2024-11-26 08:37:17 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Table of Links
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
3 DREAMLLM
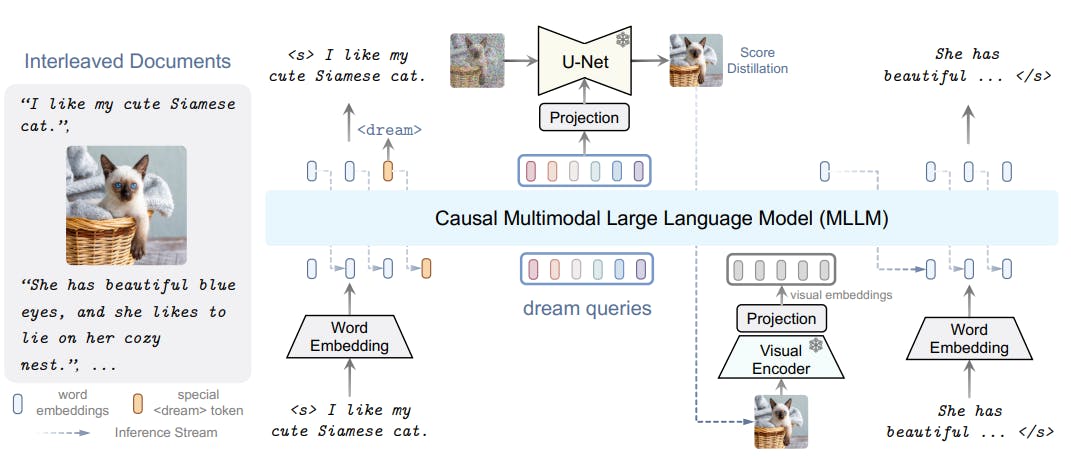
We introduce DREAMLLM, a universal learning framework that facilitates both MLLM’s comprehension and creation capabilities. Our DREAMLLM is built with a causal decoder-only LLM Fθ as the model foundation, i.e., Vicuna (Chiang et al., 2023) based on LLaMA (Touvron et al., 2023a)

trained on ShareGPT (Zheng et al., 2023). We adopt OpenAI’s CLIP-Large (Radford et al., 2021) as the visual encoder Hϕ, followed by a linear layer Mζ for visual embedding projection. To synthesize images, we use Stable Diffusion (SD) (Rombach et al., 2022) as the image decoder, and the condition projector Mψ is also a linear layer. An overview of the architecture is depicted in Fig. 2.
Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.
如有侵权请联系:admin#unsafe.sh