2024-11-27 05:27:34 Author: hackernoon.com(查看原文) 阅读量:0 收藏
The Role of Data in Machine Learning
In today's AI-driven landscape, machine learning, AI, and chatbots are transforming industries at an unprecedented pace.
More businesses are looking to integrate AI into their operations, but how these systems are built often gets overlooked. The main ingredient? Data. A machine learning model is only as good as the data it’s trained on. But where does all this data come from?
A significant portion of the data we rely on is publicly available, often found in social media posts, user reviews, and other online content. For sentiment analysis, one of the richest sources of data is Twitter, which continuously streams real-time user-generated content. The challenge, however, lies in how to collect this data effectively and cleanly.
The Problem with Traditional Twitter Data Collection
When I began working on a sentiment analysis project using Twitter data, I initially considered using the Twitter API. However, I quickly encountered a significant limitation: the free-tier API only provides access to tweets from the previous seven days. For comprehensive sentiment analysis, especially for trending topics or political events spanning weeks or months, this restriction severely limits the scope and quality of the data available.
While upgrading to a higher API tier was an option, the cost was prohibitive for a small-scale project like mine. This left me with two paths: attempt to collect the data manually through traditional scraping (which came with its own set of challenges like CAPTCHAs, redundancies, and incomplete records) or find an alternative solution.
That's where Bright Data comes into play, solving these issues seamlessly by offering clean, scalable, and historical Twitter datasets. Instead of being confined by API limitations, I could access diverse, high-quality data for my project without the usual hassles.
Step-by-Step Guide to Using Bright Data’s Prebuilt Twitter Dataset
In this article, I’ll walk you through how you can leverage Bright Data’s Marketplace to acquire high-quality Twitter data for sentiment analysis and share my experience.
Step 1: Sign Up and Access the Bright Data Platform
Head to the Bright Data website and create a free account to start. Once logged in, you'll be directed to the Data Marketplace, where various prebuilt datasets can be accessed, including those related to Twitter.
Step 2: Search for the Relevant Dataset
Once you select your dataset, you can download it directly to your local machine or access it via API. The quick process allows you to start working with high-quality data almost immediately. I used the Twitter-posts data set
Step 3: Load and Clean the Data
The raw Twitter data typically contains a lot of metadata that may not be relevant for sentiment analysis, such as user information, image URLs, and other non-textual data. We'll focus on the text of the tweets, as that is where the sentiment analysis will be applied, along with relevant engagement metrics like reposts and likes.
import pandas as pd
df = pd.read_csv("path_to_your_dataset.csv")
df.head()
The next step is to clean the data by handling missing values and removing irrelevant columns.
df_clean = df[['user_posted', 'description', 'date_posted', 'reposts', 'likes']]
df_clean = df_clean.dropna(subset=['description'])
df_clean = df_clean.drop_duplicates(subset=['description'])
df_clean.head()
Now that we have cleaned the data and have the relevant text, it’s time to dive into the sentiment analysis. Sentiment analysis means determining the emotional tone behind words—whether the tweet is positive, negative, or neutral.
I’ve used a popular library called VADER (Valence Aware Dictionary and Sentiment Reasoner), specifically designed for social media text. It’s great at handling informal language like slang and emojis.
The code snippet below performs sentiment analysis using VADER
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
def get_sentiment(text):
sentiment = analyzer.polarity_scores(text)
return sentiment['compound']
df_clean['sentiment'] = df_clean['description'].apply(get_sentiment)
df_clean.head()
Step 5: Analyzing Sentiment Distribution
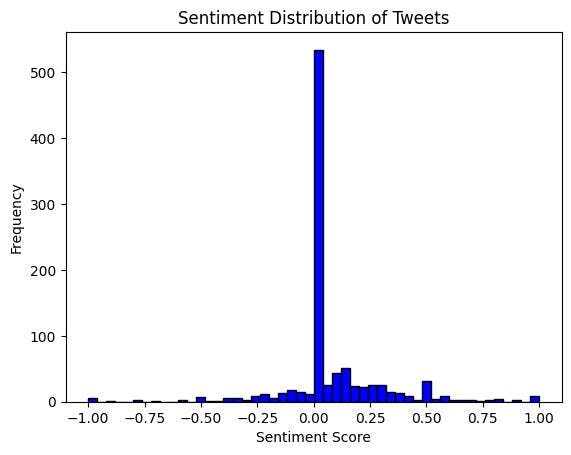
Once sentiment scores are calculated, we can analyze the distribution to see how positive or negative the tweets are on average. This can provide insights into the overall public mood about a particular topic or event. We can also visualize the sentiment distribution using a histogram or wordcloud to identify key emotions.

This plot will give you a good sense of the sentiment spread, whether it's leaning toward positive, negative, or neutral. In this case, There’s a high frequency of neutral tweets.
Step 6: Correlating Sentiment with Engagement
Now that we have the sentiment scores for each tweet, the next step is to explore whether there's any correlation between sentiment and engagement metrics like likes and reposts. In social media analytics, one might expect that more positive sentiment could lead to higher engagement (more likes, more reposts). However, is that truly the case?
To find out, we can calculate the correlation between the sentiment scores and engagement metrics, the results are:
Correlation between sentiment and likes: 0.022806738610786123
Correlation between sentiment and reposts: 0.008885789875330416
Given the weak correlation values from my data analysis, we see that there isn't a strong connection between sentiment and engagement. The correlation between sentiment and likes was 0.02, and for sentiment and reposts, it was only 0.008. These values suggest that engagement metrics like likes and reposts are not significantly influenced by the sentiment of tweets.
Rethinking the Role of Sentiment in Engagement
The weak correlation between sentiment and engagement shows that there are other factors at play. While sentiment analysis helps us understand public opinion, engagement is likely driven by additional factors, such as:
- Content relevance: Trending topics tend to generate more engagement regardless of sentiment.
- User influence: Popular accounts often receive higher engagement, irrespective of their tweet’s sentiment.
- Timing: Tweets posted during live events or peak times are more likely to get attention.
While sentiment analysis is a valuable tool for understanding how people feel about a topic, it’s not always a reliable predictor of engagement. To gain deeper insights into user behavior, it’s essential to consider other factors such as the content’s timing, relevance, and the user’s influence.
如有侵权请联系:admin#unsafe.sh