2024年1月,腾讯朱雀实验室和腾讯安全科恩实验室,联合清华大学江勇教授/夏树涛教授团队、香港理工大学罗夏朴教授研究团队、上海人工智能实验室OpenCompass团队发布行业首个网络安全大模型评测平台SecBench:https://secbench.org
自SecBench上线发布以来,团队持续补充高质量的评测数据,跟进新发布的大模型开展评测。SecBench技术文章现已发布在arXiv,期待与学术界和工业界的合作伙伴共创共赢,推动网络安全大模型的发展。
1 引言
在大模型时代,除了评估大模型的通用指标外,评估其在专家领域的能力也尤为重要。在网络安全领域,现有的评测数据集普遍存在两个主要问题:1. 数据量不足,2. 评测形式单一(仅通过选择题评测)。这些问题使得现有数据集是否能全面有效地评估大模型的网络安全能力存疑。
为了解决这些挑战,我们提出了SecBench:一个大规模且多维度的数据集,用于全面评估大模型在安全领域的能力。SecBench从多个维度对大模型进行全面评测(见图1),包括:
●多能力维度:评测大模型的知识记忆(Knowledge Retention)和逻辑推理(Logical Reasoning)能力。
●多语言维度:包含中文和英文两种语言的评测数据。
●多评测形式维度:采用选择题(Multiple-Choice Question: MCQ)和问答题(Short-Answer Question: SAQ)两种题型进行立体评测。
●多子领域维度:涵盖安全管理、数据安全、网络与基础架构安全、安全标准与法规、应用安全、身份与访问控制、基础软硬件与技术、端点与主机安全、云安全等9个安全子领域的评测数据。
为了高效构建SecBench数据集并评测具有挑战性的问答题,我们提出了基于大模型的自动化数据标注和评测流程。每一条SecBench的数据都被准确地自动标注到其对应的评测维度。此外,通过构建自动化的问答题评测流程,SecBench能够高效地评估模型在回答问答题(SAQ)方面的能力。
SecBench包含44823道选择题和3087道问答题,从质和量两个角度极大地扩充了现有的大模型网络安全能力评测数据集。SecBench的详细介绍可以在我们的完整文章中找到(https://arxiv.org/abs/2412.20787)。为了促进领域的发展,我们也发布了SecBench的部分数据:https://secbench.org/dataset。
2 SecBench数据集构造
图2展示了SecBench数据集的构建过程,分为以下两步:
●初始数据集构建:我们从开源的高质量数据中进行清洗和收集,构建初始数据集。通过大模型(LLM)的自动标注,我们获得了10551道高质量的选择题。
●大规模数据集构建:为了进一步提升数据集的质量和规模,我们举办了一场面向公众的网络安全数据集构造挑战赛。通过对比赛中收集的高质量数据进行清洗和标注,我们进一步获得了34272道选择题和3087道问答题。
最终,SecBench全量数据集由以上两部分数据组成,共包含44823道选择题和3087道问答题,是目前规模最大的网络安全评测数据集。
3 SecBench数据分布
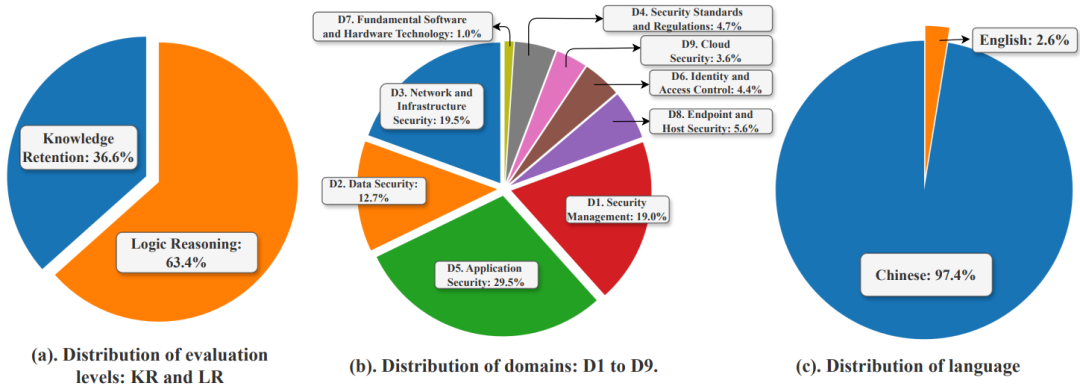
图3与图4分别表示了SecBench的选择题与问答题的数据分布情况:
知识记忆题目与逻辑推理题目分布:多数选择题(90.8%)考察知识记忆,而较多的问答题考察逻辑推理(63.4%)。
九个子领域题目分布:数据在九个子领域总体分布均匀。
题目考察语言分布:由于挑战赛收集的题目多为中文,所以最终的评测数据以中文居多。但考虑到整体数据的量级,我们仍然有相当足够的英文评测数据(包括近9000条选择题和100道问答题)。
4 Benchmarking实验
基于SecBench的测试数据,我们对总计16种不同的LLM进行Benchmarking。
●选择题评测
下表展示了基于44823道选择题对多家LLM的测试结果。表中的数字表示平均正确率。特别地,腾讯混元大模型在该项测试中列位第一 (94.28%),分数明显高于包括OpenAI o1和GPT系列在内的所有其他大模型。此外,混元大模型在逻辑推理问题 (Logical Reasoning - LR) 上的表现也显著高于其他所有模型 (93.06%),展现了其在处理具有挑战的网络安全问题时的强大性能。
●问答题评测
为了使SecBench能够自动化评测大模型解决问答题的能力,我们提出了基于Agent的自动化评分流程,如下图所示:
首先,我们将问答题的题干输入待测大模型,使其生成答案。然后,将题干、模型生成的答案和标准答案一并输入用于打分的LLM Agent。LLM Agent基于标准答案对模型生成的答案进行评分,最终输出待测模型的评分结果用于统计。
下表展示了基于3087道问答题对多家LLM的测试结果。表中的数字表示Agent给出的评分均值。从表中可看出,不同模型在处理问答题时的表现差异远大于选择题,展示了问答题设计的挑战性。在应对具有挑战性的问答题时,擅长推理的o1-preview和o1-mini模型得到了最高的分数(89.24和87.50)。另外,混元大模型的表现(得分82.13)也优于多数的现有大模型,展现出了与GPT-4o-mini(82.49)和DeepSeek-V3(83.71)同等的强悍水平。
5 总结
我们提出SecBench,大规模+多维度对大模型的网络安全能力进行评测的数据集。SecBench包含有44823道选择题和3087道问答题,从不同形式,不同考察能力,不同语言,多个子领域维度对大模型进行评测,从质与量两方面极大扩充了目前的网络安全评测数据集。
SecBench的细节详见文章:https://arxiv.org/abs/2412.20787
发布的部分数据详见:https://secbench.org/dataset
如有侵权请联系:admin#unsafe.sh