2024-11-22 01:53:0 Author: googleprojectzero.blogspot.com(查看原文) 阅读量:5 收藏
Posted by Ivan Fratric, Google Project Zero
Recently, one of the projects I was involved in had to do with video decoding on Apple platforms, specifically AV1 decoding. On Apple devices that support AV1 video format (starting from Apple A17 iOS / M3 macOS), decoding is done in hardware. However, despite this, during decoding, a large part of the AV1 format parsing happens in software, inside the kernel, more specifically inside the AppleAVD kernel extension (or at least, that used to be the case in macOS 14/ iOS 17). As fuzzing is one of the techniques we employ regularly, the question of how to effectively fuzz this code inevitably came up.
It should be noted that I wasn’t the first person to look into the problem of Apple kernel extension fuzzing, so before going into the details of my approach, other projects in this space should be mentioned.
In the Fairplay research project, @pwn0rz utilized a custom loader to load the kernel extension into userspace. A coworker tried to run this code on the current AppleAVD extension, however it didn’t work for them (at least not out of the box) so we didn’t end up using it. It should be noted here that my approach also loads the kernel code into userspace, albeit in a more lightweight way.
In the Cinema time! presentation at Hexacon 2022, Andrey Labunets and Nikita Tarakanov presented their approach for fuzzing AppleAVD where the decompiled code was first extracted using IDA and then rebuilt. I used this approach in the past in some more constrained scenarios, however the decompiled code from IDA is not perfect and manual fixing was often required (such as, for example, when IDA would get the stack layout of a function incorrectly).
In the KextFuzz project, Tingting Yin with the co-authors statically instrumented kernel extensions by replacing pointer authentication instructions with a jump to a coverage-collecting trampoline, which results in a partial coverage.
Most recently, the Pishi project by Meysam Firouzi was released just before this research. The project statically instruments kernel extension code by using Ghidra to identify all basic blocks, and then replacing one instruction from each basic block with a branch to a dedicated trampoline. The trampoline records the coverage, executes the replaced instruction and jumps back to the address of the next instruction. This was reported to run on a real device.
Given the existence of these other projects, it is worth saying that my goal was not to create necessarily the “best” method for kernel extension fuzzing, but what for me was the simplest (if we don’t count the underlying complexity of the off-the shelf tools being used). In short, my approach, that will be discussed in detail in other sections, was
- Load AppleAVD extension or full kernelcache into IDA
- Rebase the module to an address that can be reliably allocated in userspace
- Export raw memory using an IDA Python script
- Load exported bytes using custom loader
- Use custom TinyInst module to hook and instrument the extension
- Use Jackalope for fuzzing
All the project code can be found here. Various components will be explained in more detail throughout the rest of the blog post.
Normally, on macOS, kernel extensions are packaged inside “kernel collections” files that serve as containers for multiple extensions. At first OS boot (and whenever something is changed with regards to kernel extensions), the kernel extensions needed by the machine are repackaged into what is called the “kernel cache” (kernelcache file on the filesystem). Kernel extensions can be extracted from these caches and collections, but existing tooling can’t really produce individual .dylib files that can be loaded into userspace and run without issues.
However, reverse engineering tooling, specifically IDA Pro which I used in this research, comes with a surprisingly good loader for Apple kernel cache. I haven’t tried how other reverse engineering tools compare, but if they are comparable and someone would like to contribute to the project, I would gladly accept export scripts for these other tools.
So, instead of writing our own loader, we can simply piggyback on IDA’s. The idea is simple:
- we let IDA load the kernel extension we want (or even the entire kernelcache)
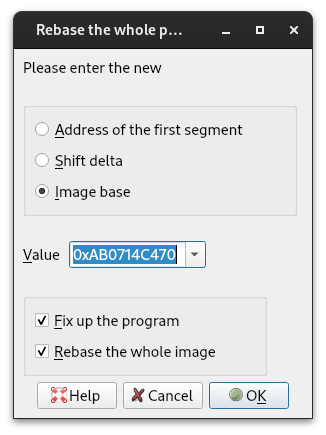
- we use IDA to rebase the code so it’s in memory range that is mappable in userspace (see image)
- using a simple IDA Python script, we export for each memory segment its start address, end address, protection flags and raw bytes
- optionally, we can also, using the same script, export all the symbol names and the corresponding addresses so we can later refer to symbols by name
The following image shows rebasing of the kernel extension. This functionality is accessible in IDA via Edit->Segments->Rebase program… menu. When choosing the new base address, it is convenient to only change the high bits which makes it easy to manually convert rebased to original addresses and vice versa when needed. In the example below the image base was changed from 0xFFFFFE000714C470 to 0xAB0714C470.

Figure 1: Rebasing the extension
The IDA script for exporting the data can be found here. You can run it using the following commands in IDA:
sys.path.append('/directory/containing/export/script')
import segexport
segexport.export('/path/to/output/file)
Loading the exported data should now be only the matter of memory mapping the correct addresses and copying the corresponding data from the exported file. You can see it in the load() function here.
However, since we are now loading and running kernel code in userspace, there will be functions that won’t run well or that we would want to change. One example for this are the kernel allocator functions that we’ll want to replace with the system malloc.
One way of replacing these functions would be to rewrite the prolog of each function we want to replace with a jump to its replacement. However, since we will later be using TinyInst to extract code coverage, there is a simpler way. We will simply write a breakpoint instruction to each function we want to replace. Since TinyInst is (among other things) a debugger, it will catch each of these breakpoints and, from the TinyInst process, we can replace the instruction pointer with the address of the corresponding replacement function. More details on this can be found in the next section.
Besides replacing the memory allocation functions, logging functions etc., we will also need to replace all functions that interact with the hardware that we can’t access from userspace (or, in our case, that isn’t even present on the machine). In the case of AV1 parsing code in the AppleAVD kernel extension, a function called AppleAVD::sendCommandToCommandGate gets called, which I assume is meant to communicate with the decoding hardware. Thus, as a part of the harness, this function was replaced with a function that always returns 0 (success).
The final code of the AV1 harness code can be found here. It can be compiled as
clang++ loader.cpp avdharness.cpp -oloader
and might need some additional entitlements to run which can be applied with
codesign --entitlements entitlements.txt -f -s - ./loader
Note that, in the harness code, although I tried to rely on symbol names instead of hardcoded offsets wherever possible, it still contains some struct offsets. This version of the harness was based on macos 14.5 kernel, which was the most recent OS version at the time the loader was written.
This section explains the custom TinyInst module that accompanies the loader (and is required for the correct functioning of the loader). This code doesn’t contain anything specific for a particular kernel extension and thus can be reused as is. If you are not interested in how it works or writing custom TinyInst modules, then you can skip this section.
Firstly, since we will want to extract code coverage for the purposes of fuzzing, we will base our custom module on LiteCov, the “default” TinyInst module for code coverage:
class AVDInst : public LiteCov {
…
};
Secondly, we need a way for our custom loader to communicate with the TinyInst module
- It needs to tell TinyInst which functions in the kext should be replaced with which replacement functions.
- It needs to tell TinyInst where the kext was loaded so that TinyInst can instrument it.
While TinyInst provides an API for function hooking that we could use here, there is also a more direct (albeit, also more low-level) way. From our loader, we will simply call a function at some hardcoded non-mapped address. This will, once again, cause an exception that TinyInst (being a debugger) will catch, read the parameters from registers, do the required action and “return” (by replacing the instruction pointer with the value inside the link register). The loader uses the hardcoded address 0x747265706C616365 to register a replacement and 0x747265706C616366 to tell TinyInst about the address range to instrument:
#define TINYINST_REGISTER_REPLACEMENT 0x747265706C616365
#define TINYINST_CUSTOM_INSTRUMENT 0x747265706C616366
We can catch those in the exception handler of our custom module
bool AVDInst::OnException(Exception *exception_record) {
…
if(exception_address == TINYINST_REGISTER_REPLACEMENT) {
RegisterReplacementHook();
return true;
}
if(exception_address == TINYINST_CUSTOM_INSTRUMENT) {
InstrumentCustomRange();
return true;
}
…
}
and then read the parameters and do the required action
void AVDInst::RegisterReplacementHook() {
uint64_t original_address = GetRegister(X0);
uint64_t replacement_address = GetRegister(X1);
redirects[original_address] = replacement_address;
SetRegister(ARCH_PC, GetRegister(LR));
}
void AVDInst::InstrumentCustomRange() {
uint64_t min_address = GetRegister(X0);
uint64_t max_address = GetRegister(X1);
InstrumentAddressRange("__custom_range__", min_address, max_address);
SetRegister(ARCH_PC, GetRegister(LR));
}
Where InstrumentAddressRange is a recently added TinyInst function that will instrument all code between addresses given in its parameters. “__custom_range__” is simply a name that we give to this region of memory so we can differentiate between multiple instrumented modules (if there are more than one).
Next, TinInst needs to perform the actual function replacements. As explained above, this can be done in the exception handler of our module.
auto iter = redirects.find(exception_address);
if(iter != redirects.end()) {
// printf("Redirecting...\n");
SetRegister(ARCH_PC, iter->second);
return true;
}
This is mostly sufficient for running the kernel extension without instrumenting it (e.g. to collect coverage). However, if we also want to instrument the extension, then the process of instrumentation involves rewriting the extension code in another location and inserting e.g. additional instructions to record coverage. The consequence of this is that our breakpoint instructions (that we inserted for the purpose of redirects) will be rewritten at different addresses. We need to make TinyInst aware of this (as a side note, TinyInst Hook API does this under the hood, but it wasn’t used in this module). We can do this in the InstrumentInstruction function which gets called for every instruction as it’s being instrumented:
InstructionResult AVDInst::InstrumentInstruction(ModuleInfo *module,
Instruction& inst,
size_t bb_address,
size_t instruction_address)
{
auto iter = redirects.find(instruction_address);
if(iter != redirects.end()) {
instrumented_redirects[assembler_->Breakpoint(module)] = iter->second;
return INST_STOPBB;
}
return LiteCov::InstrumentInstruction(module, inst, bb_address, instruction_address);
}
The INST_STOPBB return value tells TinyInst to stop processing the current basic blocks. Since on breakpoints/redirects, we redirect the execution to another function, no other instructions from the same basic block ever get executed and are thus unneeded.
After this, we now know the addresses of breakpoints (and the corresponding replacements) in both instrumented and non-instrumented code. The final exception handler of our custom module looks like this:
bool AVDInst::OnException(Exception *exception_record) {
size_t exception_address;
if(exception_record->type == BREAKPOINT)
{
exception_address = (size_t)exception_record->ip;
} else if(exception_record->type == ACCESS_VIOLATION) {
exception_address = (size_t)exception_record->access_address;
} else {
return LiteCov::OnException(exception_record);
}
if(exception_address == TINYINST_REGISTER_REPLACEMENT) {
RegisterReplacementHook();
return true;
}
if(exception_address == TINYINST_CUSTOM_INSTRUMENT) {
InstrumentCustomRange();
return true;
}
auto iter = redirects.find(exception_address);
if(iter != redirects.end()) {
// printf("Redirecting...\n");
SetRegister(ARCH_PC, iter->second);
return true;
}
iter = instrumented_redirects.find(exception_address);
if(iter != instrumented_redirects.end()) {
// printf("Redirecting...\n");
SetRegister(ARCH_PC, iter->second);
return true;
}
return LiteCov::OnException(exception_record);
}
The entire code, with all the housekeeping functions can be found here.
Once our custom module is ready, we still need to make sure TinyInst and Jackalope will use this module instead of the default LiteCov module. See the appropriate patches for TinyInst and Jackalope.
Our harness should now run correctly under TinyInst, both without and with coverage instrumentation:
./Jackalope/build/TinyInst/Release/litecov -- ./loader avd_rebased.dat -f <sample>
Where avd_rebased.dat contains the kernel extension code exported from IDA. We can also add the -trace_basic_blocks flag to trace basic blocks as they are being executed (primarily useful for debugging). We can also run a fuzzing session with Jackalope like this:
./Jackalope/build/Release/fuzzer -in in -out out -t 1000 -delivery shmem -target_module loader -target_method __Z4fuzzPc -nargs 1 -iterations 5000 -persist -loop -cmp_coverage -mute_child -nthreads 6 -- ./loader avd_rebased.dat -m @@
This tells jackalope to run in persistent mode (with the function “fuzz” being looped), with sample delivery over shared memory (-delivery shmem fuzzer flag and -m being implemented in the harness code).
Fuzzing is useful not only for finding bugs in the target, but in our case also for finding bugs in the harness, e.g. finding other kernel functions we need to replace in order for the target to work correctly.
After several iterations of fixups, the harness appeared to be working correctly. However, the fuzzer also caught some crashes that appeared to have been caused by genuine issues in the AV1 parsing code. I did a root cause analysis and reported the issues to Apple. The reports can be seen in the following entries in the Project Zero issue tracker:
- AppleAVD: Large OBU size in AV1_Syntax::Parse_Header reading to out-of-bounds reads
- AppleAVD: Issue with AV1_Syntax::f leading to out-of-bounds reads
- AppleAVD: Integer underflow in AV1_Syntax::Parse_Header leading to out-of-bounds reads
Unfortunately, at the time of reporting these issues I still didn’t have access to a machine with AV1 decoding capabilities. Thus, instead of full end-to-end PoCs, the issues were reported in the form of a full root cause analysis and a binary stream that causes a crash when used as a parameter to a particular decoding function. Eventually, we did get a Macbook with a M3 chip that supports AV1 hardware decoding and tried to reproduce the reported issues. Unsurprisingly, all three issues reproduced exactly the same on the real hardware as in the userspace harness.
The goal of this project was to create userspace kernel extension fuzzing tooling that was as simple as possible, and at least one of the reasons for this simplicity was that it could be easily adapted to other pieces of kernel code. The process is versatile enough that it allowed us to fuzz AV1 parsing code that normally requires hardware we didn’t even have at the time. While the three issues found during this research are not critical, they demonstrate the correctness of the approach and the potential for finding other issues.
如有侵权请联系:admin#unsafe.sh