![]()
大模型技术的涌现,为行业不断突破安全防护的能力上限提供了新的契机。我们在将大模型技术引入安全垂类领域方面也做了很多尝试,并沉淀形成大模型应用实践系列文章。作为该系列的开篇,本文重点介绍在代码安全领域安全左移的落地实践经验。后续还将推出更多关于大模型在研发安全、网络安全、威胁情报等方面应用的探索和总结,欢迎持续关注本公众号。
隐藏在代码中的安全漏洞如同一条通往业务核心数据资产的隐秘通道,极易被黑客盯上和利用。及时识别和修复代码漏洞对防止黑客入侵和数据泄露至关重要。借助混元大模型,腾讯啄木鸟代码安全团队在代码评审(Code Review,下文简称CR)场景下的安全漏洞检出能力取得显著提升,日均发现和阻断300+个代码安全风险,极大提升了公司核心数据资产安全性。代码漏洞作为一种特殊的代码缺陷,是黑客窃取数据的主要途径。业界代码漏洞导致的安全事件频繁发生。23年5月,著名文件传输系统MoveIt Transfer被曝存在sql注入漏洞,导致2095个组织和超过6200万人的数据被泄露。同样在23年5月,梭子鱼发现其邮件网关产品存在远程命令执行漏洞,且已经被黑客利用超过8个月。
CR是保证代码质量的重要手段,通过CR可以在开发阶段提前发现并修复漏洞,避免漏洞流入线上造成严重数据泄露,并可极大提升漏洞风险闭环的效率。Steve McConnel在《Code Complete》中提到,通过CR能够发现高达60%至65%的潜在缺陷,而大多数测试的潜在缺陷发现率仅在30%左右。SmartBear经过实际调研发现,引入代码CR可以解决节约六成代码修复成本。
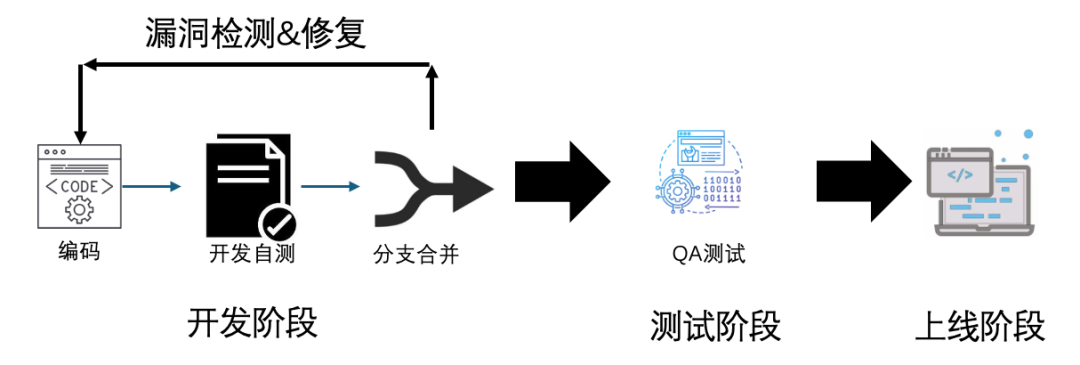
图1 CR阶段漏洞修复流程说明
由此可见,代码漏洞如果不能在上线之前及时解决,流入到线上环境后,不但对业务影响大,而且发现难度高。在CR阶段发现并修复漏洞,能够更及时、高效地避免漏洞引发的安全威胁,保障业务安全稳定运营。代码本质上是一种高维的自然语言。在大模型技术涌现之前,代码漏洞检测主要依赖静态分析:先将代码解析成低维的语法结构,通过数据流和污点分析对代码进行扫描,检测代码中的漏洞。静态分析通常需要提供漏洞完整的上下文信息,包括source点(用户控制入口)、sink点(漏洞作用位置)和数据流(传播路径),因此只适用于项目级代码扫描。
图2 代码静态分析流程图
CR 场景中,用户合入的代码通常是代码片段,只包含项目代码中的一小部分。直接使用静态分析方法扫描整个项目,以检测合入代码的漏洞情况,会引入大量冗余的扫描动作,效率极低。据统计,静态分析工具对项目级的扫描耗时平均需要20分钟以上。如果用户合入代码后,需要等待几十分钟,甚至数个小时才能获取代码扫描结果,这远远无法满足开发人员快速迭代的要求。而如果只基于合并的代码片段进行漏洞检测,由于没有完整数据流,静态分析方法难以奏效。得益于大模型天然的代码理解和分析能力,将代码漏洞检测回归到语义层面理解,为代码片段的漏洞检测问题提供了新的契机。CR 场景下检测代码漏洞的基础是理解代码功能。以 SQL 注入为例,检测 SQL 注入风险的关键是识别不合理的SQL语句拼接。然而变量命名、函数用法等在代码层面有各式各样的写法,单纯从语言规则层面难以辨别。
图3 大模型对各式各样的SQL代码拼接识别情况示例
利用大模型在代码理解方面的强大能力,可以正确识别此类代码功能。
虽然代码片段缺乏项目级数据流,但是我们依然需要基于代码片段的上下文,分析是否存在sink 点信息是否会被外部可控。例如数据是否从安全的上下文中获取,或者代码片段中是否存在过滤函数等。
利用大模型,可以准确捕获代码片段的上下文信息,并且聚焦与漏洞相关的代码,规避漏洞误报,提高漏洞检测准确率。从上文可知,大模型的通用代码理解能力为代码漏洞检测提供了良好的基础。接下来我们详细介绍如何设计代码漏洞检测提示词,从而更好地发挥大模型的能力。借鉴思维链(Chain-of-Thought,简称CoT)思想,在提示词中给出漏洞检测详细且明确的推理过程示例,并引导大模型按照步骤逐步分析。
由于大模型会将已输出的内容作为上下文的一部分,因此显式输出推理过程可以有效引导大模型得到正确结果,显著提升结果准确性。即使提供了详细的推理步骤,但是大模型还是存在偶发事实认定错误的情况。例如在明文账密的场景,只有当账密直接暴露在代码中,才有泄露风险。但是大模型会偶发识别错误,将变量认定成字符串常数,从而认为存在账密泄露问题。
这种现象存在一定随机性,难以通过固定 prompt 模板彻底解决。起初,我们尝试利用规则的方式消除这种随机性带来的误报。然而在代码域难以用规则或正则全部枚举所有情况。因此我们借助大模型的代码理解和生成能力,先让大模型将关键代码内容按照指定模式输出,然后在一个固定模式下,通过规则规避误报情况。在CR 漏洞检测场景中,我们在代码存在漏洞的情况下,需要向用户反馈结果,并提示漏洞所在具体的代码行、漏洞类型、漏洞描述。由此可知,CR 场景要求大模型反馈的信息较多且结构化要求高。初期我们尝试了让大模型在每一部分加入指定前缀,便于后续内容解析,但是经常遇到大模型不按指定格式输出的情况。如:增加换行、冒号等字符,输出格式外的额外信息等,最终导致解析失败。为了解决这一问题,我们选择让大模型按照 json 格式输出。由于 json 是一种通用的结构化数据,大模型经过广泛的预训练可以很好输出 json 格式数据,使得输出结果更加准确。经过多轮优化,漏洞检出准确率提升 69%(26%->95%),日均发现 300+个代码安全风险,可起到在代码上线前提前阻断风险的效果。 典型案例 1:成功检出某业务Web前端代码中存在AKSK硬编码。若直接发布到线上环境,黑客扫描网页即可获取相应AKSK,进而使用该账号下的所有资源。可能造成严重的数据泄露事故。图9 Web前端代码中存在AKSK硬编码漏洞的危害说明示意图典型案例2: 某订单系统项目中,业务同学在提交代码时直接将上游变量拼接到 SQL 语句中,引入SQL注入漏洞,被模型成功检出。若该缺陷代码发布到线上环境,黑客可从客户端入口构造恶意输入,进而直接操作后端 DB,窃取用户信息和订单信息,获取业务核心数据。图10 订单系统代码中SQL注入漏洞的危害说明示意图本文主要介绍了传统静态分析方法应用于CR场景漏洞检测的弊端,以及基于混元大模型底层技术和专家规则结合的方案在该场景的落地实践和提升效果。
在相关工作的落地过程中,还有很多问题值得我们进一步深入探索和解决。以下问题如有兴趣,欢迎一起交流探讨。随着覆盖的漏洞种类的增多,每种漏洞都需要在 prompt 中指定分析步骤,平均每个漏洞规则需要 500+token 描述,加上用户输入的代码片段,进一步增加了上下文长度,这会导致大模型更容易遗忘 CoT 中的重要步骤,无法按照预期步骤推理,影响结果准确性。
解决思路:这一问题可以借鉴 MoE 模型的思路,针对多种多样的漏洞场景构建一个 MoE 模型,每个子模型单独解决一类漏洞问题,不仅可以减少上下文数量,还可以针对不同漏洞针对性设计prompt和输出格式,更加灵活精准。幻觉问题是大模型落地过程中常见的问题,某些情况下,大模型会无中生有、编造事实,影响结果准确性。虽然从整体来看,大模型的幻觉问题发生概率非常低,但是特定场景下的幻觉问题不可避免。
格式化输出会在一定程度上限制大模型的推理能力,从而影响CoT 的效果。有研究人员提出,格式化输出和 CoT 兼容的方法是二次转换,先让大模型自由发挥,然后再利用大模型将生成结果转换成 json 格式。但是这无疑会增加 CR 的整体耗时和大模型调用次数。
解决思路:这一问题可以通过调用两次模型解决,第一次不限制输出格式,提高解决准确性,第二次基于第一次输出的事实,只做简单的总结和格式化输出,提高结果可用性。
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NzE1NjA0MQ==&mid=2651206699&idx=1&sn=b850cf1e858f00b90a717efd504988dc&chksm=bd2cd18d8a5b589baf4bc2e8229f0eef51a96cf1ffe79bcd9214278becd3684f3fa040892043&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh