2024-11-13 06:26:58 Author: hackernoon.com(查看原文) 阅读量:6 收藏
Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
Table of Links
3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
4.2. Main results
Open-vocabulary semantic segmentation. As demonstrated in Tab. 1, our study presents a comprehensive comparison of our Uni-OVSeg against previous works across a range of benchmarks. These include ADE20K (encompassing both 150 and 847 class variants), PASCAL Context (459 and 59 class variants), PASCAL VOC (with 20 and 21 class categories), and Cityscapes. Compared to weakly-supervised methods, Uni-OVSeg exhibits remarkable performance improvements across all evaluated datasets. Specifically, in the more challenging datasets of PASCAL Context-459, Uni-OVSeg not only surpasses its weakly-supervised counterparts but also outperforms the cutting-edge fully-supervised methods, e.g., FC-CLIP. This is indicative of Uni-OVSeg’s superior capability in categorizing a diverse array of semantic classes. Furthermore, in the PASCAL VOC benchmarks (20 and 21 classes), Uni-OVSeg demonstrates a substantial enhancement over state-of-the-art weakly-supervised methods, achieving improvements of 18.3% and 12.2% mIoU, respectively, which demonstrates our Uni-OVSeg captures fine-grained spatial structures. These results elevate the practical applicability of weakly-supervised open-vocabulary segmentation to new heights.
Open-vocabulary panoptic segmentation. For openvocabulary panoptic segmentation, we zero-shot evaluate our model on the COCO, ADE20K, and Cityscapes datasets, shown in Tab. 2. Existing weakly-supervised methods only use text supervision, which causes a challenge to discriminate different instances with the same semantic class. To the best of our knowledge, we are the first to learn open-vocabulary panoptic segmentation with weak supervision. Compared to unsupervised methods, we obviously outperform U2Seg by 1.9% PQ, 1.5%SQ, and 4.4% RQ on COCO datasets. Unfortunately, our used image-mask pairs contain multiple granularity masks, such as object-wise and part-wise masks, which is different with the panoptic segmentation datasets. This discrepancy leads to a number of false positive results, limiting our performance.
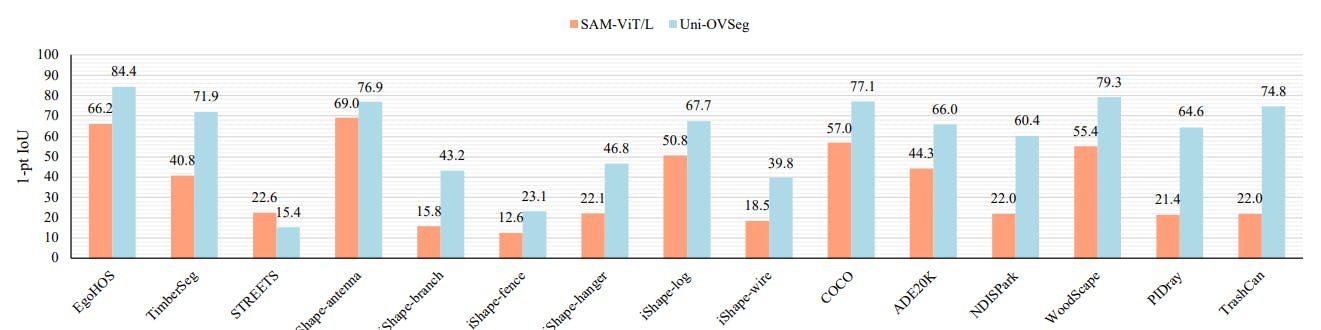
Promptable segmentation. To evaluate the segmentation efficacy of Uni-OVSeg in scenarios involving interactive point and box prompts, we conduct comparative analyses with the SAM-ViT/L model across a range of datasets from diverse domains. For visual prompts, we implement a uniform 20×20 point grid as the interactive point prompt and utilise the actual bounding boxes as box prompts. The segmentation performance is measured using the 1-pt IoU (Oracle) metric across all datasets. The results, as demonstrated in Fig. 3, indicate that Uni-OVSeg exceeds SAM in most

![Figure 3. Point-promptable segmentation performance. We compare our method with SAM-ViT/L [34] on a wide range of datasets. Given a 20 × 20 point grid as visual prompt, we select the output masks with max IoU by calculating the IoU with the ground-truth masks. We report 1-pt IoU for all datasets.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-py930m7.png?auto=format&fit=max&w=3840)
datasets when employing point and box prompts. In particular, Uni-OVSeg significantly surpasses SAM in terms of IoU by 31.1%, 20.1%, and 43.2% on the TimberSeg, COCO instance, and PIDray datasets, respectively. Additionally, we provide a visualisation of the segmentation results of both SAM and Uni-OVSeg in Fig. 4. The visualisation reveals that SAM tends to miss larger masks and erroneously categorise areas with unclear boundaries. In contrast, UniOVSeg demonstrates exceptional precision in segmenting objects of varying scales and different stuff. More experimental results are visualisation can be found in the Appendix B and C.
如有侵权请联系:admin#unsafe.sh