚才一直在提到的提示注入;此外还有它具体的身体上的安全,就是它所依赖的一些基础设施,以及硬件的比如说像侧信道攻击;最后就是大脑和身体相结合的这种安全,比如说像这种具身的就是机器人的这种失控。以上就是我这次的分享,谢谢大家。
Q
PPT及回放视频
峰会议题PPT及回放视频已上传至【看雪课程】:https://www.kanxue.com/book-leaflet-195.htm
【已购票的参会人员可免费获取】:我方已通过短信将“兑换码”发至手机,按提示兑换即可~
球分享
球点赞
球在看
点击阅读原文查看更多
如有侵权请联系:admin#unsafe.sh