基于LLM的库API输入空间划分测试基于大语言模型的库API输入空间划分测试的研究工作《LLM Based Input Space Partitioning Testing for Library A 2024-12-16 10:44:0 Author: mp.weixin.qq.com(查看原文) 阅读量:18 收藏
基于LLM的库API输入空间划分测试
基于大语言模型的库API输入空间划分测试的研究工作《LLM Based Input Space Partitioning Testing for Library APIs》(作者:Jiageng Li,Zhen Dong,Chong Wang,Haozhen You,Cen Zhang,Yang Liu,Xin Peng)被CCF-A类国际会议ICSE 2025 47th International Conference on Software Engineering录用。
● 论文地址:https://zhendong2050.github.io/res/icse25.pdf
● 代码仓库:https://github.com/FudanSELab/LISP
在软件测试领域,准确地划分或探索待测方法的输入空间一直是经久不衰的研究问题。符号执行作为一种输入空间划分的系统方法,其可扩展性受制于“路径爆炸”、“函数建模”等问题的限制;基于搜索的软件测试技术是探索输入空间的有效方法,但其在构造能够覆盖特定代码的复杂类型输入时较为低效。
我们尝试利用LLM从业务逻辑上对待测代码进行输入空间划分。比如对于 “input:age” 的输入,其变量名称就蕴含了业务逻辑,也就是代表人的年龄,LLM很容易对输入空间进行划分(比如0<,0~200;200<),进而高效探索软件行为,达到 “在没有做符号执行的情况下达到符号执行的效果”。
为评估方法的有效性、可用性等方面,我们设计了4个RQ:
● RQ1: 相较于基于搜索的软件测试工具,基于LLM的输入空间划分测试能够达到何种程度的覆盖率?
● RQ2: 基于LLM的输入空间划分测试能否触发软件异常?是否可以发现先前未发现的软件缺陷?
● RQ3: 基于LLM的输入空间划分测试在执行时间、生成成本(幻觉、token消耗)方面效率如何?
● RQ4: 基于LLM的输入空间划分测试流程中的各步骤是否有效?
一、概述
第三方库作为软件生态系统中的重要组成部分,已经成为当今软件系统快速发展的最重要的部分之一。根据最近的一项研究,一个Java项目直接依赖14个不同的第三方库。这些库中的漏洞可能对许多软件系统造成重大风险。因此,测试库对外暴露的API是确保系统安全的关键。
然而,测试库API 是具有挑战性的,因为其通常涉及多参数构成的输入空间的探索。当这些参数涉及复杂数据类型的对象时,探索输入空间更加困难。库API的行为可能受到一个或多个输入中特定状态的限制。触发这种状态需要生成满足相关条件的输入值,以及生成语句以实例化这些对象。
这对现有的自动化测试生成技术带来了许多挑战:
● 基于搜索的测试:大多数现有技术将自动化测试生成框架视为一个优化问题,目标是在输入空间中生成输入以实现最大的代码覆盖率。例如,EvoSuite,一个广泛使用的自动化测试生成工具,采用遗传算法生成测试。这类技术的问题在于,当处理涉及多个复杂数据类型对象的库API的广泛输入空间时,效率较低;
● 符号执行:符号执行是一种有效的测试技术,可以生成覆盖所需程序路径的输入。Yannic Noller等人利用符号执行指导模糊测试,以生成覆盖深层程序行为的输入。尽管显著提高了效率,这些技术在扩展到大型程序时面临困难,因为符号执行的固有限制,例如,SPF对堆输入的支持有限。
二、方法简介
在本文中,我们将自动化测试生成视为程序输入空间的采样问题。一种理想的采样方式是 “计算输入空间的划分,然后从每个划分中选择输入”,进而覆盖所有可能的程序行为。从这个角度来看,基于搜索的方法利用启发式算法来引导搜索,旨在从尽可能多的划分中采样输入。基于符号执行的方法则尝试通过求解程序路径条件来计算输入空间的划分。这两种方法都有一定不足:前者会生成大量输入;后者则需要大量计算资源来解决路径条件。
我们提出了一种基于LLM的库API输入空间划分测试方法,即 LISP。具体而言,我们利用LLM推断待测库API的输入空间划分,然后从每个划分中采样输入,以生成高质量的测试套件。最近,LLM在理解程序和常识推理方面展示了良好的能力,从而在软件工程领域得到了广泛应用。受到这些能力的启发,我们探索使用LLM来自动化输入空间的划分,从而实现符号执行的目标,而无需明确执行它。为此,我们提出了一个框架,该框架与LLM交互,以计算给定库API的输入空间划分,并根据每个划分的文本描述生成输入值,最终得到高质量的测试输入。随后,该框架使用这些输入生成库API测试的测试套件。
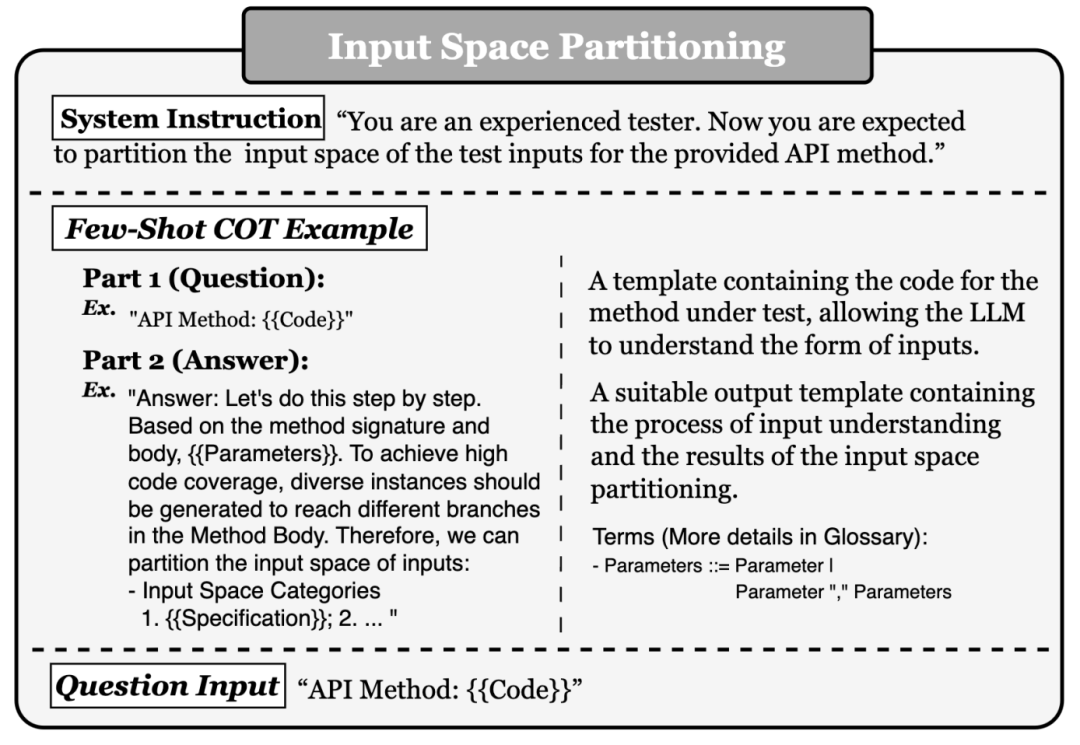
第二节中,我们提出了一个极具代表性的示例来展现LLM与输入空间划分测试间的的相性,并引出了第三节中的方法概述。
左右滑动查看更多
第三节中,我们分阶段地阐述了本文所提出的“基于LLM的输入空间划分测试”方法——“输入空间划分”、“自顶向下的类型依赖分析”和“自底向上的输入生成”三阶段,并提供了对应提示词模版。
三、实验
第四节中,首先,我们构造了五组实验组,分别是:LISP、EvoSuite 200s、EvoSuite 150s、EvoSuite 100s、LISP-CG(提供了待测方法所调用的方法的方法体,拥有更多上下文信息)和LLM-based baseline(没有LISP的三阶段流程,仅要求LLM根据输入代码和相关信息给出测试输入)。
在此基础上,我们设计了丰富的实验以回答4个研究问题。
● 覆盖率方面:LISP普遍优于其他实验组。LISP-CG的覆盖率略微高过LISP。LLM-based baseline覆盖率最低。
● 可用性方面:LISP共触发1287个异常,其中404个为非预期异常。在 404 个非预期异常中,NPE约占60%,数组越界共计约占20%。LISP发现了EvoSuite以及LLM baseline所不能发现的217个非预期异常,其中有13个被分配CVE ID。
● 开销方面:LISP为98.68% 的待测库API生成了可执行的测试输入,生成单个输入的成功率在50% 左右(根据同领域论文提供的数据,该数据是合理的)。LISP为2205个库API仅花费了42.84美元,成本处于可控范围内。
● 消融实验方面:本小节构造了ISP+OI(输入空间划分+输入生成)和TDA+OI(自顶向下的类型依赖分析/构造函数选择+输入生成)两种消融实验组。结果表明,缺少输入空间划分的TDA+OI实验组的覆盖率更低,触发非预期异常更少。
三、结论
在本工作中,我们探索了基于LLM的输入空间划分测试的可行性。我们利用了LLM丰富的背景知识以及代码理解与生成能力,根据对软件测试流程的良好抽象,将LLM与软件测试流程巧妙结合,提出了一种高度自动化的软件测试方法。
在未来的工作中,我们旨在基于现有基础进一步扩展。我们将着眼于API测试中的困难问题——多API交互下的测试生成、微服务中的API测试等等。此外,我们将深入研究软件测试与LLM相关的新兴技术(如Agent)的结合,以探索自动化软件测试的边界。我们希望LLMs能够实现测试用例的自动设计和执行、结果的全面分析,甚至提出改进建议。通过这种方式,我们不仅将提高自动化测试的有效性和准确性,还将增强其在多样化和复杂软件系统中的可扩展性。
排版丨牛嘉阳
审核丨董震
如有侵权请联系:admin#unsafe.sh