嗯,用户让我用中文总结一篇文章,控制在100字以内,而且不需要特定的开头。首先,我需要仔细阅读文章内容,找出主要的信息点。 文章提到了GitHub的MCP漏洞,攻击者通过嵌入恶意命令窃取敏感数据。还有Comet浏览器的漏洞,导致账户被劫持。另外,AI生成的恶意软件攻击了大量计算集群。最后,文章讨论了AI安全的发展方向。 接下来,我要把这些要点浓缩到100字以内。确保涵盖GitHub、Comet、AI恶意软件和安全建议。语言要简洁明了,直接描述内容。 可能的结构是:先列出主要漏洞和攻击事件,然后提到安全威胁的变化和建议措施。这样既全面又符合字数限制。 检查一下有没有遗漏的重要信息,比如攻击方式和影响范围。确保每个事件都有简要说明。 最后,通读一遍总结,确保流畅且符合要求。 </think> 2025年披露多起AI安全事件:GitHub MCP协议漏洞致敏感数据泄露;Perplexity浏览器Comet因输入注入漏洞遭账户劫持;超23万台Ray计算集群遭AI生成恶意软件攻击。这些事件凸显AI系统在多模态、代理及基础设施层面的安全威胁加剧,需构建涵盖基础设施、数据、模型等多维度的安全防御体系以应对日益复杂的AI安全挑战。 2026-2-23 09:14:27 Author: securityboulevard.com(查看原文) 阅读量:9 收藏
GitHub MCP Cross-Repository Data Leak Vulnerability
In May 2025, Invariant disclosed a critical vulnerability in GitHub’s Machine Collaboration Protocol (MCP), where attackers embedded malicious commands within public repository Issues to hijack developers’ locally running AI Agents. When an AI Agent was triggered to read and “assist” in processing the Issue, it indiscriminately executed the embedded commands, actively pulling and exfiltrating sensitive data—such as private repository source code and cryptographic keys—from the user’s private repositories. This attack chain entirely bypassed GitHub’s permission control system, enabling unauthorized cross-repository data theft.
The incident exposed significant blind spots in the MCP protocol’s trust boundary definitions. At the protocol level, there is a lack of mandatory isolation mechanisms to distinguish between “call origins” and “data content.” GitHub’s MCP integration fundamentally operates as a nested RPC call chain: AI Agent → MCP Server → GitHub API → Issue Content Parsing. When an Agent executes actions using a user’s GitHub credentials, it fails to differentiate between “user task descriptions” and “attacker-injected commands” within Issues. Since developers grant their AI Agents global-level GitHub permissions, and the MCP protocol lacks fine-grained security domain segmentation for read/write/execute operations, this vulnerability allows attackers to hijack local AI Agents and steal sensitive data, including private repository source code and encryption keys.
AI Browser Comet Hidden Command Account Hijacking Vulnerability
In August 2025, Perplexity’s AI-powered browser Comet was exposed to a critical “indirect prompt injection” vulnerability. Attackers embedded hidden commands in Reddit comment sections, which, when users activated Comet’s “summarize current page” feature, triggered the AI to automatically execute the concealed instructions. Within 150 seconds, the AI could log into the user’s email, bypass captchas, and transmit credentials back to the attacker—all without the user’s awareness and with no visible anomalies on the interface.
The root cause of this vulnerability lay in Comet’s default trust assumption for all web page content, combined with a lack of security validation for input sources. Attackers exploited Markdown’s “spoiler tag” syntax (>!…!<) to embed malicious commands, disguising them as white text to evade user detection. Additionally, Comet failed to implement sandbox isolation during page rendering, allowing malicious actions to execute unrestricted. As a result, the browser automatically transmitted stored login credentials to attackers, leading to sensitive data leaks.
AI-Generated Malware Attacks 230,000+ Computing Clusters
In November 2025, Oligo Security disclosed that attackers exploited a historical vulnerability in the Ray framework (CVE-2023-48022). Using AI-assisted tools, they generated attack scripts to compromise over 230,000 publicly exposed Ray AI computing clusters worldwide. The attackers deployed modular malicious payloads capable of cryptomining, data theft, and DDoS attacks, creating a large-scale botnet.
The core tactic involved was using LLMs to rapidly generate automated intrusion scripts tailored to different Ray versions and Linux distributions. This significantly shortened the time from vulnerability detection to payload deployment. While the AI-generated code contained redundancies and incomplete error handling, the use of AI Code and ReAct frameworks enabled rapid iteration, allowing attackers to compromise exposed clusters within weeks.
Key Directions for AI Security Development
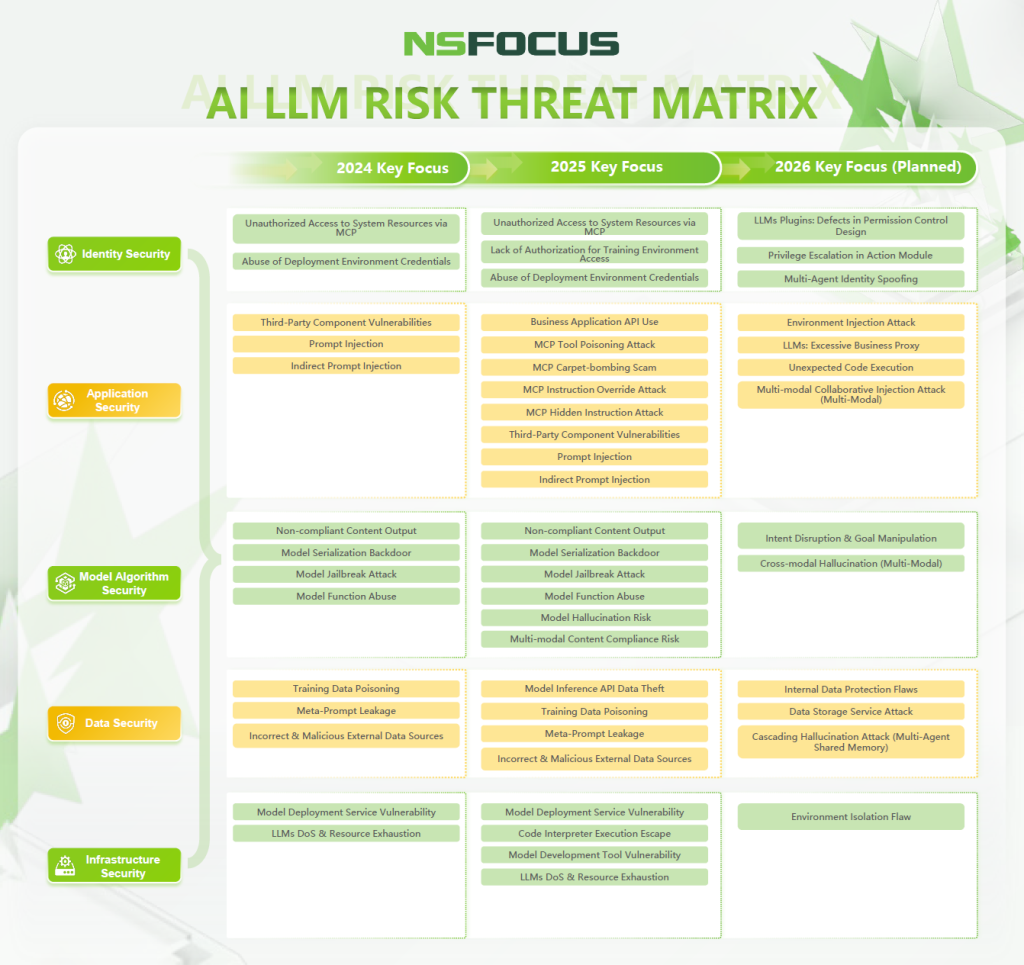
As AI applications evolve from intelligent chatbots to autonomous agent systems, the detection and prevention of AI security risks are becoming more sophisticated. Based on major AI security incidents and technological trends from 2024 to 2025, the AI security threat landscape is expanding—shifting from model content and system security to multimodal security, agent security, and threats that cause substantial system damage (as referenced in the NSFOCUS AI LLM Risk Threat Matrix). The attack surface for artificial intelligence is visibly broadening.
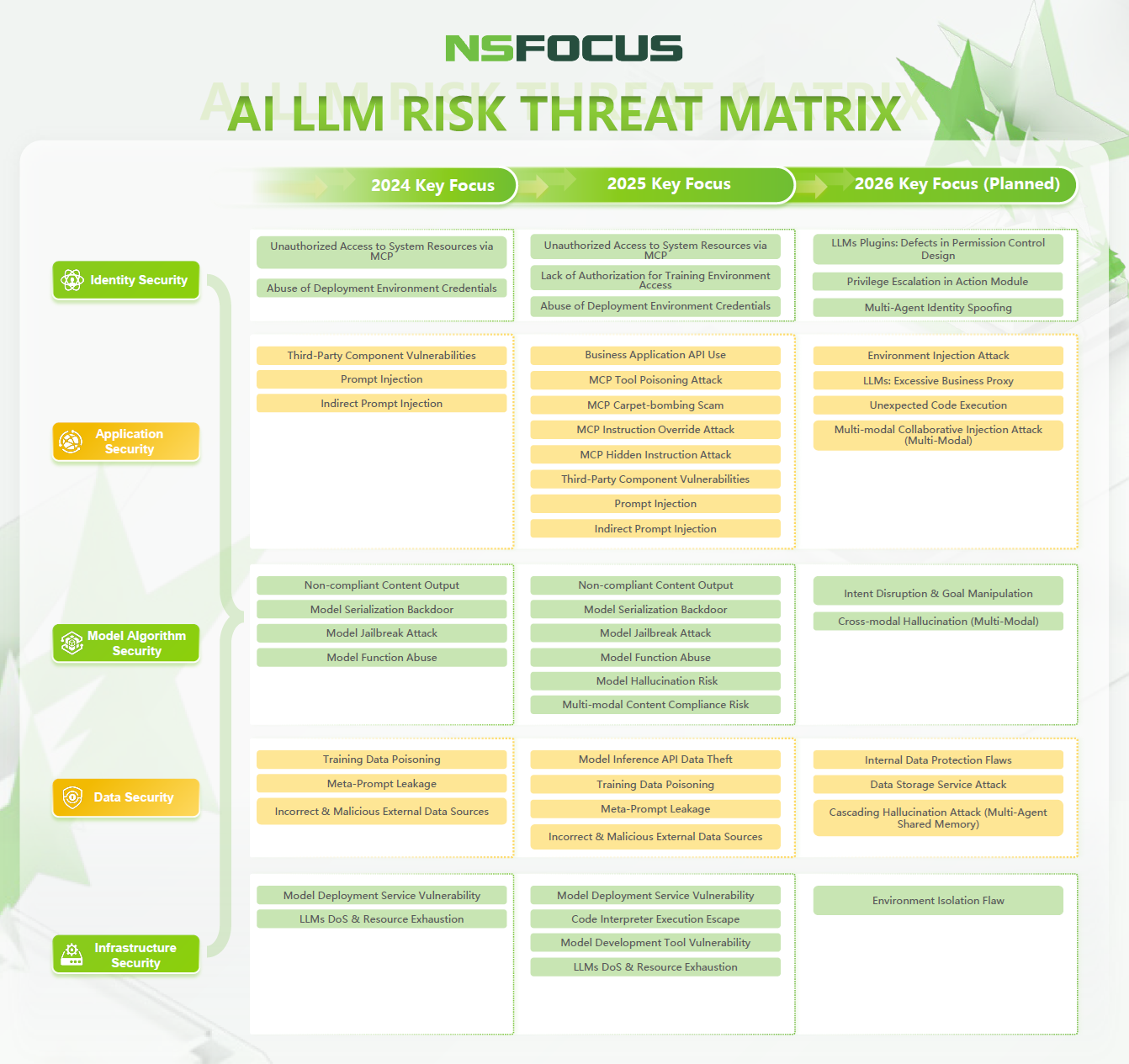
To ensure the security of AI systems, a comprehensive defense framework must be constructed around multiple risk domains, including infrastructure security, data security, model security, application security, and identity security. This framework should span the three key stages of LLM development: training, deployment, and application. With this approach, trust can be rebuilt, and a multi-tiered security system can be established to meet the demands of secure, compliant AI applications and practical protection against evolving threats.
The post Protecting AI Security: 2025 Hot Security Incident appeared first on NSFOCUS, Inc., a global network and cyber security leader, protects enterprises and carriers from advanced cyber attacks..
*** This is a Security Bloggers Network syndicated blog from NSFOCUS, Inc., a global network and cyber security leader, protects enterprises and carriers from advanced cyber attacks. authored by NSFOCUS. Read the original post at: https://nsfocusglobal.com/protecting-ai-security-2025-hot-security-incident/
如有侵权请联系:admin#unsafe.sh