I’ve written about File Downloads quite a bit, and early this year, I delivered a full tech talk 2024-11-23 02:12:39 Author: textslashplain.com(查看原文) 阅读量:56 收藏
I’ve written about File Downloads quite a bit, and early this year, I delivered a full tech talk on the topic.
From my very first days online (a local BBS via 14.4 modem, circa 1994), I spent decades longing for faster downloads. Nowadays, I have gigabit fiber at the house, so it’s basically never my connection that is the weak link. However, when I travel, I sometimes find myself on weak WiFi connections (my current hotel is 3mbps) and am reminded of the performance pains of yesteryear.
Over the years, various schemes have been concocted for faster downloads; the most effective concern sending fewer bytes (typically by using compression). Newer protocols (e.g. H3’s QUIC) are able to offer some improvements even without changing the number of bytes transferred.
For the last twenty years or so, one performance idea has hung around at the periphery: “What if we used multiple connections to perform a single download?” You can see this Parallel downloading option today inside Chrome and Edge’s about:flags page:

This is an “Enthusiast” feature, but does it really improve download performance?
Mechanics: How Parallel Downloads Work
Parallel downloads work by using the Range Request mechanism in HTTP that allows a client to request a particular range (portion) of a file. This mechanism is most commonly used to resume incomplete downloads.
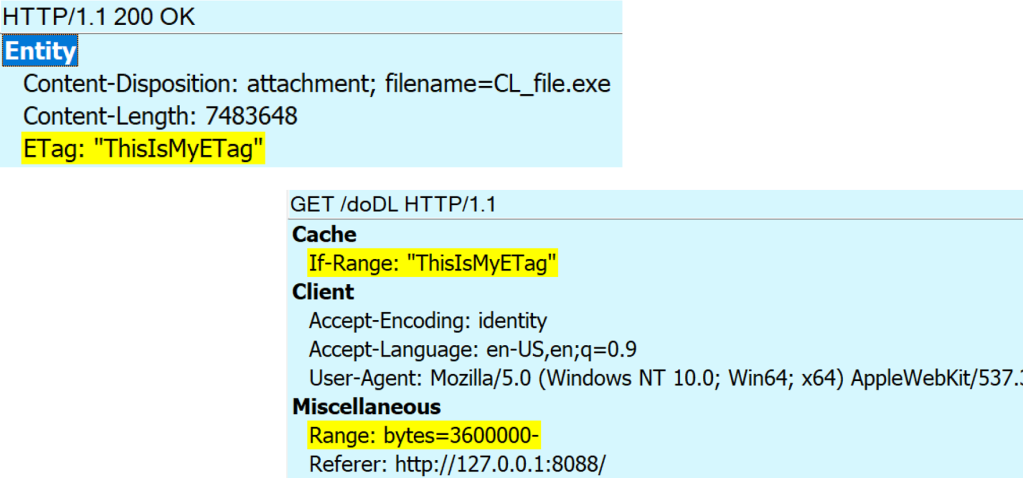
For example, say you went offline after downloading the first 3.6mb of a file. When you get back online, the browser can request that the server send only the remainder of the file by sending a Range header that specifies that it wants bytes #3,600,000 and later, like so:

The If-Range request header supplies the ETag received on the first part of the response; if the server can send the requested range of that original response, it will return a HTTP/206 Partial Content response. If the server cannot return the requested portion of the original resource, it will either return a HTTP/200 with the entire file, or a HTTP/416 Requested Range Not Satisfiable error.
The Range Request mechanism is also used for retrieving specific portions of media in other scenarios where that makes sense: imagine the user skips ten minutes ahead in a long web video, or jumps down 50 pages in a PDF file. There’s no point in wasting data transfer or time downloading the part that the user skipped over.
The Parallel Downloads feature uses the same mechanism. Instead of downloading just one range at a time, the browser establishes, say, 4 simultaneous connections to the server and downloads 25% of the file on each connection.
Limitations
Notably, not every server supports Range requests. A server is meant to indicate its support via the Accept-Ranges response header, but the client only gets this header after it gets its first response.
Even if a server does support Range requests, not every response supports ranges. For example, the server may not support returning a specific range for a dynamically-generated download because the bytes of that download are no longer available after the first connection.
Are Parallel Downloads Faster?
From a theoretical point-of-view, parallel downloads should never be faster. The performance overhead of establishing additional connections:
- TCP/IP connection establishment requires extra roundtrips
- The TCP/IP congestion-controlling behavior called “Slow start” that throttles newly-established connections
- HTTPS connections require relatively expensive TLS handshakes
… means that performing downloads across multiple parallel connections should never be faster than using a single connection, and it should usually be slower.
Now, having said that, there are two cases where performing downloads in parallel can be faster.
First, there exist file download servers that deliberately throttle download speeds for “free” customers. For example, many free file download services (often used for downloading pirated content, etc) throttle download speeds to, say, 100kbps to entice users to upgrade to a “pay” option. By establishing multiple parallel connections, a user may be able to circumvent the throttle and download at, say, 400kbps by using 4 parallel connections. This trick only works if the service is oblivious to this hack; smarter servers will either not support Range requests, reject additional connections, or share the cap across all of a user’s connections.
Next, HTTP/1 and HTTP2 are based on TCP/IP, and TCP/IP has a “head-of-line” blocking problem that can cause slowness for spotty network connections wherein a dropped packet can cause the stream to stall. If a download is conducted across multiple parallel connections, the impact is muted because each TCP/IP connection stalls independently. A parallel download could conceivably still make progress on the other connection’s chunks until the stalled connection recovers. HTTP3 does not have this problem because it is based on QUIC, and UDP does not suffer from the head-of-line blocking problem.
In some markets, support for Parallel Downloading may be an important competitive feature. In India and China specifically, connection quality is somewhat lower, making it somewhat more likely users will encounter head-of-line blocking in TCP/IP. However, I believe that the main reason that Chromium offers this feature is that less popular browsers in those markets trumpet their support for Parallel Downloads in their marketing materials, so natively offering this feature in Chromium is important from a competitive marketing point-of-view.
如有侵权请联系:admin#unsafe.sh