2020-09-06 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:278 收藏
Published at 2020-09-06 | Last Update 2020-09-06
译者序
本文翻译自 2020 年 Daniel Borkmann 在 KubeCon 的一篇分享: eBPF and Kubernetes: Little Helper Minions for Scaling Microservices, 视频见油管。 翻译已获得 Daniel 授权。
Daniel 是 eBPF 两位 maintainer 之一,目前在 eBPF commits 榜单上排名第一,也是 Cilium 的核心开发者之一。
本文内容的时间跨度有 8 年,覆盖了 eBPF 发展的整个历史,非常值得一读。时间限制, Daniel 很多地方只是点到,没有展开。译文中加了一些延展阅读,有需要的同学可以参考。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
- 译者序
- 1 eBPF 正在吞噬世界
- 2 内核面临的挑战
- 3 eBPF 降世:重新定义数据平面(datapth)
- 4 eBPF 长什么样,怎么用?Cilium eBPF networking 案例研究
- 5 温故:kube-proxy 包转发路径
- 6 知新:Cilium eBPF 包转发路径
- 7 eBPF 年鉴
- 8 eBPF:过去 50 年操作系统最大的变革
- 9 eBPF 数字榜单(截至 2020.07)
- 10 业界趋势
- 11 eBPF 革命:燃烧到 Kubernetes 社区
- 12 eBPF 和 Kubernetes:未来展望
- 13 结束语
以下是译文。
1.1 Kubernetes 已经是云操作系统
Kubernetes 正在吞噬世界(eating the world)。越来越多的企业开始迁移到容器平台上 ,而 Kubernetes 已经是公认的云操作系统(Cloud OS)。从技术层面来说,
- Linux 内核是一切的坚实基础,例如,内核提供了 cgroup、namespace 等特性。
-
Kubernetes CNI 插件串联起了关键路径(critical path)上的组件。例如,从网络的 视角看,包括,
- 广义的 Pod 连通性:一个容器创建之后,CNI 插件会给它创建网络设备,移动到容 器的网络命名空间。
- IPAM:CNI 向 IPAM 发送请求,为容器分配 IP 地址,然后配置路由。
- Kubernetes 的 Service 处理和负载均衡功能。
- 网络策略的生效(network policy enforcement)。
- 监控和排障。
1.2 两个清晰的容器技术趋势
今天我们能清晰地看到两个技术发展趋势:
- 容器的部署密度越来越高(increasing Pod density)。
- 容器的生命周期越来越短(decreasing Pod lifespan)。甚至短到秒级或毫秒级。
大家有兴趣的可以查阅相关调查:
从操作系统内核的角度看,我们面临很多挑战。
2.1 复杂度性不断增长,性能和可扩展性新需求
内核,或者说通用内核(general kernel),必须在子系统复杂度不断增长( increasing complexity of kernel subsystems)的前提下,满足这些性能和可扩展性 需求(performance & scalability requirements)。
2.2 永远保持后向兼容
Linus torvalds 的名言大家都知道:never break user space。
这对用户来说是好事,但对内核开发者来说意味着:我们必须保证在引入新代码时,五年前 甚至十几年前的老代码仍然能正常工作。
显然,这会使原本就复杂的内核变得更加复杂,对于网络来说,这意味着快速收发包路径 (fast path)将受到影响。
2.3 Feature creeping normality
开发者和用户不断往内核加入新功能,导致内核非常复杂,现在已经没有一个人能理解所有东西了。
Wikipedia 对 creeping normality 的定义:
Def. creeping normality: … is a process by which a major change can be accepted as normal and acceptable if it happens slowly through small, often unnoticeable, increments of change. The change could otherwise be regarded as objectionable if it took place in a single step or short period.
应用到这里,意思就是:内核不允许一次性引入非常大的改动,只能将它们拆 分成数量众多的小 patch,每次合并的 patch 保证系统后向兼容,并且对系统的影响非 常小。

来看 Linus torvalds 的原话:
Linus Torvalds on crazy new kernel features:
So I can work with crazy people, that’s not the problem. They just need to sell their crazy stuff to me using non-crazy arguments, and in small and well-defined pieces. When I ask for killer features, I want them to lull me into a safe and cozy world where the stuff they are pushing is actually useful to mainline people first.
In other words, every new crazy feature should be hidden in a nice solid “Trojan Horse” gift: something that looks obviously good at first sight.
Linus Torvalds,
https://lore.kernel.org/lkml/[email protected]/
这就是我们最开始想将 eBPF 合并到内核时遇到的问题:改动太大,功能太新(a crazy new kernel feature)。
但是,eBPF 带来的好处也是无与伦比的。
首先,从长期看,eBPF 这项新功能会减少未来的 feature creeping normality。 因为用户或开发者希望内核实现的功能,以后不需要再通过改内核的方式来实现了。 只需要一段 eBPF 代码,实时动态加载到内核就行了。
其次,因为 eBPF,内核也不会再引入那些影响 fast path 的蹩脚甚至 hardcode 代码 ,从而也避免了性能的下降。
第三,eBPF 还使得内核完全可编程,安全地可编程(fully and safely programmable ),用户编写的 eBPF 程序不会导致内核 crash。另外,eBPF 设计用来解决真实世界 中的线上问题,而且我们现在仍然在坚守这个初衷。
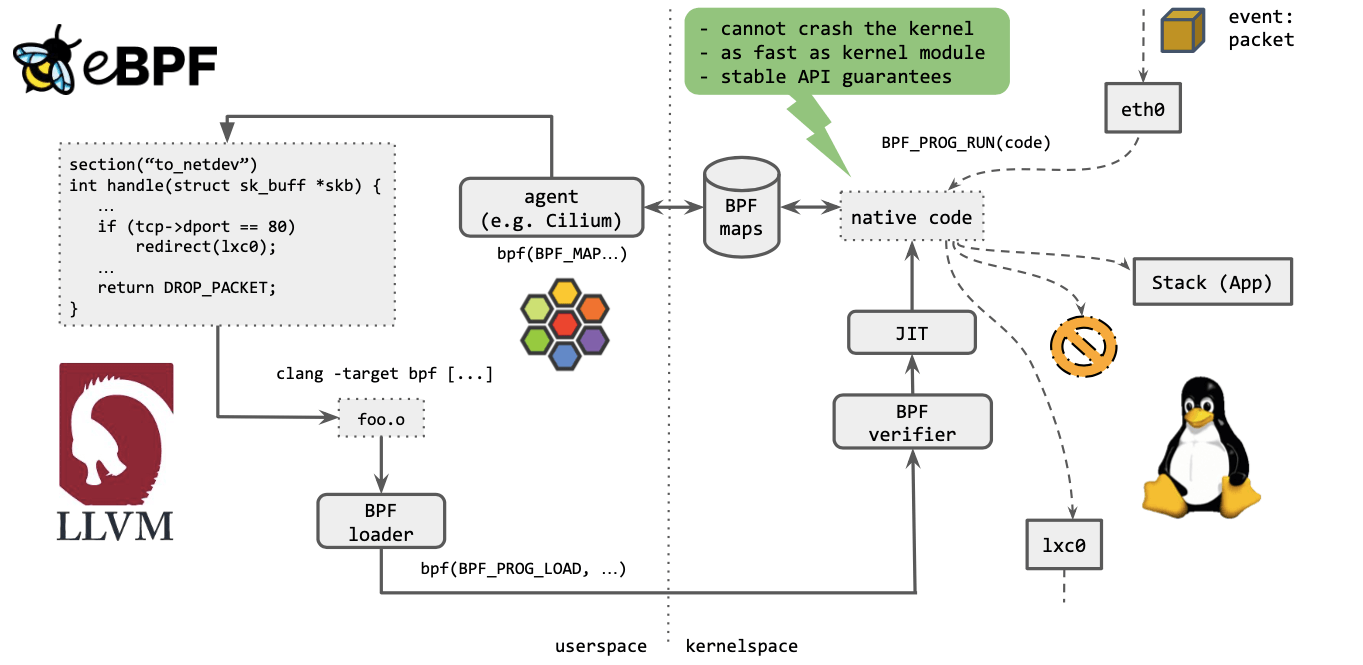
eBPF 程序长什么样?如下图所示,和 C 语言差不多,一般由用户空间 application 或 agent 来生成。
4.1 Cilium eBPF 流程
下面我们将看看 Cilium 是如何用 eBPF 实现容器网络方案的。
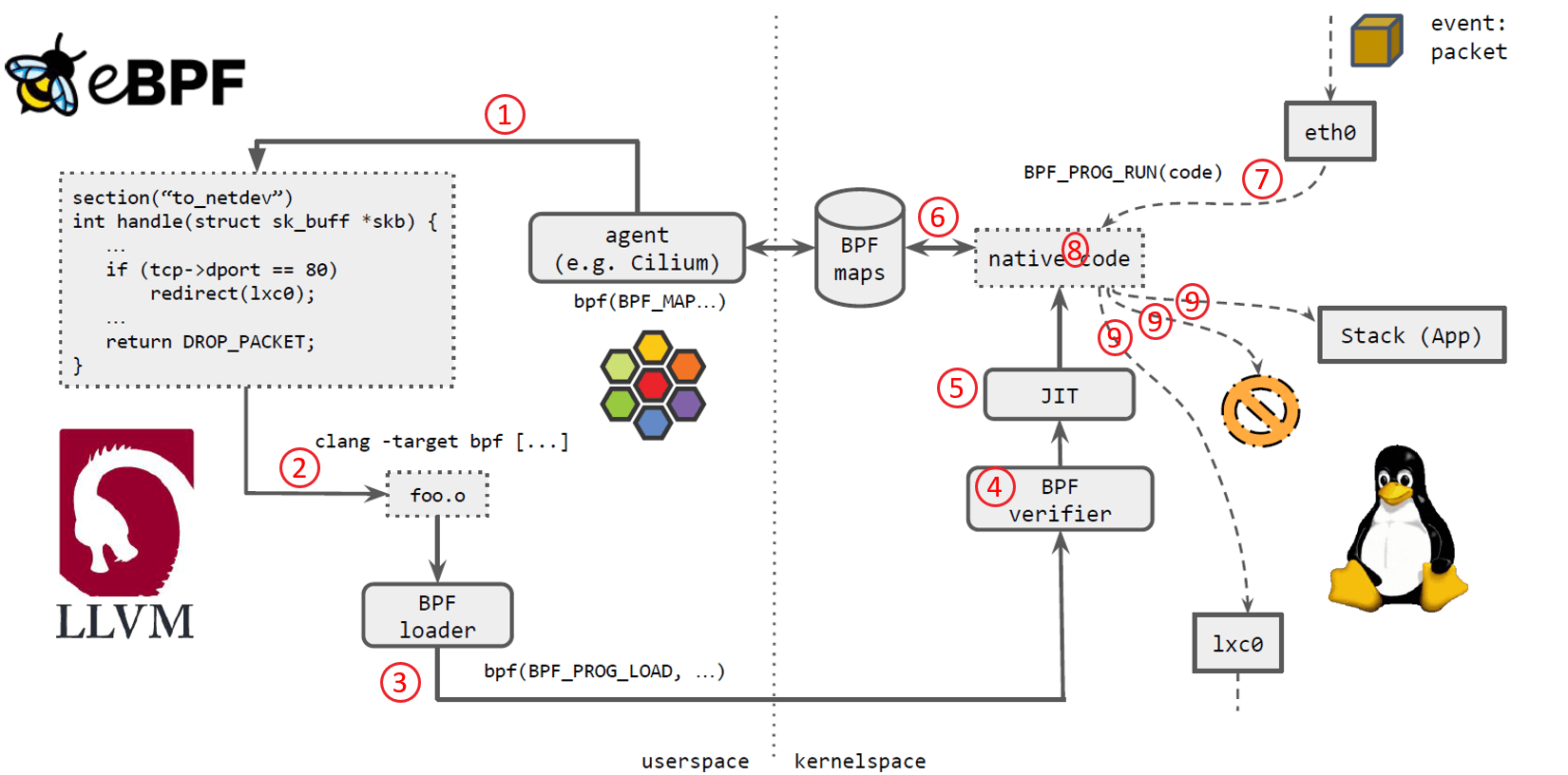
如上图所示,几个步骤:
- Cilium agent 生成 eBPF 程序。
- 用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,
*.o)。 - 用 eBPF loader 将对象文件加载到 Linux 内核。
- 校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
- 对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
- 如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储 ,BPF 侧和用户侧都可以访问。
- BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
- BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
- 根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
4.2 eBPF 特点
- 最重要的一点:不能 crash 内核。
- 执行起来,与内核模块(kernel module)一样快。
- 提供稳定的 API。
这意味着什么?简单来说,如果一段 BPF 程序能在老内核上执行,那它一定也能继续在新 内核上执行,而无需做任何修改。
这就像是内核空间与用户空间的契约,内核保证对用户空间应用的兼容性,类似地,内核也 会保证 eBPF 程序的兼容性。
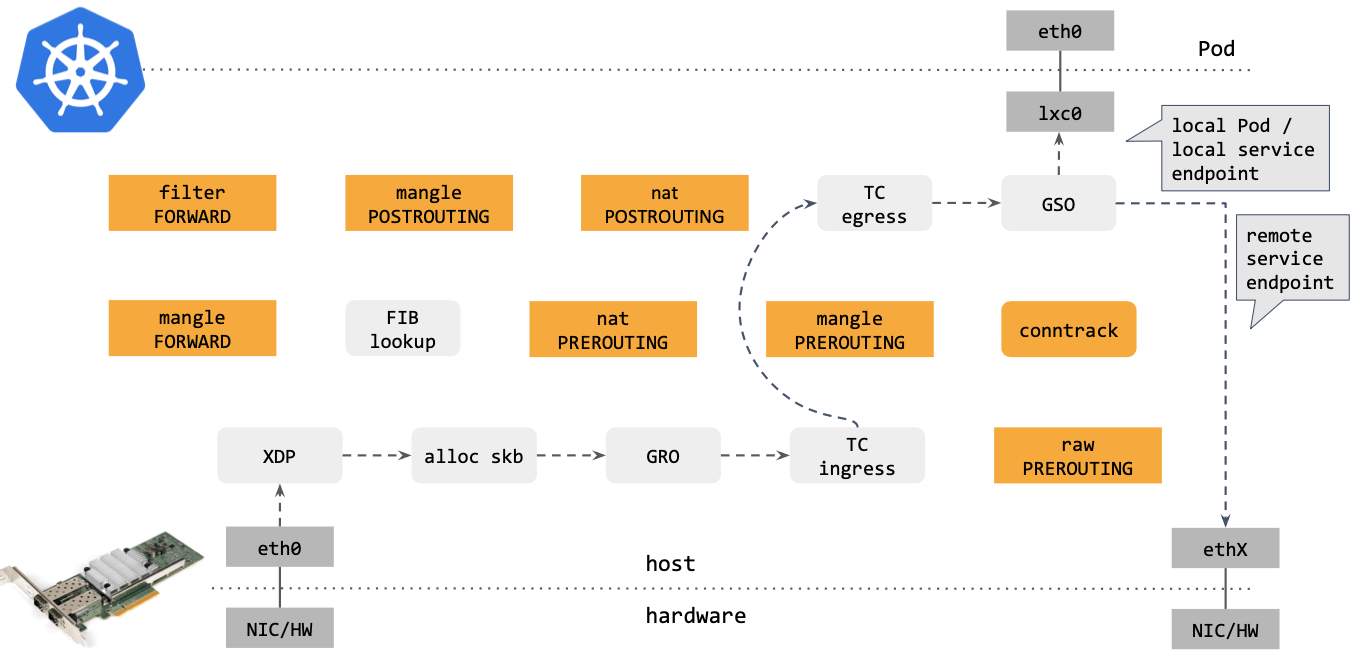
从网络角度看,使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图所示:
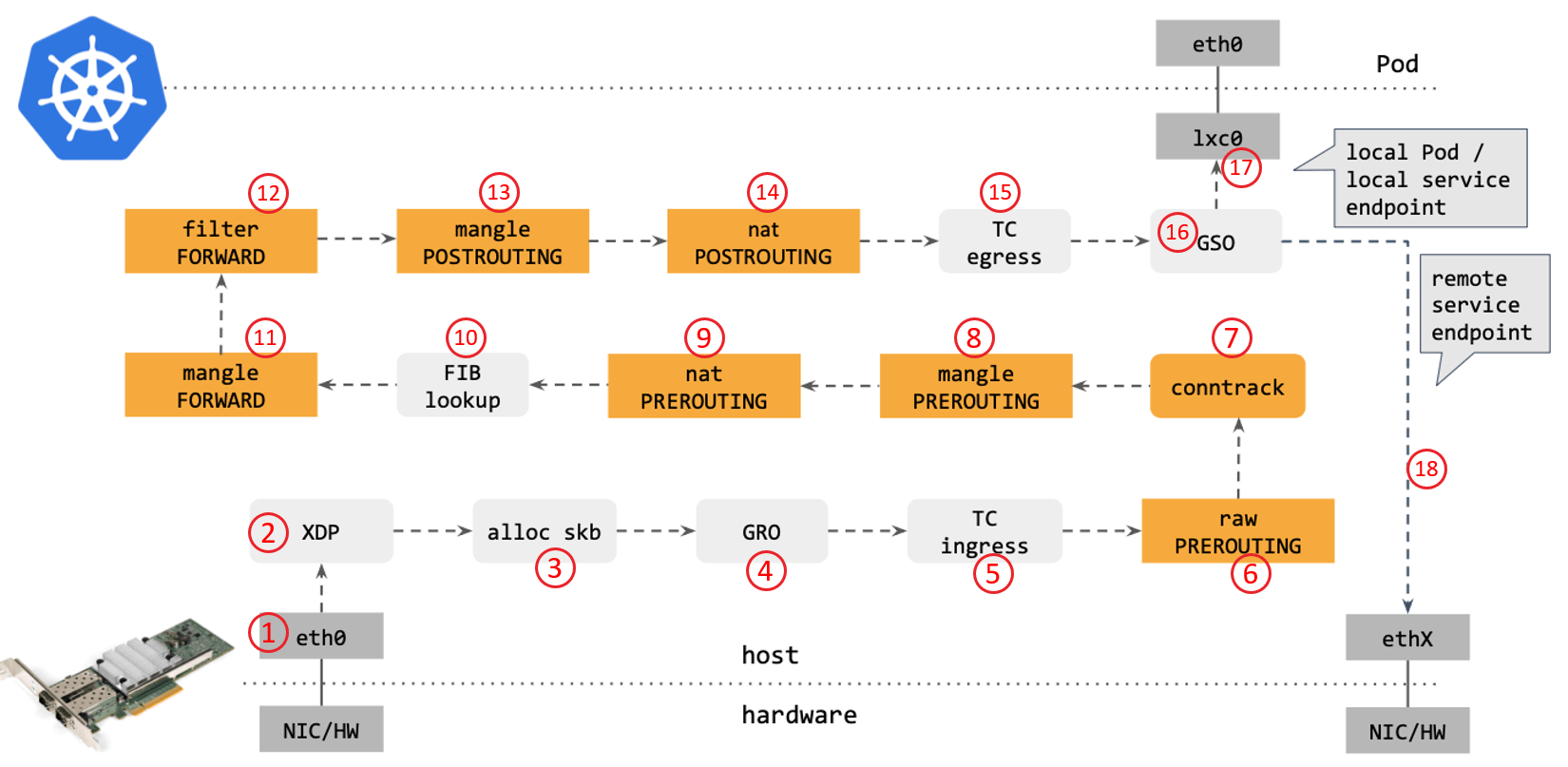
步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的
skb(包的内核结构体表示),然后 送到内核协议栈。 - 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在
PREROUTINGhook 点处理rawtable 里的 iptables 规则。 - 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在
PREROUTINGhook 点处理mangletable 的 iptables 规则。 - Netfilter:在
PREROUTINGhook 点处理nattable 的 iptables 规则。 - 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在
FORWARDhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
FORWARDhook 点处理filtertable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理nattable 里的 iptables 规则。 - 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去。
相关阅读,有助于理解以上过程:
- Cracking Kubernetes Node Proxy (aka kube-proxy)
- (译) 深入理解 iptables 和 netfilter 架构
- 连接跟踪(conntrack):原理、应用及 Linux 内核实现
- (译) 深入理解 Cilium 的 eBPF 收发包路径(datapath)
译者注。
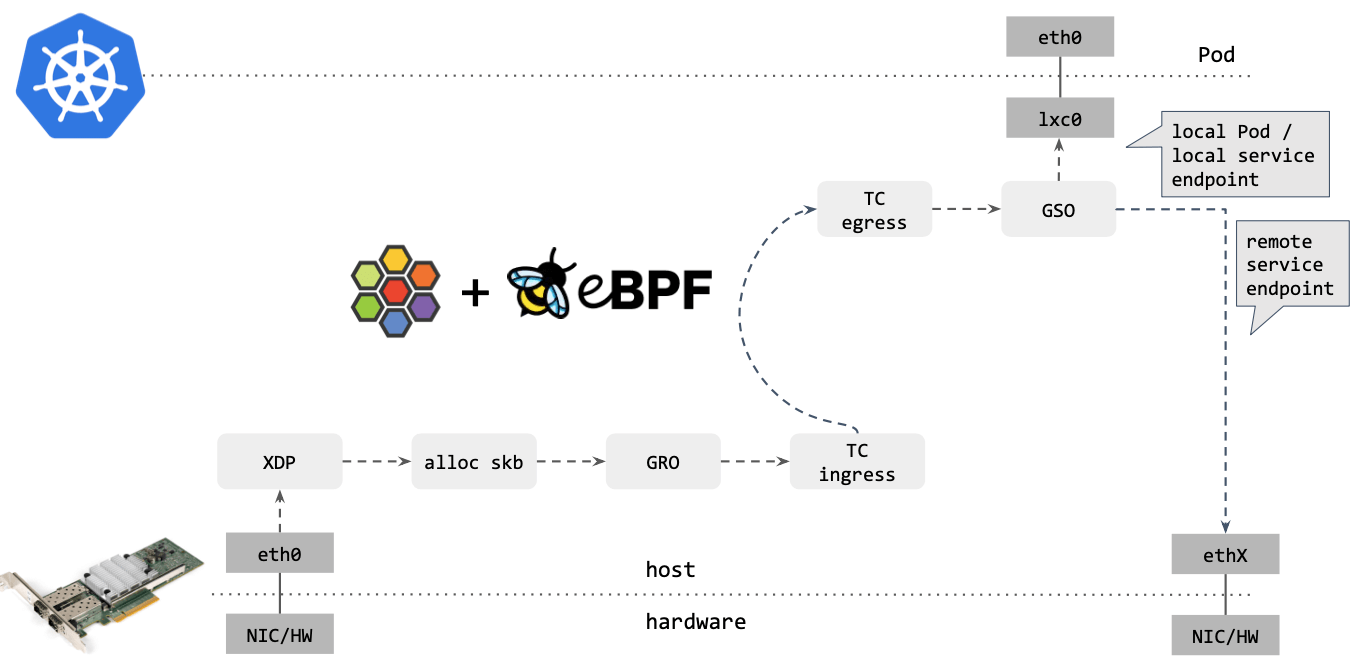
作为对比,再来看下 Cilium eBPF 中的包转发路径:
建议和 (译) 深入理解 Cilium 的 eBPF 收发包路径(datapath) 对照看。
译者注。
对比可以看出,Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
去掉那些不用的框之后,Cilium eBPF datapath 长这样:
Cilium/eBPF 还能走的更远。例如,如果包的目的端是另一台主机上的 service
endpoint,那你可以直接在 XDP 框中完成包的重定向(收包 1->2,在步骤 2 中对包
进行修改,再通过 2->1 发送出去),将其发送出去,如下图所示:

可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb)就被转 发出去了,性能可想而知。
XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,而无需将包送 到复杂的协议栈进行处理,因此处理代价很小,速度极快。
eBPF 是如何诞生的呢?我最初开始讲起。这里“最初”我指的是 2013 年之前。
2013
前浪工具和子系统
回顾一下当时的 “SDN” 蓝图。
- 当时有 OpenvSwitch(OVS)、
tc(Traffic control),以及内核中的 Netfilter 子系 统(包括iptables、ipvs、nftalbes工具),可以用这些工具对 datapath 进行“ 编程”:。 - BPF 当时用于
tcpdump,在内核中尽量前面的位置抓包,它不会 crash 内核;此 外,它还用于 seccomp,对系统调用进行过滤(system call filtering),但当时 使用的非常受限,远不是今天我们已经在用的样子。 - 此外就是前面提到的 feature creeping 问题,以及 tc 和 netfilter 的代码重复问题,因为这两个子系统是竞争关系。
- OVS 当时被认为是内核中最先进的数据平面,但它最大的问题是:与内核中其他网 络模块的集成不好【译者注 1】。此外,很多核心的内核开发者也比较抵触 OVS,觉得它很怪。
【译者注 1】
例如,OVS 的 internal port、patch port 用 tcpdump 都是 抓不到包的,排障非常不方便。
eBPF 与前浪的区别
对比 eBPF 和这些已经存在很多年的工具:
- tc、OVS、netfilter 可以对 datapath 进行“编程”:但前提是 datapath 知道你想做什
么(but only if the datapath knows what you want to do)。
- 只能利用这些工具或模块提供的既有功能。
- eBPF 能够让你创建新的 datapath(eBPF lets you create the datapath instead)。
- eBPF 就是内核本身的代码,想象空间无限,并且热加载到内核;换句话说,一旦加 载到内核,内核的行为就变了。
- 在 eBPF 之前,改变内核行为这件事情,只能通过修改内核再重新编译,或者开发内 核模块才能实现。
译者注
eBPF:第一个(巨型)patch
- 描述 eBPF 的 RFC 引起了广泛讨论,但普遍认为侵入性太强了(改动太大)。
- 另外,当时 nftables (inspired by BPF) 正在上升期,它是一个与 eBPF 有点类似的 BPF 解释器,大家不想同时维护两个解释器。
最终这个 patch 被拒绝了。
被拒的另外一个原因是前面提到的,没有遵循“大改动小提交”原则,全部代码放到了一个 patch。Linus 会疯的。
2014
第一个 eBPF patch 合并到内核
- 用一个扩展(extended)指令集逐步、全面替换原来老的 BPF 解释器。
- 自动新老 BPF 转换:in-kernel translation。
- 后续 patch 将 eBPF 暴露给 UAPI,并添加了 verifier 代码和 JIT 代码。
- 更多后续 patch,从核心代码中移除老的 BPF。
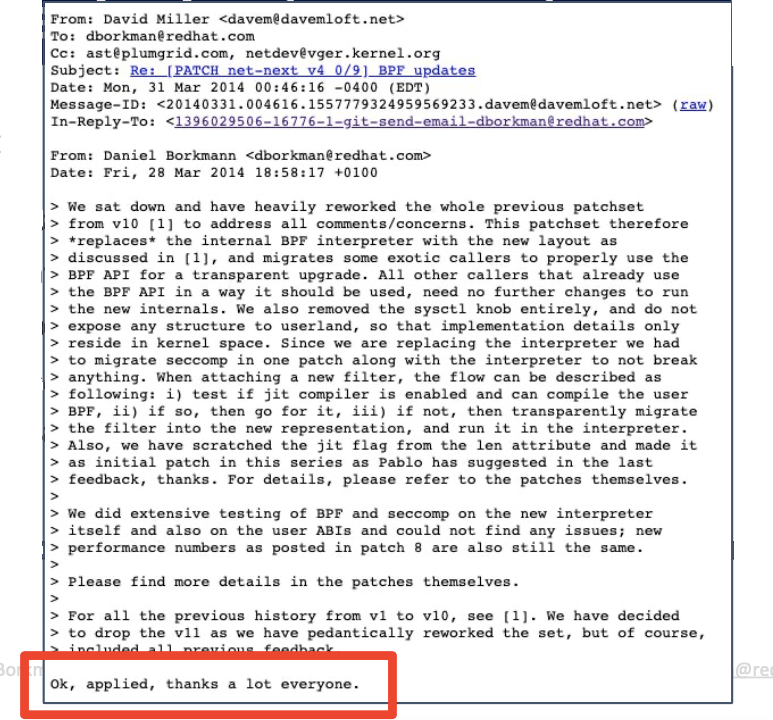
我们也从那时开始,顺理成章地成为了 eBPF 的 maintainer。
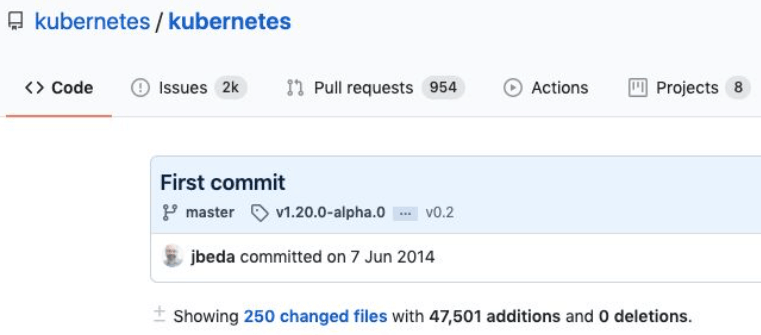
Kubernetes 提交第一个 commit
巧合的是,对后来影响深远的 Kubernetes,也在这一年提交了第一个 commit:
2015
eBPF 分成两个方向:networking & tracing
到了 2015 年,eBPF 开发分成了两个方向:
- networking
- tracing
eBPF backend 合并到 LLVM 3.7
这一年的一个重要里程碑是 eBPF backend 合并到了 upstream LLVM 编译器套件,因此你 现在才能用 clang 编译 eBPF 代码。
支持将 eBPF attach 到 kprobes
这是 tracing 的第一个使用案例。
Alexei 主要负责 tracing 部分,他添加了一个 patch,支持加载 eBPF 用来做 tracing, 能获取系统的观测数据。
通过 cls_bpf,tc 变得完全可编程
我主要负责 networking 部分,使 tc 子系统可编程,这样我们就能用 eBPF 来灵活的对 datapath 进行编程,获得一个高性能 datapath。
为 tc 添加了一个 lockless ingress & egress hook 点
添加了很多 verifer 和 eBPF 辅助代码(helper)
使用更方便。
bcc 项目发布
作为 tracing frontend for eBPF。
2016
eBPF 添加了一个新 fast path:XDP
- XDP 合并到内核,支持在驱动的 ingress 层 attach BPF 程序。
- nfp 最为第一家网卡及驱动,支持将 eBPF 程序 offload 到 cls_bpf & XDP hook 点。
Cilium 项目发布
Cilium 最开始的目标是 docker 网络解决方案。
- 通过 eBPF 实现高效的 label-based policy、NAT64、tunnel mesh、容器连通性。
- 整个 datapath & forwarding 逻辑全用 eBPF 实现,不再需要 Docker 或 OVS 桥接设备。
2017
eBPF 开始大规模应用于生产环境
2016 ~ 2017 年,eBPF 开始应用于生产环境:
- Netflix on eBPF for tracing: ‘Linux BPF superpowers’
- Facebook 公布了生产环境 XDP+eBPF 使用案例(DDoS & LB)
- 用 XDP/eBPF 重写了原来基于 IPVS 的 L4LB,性能
10x。 - eBPF 经受住了严苛的考验:从 2017 开始,每个进入 facebook.com 的包,都是经过了 XDP & eBPF 处理的。
- 用 XDP/eBPF 重写了原来基于 IPVS 的 L4LB,性能
- Cloudflare 将 XDP+BPF 集成到了它们的 DDoS mitigation 产品。
- 成功将其组件从基于 Netfilter 迁移到基于 eBPF。
- 到 2018 年,它们的 XDP L4LB 完全接管生产环境。
- 扩展阅读:(译) Cloudflare 边缘网络架构:无处不在的 BPF(2019)
译者注:基于 XDP/eBPF 的 L4LB 原理都是类似的,简单来说,
- 通过 BGP 宣告 VIP
- 通过 ECMP 做物理链路高可用
- 通过 XDP/eBPF 代码做重定向,将请求转发到后端(VIP -> Backend)
对此感兴趣可参考入门级介绍:L4LB for Kubernetes: Theory and Practice with Cilium+BGP+ECMP
2017 ~ 2018
eBPF 成为内核独立子系统
随着 eBPF 社区的发展,feature 和 patch 越来越多,为了管理这些 patch,Alexei、我和 networking 的一位 maintainer David Miller 经过讨论,决定将 eBPF 作为独立的内核子 系统。
- eBPF patch 合并到
bpf&bpf-nextkernel trees on git.kernel.org - 拆分 eBPF 邮件列表:
[email protected](archive at:lore.kernel.org/bpf/) - eBPF PR 经内核网络部分的 maintainer David S. Miller 提交给 Linus Torvalds
kTLS & eBPF
kTLS & eBPF for introspection and ability for in-kernel TLS policy enforcement
kTLS 是将 TLS 处理 offload 到内核,例如,将加解密过程从 openssl 下放到内核进 行,以使得内核具备更强的可观测性(gain visibility)。
有了 kTLS,就可以用 eBPF 查看数据和状态,在内核应用安全策略。 目前 openssl 已经完全原生支持这个功能。
bpftool & libbpf
为了检查内核内 eBPF 的状态(introspection)、查看内核加载了哪些 BPF 程序等, 我们添加了一个新工具 bpftool。现在这个工具已经功能非常强大了。
同样,为了方便用户空间应用使用 eBPF,我们提供了用户空间 API(user space API
for applications) libbpf。这是一个 C 库,接管了所有加载工作,这样用户就不需要
自己处理复杂的加载过程了。
BPF to BPF function calls
增加了一个 BPF 函数调用另一个 BPF 函数的支持,使得 BPF 程序的编写更加灵活。
2018
Cilium 1.0 发布
这标志着 BPF 革命之火燃烧到了 Kubernetes networking & security 领域。
Cilium 此时支持的功能:
- K8s CNI
- Identity-based L3-L7 policy
- ClusterIP Services
BTF(Byte Type Format)
内核添加了一个称为 BTF 的组件。这是一种元数据格式,和 DWARF 这样的 debugging data 类似。但 BTF 的 size 要小的多,而更重要的是,有史以来,内核第一次变得可自 描述了(self-descriptive)。什么意思?
想象一下当前正在运行中的内核,它内置了自己的数据格式(its own data format) 和内部数据结构(internal structures),你能用工具来查看这些东西(you can introspect them)。还是不太懂?这么说吧,BTF 是后来的 “一次编译、到处运行”、 热补丁(live-patching)、BPF global data 处理等等所有这些 BPF 特性的基础。
新的特性不断加入,它们都依赖 BTF 提供富元数据(rich metadata)这个基础。
更多 BTF 内容,可参考 (译) Cilium:BPF 和 XDP 参考指南(2019)
译者注
Linux Plumbers 会议开辟 BPF/XDP 主题
这一年,Linux Plumbers 会议第一次开辟了专门讨论 BPF/XDP 的微型分会,我们 一起组织这场会议。其中,Networking Track 一半以上的议题都涉及 BPF 和 XDP 主题,因为这是一个非常振奋人心的特性,越来越多的人用它来解决实际问题。
新 socket 类型:AF_XDP
内核添加了一个新 socket 类型 AF_XDP。它提供的能力是:在零拷贝(
zero-copy)的前提下将包从网卡驱动送到用户空间。
回忆前面的内容,数据包到达网卡后,先经过 XDP,然后才为这个包分配内存。 因此在 XDP 层直接将包送到用户态是无需拷贝的。
译者注
AF_XDP 提供的能力与 DPDK 有点类似,不过
- DPDK 需要重写网卡驱动,需要额外维护用户空间的驱动代码。
AF_XDP在复用内核网卡驱动的情况下,能达到与 DPDK 一样的性能。
而且由于复用了内核基础设施,所有的网络管理工具还都是可以用的,因此非常方便, 而 DPDK 这种 bypass 内核的方案导致绝大大部分现有工具都用不了了。
由于所有这些操作都是发生在 XDP 层的,因此它称为 AF_XDP。插入到这里的 BPF 代码
能直接将包送到 socket。
bpffilter
开始了 bpffilter prototype,作用是通过用户空间驱动(userspace driver),将 iptables 规则转换成 eBPF 代码。
这是将 iptables 转换成 eBPF 的第一次尝试,整个过程对用户都是无感知的,其中的某些 组件现在还在用,用于在其他方面扩展内核的功能。
2018 ~ 2019
bpftrace
Brendan 发布了 bpftrace 工具,作为 DTrace 2.0 for Linux。
BPF 专著《BPF Performance Tools》
Berendan 写了一本 800 多页的 BPF 书。
Cilium 1.6 发布
第一次支持完全干掉基于 iptables 的 kube-proxy,全部功能基于 eBPF。
这个版本其实是有问题的,例如 1.6 发布之后我们发现 externalIPs 的实现是有问题 ,社区在后面的版本修复了这个问题。在修复之前,还是得用 kube-proxy: https://github.com/cilium/cilium/issues/9285
译者注
BPF live-patching
添加了一些内核新特性,例如尾调用(tail call),这使得 eBPF 核心基础 设施第一次实现了热加载。这个功能帮我们极大地优化了 datapath。
另一个重要功能是 BPF trampolines,这里就不展开了,感兴趣的可以搜索相关资料,我只 能说这是另一个振奋人心的技术。
第一次 bpfconf:受邀请才能参加的 BPF 内核专家会议
如题,这是 BPF 内核专家交换想法和讨论问题的会议。与 Linux Plumbers 会议互补。
BPF backend 合并到 GCC
前面提到,BPF backend 很早就合并到 LLVM/Clang,现在,它终于合并到 GCC 了。 至此,GCC 和 LLVM 这两个最主要的编译器套件都支持了 BPF backend。
此外,BPF 开始支持有限循环(bounded loops),在此之前,是不支持循环的,以防止程 序无限执行。
2019 ~ 2020
不知疲倦的增长和 eBPF 的第三个方向:Linux security modules
- Google 贡献了 BPF LSM(安全),部署在了他们的数据中心服务器上。
- BPF verifier 防护 Spectre 漏洞(2018 年轰动世界的 CPU bug):even verifying safety on speculative program paths。
- 主流云厂商开始通过 SRIOV 支持 XDP:AWS (ena driver), Azure (hv_netvsc driver), …
- Cilium 1.8 支持基于 XDP 的 Service 负载均衡和 host network policies。
- Facebook 开发了基于 BPF 的 TCP 拥塞控制模块。
- Microsoft 基于 BPF 重写了将他们的 Windows monitoring 工具。
Brendan 说在他的职业生涯中,eBPF 是他见过的操作系统中最大的变革之一(one of the biggest operating system changes),他为能身处其中而感到非常兴奋。
我接下来只能用数字证明:Brendan 的兴奋是没错的。
eBPF 内核社区截至 7 月份的一些数据:
- 347 个贡献者,贡献了 4,935 个 patch 到 BPF 子系统。
- BPF 内核邮件列表日均 50 封邮件 (高峰经常超过日均 100)。
- 23,395 mails since mailing list git archive was added in Feb 2019
- 每天合并 4 个新 patch。patch 接受率 30% 左右。
- 30 个程序(different program),27 种 BPF map 类型,141 个 BPF helpers,超过 3,500 个测试。
- 2 个 BPF kernel maintainers & team of 6 senior core reviewers。
- 主要贡献来自:Isovalent(Cilium), Facebook and Google
毫无疑问,这是内核里发展最快的子系统!
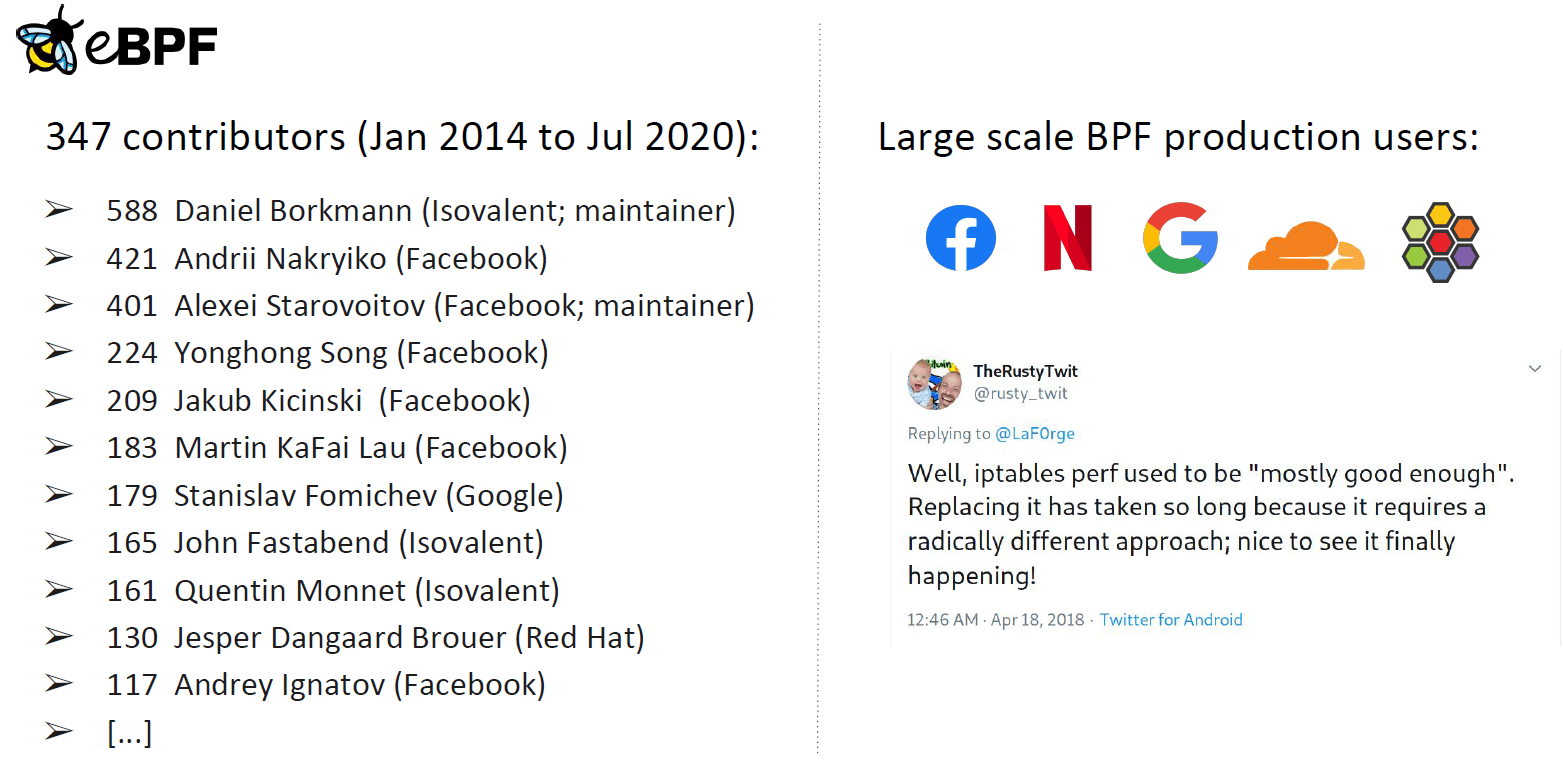
注意贡献榜排名第一的就是演讲者本人,译者注。
列举几个生产环境大规模使用 BPF 的大厂:
- Facebook:L4LB、DDoS、tracing。
- Netflix:BPF 重度用户,例如生产环境 tracing。
- Google:Android、服务器安全以及其他很多方面。
- Cloudflare:L4LB、DDoS。
- Cilium
上图中,右下角是前 Netfilter 维护者 Rusty Russel 说的一句,业界对 eBPF 的受认可程度可窥一斑。
eBPF 已无处不在,而你还在使用 iptables?
11.1 干掉 kube-proxy/iptables
不用再忍受 iptables 复杂冗长的规则和差劲的性能了,以前没得选,现在你可以做个好人:
$ kubectl -n kube-system delete ds kube-proxy
作为例子,我们来看看 Cilium 是怎么做 Service 的负载均衡的。
Service 细节实现可参考 Cracking Kubernetes Node Proxy (aka kube-proxy)。
译者注。
11.2 Cilium 的 Service load balancing 设计
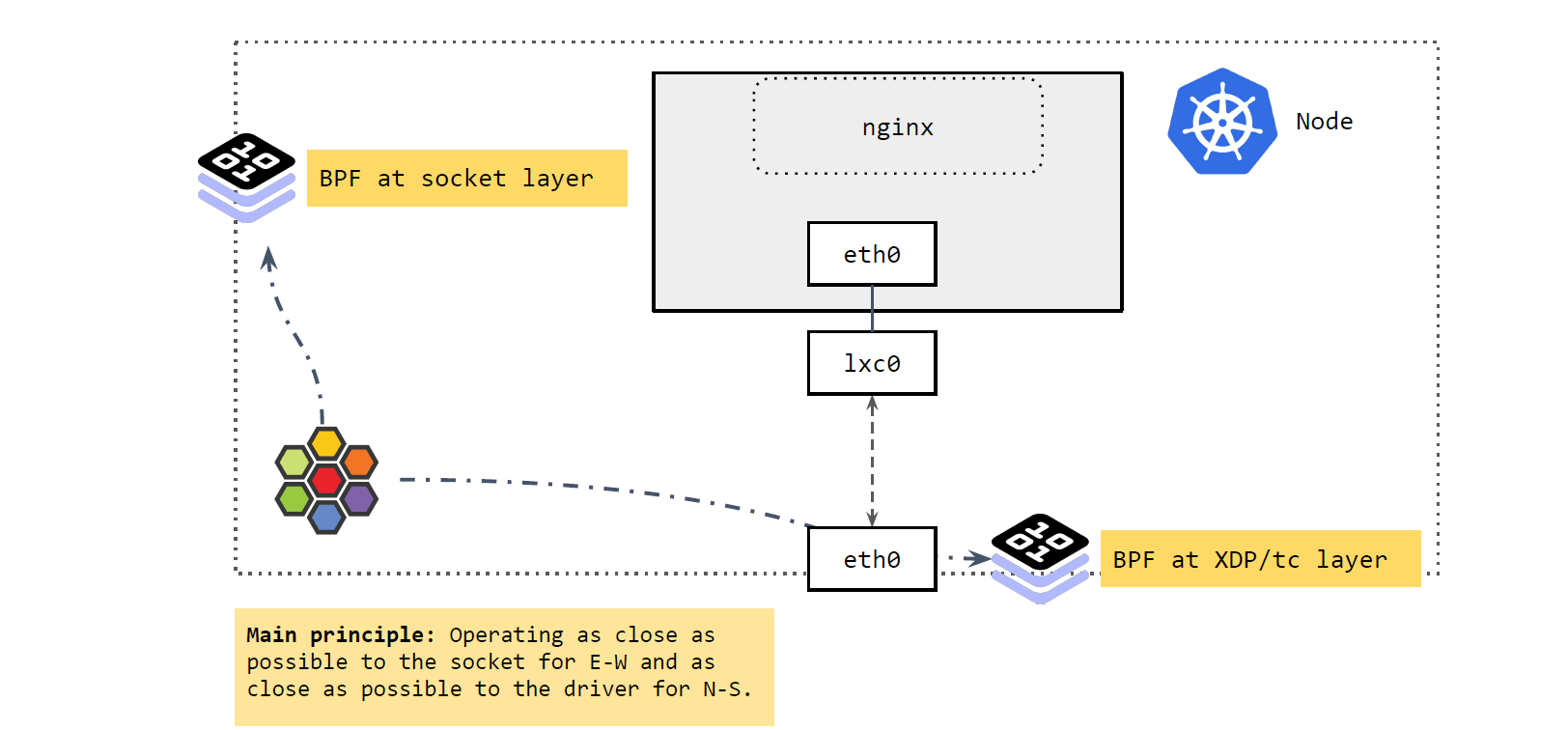
如上图所示,主要涉及两部分:
- 在 socket 层运行的 BPF 程序
- 在 XDP 和 tc 层运行的 BPF 程序
东西向流量
我们先来看 socker 层。
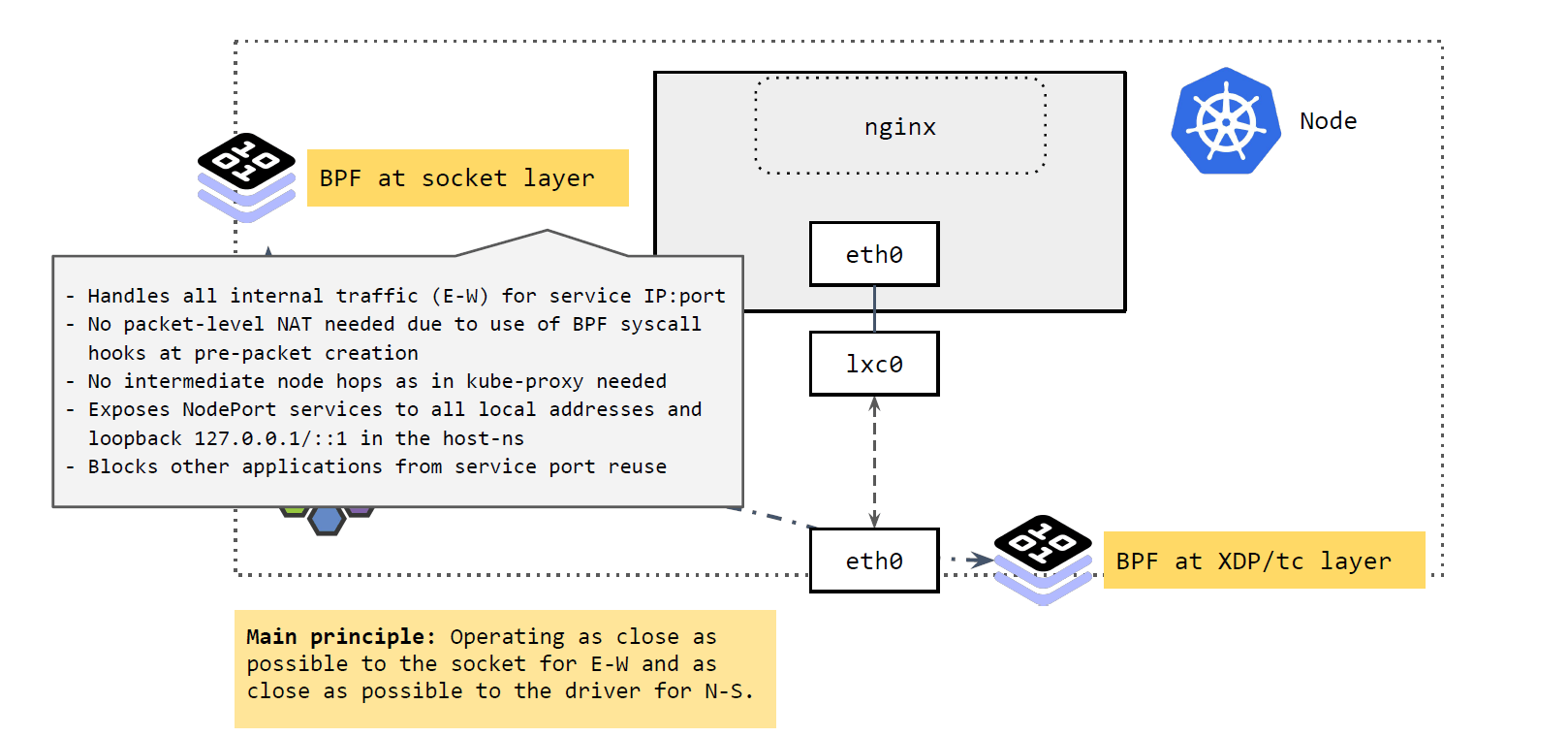
如上图所示,
Socket 层的 BPF 程序主要处理 Cilium 节点的东西向流量(E-W)。
- 将 Service 的
IP:Port映射到具体的 backend pods,并做负载均衡。 - 当应用发起 connect、sendmsg、recvmsg 等请求(系统调用)时,拦截这些请求,
并根据请求的
IP:Port映射到后端 pod,直接发送过去。反向进行相反的变换。
这里实现的好处:性能更高。
- 不需要包级别(packet leve)的地址转换(NAT)。在系统调用时,还没有创建包,因此性能更高。
- 省去了 kube-proxy 路径中的很多中间节点(intermediate node hops)
可以看出,应用对这种拦截和重定向是无感知的(符合 k8s Service 的设计)。
南北向流量
再来看从 k8s 集群外进入节点,或者从节点出 k8s 集群的流量(external traffic), 即南北向流量(N-S):
区分集群外流量的一个原因是:Pod IP 很多情况下都是不可路由的(与跨主机选用的网 络方案有关),只在集群内有效,即,集群外访问 Pod IP 是不通的。
因此,如果 Pod 流量直接从 node 出宿主机,必须确保它能正常回来。而 node IP 一般都是全局可达的,集群外也可以访问,所以常见的解决方案就是:在 Pod 通过 node 出集群时,对其进行 SNAT,将源 IP 地址换成 node IP 地址;应答包回来时,再进行相 反的 DNAT,这样包就能回到 Pod 了。
译者注
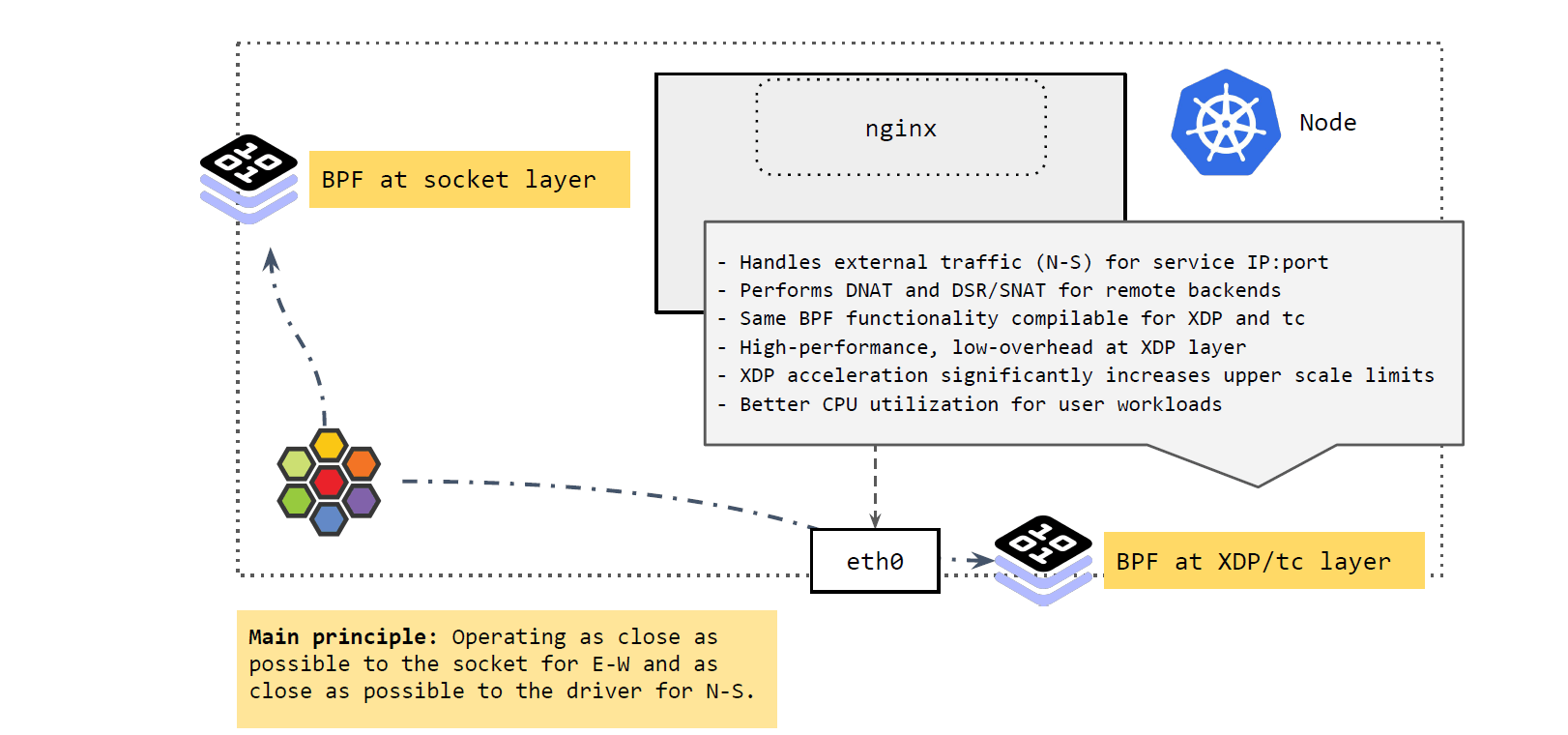
如上图所示,集群外来的流量到达 node 时,由 XDP 和 tc 层的 BPF 程序进行处理,
它们做的事情与 socket 层的差不多,将 Service 的 IP:Port 映射到后端的
PodIP:Port,如果 backend pod 不在本 node,就通过网络再发出去。发出去的流程我们
在前面 Cilium eBPF 包转发路径 讲过了。
这里 BPF 做的事情:执行 DNAT。这个功能可以在 XDP 层做,也可以在 TC 层做,但 在 XDP 层代价更小,性能也更高。
总结起来,这里的核心理念就是:
- 将东西向流量放在离 socket 层尽量近的地方做。
- 将南北向流量放在离驱动(XDP 和 tc)层尽量近的地方做。
11.3 XDP/eBPF vs kube-proxy 性能对比
网络吞吐
测试环境:两台物理节点,一个发包,一个收包,收到的包做 Service loadbalancing 转发给后端 Pods。
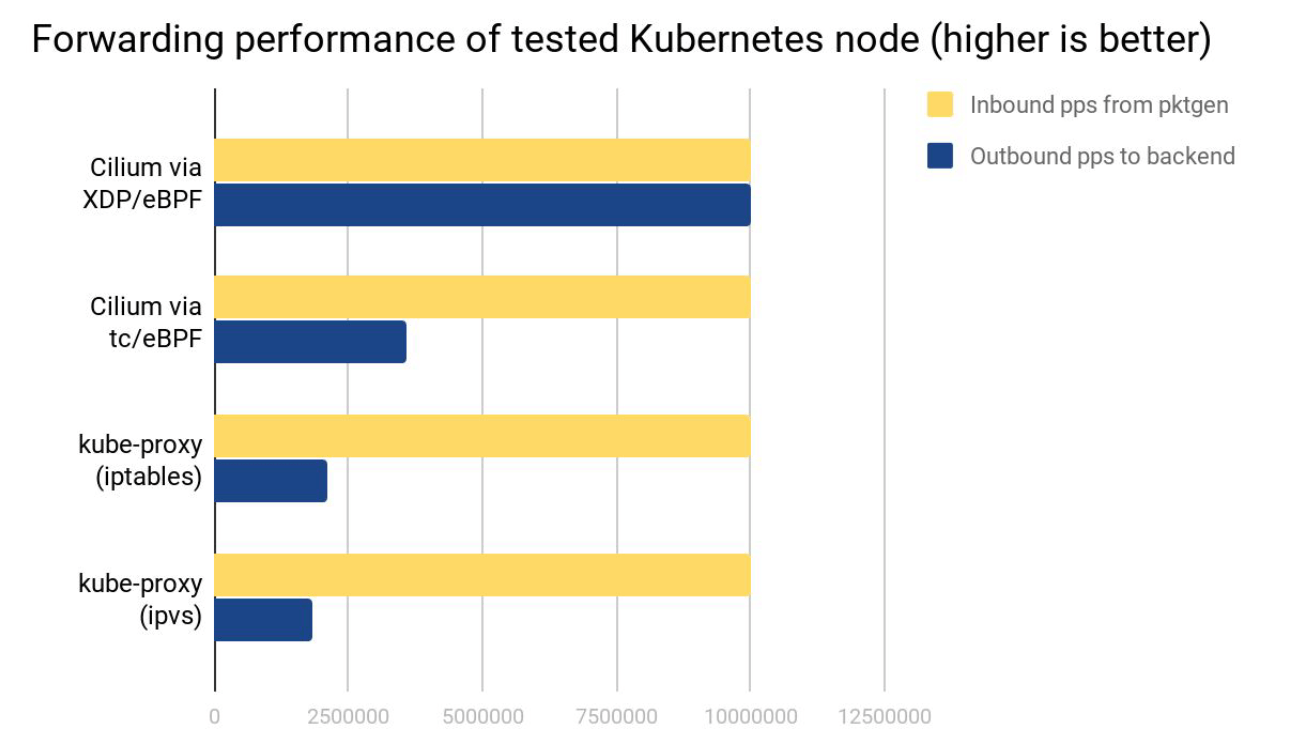
可以看出:
- Cilium XDP eBPF 模式能处理接收到的全部 10Mpps(packets per second)。
- Cilium tc eBPF 模式能处理 3.5Mpps。
- kube-proxy iptables 只能处理 2.3Mpps,因为它的 hook 点在收发包路径上更后面的位置。
- kube-proxy ipvs 模式这里表现更差,它相比 iptables 的优势要在 backend 数量很多的时候才能体现出来。
CPU 利用率
我们生成了 1Mpps、2Mpps 和 4Mpps 流量,空闲 CPU 占比(可以被应用使用的 CPU)结果如下:
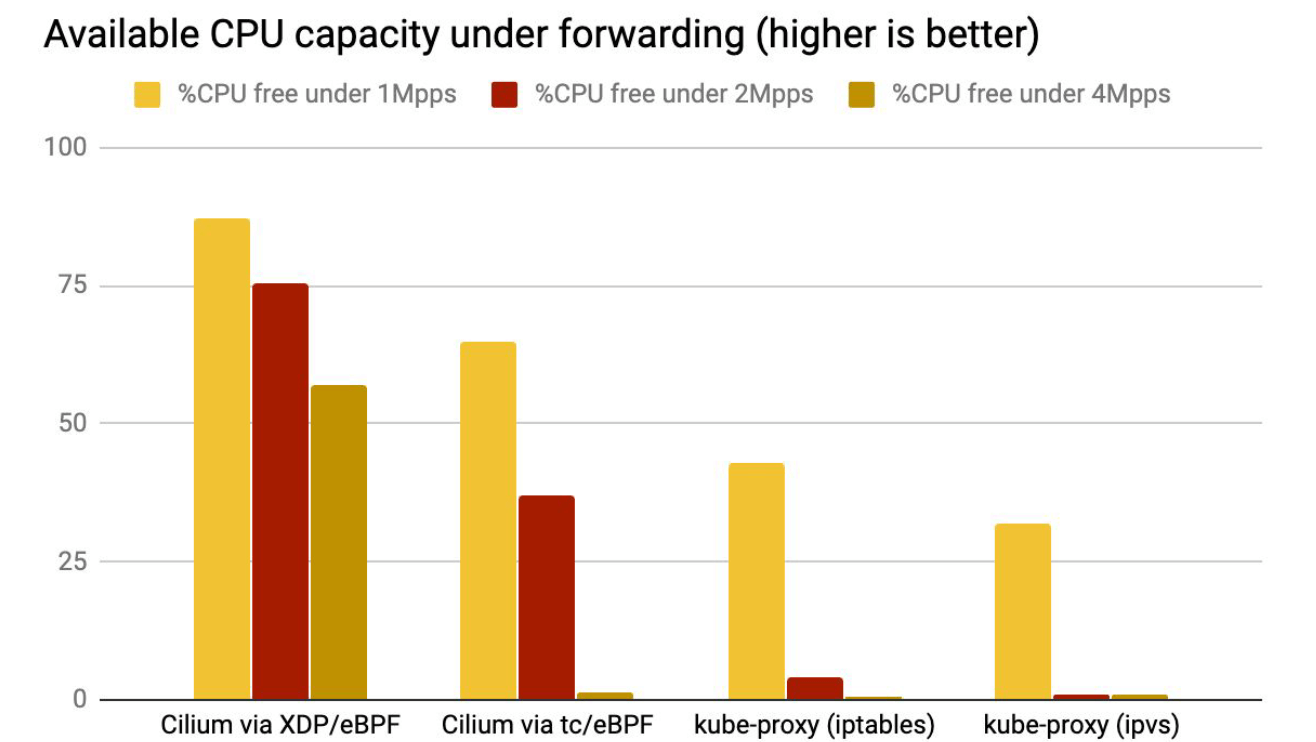
结论与上面吞吐类似。
- XDP 性能最好,是因为 XDP BPF 在驱动层执行,不需要将包 push 到内核协议栈。
- kube-proxy 不管是 iptables 还是 ipvs 模式,都在处理软中断(softirq)上消耗了大量 CPU。
“The Linux kernel continues its march towards becoming BPF runtime-powered microkernel.”
“Linux 内核继续朝着成为 BPF runtime-powered microkernel 而前进”。这是一个非 常有趣的思考角度。
- 设想在将来,Linux 只会保留一个非常小的核心内核(tiny core kernel),其他所有 内核功能都由用户定义,并用 BPF 实现(而不再是开发内核模块的方式)。
- 这样可以减少受攻击面,因为此时的核心内核非常小;另外,所有 BPF 代码都会经过 verifer 校验。
- 极大减少 ‘static’ feature creep,资源(例如 CPU)可以用在更有意义的地方。
- 设想一下,未来 Kubernetes 可能会内置 custom BPF-tailored extensions,能根据用户的应用自动适配(optimize needs for user workloads);例如,判断 pod 是跑在数据中心,还是在嵌入式系统上。

BPF will replace Linux.
我们的目标是星辰大海,与此相比,kube-proxy replacement 只是最微不足道的开端。

- Try it out:https://cilium.link/kubeproxy-free
- Contribute:https://github.com/cilium/cilium
如有侵权请联系:admin#unsafe.sh