2020-06-02 20:12:13 Author: bbs.pediy.com(查看原文) 阅读量:556 收藏
写在前面
笔者水平不高,但是既然做出了这道题,就和大家分享一下吧。文中出现的谬误还请大佬们斧正~
文章图片如有看不清楚的可以去我博客单击相应图片查看原图
ghidra反编译mips64程序
题目给出cipher程序和ciphertext密文。
ciphertext:

最后的0a是换行符。
用reafelf -h file看一下cipher程序信息:

mips64的程序,大端。
ida无法反编译mips64的代码,网上查到说ida的retdec插件可以反编译mips,但是我去github看了看官方介绍,似乎不支持mips64:

然后无意间搜索到一款由美国安全局开发的开源逆向软件,ghidra,可以反编译mips64。
安装很简单。先安装好jdk11,可以不添加环境变量。然后运行ghidraRun.bat,如果没添加环境变量的话,会询问你jdk11的安装目录(填写根目录)。然后就可以运行了。
较为详细ghidra操作的学习可以移步全面详解 Ghidra
建立一个新project,把ciphter拖进来:


最后分析好的界面如下:

左侧中间窗口可以查看函数。
main函数

从flag文件中读入flag,然后调用cipher
cipher函数

根据变量的实际含义改一下变量名(单击变量后按L键):

16个字节为一组(两个ulonglong)进行分组,第17行代码的作用就是求一共几组。右移4其实就是除以16。先减一再移位最后再加一的作用是让不足一组的算作一组,代入个实际的数算一算就容易理解了。
CONCAT44()是ghidra自己定义的一个函数,因为一些汇编操作无法通过已有的c语言中的函数进行简单描述:

CONCATxy(x,y的值可以变)系列的函数其实就是拼接函数,比如说CONCAT31(0xaabbcc, 0xdd) = 0xaabbccdd。
具体的解释可以查看官方手册:

依次点击Ghidra Functionality > Decompiler > Internal Decompiler Functions:

顺便吐槽下,ghidra很新,所以很多知识很难查到,google都很难查到相关内容。不像ida,遇到的问题基本网上都很容易找到前辈们的中文总结。
第18到20行得到了两个随机数,并分别取char,并保存至param_2[0]和param_2[1]。注意这里的param_2这个数组的变量类型不确定,伪代码中用undefined来注明了。我对此处的误解导致了我一直没有成功解出flag,直到动态调试才发现错误所在。等下我会细说此处。
然后进入循环,调用cipher,每次循环处理一组数据(16个字节,2个无符号长整型)。
最后第28行开始,输出处理后的数据。
encrypt函数

乍一看就是一些异或和循环移位,应该没有特别难的地方。所以,等下会有个但是。
阅读一边后,很容易发现一个问题,第8行声明的in_a2这个指针,在第17、18行被调用。但是,代码中没有任何对这个指针的赋值地址的行为,我们(和程序)根本不知道这个指针指向何处(如果按照伪代码的逻辑来的话)。
所以很容易想到,是不是ghidra反编译出了一点小差错。
我们来看看汇编代码:
小白的我第一次接触mips指令集,以下内容如有谬误,希望大佬们可以斧正~
首先介绍几个用到的mips的指令:
为了不引起混淆,先说一点:
emmm,因为伪代码中的变量大多都是ulonglong(64bit),我看到下文中的双字,还在纳闷这不是32位的吗?查资料才明白,不同的架构,规定的数据类型是不一致的。mips64的数据类型没搜到,应该和mips32类似吧。这和x86差异挺大的,像我这种小白很容易误解。
指令的主要任务就是对操作数进行运算,操作数有不同的类型和长度,MIPS32 提供的基本数据类型如下:
(1)位(b):长度是 1bit。
(2)字节(Byte):长度是 8bit。
(3)半字(Half Word):长度是 16bit。
(4)字(Word):长度是 32bit。
(5)双字(Double Word):长度是 64bit。
(6)此外,还有 32 位单精度浮点数、64 位双精度浮点数等。
LD rt, offset(base)
从存储器中读取双字的数据到寄存器中。
rt是寄存器,offset是偏移量,base是基址。

SD rt, offset(base)
把双字的数据从寄存器存储到存储器中
rt是寄存器,offset是偏移量,base是基址。

单击伪代码中第17行中的in_a2,中间的汇编自动跳转到相关的指令位置。如图所示:

s8表示的是栈。v0是最常使用的寄存器。
我们得知:in_a2在栈中0x08的位置,即stack[-0x8],结合划线处,我们可以判断,encrypt是有三个参数的,第三个参数就是in_a2,是一个指针。根据指令ld(load double word)判断,应该是个longlong*或者ulonglong*类型的指针
ghidra有个很有用的功能,如果你对伪代码的不满意,可以进行一定程度的修改。
在如图所示处右键,选择第一项,进行函数签名的修改。

手动添加第三个参数:

修改后:

到此时,目前代码中唯一有点问题的就是第14、15行的concat44()这个函数,其他的部分都是正常的c语言代码。
看不懂伪代码,直接读汇编吧。

伪代码中的uVar1是[s8 + 0x30]。这其实是x86汇编中的表示方式,因为大多数人更熟悉x86,所以本文中我用了这样表示方式。它意思是取栈中偏移为0x30处的值。
伪代码中uVar1是[s8 + 0x30],uVa2r是[s8 + 0x38]。
所以uVar1 = [__edflag], uVar2 = [__edflag + 0x8]
cipher函数中调用本函数时,__edflag传进来的实参是(int)input_flag + i * 0x10,即每个分组的首地址。
所以uVar1是第一个ulonglong的地址,uVar2是第二个ulonglong的地址。
(其实不用分析,靠猜也能猜出这两个变量就是分组的数据,我做题的时候也是直接猜测的,写本文的时候才开始读的这部分汇编)
其实有时候汇编代码反而比伪代码更容易读懂。
比如本函数的第22行,(uStack24 >> 8) + (uStack24 << 0x38),有点意思,其实就是一个64位的循环右移,汇编中一行就搞定了:

第23行的(uStack32 >> 0x3d) + uStack32 * 8就更有意思了:

没想到吧,参数是0x1d,但是却移了0x3d位。为什么?请从下图找答案。
关于移位指令:


加密逻辑
分析到这一步,本函数的逻辑应该很明显了啊。
我们用ror64表示64位的循环右移,可以将加密逻辑整理为:
def enc(a, b, c, d):
v32, v24 = c, d
v40 = (ror64(b, 8) + a) ^ v32
v48 = ror64(a, 0x3d) ^ v40
for i in range(0x1f):
v24 = (ror64(v24, 8) + v32) ^ i
v32 = ror64(v32, 0x3d) ^ v24
v40 = (ror64(v40, 8) + v48) ^ v32
v48 = ror64(v48, 0x3d) ^ v40
print(hex(v48), hex(v40))
a, b分别是送入的两个ulonglong数据。
c,d是和我们之前分析的encrypt函数添加的第三个参数array有关,分别是array[0]和array[1]。先下结论c和d与cipher函数中获取的两个随机数有关,什么关系,下文会细说。
一共进行0x1f轮的加密处理。
v32和v24是一组key(密钥),在每轮的加密中都会进行变换,其值与c,d,i有关。怎么看出它是key的?因为其值与密文无关,而反过来密文与它有关。
v48和v40是密文。其值与plaintext(a,b), key(c,d)有关。
下面重点说一下c和d这俩值。
在cipher函数的伪代码中可以看到:

如果你的伪代码中看不到encrypt函数的第三个参数,请退回上文,按照步骤修改encrypt函数的signature。
可以看到c,d和随机数有关。
如果靠猜的话,我估计绝大多数人,都会猜测c = param_2[0], d = param_2[1]。是的,我也是这么猜的,这一错误的猜测使得我整整一天都在查找错误何在。
此处伪代码很难分析啊,最大的问题在于我们不知道param_2的变量类型,伪代码给出的是undefined *代表未知。再加上这么明显的暗示!
让谁来看,都会觉得是两个随机数分别强制格式转化为一个字节的数据,然后送入param_2[0]和param_2[1],这两个都是ulonglong,然后传入encrypt函数中当作key。
当然可以通过汇编来做出判断:

当然这对我来说是马后炮,当我动调之后才理解了这段汇编的含义。
最后我是通过动态调试了解的具体细节。这段赋值过程特别有意思,这也是我写篇文章的主要目的。文章到这里才刚刚进入主题。
动态调试(qemu+ida)
qemu运行mips64程序
要想动态调试,首先要能运行这个程序。
QEMU(quick emulator)是一款由Fabrice Bellard等人编写的免费的可执行硬件虚拟化的(hardware virtualization)开源托管虚拟机(VMM)。
其与Bochs,PearPC类似,但拥有高速(配合KVM),跨平台的特性。
QEMU是一个托管的虚拟机镜像,它通过动态的二进制转换,模拟CPU,并且提供一组设备模型,使它能够运行多种未修改的客户机OS,可以通过与KVM(kernel-based virtual machine开源加速器)一起使用进而接近本地速度运行虚拟机(接近真实电脑的速度)。
QEMU还可以为user-level的进程执行CPU仿真,进而允许了为一种架构编译的程序在另外一种架构上面运行(借由VMM的形式)。
说人话:通过qemu能运行mips64架构的程序
安装qemu
以下过程可能存在谬误,我试图复现环境,但是暂时没能成功,稍后会琢磨琢磨,请大家先移步https://www.cnblogs.com/WangAoBo/p/debug-arm-mips-on-linux.html
以ubuntu为例:
apt install qemu-user-static
我做题时应该是使用apt install qemu-user进行安装的,但是滚档重新安装时发现虽然能够安装成功,但是运行文件时报错:
qemu: uncaught target signal 11 (Segmentation fault) - core dumped
Segmentation fault (core dumped)
尝试了几次都不行,改用了apt install qemu-user-static
运行
静态链接的程序可以像正常程序一样运行。
如果是动态链接的程序直接运行会报错:

需要安装相对应的链接库,然后通过qemu运行程序,同时指明共享库(-L参数)。
以本文mips64程序为例:
查找相关库:
apt-cache search "libc6" | grep mips64
mips64el是小端,注意区分。

我们在列表中选择形如libc6-mips64-cross的包进行安装:
sudo apt install libc6-mips64-cross
然后运行程序,同时指定共享库的路径:
qemu-mips64-static -L /usr/mips64-linux-gnuabi64/ cipher
注意不同架构对应的qemu的命令不同,可以先输入qemu,然后下tab键查看所有命令。
输入/usr/mips64的时候也是按下tab键,有惊喜。

可以看到程序运行,并输出密文。(main函数中通过putchar输出密文而不是保存到文件中)
ida远程动态调试
服务端:
qemu-mips64 -L /usr/mips64-linux-gnuabi64/ -g 23946 ./cipher > out
-g在23946端口开一个gdb调试
客户端:
Debugger->attach->remote GDB debugger

填写服务端ip和端口,然后点击Debug options:

箭头处的两项要勾选,不然一进入调试状态,程序就执行完成并退出了。然后点击图中划线处Set specific options.

选择相应的架构:

此后点击多次ok:



最后进入调试:

很不幸,前面说过,ida无法反编译mips64。所以只能看汇编了。
程序一开始停在系统领空。

按上一会f8(大概三四十步)即可跳转至程序领空。
先跳出系统领空再进行地址的跳转。否则容易导致代码没加载成功:

在程序领空内,g直接跳转到某处都容易导致代码没加载成功。

此时按c转换成汇编语言时容易出现下图所示的错误,ida崩溃退出。

所以我们虽然通过静态能知道各个函数的地址,但也不要直接跳转,先跳出系统领空后,再按g并输入地址进行跳转。跳转时也不要直接跳,先跳到函数的起始地址,再跳这个函数内部的地址。
然后正式开始动调。之后的过程和正常题目的调试没啥区别,就是指令集不一样罢了,照着指令手册慢慢分析就行。
我们动调的目标是搞清楚前面归纳的c,d两个参数和cipher函数中生成的两个随机数之间的关系。
所以跳出系统领空后,我们先跳转到cipher函数的起始地址120000F5C,并按c分析汇编代码:

动调中看不到函数信息,所以可以先静态看一下rand的调用位置:

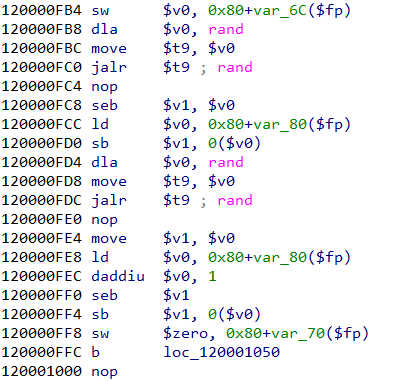
然后跳转到与随机数相关的位置,f8走几步,观察寄存器中值的变化:
下图寄存器v0中放的是第一个随机数:

取低位字节放入v1,得到单字节的0x85:
前面是ff开头应该是因为0x85>0x7f,char中算作负数,seb指令是Sign-Extend Byte,有符号扩展字节。

第二个操作数同理:

拿到单字节0xf1:

然后我们跳转到encrypt函数,看看c,d两个变量的值。
从cipher函数直接跳转到encrypt函数同样容易出现代码未加载的问题,我们可以先跳转到cipher中调用encrypt函数的位置,然后f7步入。
静态查看地址:

动调在此处f7步入:

ghidra可以轻松确定encrypt中我们归纳的那个c,d的传值的位置:

动调运行到此处:
可以看到此时c = 0x85f1 0000 0000 0000

继续运行:

所以c = char(rand1)<<56 + char(rand2)<<48,d = 0
这样我们就知道了c,d的值与随机数的关系。
这个的动调太容易让程序以及ida崩溃了,不知道大佬们有没有什么方法能使得跳转地址时代码可以正常加载出来,减少错误率。
逆向逻辑分析
为了方便大家,所以把上面归纳的加密逻辑复制到此处:
def enc(a, b, c, d):
v32, v24 = c, d
v40 = (ror64(b, 8) + a) ^ v32
v48 = ror64(a, 0x3d) ^ v40
for i in range(0x1f):
v24 = (ror64(v24, 8) + v32) ^ i
v32 = ror64(v32, 0x3d) ^ v24
v40 = (ror64(v40, 8) + v48) ^ v32
v48 = ror64(v48, 0x3d) ^ v40
print(hex(v48), hex(v40))
c和d每次运行程序都不一样,但是好在有效取值在两个字节的范围内,可以爆破。
爆破时的每次尝试可以得到一组假定的key(c,d)即key(v32, v24),经过0x1f轮的迭代,可以得到最后一轮的v32, v24(上文说过,因为v32, v24只与c,d,i有关,i是迭代的轮数)
我们已知密文,即最后一轮迭代得到的的v48, v40;并可以以爆破的方式假定c,d从而求出最后一轮的v32, v24.
可以通过v48 = ror64(v48, 0x3d) ^ v40得到上一轮的v48
再通过v40 = (ror64(v40, 8) + v48) ^ v32得到上一轮的v40
再通过v32 = ror64(v32, 0x3d) ^ v24得到上一轮的v32
再通过v24 = (ror64(v24, 8) + v32) ^ i得到上一轮的v24
如此逆向迭代,可求出明文。
解密脚本
import struct
def solve():
#with open('ciphertext', 'rb')as f:
# enc = f.read()
enc = b'*\x00\xf8+\xe1\x1dw\xc1\xc3\xb1q\xfc#\xd5\x91\xf40\xf1\x1e\x8b\xc2\x88YW\xd5\x94\xabwB/\xebu\xe1]v\xf0Fn\x98\xb9\xb6Q\xfd\xb5]w6\xf2\n'
for i in range(0x10000):
v32, v24 = get_final_r1_r2(i*0x1000000000000, 0)
flag = b''
for k in range(len(enc)//16):
f1, f2 = decrypt(enc[k*16:k*16+16], v32, v24)
flag += struct.pack('>Q', f1) + struct.pack('>Q', f2)
if b'RCTF' in flag:
print(hex(i), flag)
def decrypt(byte16, fc, fd):
v48 = struct.unpack('>Q', byte16[:8])[0]
v40 = struct.unpack('>Q', byte16[8:])[0]
v32, v24 = fc, fd
for i in range(0x1e, -1, -1):
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
v32 = rol64(v32 ^ v24, 0x3d)
v24 = rol64(ull((v24 ^ i) - v32), 8)
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
return v48, v40
def get_final_r1_r2(c, d):
v32, v24 = c, d
for i in range(0x1f):
v24 = ull(ror64(v24, 8) + v32) ^ i
v32 = ror64(v32, 0x3d) ^ v24
return v32, v24
def rol64(value, k):
return ull(value << k) | ull(value >> (64-k))
def ror64(value, k):
return ull(value << (64-k)) | ull(value >> k)
def ull(n):
return n & 0xffffffffffffffff
solve()
#RCTF{9876235e3a9bd69cfb6b4a3dfcdbca70f3054f91}
跑两分钟出结果。
没啥要注意的,记得进行加减等操作时注意保持ulonglong的位数就好。
参考:
【预售】物联网安全漏洞实战!离物联网安全研究员只有一个课程的距离!报名满30人开班!
最后于 17小时前 被iyzyi编辑 ,原因: 修改几处笔误
如有侵权请联系:admin#unsafe.sh