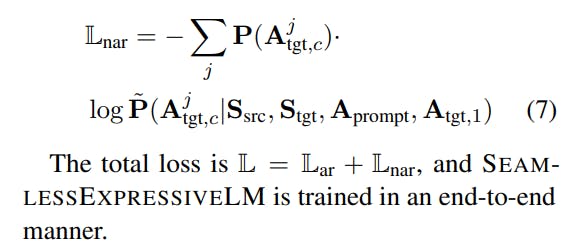
2025-1-29 20:15:7 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Table of Links
3. Model
This section introduces SEAMLESSEXPRESSIVELM, a decoder-only language model for style transferred speech-to-speech translation.
3.1 Speech Tokenizers
Speech tokenizers convert continuous speech waveform into a sequence of discrete units. HuBERT is used to derive semantic units of speech which mainly keep the semantic information (Hsu et al., 2021). EnCodec extracts multi-codebook units to carry more fine-grained acoustic information in speech such as speaker vocal style and intonation(Défossez et al., 2022). Suppose that EnCodec has C codebooks, and C = 8 in our experiments. Both HuBERT and EnCodec units are leveraged in our modeling as described below.
3.2 Architecture

As illustrated in Figure 1, the input sequence reflects the chain of thoughts in translation process. The model starts from semantic translation, proceeds to transfer the style from prompt acoustic units to the first acoustic stream and lastly learns the mapping to residual acoustic streams.
Embedding layer. We construct embedding tables for semantic and acoustic units to vectorize the speech tokens before passing them to the speech language model. For semantic units and first-stream acoustic units, their embeddings can be retrieved directly from the embedding table Emb(·). As for prompt acoustic tokens from multiple streams, we sum up embeddings from all codebooks as the acoustic embedding in each position.



3.3 Training
Acoustic prompt. Prompt acoustic units Aprompt provide all acoustic information to be preserved in the target speech. Ideally given source and target speech which both semantically and acoustically aligned, the model could simply use source units as the acoustic prompt. Now we want to relax the data requirements and use only semantically aligned speech. We carve a portion of target speech as the acoustic prompt. To prevent the model from naively copy-paste the acoustic prompt in target acoustic generation, the acoustic prompt is randomly selected at each train step and the prompt length has non-trivial effect on mdel performance. The designs of acoustic prompt is discussed in Section 5.2
AR loss. The autoregressive layers takes care of target semantic units and first-stream acoustic units. We use chain-of-thought to train the model to first translate speech semantically and then transfer speaker vocal style to the target speech. AR layers of SEAMLESSEXPRESSIVELM are trained with next token prediction similar to existing language models. It is noted that source semantic units and source acoustic units are given as the prompt, and these tokens do not count towards the training loss. Assume that P(·) is the ground truth probability (either 0 or 1) of target units.

NAR loss. In each train step, we randomly select one stream c of acoustic units for NAR layers to predict.

3.4 Inference
The model decodes target semantic units with beam search, and then generates acoustic units with temperature sampling. Target speech is synthesized by EnCodec decoder from predicted acoustic units.
如有侵权请联系:admin#unsafe.sh