上周末做了TSG ctf,感觉这个reverse题目还挺有创意,参考了了Writeup发现他们有些点没讲出来,我再这里补充一下。先附上原文链接:https://0x90skids.com/tsg-ctf-writeup/#reverse-ing
Solved By: not-matthias
Points: 114
Flag: TSGCTF{S0r3d3m0_b1n4ry_w4_M4wa77e1ru}
拿到题目的第一件事就是检查二进制架构,目标操作系统以及是否保留了调试信息
$ file reversing reversing: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
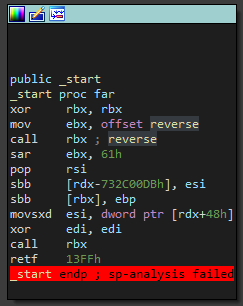
现在我们知道他是一个Linux的ELF文件,拖到IDA里面看一下_start函数,可以看到他先是跳到了reverse函数里面进行执行,但是执行完Call rbx之后,代码就变成了一团糟

reverse函数里面对_start函数进行了修改,所以每次我们从call rbx回来之后,代码都发生了变化

我最开始直接把代码复制过去,然后写了一个python脚本来转换指令,但是实话实说这个有点难而且花了我很多时间。后面@jeff_提到reverse函数调用了很多次决定采用另一种方法。我从_start函数的起始地址开始,遍历所有的代码,检查是否有jmp rbx的opcode存在。因为我们知道在跳转之前的代码都是能够正确执行的,所以我们jmp rbx之前的代码保存在输出文件中。接下来我们调用reverse函数,转换_start函数的代码,继续往下执行。
file = open('reversing', 'rb')
output = open('reversing_deobfuscated', 'wb')
original = file.read()
content = bytearray(original)
patched = bytearray(original)
SHELLCODE = 0x1BA
START = 0xE5
JMP_RBX_OPCODE = [0xFF, 0xD3]
def save(from_offset, to_offset):
for i in range(from_offset, to_offset):
patched[i] = content[i]
def reverse():
# for ( index = 106LL; index >= 0; --index )
# {
# opcode = *(shellcode - index);
# *(shellcode - index) = *(start + index);
# *(start + index) = opcode;
# }
#
for i in range(106, 0, -1):
opcode = content[SHELLCODE - i]
content[SHELLCODE - i] = content[START + i]
content[START + i] = opcode
SAVE_OFFSET = START
for IP in range(START, SHELLCODE):
# Check if the opcode is `jmp rbx`
if content[IP] == JMP_RBX_OPCODE[0] and content[IP + 1] == JMP_RBX_OPCODE[1]:
# Save the instructions that have been executed
save(SAVE_OFFSET, IP + 2)
SAVE_OFFSET = IP + 2
# Patch the `jmp rbx` instructions, since we don't need them anymore.
patched[IP] = 0x90
patched[IP + 1] = 0x90
reverse()
# Write to the output file
#
output.write(patched)
我们用IDA打开已经去混淆的二进制文件,代码已经能够读懂了。但是IDA似乎无法创建函数?及时我们手动创建,也还是会出现错误:The function has undefined instruction/data at the specified address..

从上到下看了一遍之后,我注意到没有返回状态,所以我把最后一个NOP(0x90)修改为了RET(0xC3)
之后按P创建函数,F5看伪代码

那,到了这里大家好像就觉得,“啊,就是个异或和加运算”,这样往下走就行了对不对?并不是!!!
有一点不要忘了,因为reverse函数的存在我们这里面的loc_600194里面的数据,每执行一次reverse函数,都会进行交换。
所以还是要回到汇编代码上来看
.~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~. | 48 mov cl, BYTE PTR [rsi+rdx*1] | | 53 xor cl, BYTE PTR [rdx+0x600194] | | 61 add cl, BYTE PTR [rdx+0x600194] | | 69 or rdi, rcx | | 74 dec dl | | 78 jns 0x600171 <_start+140> | |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| | 140 mov cl, BYTE PTR [rsi+rdx*1] | | 145 xor cl, BYTE PTR [rdx+0x600194] | | 153 add cl, BYTE PTR [rdx+0x600194] | | 161 or rdi, rcx | | 166 sub dl, 0x1 | | 171 jns 0x600115 <_start+48> | '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
先单步来解释一下:
1. 执行48语句,cl = input[0] 2. 切换上下文,loc_600194=[0x48, 0x80, 0x46, 0xba, 0xa5, 0xd3...],记为A 3.执行XOR cl= input[0] ^ 0x48 4.切换上下文,loc_600194=[0xE4, 0xD3, 0xFF, 0x05, 0x0F, 0x6B, 0x7C.....],记为B 5.执行加法, cl= (input[36] ^ 0xdb + 0xe4)&0xFF 6.计算$rdi = $rdi | cl ......这样循环1-6步,计算直到字符串末尾(计算过程中注意数据切换)。。。。。。。 判断是$rdi是不是0,如果是0,输出字符“correct”,否则输出“wrong”
因此写出来公式为 Input[i] ^ A[i] + B[i] = 0; i为奇数
Input[i] ^ B[i] + A[i] = 0; i为偶数
计算Flag的代码为:
X1 = [0x48, 0x80, 0x46, 0xba, 0xa5, 0xd3, 0xff, 0xc0, 0x31, 0x48, 0x1e, 0x65, 0x32, 0xa4, 0x88, 0xd3,0xff, 0xe6, 0x89, 0x48, 0x5f, 0x7a, 0x84, 0x3b, 0xd3, 0xff, 0xd2, 0x31, 0x48, 0x4e, 0x36, 0xc9,0xc5, 0xcf, 0x22, 0x32, 0x58,]
X2 = [0xe4, 0xd3, 0xff, 0x05, 0x0f, 0x6b, 0x7c, 0x13, 0xff, 0xca, 0xd3, 0xff, 0xff, 0x31, 0x48, 0x72,0x63, 0x2b, 0x19, 0x8c, 0xd3, 0xff, 0x25, 0xb2, 0x19, 0x5e, 0x61, 0xfb, 0xc1, 0xd3, 0xff, 0x00,0x60, 0x00, 0xb0, 0xbb, 0xdb,]
flag = ""
for i in range(0x25):
if i%2==0:
f = (-X2[i]^X1[i])%0x100
else:
f = (-X1[i]^X2[i])%0x100
flag += chr(f)
print(flag)
最后输出flag:TSGCTF{S0r3d3m0_b1n4ry_w4_M4wa77e1ru}
[赠书活动] 《云计算安全》和《云存储安全实践》上线!老师留下通讯地址,即可获得赠书一套!送100套,送完为止!
最后于 2小时前 被CrackM编辑 ,原因: 补充附件
如有侵权请联系:admin#unsafe.sh