前言
鄙人现今是一名研究生, 研究方向为样本分析自动化, cuckoo 沙箱项目是一个非常不错的例子, 给大家分享一下.
环境搭建
os: Ubuntu 18.04 python: python2 link: https://www.jianshu.com/p/ac009f6c2710(这个链接是我试过最靠谱的)
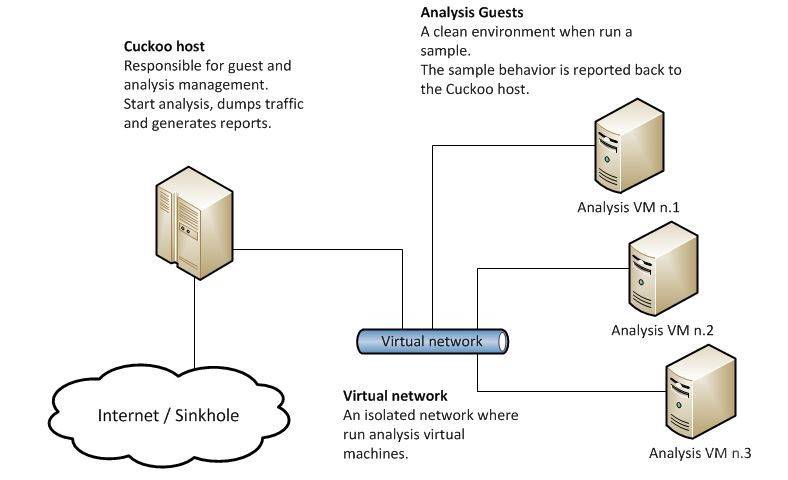
cuckoo总体架构描述
cuckoo总体架构如下图, host接收分析任务,然后开启虚拟机client, 将样本和一些必要的分析代码通过http协议传输给client端. 必要的分析代码通过会包括一些hook代码和内核模块,以及一些其他与这些模块交互的Python代码, 以Windows系统为例:monitor.dll(hook), zer0m0n.sys(内核模块), inject.exe(控制monitor),execsc.exe(执行shellcode)等. cuckoo通过这些分析代码来获取样本的行为, 然后待分析时间耗尽, 将分析结果通过tcp传输给host端, 将client回复到样本执行的状态.

cuckoo常用命令行介绍
cuckoo community --> 获取一些恶意样本的特征库 cuckoo init --> 初始化cucko cuckoo web --> 开启web服务, 可以使用浏览器上传样本,查看报告 cuckoo -d --> 开启分析样本服务, cuckoo submit --> 提交样本 cuckoo clean --> 清空分析结果
cuckoo命令
使用pip安装cuckoo之后, 可以使用cuckoo命令.查看一下cuckoo命令的位置:
(venv) pwnmelife@ubuntu:~/Downloads/cuckoo$ which cuckoo
/home/pwnmelife/Downloads/cuckoo/venv/bin/cuckoo
...
(venv) pwnmelife@ubuntu:~/Downloads/cuckoo$ cat $(which cuckoo)
#!/home/pwnmelife/Downloads/cuckoo/venv/bin/python2
# -*- coding: utf-8 -*-
import re
import sys
from cuckoo.main import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(main())
可以看到cuckoo命令其实是一个python脚本, 最后执行代码是cuckoo模块中main函数
cuckoo.main函数
main函数中使用了click模块, 可以很方便的构建命令行程序.
main函数中核心就是调用了下列的两个函数:
cuckoo_init(level, ctx) # level --> 指明输出的级别(debug or quiet), ctx是click.core.Context的对象, 用于记录一些信息. cuckoo_main(maxcount) # maxcount --> Maxinum number of analyses to process
cuckoo.init 函数
功能: 进行cuckoo的初始化,包括:
- 创建CWD文件夹
- 检查配置文件,检查版本
- 连接数据库
- 初始化cuckoo的组件
创建CWD文件夹
CWD(Current Working Directory)文件夹包含了除了运行代码以外的其余文件,非常重要.
├── agent(agent.py agent.sh android) ├── analyzer(android, darwin, linux, windows) ├── conf --> (cuckoo的配置文件) ├── distributed ├── elasticsearch ├── __init__.py ├── log(日志) ├── monitor(hook程序) ├── pidfiles(正在) ├── signatures(样本特征) ├── storage(存储样本程序,及分析的结果) ├── stuff ├── supervisord ├── supervisord.conf ├── web(web登录的一些设置) ├── whitelist └── yara(样本分析的yara规则, 如:shellcode.yar, vmdetect.yar)
连接数据库
cuckoo支持三种数据库: mysql, sqlite3, postgres, 可以在配置文件中进行配置.其中最常用的是mysql, 一般用作web模块存储数据.
mysql数据库中的表 +------------------+ | Tables_in_cuckoo | +------------------+ | alembic_version | | errors | | guests | --> 执行分析任务虚拟机的分析流程 | machines | --> 虚拟机信息 | machines_tags | | samples | --> 样本信息(sha512, md5, crc32等) | submit | | tags | | tasks | --> 分析任务信息 | tasks_tags | +------------------+ [database] # Specify the database connection string. # NOTE: If you are using a custom database (different from sqlite), you have to # use utf-8 encoding when issuing the SQL database creation statement. # Examples, see documentation for more: # sqlite:///foo.db # postgresql://foo:bar@localhost:5432/mydatabase # mysql://foo:bar@localhost/mydatabase # If empty, defaults to a SQLite3 database at $CWD/cuckoo.db. connection = mysql://root:toor@localhost/cuckoo # Database connection timeout in seconds. # If empty, default is set to 60 seconds. timeout = 60
初始化cuckoo组件
init_modules() init_tasks() init_yara() init_binaries() init_rooter() # VPN的一些初始化 init_routing() # VPN的初始化 文件: core/startup.py
init_modules
# core.startup.py
def init_modules():
"""Initialize plugins."""
log.debug("Imported modules...")
categories = (
"auxiliary", "machinery", "processing", "signatures", "reporting",
)
# Call the init_once() static method of each plugin/module. If an exception
# is thrown in that initialization call, then a hard error is appropriate.
# 下面三行代码,执行auxiliary,machinery,processing,reporting四个文件夹中的所有类的init_once函数
# 但这些类均继承自common/abstract.py中Auxiliary,Machinery,Processing,Signature,Report,
# Extractor. 个人觉得init_once函数是一个占坑函数, 为以后代码修改提供方便
for category in categories:
for module in cuckoo.plugins[category]:
module.init_once()
for category in categories:
log.debug("Imported \"%s\" modules:", category)
entries = cuckoo.plugins[category]
for entry in entries:
if entry == entries[-1]:
log.debug("\t `-- %s", entry.__name__)
else:
log.debug("\t |-- %s", entry.__name__)
# Initialize the RunSignatures module with all available Signatures and
# the ExtractManager with all available Extractors.
#
# RunSignatures.init_once()修改了以下两个类变量:
# 类变量 available_signatures: 存储所有signatures文件夹下的filename
# 类变量 ttp_descriptions: 存储ttp_descriptions.json文件中的内容.
RunSignatures.init_once()
# Extractor的子类
# OfficeDDE1, OfficeDDE2,LnkHeader,OleStream,Powerfun,Unicorn
# 将一些Extractor的子类添加到ExtractManager的类变量extractors中.
# 至于为什么要添加这些子类, 先挖一个坑, 后面会填上的.
ExtractManager.init_once()
init_tasks
# 初始化任务队列, 处理的对象:
# 1. 上次分析失败的任务
# 2. 意外退出, 未完成分析的任务
def init_tasks():
"""Check tasks and reschedule uncompleted ones."""
db = Database()
log.debug("Checking for locked tasks..")
# 获取cuckoo数据库, 表tasks中, status为running的任务
for task in db.list_tasks(status=TASK_RUNNING):
# 检查cuckoo.conf中的reschedule选项是否修改为yes
if config("cuckoo:cuckoo:reschedule"):
# 如果为yes
# 重新加入分析队列中
task_id = db.reschedule(task.id)
log.info(
"Rescheduled task with ID %s and target %s: task #%s",
task.id, task.target, task_id
)
# 如果为no
else:
# 设置为TASK_FAILED_ANALYSIS
db.set_status(task.id, TASK_FAILED_ANALYSIS)
log.info(
"Updated running task ID %s status to failed_analysis",
task.id
)
log.debug("Checking for pending service tasks..")
for task in db.list_tasks(status=TASK_PENDING, category="service"):
# 任务状态为TASK_PENDING, 说明上次分析时, 虚拟机启动失败
# 将对应任务设置为TASK_FAILED_ANALYSIS
db.set_status(task.id, TASK_FAILED_ANALYSIS)
init_yara
# 关键代码
# 编译yara规则为对应的yarac
def init_yara():
"""Initialize & load/compile Yara rules."""
# yara规则所在的文件夹
categories = (
"binaries", "urls", "memory", "scripts", "shellcode",
"dumpmem", "office",
)
for category in categories:
dirpath = cwd("yara", category)
if not os.path.exists(dirpath):
log.warning("Missing Yara directory: %s?", dirpath)
rules, indexed = {}, []
for dirpath, dirnames, filenames in os.walk(dirpath, followlinks=True):
for filename in filenames:
if not filename.endswith((".yar", ".yara")):
continue
filepath = os.path.join(dirpath, filename)
# 省略一些异常处理
rules["rule_%s_%d" % (category, len(rules))] = filepath
indexed.append(filename)
# Need to define each external variable that will be used in the
# future. Otherwise Yara will complain.
externals = {
"filename": "",
}
try:
# 编译
File.yara_rules[category] = yara.compile(
filepaths=rules, externals=externals
)
except yara.Error as e:
raise CuckooStartupError(
"There was a syntax error in one or more Yara rules: %s" % e
)
# The memory.py processing module requires a yara file with all of its
# rules embedded in it, so create this file to remain compatible.
if category == "memory":
f = open(cwd("stuff", "index_memory.yar"), "wb")
for filename in sorted(indexed):
f.write('include "%s"\n' % cwd("yara", "memory", filename))
indexed = sorted(indexed)
# 省略一些log.debug
# Store the compiled Yara rules for the "dumpmem" category in
# $CWD/stuff/ so that we may pass it along to zer0m0n during analysis.
# 如果分析windows程序, 则将dumpmem.yarac一同发送到windows 虚拟机中, 供zer0m0n驱动使用
File.yara_rules["dumpmem"].save(cwd("stuff", "dumpmem.yarac"))
init_binaries
# 比较简单
def init_binaries():
"""Inform the user about the need to periodically look for new analyzer
binaries. These include the Windows monitor etc."""
dirpath = cwd("monitor", "latest")
# If "latest" is a symbolic link, check that it exists.
if os.path.islink(dirpath):
if not os.path.exists(dirpath):
# 抛出错误信息
throw()
# If "latest" is a file, check that it contains a legitimate hash.
elif os.path.isfile(dirpath):
monitor = os.path.basename(open(dirpath, "rb").read().strip())
if not monitor or not os.path.isdir(cwd("monitor", monitor)):
# 抛出错误信息
throw()
else:
# 抛出错误信息
throw()
cuckoo_main函数
SIGTERM信号
def stop():
if sched:
sched.running = False
if rs:
rs.instance.stop()
Pidfile("cuckoo").remove()
if sched:
sched.stop()
def handle_sigterm(sig, f):
stop()
# Handle a SIGTERM, to reduce the chance of Cuckoo exiting without
# cleaning
# 退出时, 进行一些清理工作
signal.signal(signal.SIGTERM, handle_sigterm)
关键代码
# 由于cuckoo采用的时类似cs架构, 即host通过网络传输将必要的python代码和分析工具传输给client # client, 接受样本和python代码进行分析, 然后将结果通过网络回传给host, 完成分析. rs = ResultServer() #运行host服务器 sched = Scheduler(max_analysis_count) # 初始化Scheduler(管理任务执行和调度的类) sched.start() # 开始进行任务调度
ResultServer类
主要用于与client主机进行数据传输.
构造函数
# 获取cuckoo.conf中的配置信息
ip = config("cuckoo:resultserver:ip")
port = config("cuckoo:resultserver:port")
pool_size = config('cuckoo:resultserver:pool_size')
# 绑定端口
# gevent官方介绍:
# gevent是一个基于协程的Python网络库,它使用greenlet在libev或libuv事件循环之上提供一个高级同步API
sock = gevent.socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((ip, port))
# http 服务
self.thread = threading.Thread(target=self.create_server,
args=(sock, pool_size))
self.thread.daemon = True
self.thread.start()
create_server
# create_server是创建一个http服务, 与client端进行交互.
# create_server中使用了GeventResultServerWorker, 这个类继承于gevent.server.StreamServer(http服务器)
# self.instance也会在add_task和del_task中使用
def create_server(self, sock, pool_size):
if pool_size:
pool = gevent.pool.Pool(pool_size)
else:
pool = 'default'
self.instance = GeventResultServerWorker(sock, spawn=pool)
self.instance.do_run()
del_task
# 删除一个映射, ip和task_id
def del_task(self, task, machine):
"""Delete running task and cancel existing handlers."""
self.instance.del_task(task.id, machine.ip)
add_task
# 添加一个映射, ip和task_id
def add_task(self, task, machine):
"""Register a task/machine with the ResultServer."""
self.instance.add_task(task.id, machine.ip)
Scheduler类
Scheduler类cuckoo沙箱的一个任务调度类,
initialize函数
# 关键代码 # 以virtualbox为例 # 获取虚拟机client类型, virtualbox machinery_name = self.cfg.cuckoo.machinery # 获取最大并行的虚拟机数量 max_vmstartup_count = self.cfg.cuckoo.max_vmstartup_count # 获取virtualbox的对应的管理模块, 对应的类在machinery文件夹 # cuckoo管理虚拟机通过相应的命令, 如: virtualbox # 开启虚拟机: vboxmanage startvm <uuid|vmname> # 恢复快照: vboxmanage snapshot <uuid|vmname> restore <snapshot-name> machinery = cuckoo.machinery.plugins[machinery_name]() # 读取virtualbox.conf配置信息 # 虚拟机启动的方式(headless, gui), 虚拟网卡名称(传输文件用),虚拟机的名称, 快照名称, 平台(windows/Linux) machinery.set_options(Config(machinery_name)) # 检查虚拟机是否存在,恢复快照 machinery.initialize(machinery_name)
start函数
# 关键代码
# 省略的部分代码, 包括: 错误的输出, 调试信息的输出,
# 以及使用信号量机制和锁来对虚拟机(共享资源)的运行的进行同步.
# 上面一个函数, 主要初始化虚拟机软件(virtualbox ,vmware, xenserver)
self.initialize()
# 检查host是否有足够的空间
# 目前只实现了Linux
if self.cfg.cuckoo.freespace:
dir_path = cwd("storage", "analyses")
# Linux ,return True
# Windows, return False
if hasattr(os, "statvfs"):
dir_stats = os.statvfs(dir_path.encode("utf8"))
# Calculate the free disk space in megabytes.
space_available = dir_stats.f_bavail * dir_stats.f_frsize
space_available /= 1024 * 1024
if space_available < self.cfg.cuckoo.freespace:
# ......
continue
# 为任务选择合适的虚拟机, 空闲状态, web界面可以选择合适的虚拟机进行执行样本.
for machine in self.db.get_available_machines():
import pdb; pdb.set_trace()
task = self.db.fetch(machine=machine.name)
if task:
break
if machine.is_analysis():
available = True
# 接收之后, 开始进行分析, 开启虚拟机,balablala
analysis = AnalysisManager(task.id, errors)
analysis.daemon = True
analysis.start()
self.analysis_managers.add(analysis)
待续......
文章来源: https://bbs.pediy.com/thread-260038.htm
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh