Authors:
(1) Yuwei Guo, The Chinese University of Hong Kong;
(2) Ceyuan Yang, Shanghai Artificial Intelligence Laboratory with Corresponding Author;
(3) Anyi Rao, Stanford University;
(4) Zhengyang Liang, Shanghai Artificial Intelligence Laboratory;
(5) Yaohui Wang, Shanghai Artificial Intelligence Laboratory;
(6) Yu Qiao, Shanghai Artificial Intelligence Laboratory;
(7) Maneesh Agrawala, Stanford University;
(8) Dahua Lin, Shanghai Artificial Intelligence Laboratory;
(9) Bo Dai, The Chinese University of Hong Kong and The Chinese University of Hong Kong.
Table of Links
- AnimateDiff
4.1 Alleviate Negative Effects from Training Data with Domain Adapter
4.2 Learn Motion Priors with Motion Module
4.3 Adapt to New Motion Patterns with MotionLora
5 Experiments and 5.1 Qualitative Results
8 Reproducibility Statement, Acknowledgement and References
3 PRELIMINARY
We introduce the preliminary of Stable Diffusion (Rombach et al., 2022), the base T2I model used in our work, and Low-Rank Adaptation (LoRA) (Hu et al., 2021), which helps understand the domain adapter (Sec. 4.1) and MotionLoRA (Sec. 4.3) in AnimateDiff.

4 ANIMATEDIFF
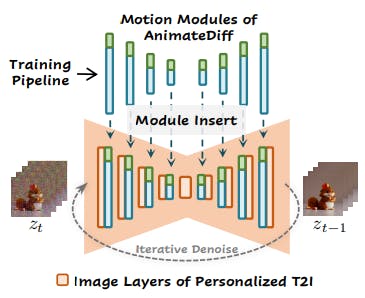
This core of our method is learning transferable motion priors from video data, which can be applied to personalized T2Is without specific tuning. As shown in Fig. 2, at inference time, our motion module (blue) and the optional MotionLoRA (green) can be directly inserted into a personalized T2I to constitute the animation generator, which subsequently generates animations via an iterative denoising process.
We achieve this by training three components of AnimateDiff, namely domain adapter, motion module, and MotionLoRA. The domain adapter in Sec. 4.1 is only used in the training to alleviate the negative effects caused by the visual distribution gap between the base T2I pre-training data and our video training data; the motion module in Sec. 4.2 is for learning the motion priors; and the MotionLoRA in Sec. 4.3, which is optional in the case of general animation, is for adapting pre-trained motion modules to new motion patterns. Sec.4.4 elaborates on the training (Fig. 3) and inference of AnimateDiff.

如有侵权请联系:admin#unsafe.sh