2025-1-29 20:15:14 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Table of Links
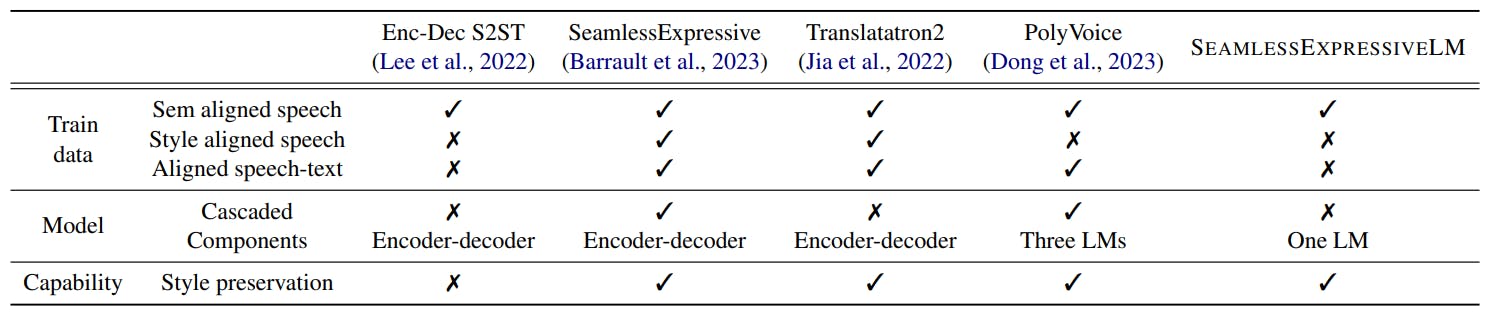
S2ST. The series of Translatotron models have encoder-decoder architecture to translate source speech into target spectrogram, which could be synthesized as waveform with a separately trained vocoder. Translatotron uses a speaker encoder to enable voice conversion in translated speech (Jia et al., 2019). Translatotron 2 removes speaker encoder from the model design for the purpose of antispoofing, and creates speaker-aligned data with a cross-lingual TTS model for model training (Jia et al., 2022). Therefore the translation model learns to transfer vocal style with a data-driven approach. Translatotron models also leverage textual supervision by using phoneme in the auxiliary task of speech recognition task.
With semantic units emerging as an efficient semantic representation of speech, unit based translation models are developed. The textless S2ST model learns to map source speech to target units without relying on textual data such as phonemes (Lee et al., 2022), and the target speech could be synthesized from semantic units with HiFi-GAN vocoder (Gong et al., 2023). Despite the good semantic quality, semantic units do not capture speaker vocal style, and thus the unit based S2ST lost the style information in speech translations. To enhance expressivity transfer, it is proposed by Duret et al. to integrate speaker and emotion encoder into the translation system. The system consists of speech-to-unit translator and unit-to-speech synthesizer with speaker and emotion embeddings.
S2ST with language model. Recent progress in acoustic units such as EnCodec (Défossez et al., 2022) and Soundstream (Zeghidour et al., 2022) capture richer acoustic and style information than semantic speech units by using multiple codebooks to encode residual information in each codebook. This also unlocked the speech language modeling in vocal style transfer (Wang et al., 2023).
With acoustic units as translation target, the translation model is trained to preserve the style of source speaker. Existing works are built upon a cascaded architecture (Dong et al., 2023; Zhang et al., 2023) consisting of speech-to-unit translation, primary acoustic unit and residual acoustic unit generation. The first component translates target semantic units from source speech. The other two components take care of speaker style transfer, and generate the first stream of acoustic units and remaining streams sequentially. This type of model has general limitations of cascaded architecture, which are inefficiency and error propagation. A multi-task learning framework is recently designed (Peng et al., 2024), which improves model efficiency by sharing parameters between the first and second components. However, it still goes

with cascaded training and inference of the three components.
We come up with SEAMLESSEXPRESSIVELM which is trained in an end-to-end manner with chain-of-thought. It shows better parameter efficiency and improved performance compared with the cascaded model.
如有侵权请联系:admin#unsafe.sh