2024-11-22 06:45:6 Author: securityboulevard.com(查看原文) 阅读量:0 收藏
Leveraging Genetic Algorithms for Bot Protection
The goal of this new rules-based detection method is to use genetic algorithms to discover parts of traffic caused by malicious activities. We are then able to create rules to automatically block those segments.
While DataDome heavily relies on ML techniques to detect malicious bots traffic, our detection engine also offers the possibility to execute millions of rules in a few milliseconds. Thousands of rules—generated both manually and automatically—are already efficiently filtering traffic. Multiplying the methods we use to create rules ensures protection is as complete as possible. The nature of this algorithm allows it to find bot traffic that would not have been detected otherwise, by introducing randomness and making no assumptions about the nature of the requests to target.
Let’s take a look at how we designed this system:
1. Define Our Desired Output
Our goal is for the algorithm to generate rules that specifically target bot traffic that have not already been blocked by our other detection methods. These rules should be defined as a combination of predicates, to target specific request signatures.
To begin, we collect a set of unique key-values from the signatures of the requests stored in recent days. This set contains the predicates we will use to build our potential solutions (i.e. our rules targeting specific parts of traffic).

If we receive a Post request coming from the country of France with Chrome as a user agent, we add Method=POST, Country=France and UserAgent=Chrome to our set of predicates.
We are then able to create a base set of rules by randomly combining elements from our set of predicates. This base set will serve as the starting point for the algorithm’s evolution.

For example, we create rule A, defined as Country=Spain AND UserAgent: Chrome and rule B as Country=France AND UserAgent: Firefox.
Our hypothesis is that we will be able to make new rules out of these base rules thanks to an evolutionary process. These new rules will use a combination of predicates to effectively match bot traffic.
2. Evaluate Our Potential Solutions
Then, we need to be able to evaluate the fitness of each rule—that is, how good the rule is at targeting bot traffic. This part is challenging; since we are trying to discover bot activity that wasn’t detected by any other method, we have no reliable labels to assess if the requests matched by our rule are bot-made or human-made. The solution we adopted was to look at the time series of the requests that would have been matched by the rule. In particular, we’re combining two metrics to give a fitness score to each rule:
- We evaluate how similar the time series is to the time series of known bot patterns (gathered through DataDome’s other detection methods). We want our rules to be as similar as possible to a known bot pattern.


- We evaluate how similar the time series is to the times series of known legitimate human traffic. We want our rules to be as different as possible from all of our known human patterns.


If a time series presents the characteristics of a bot traffic time series and is different from all of our known human time series, the associated rule would be deemed good and get assigned a high score. Otherwise, the rule would get assigned a low score.
3. “Evolve” Our Rules to a Satisfactory Solution
Once we have assigned a score to each of our rules, we can retain the ones that perform the best—”survival of the fittest”—and generate new rules by combining the ones we have retained.

We can combine our rule A and our rule B to create a rule C that could be Country=France AND UserAgent: Chrome.

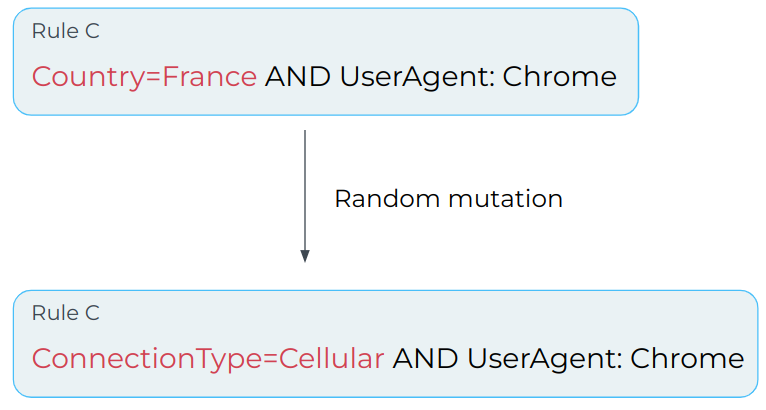
Next, we introduce random, infrequent mutations in our rules in order to introduce new predicates into the population of potential solutions.

We can randomly mutate rule C by removing part of the rule and replacing it by another key-value from our set of predicates, such as replacing Country=France with ConnectionType=Cellular.
By introducing mutations, the algorithm is able to explore new areas of the solution space and potentially find better solutions that it would have missed otherwise.
Having created this new generation, we’re able to repeat the process of scoring our potential solutions and combining them into new ones over and over. This process will increase the fitness score of our population with each new generation.
Once we’ve gathered enough satisfactory rules, we’re able to stop the evolution process and leverage the new rules through our detection system.
如有侵权请联系:admin#unsafe.sh