接上篇分享 PPT 的 Plugin (https://github.com/Y4tacker/codex-ai-ppt)补一下分享的内容,反正都不是什么私密东西

最开始,我并不打算讲这个,在最终决定这个选题之前,我大概花了一个月时间研究了很多方向。本质上,它们都是我最近感兴趣、正在探索的一些东西和技术
其中有三个选题我本来是真的打算讲的
一个叫 “代码,还是那些代码”,大纲其实都想得差不多了,但看着最近大家分享代码、工程相关的内容已经很多了,我有点想换换味道
另一个叫 “Skills 的自进化?”,这个题听起来很有意思,也确实能展开很多论文、框架和实现思路,但做到一半,我发现它对通用场景的意义不大,本质上只是把原来优化文本和 PROMPT 的思路换汤不换药
还有一个叫 “当 MCP 遇见 SKILL”,这个是我前几天捡起来在研究的东西,想法是我去年年底想到的只是一直没做实验,MCP 与 SKILLS 融合形态,将 Tools 与 Skill 通过 MCP 同源分发,但这个十几分钟就讲完了不太合适,后面写成文章再分享好了,当然还有一些个人原因想挑战下自己不想讲纯技术文
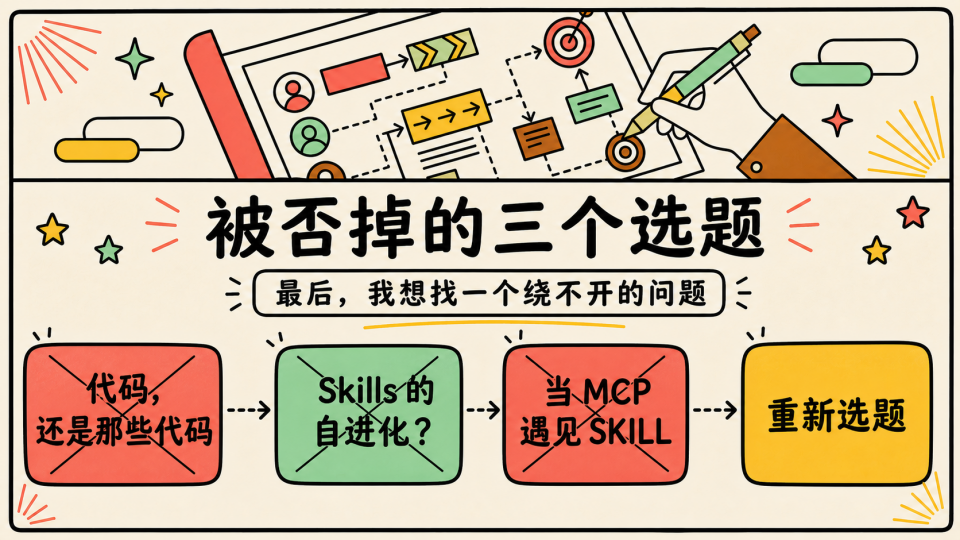
否掉这两个之后,我开始想,有没有一件事是大家都在做、也几乎所有人都绕不开的
想来想去,我发现确实有一件事:
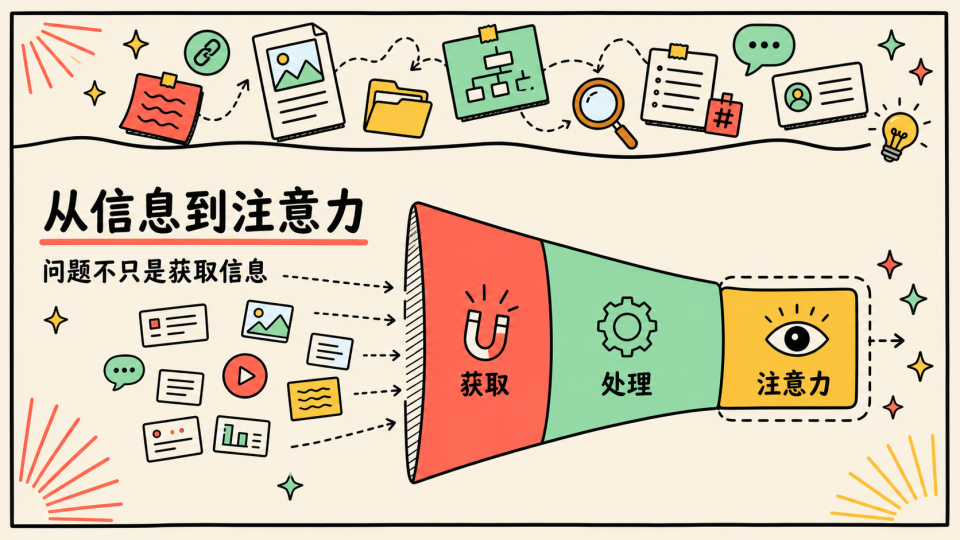
怎么获取信息,以及怎么处理信息
尤其是在今天,人人都在讲自动化,讲个人信息飞轮的时刻,我越来越觉得,这里面有一个很容易被忽略的问题:
真正留下来的,往往不是我们收集过的信息,而是我们在筛选、拒绝、使用信息时形成的判断
这次分享也算是我过去一年围绕 “信息” 折腾之后的一次复盘,这一年里我一开始以为自己要解决信息获取问题,后来才发现,我真正需要解决的是注意力分配的问题
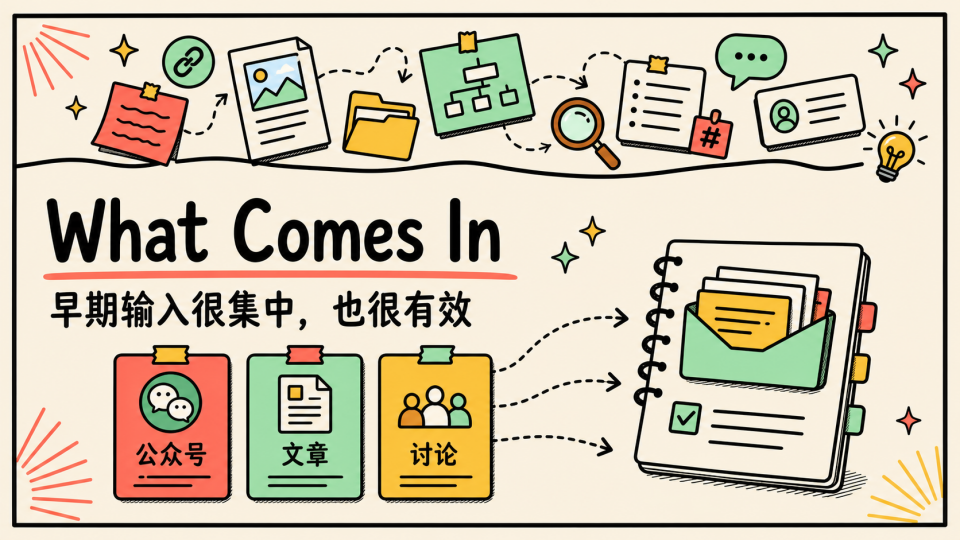
What Comes In
先从最早的信息输入讲起,刚开始接触 AI 的时候,我发现蒸馏别人的知识是一种很快的学习方法
那还是 chatbot 时代,信息环境和现在很不一样,信息量没有现在这么夸张,且高质量内容也比较集中
从 LLM 基础知识,到大模型商业进展,再到应用案例,很多内容基本都能从几个高质量公众号、文章和推特里看到,那个阶段很多账号也还处在起号,信息量少但密度很高,主要是很有人味
对我来说,这段时间是最近几年里再次让我感到学习最快乐的一段时间,更早是小时候刚开始接触网络安全的时刻
- 一方面,是因为之前每天搞网络安全确实会有点累,这个累不完全来自强度,而是来自单调重复。很多东西做久了之后,新鲜感会变少,知识带来的刺激也会变弱。
- 另一方面,是因为大模型刚出现的时候,每次迭代都能带来一种久违的耳目一新的感觉,新的能力、新的边界、新的玩法不断出现,学习是很有反馈的,而且是特别快!
- 那个时候我什么都想看,什么都想试,从大模型的预训练、后训练、Agent、RAG 甚至 Transformer 相关的东西,我都在接触。只要看到一个有意思的项目,就想拉下来跑一下;看到一篇讲得不错的文章,就想顺着里面的概念继续往下挖,这一阶段,随意的输入本身就会带来源源不断地正反馈
When It Gets Wider
后来,事情开始慢慢不对劲,大模型还在高速发展,但针对模型本身的玩法越来越少了,我能感觉到从大模型本身获得的新鲜感开始下降,而是因为很多基础知识我已经刷过几轮了。后面再看到的很多内容,本质上是在不断巩固和复习,不同文章换一种说法,不同作者换一个比喻,新瓶装旧酒,底层讲的东西并没有变太多,新鲜感开始从模型本身转移
这时候我意识到,不能只看大模型本身,如果一直只盯着模型结构、训练流程,很容易陷入一种局部循环,模型当然重要,后来在 Function Call 出来以后我的注意力变成了大家正在模型之上建立什么?安全领域在怎么用它?产品团队在怎么设计它?不同公司在怎么改造自己的工作流?
也就是说,我的关注范围开始从大模型本身扩展到大模型的生态
但问题也正是在这个时候出现的,当我不再只看模型本身,问题就从 “学什么” 变成了 “去哪里学”
当时还没有现在这些成熟的 Deep Research 产品,我也不知道到底应该从哪些网站、哪些社区、哪些渠道系统性地找到自己想要的东西
更关键的是,我其实也没有那么清楚自己想学什么,我只知道应该关注 AI 安全,应该关注大模型应用,应该关注一些新的产品形态,但 “应该关注” 并不是一个清晰的问题,它散播一种模糊的焦虑
People As Source
Btw: 后面一年的经历也证明了确实这个还是最好的,就是人越来越忙了没时间思维风暴
刚好在那个阶段,我在外面认识了一些志同道合的人,大家都对大模型很感兴趣,而且分布在不同领域,每个人关注的东西不完全一样,有的人看模型,有的人看产品,有的人看开源项目,有人喜欢当喷子
后来我们组成了一个社群,这个社群最开始只有一个作用:分享关于大模型的各种知识
在一段时间里,最好的信息源不是网站,而是一群分布在不同领域、愿意互相分享的人
初期效果非常好,那时候人的规模不算大,基本一天也就几十到上百条消息,群里会出现各种信息和链接:公众号文章、论文、GitHub 项目、产品体验,也包括大家自己的新奇想法
那段时间,每天饭点或者下班之后,看看群里大家在聊什么,其实已经能获得很多有价值的信息
这是一种很自然的信息分发方式,不是算法推荐给你,而是通过一群和你有相似兴趣、但关注面又不同的人,把信息带到你面前,每个人都带着自己的问题和视角进入这个环节。一个人看到的东西,可能正好补上另一个人的盲区,人在这个阶段先成为了信息入口。
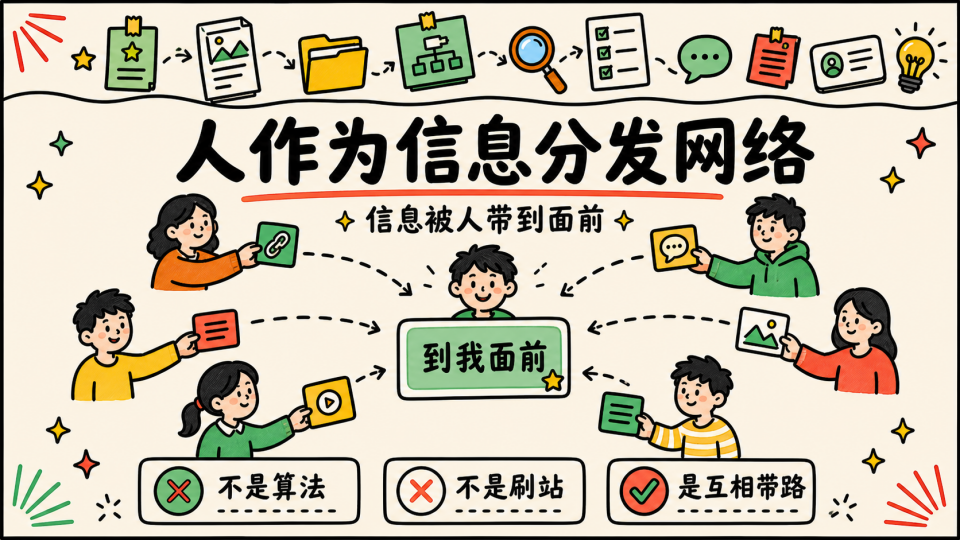
但随着群成员规模不断扩大,问题也开始出现
首先是水平参差不齐,人一多之后,大家处在学习的不同阶段对 “什么是高质量信息” 的理解也会不一样,有的人分享的是一手资料,有的人分享的是二手解读,有的人只是看到标题觉得很厉害就转了进来;
其次是水群很难避免,很多时候大家并不是故意降低信息密度,只是交流一旦变多,就一定会混入大量上下文、情绪、闲聊和重复表达,信息密度也就开始下降

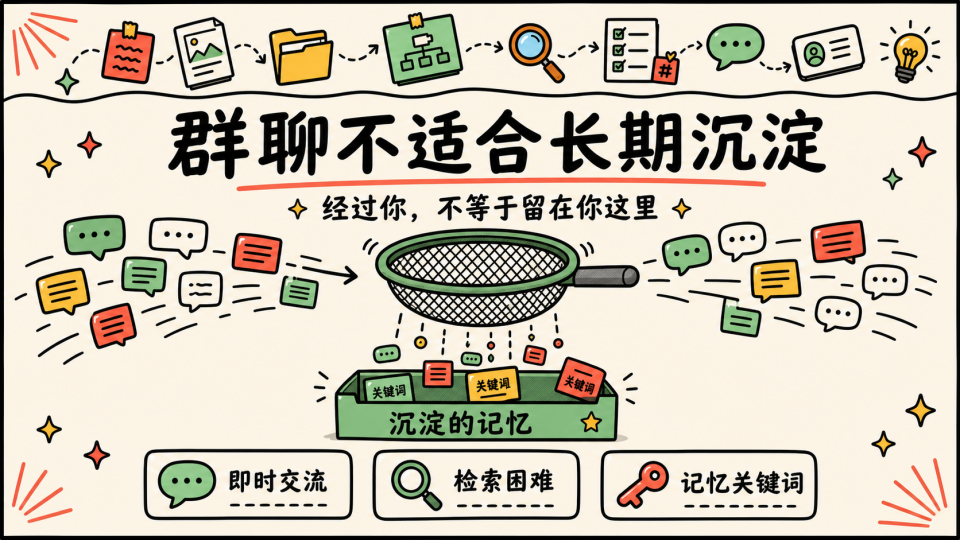
最后是沉淀困难,群聊确实是一种很适合即时交流的载体,但它并不适合长期检索。一个东西当时你看过、讨论过、甚至学过,但过了一两个月之后,如果你想重新系统地找回来,基本只能靠记忆里的几个关键词去群聊搜索,又或者说自己之前有意识地保存了下来
这时候我意识到一件事:就算信息被学习过,也应该被存下来,因为群聊里的学习,只是经过了你,没有真正留在你这里
What Gets Built
于是,我开始为信息建系统
当时的解决方案其实很直接,通过微信 Hook 插件创建一个微信小号机器人,大家在群里分享内容时,只要按照一些关键词前缀和固定格式发消息,机器人就能把这些内容抓下来,抓下来之后,后台处理识别,再通过大模型做一些简单分类。这个系统的目标很简单:先让信息不要散掉。
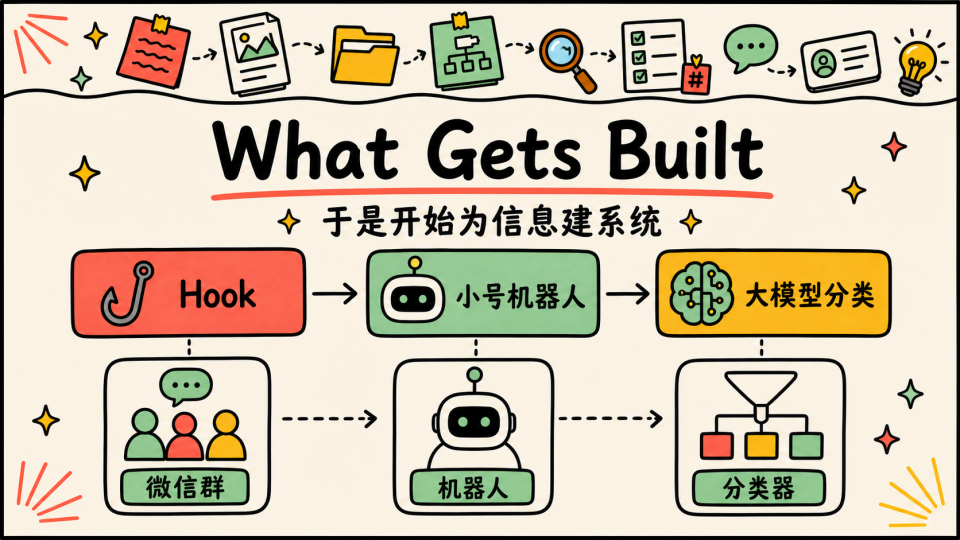
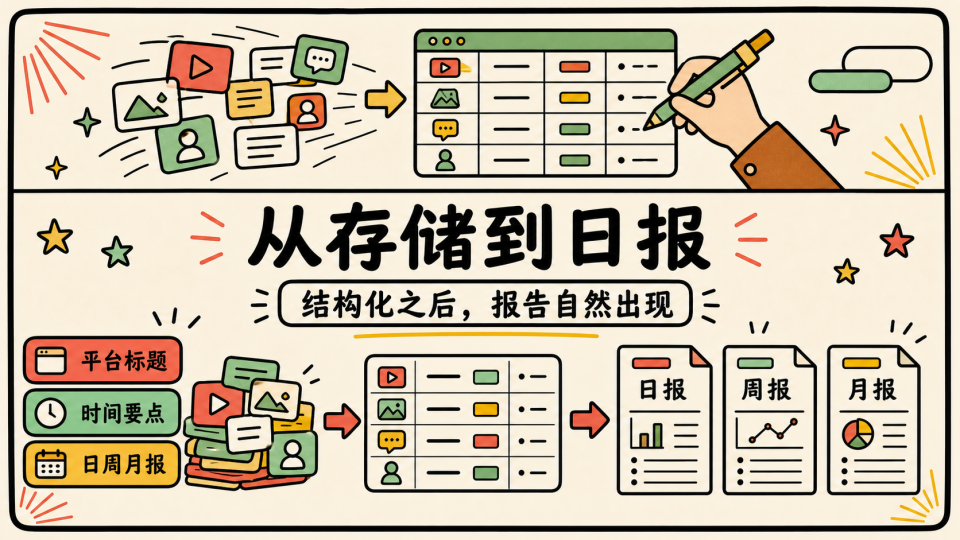
分类也不复杂,主要记录平台、标题、内容、时间,以及 AI 提炼出来的要点总结
这样一来,信息存储的问题基本就解决了,有了结构化的信息之后,日报、周报、月报功能也很自然地出现了。每天发生了什么,一周有哪些值得看的内容,一个月里某个方向出现了哪些变化,都可以被整理出来
但这个系统依赖人的积极性,只要大家愿意分享,它就有价值;一旦大家不分享,或者分享质量下降,它就会变弱。一开始通过群成员的分类分级做了多个群来缓解,但我们也知道,不可能永远靠人来收集信息,我开始逐渐从被动走向了主动,在这个过程中我也逐渐意识到,从社群里挖掘信息,本质上只是一个过渡阶段,它真正的意义应该是在我没有形成自己的长期主观判断之前帮我观察:大家关心哪些方向?有哪些长尾但高质量的信息源?哪些内容会引发讨论?哪些内容只是看起来热闹?正好在做微信 Hook 的时候积累了一些爬虫的经验,这个东西很自然而然地推了下去

后面我们就开始把绝大多数信息平台整合到一起,做了一个专门的爬虫,这个阶段,我开始把信息处理拆成几个维度
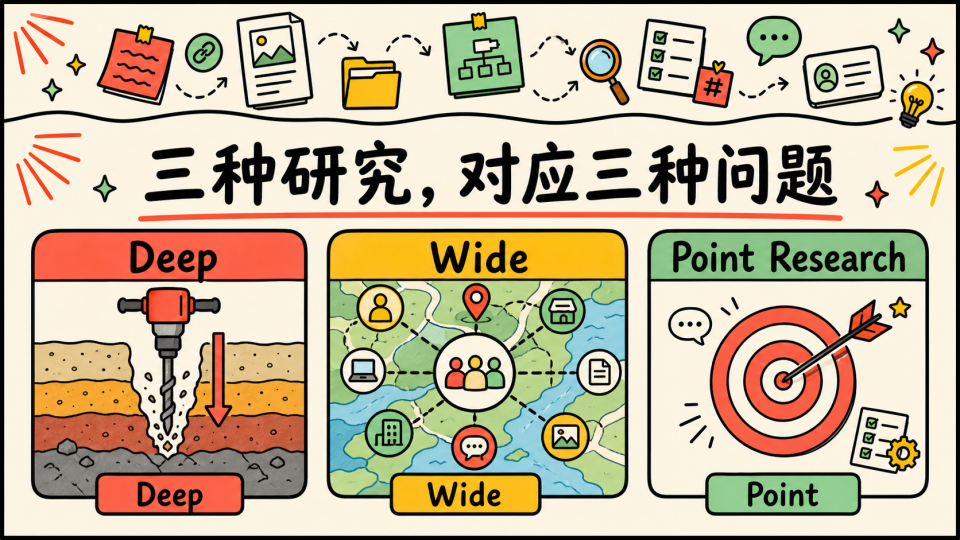
- Deep Research:纵向钻取,追求深度和系统性,需要完整的知识体系和上下文
- Wide Research:横向扫描,建立知识地图,快速发现关联和盲点
- Point Research:高效获取可执行方案,偏向 Just-in-time learning
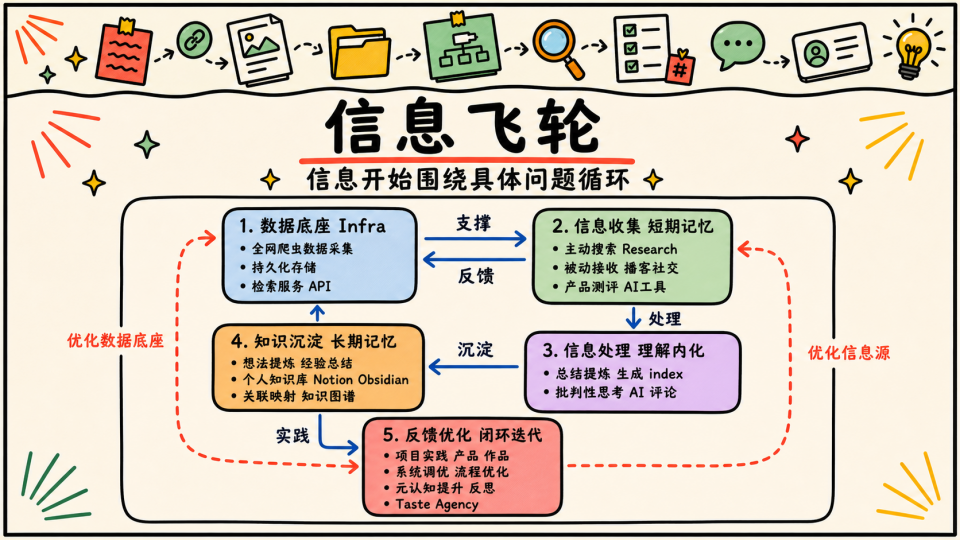
围绕这三个方向,我构建了一个所谓的信息飞轮
围绕这三个点,逐渐地我构建了一个所谓的信息飞轮,信息进来之后,会被分类、总结、归档、检索、再加工,最后服务于具体问题,并形成一个反馈循环;
某种意义上,它实现了 “信息找人”。至少它让信息不再完全散落在各个角落,也确实解决了一部分 “存” 和 “找” 和 “自动迭代” 的问题,后面很长一段时间里我都沉迷于迭代这套系统 (真累啊 00)
BTW: 当然其实这段时间里我还顺便用过各种各样地免费地知识库产品,毕竟能有现成地就懒得自己造轮子,但是他们生态都或多或少地比较封闭,并且只能解决其中的一小环节,这里不展开了毕竟不是产品调研文
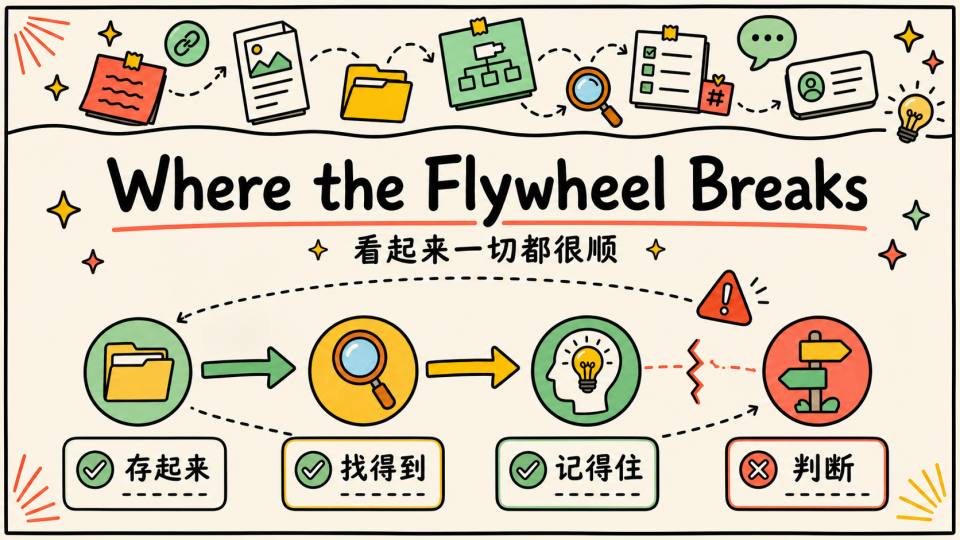
直到后来我发现,问题又不对劲起来了
Where the Flywheel Breaks
从直觉上看,这套逻辑非常顺:
- 既然信息太多,那就把它们存进知识库
- 既然人找信息效率低,那就用向量检索和大模型帮我找
- 既然原文太长,那就让 AI 总结
- 既然我记不住,那就让系统替我记住
但真正用下来之后,我发现真正难的不在存、找、记,而在判断这个信息真的有没有用,毕竟越往后信息量越来越大了,到后面我慢慢就应付不过来了,有以下问题
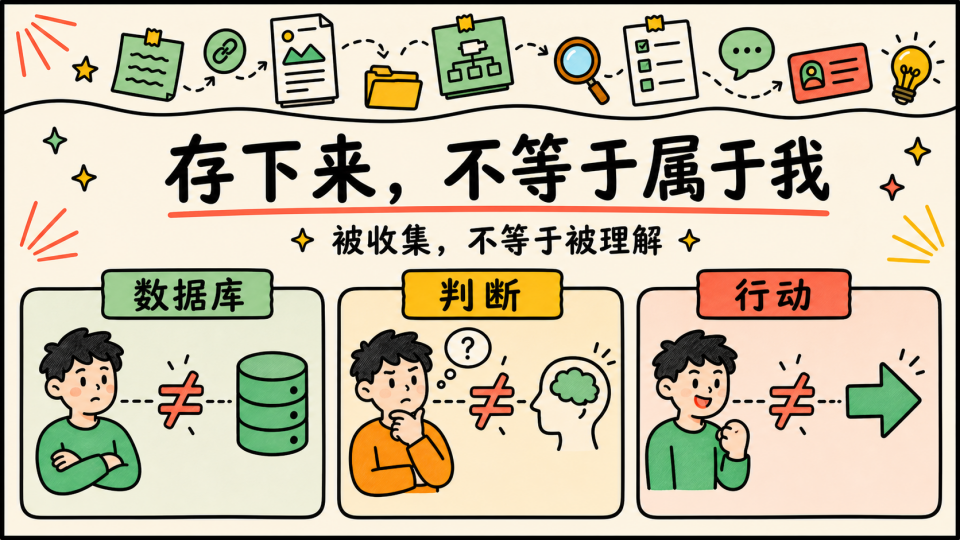
- 存下来,不等于属于我:知识飞轮最容易制造的一种错觉是,只要我把它存下来了,它就属于我了 (收藏等于学会)。但实际上不是。它只是被收集了,不是被理解了。它存在数据库里,不代表存在我的判断里;它能被搜索到,也不代表能在我需要的时候改变我的行动
- 最关键的是我开始习惯于让 AI 全自动化地帮我处理一切,我逐渐意识到了我丢掉了思考,我更像是一个无情的知识蒸馏机器,有点像之前被我自己调侃的青少年就是 AI NATIVE 的一代
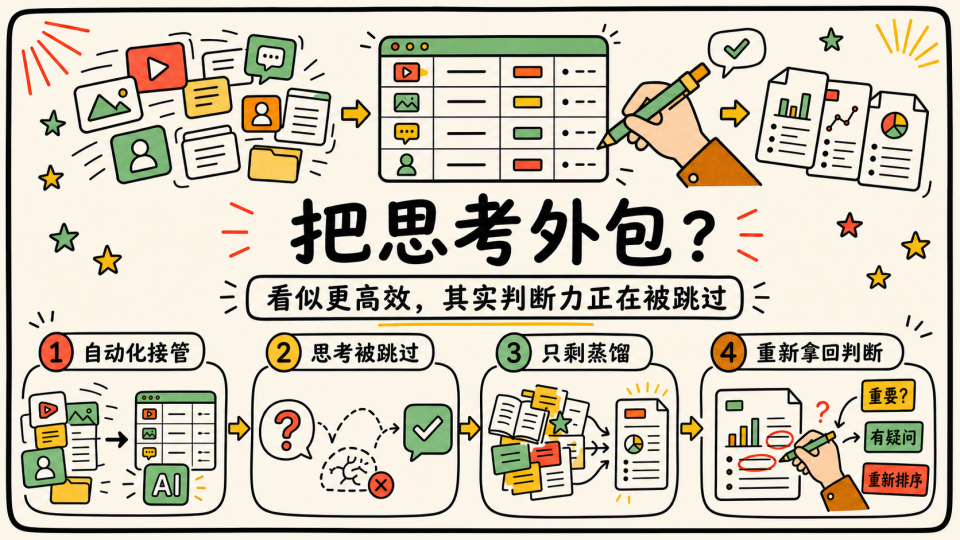
- 系统不知道我此刻真正关心什么:第一版效果好,是因为人在设计系统时已经判断过,这个阶段什么东西对自己具有高价值,但你不可能一直关注同样的东西,这样也就导致了系统的维护成本非常高,这个东西不是简单的通过 Memory 就能解决掉
- 机器可以帮我整理信息,但不能替我完成判断:虽然它可以 24 小时抓取、总结、分类,却很难真正分辨什么是短期的热闹,什么是长期问题


这里得出一个关键结论如果一个人没有明确的问题和方向,没有自己的判断标准,那么再智能的信息分发,也可能只是更精准地制造焦虑

When FOMO Hits
这就是所谓 FOMO,当你不知道自己真正要解决什么问题时,任何信息都可能看起来重要,这时候你不是在选择信息,而是在被信息牵着走

这种感觉非常典型,网上各种文章提到:
- 今天这个模型已死,明天那个框架当立
- 今天有人说所有应用都要重做一遍,明天有人说某个岗位马上就要消失
- 今天一个产品刷屏,明天一个 Agent 框架爆火。
你看多了之后会有一种感觉:好像什么都应该看,什么都不能错过,什么都和未来有关
但问题是,你真的需要它们吗?
如果没有带着自己的问题,你很难分辨它们,你只会觉得每个都好像有道理,每个都好像应该收藏,每个都好像值得以后再看,但以后再看通常就等于不会再看

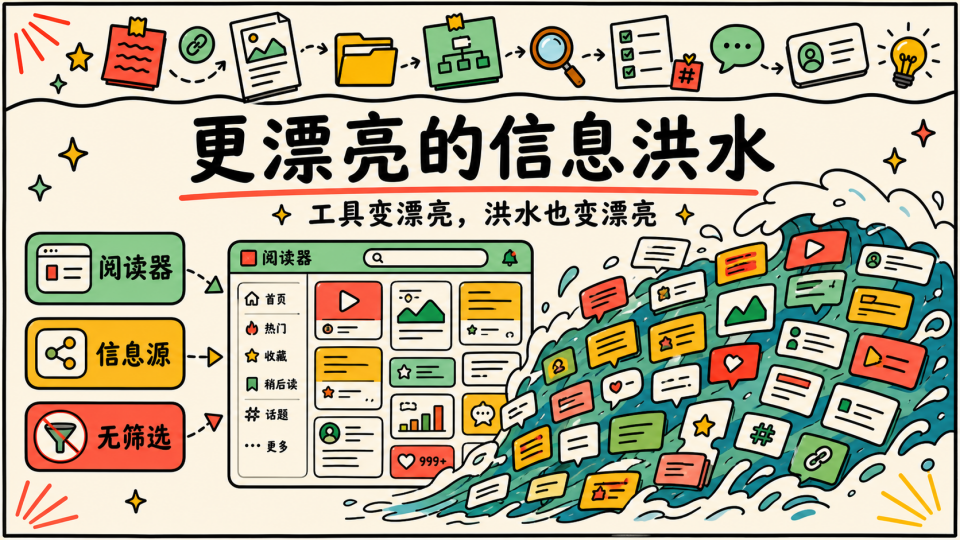
这时候无论你怎么包装的流程,信息源再全,界面再舒服,如果你没有自己的筛选标准,它们最后都只会变成更漂亮的信息洪水
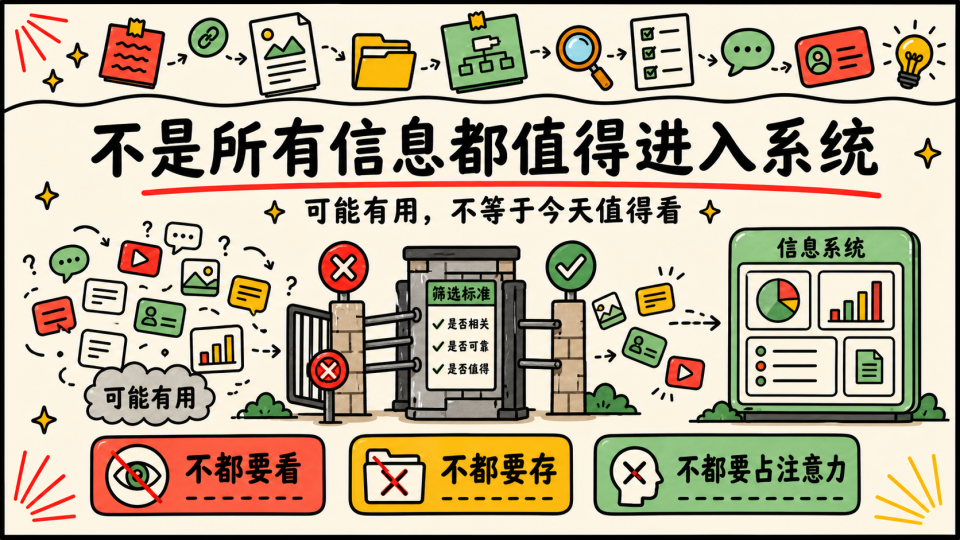
后来我慢慢我开始接受一个听起来很朴素的结论,不是所有知识都值得看,更不是所有 “可能有用” 的东西,都值得占用今天的注意力,这种 “可能” 会让很多本来不该进入注意力的东西,被包装成未来的储备,这就是一种负担,我并不是说学得多了不好,但是被动地接受很容易让人麻木丢掉思考,我逐渐意识到真正的学习应该和以前一样围绕自己的注意力机制展开,不然还不如不学,毕竟有意识的实践被证明确实是学习最高效的办法,这让我想起了以前初学安全的时候,上课讲了半学期,不如我手底下挖了一个前台 RCE 学到的多
What Actually Stays
那过去这一年,真正留下来的是什么?
从结果上看,当然有一些具体收获。我学会了怎么完整训练一个模型,至少大概知道了 SFT、RL 的流程和一些坑;我熟悉各类 RAG,Agent 流程的搭建,也知道它们在哪些场景里有用,在哪些场景里容易被高估,我也体验过很多新形态的 AI 产品,并学到了他们的设计思想

回头看,真正留下来的不是那些被我收集、总结、归档过的链接,而是这些过程中的经历改变了我判断信息的方式

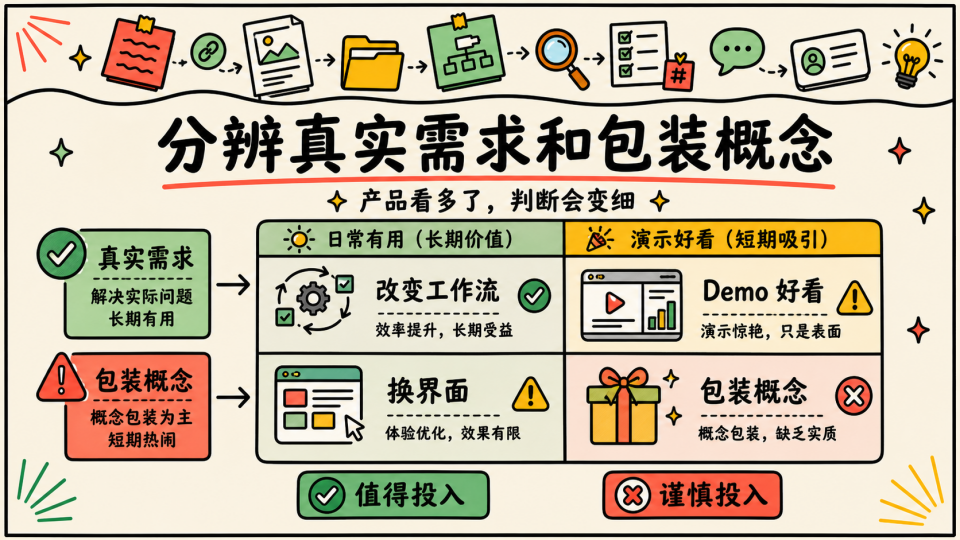
体验过大量 AI 产品之后,我开始更能分辨真实需求和包装概念,有些产品确实改变了工作流,有些产品只是把同一个能力换了个界面,有些产品的 demo 很惊艳,但每天真正用的时候并不顺手,有些产品没有那么夸张的叙事,却在某个具体场景里非常有效
看过足够多信息之后,我最大的变化反而是:我开始知道什么不需要看,这件事可能比知道该看什么更重要,因为信息环境越复杂,一定程度上来讲,知道拒绝什么往往比能吸收什么更能决定一个人的注意力质量,从而让我们能够把有限注意力留给真正能改变问题、判断和行动的东西
当然不是说啥都看不好,当然什么都看是最好的,啥都看肯定是最好的,但是我们需要工作也需要休息,这个方式不适合我,毕竟我也不是自媒体
Less, But Mine
所以现在我也越来越相信一件事:
筛选本来就是学习的一部分,留下对的东西,比读更多东西更重要
“少一点” 不是反学习,也不是不看新东西、不关注变化、不接触外部世界
相反,它要求你更主动地去选择学习对象,只看和当前方向、当前问题有关的信息,把省下来的时间拿来试工具、做项目、和人交流、自己思考多好

过去我很容易被 “完整性” 吸引
总觉得一个方向要看全,一个工具链要配齐,一个知识库要建完整,一个信息源列表要尽可能覆盖
但后来发现,对个人来说,完整性经常是一种负担
你以为自己是在搭建系统,其实是在给未来的自己制造维护成本
你以为自己是在降低焦虑,其实只是在把焦虑结构化
What Works Now
现在我不再追求信息处理的全自动化
原来的信息链路还在:AI 继续定向收集、总结、归档,日报也继续生成。但我不会再默认打开所有东西,也不会因为系统存下来了,就认为它们都值得进入我的注意力,系统可以继续运转,但 “进入注意力” 这一步必须被收紧,它唯一的作用就是未来在我需要了解某个方面的整体知识的时候有个时间线,我发现这样的效果反而比外面的 searchapi 更有效
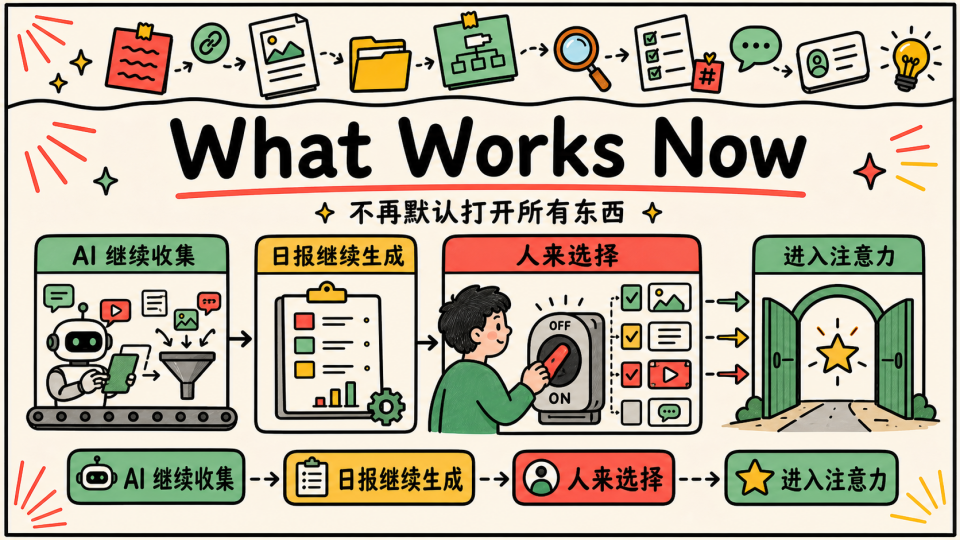
每天早上,我只做一件事:看日报总结和我近期真正关注的问题有没有关系。
如果没有关系且提不起兴趣,就直接关掉,不强迫自己看不想看的。
如果有关系,再决定要不要深入读、要不要继续追踪、要不要把它放进某个长期问题里。
这套 信息 workflow 的重点不是让信息更多,而是让第二层输入更少,第一层可以由 AI 扩大,第二层必须由人收窄,这样在闲暇时间我就可以更自由地去探索各种话题以及分析研究一些新的开源热门项目
再往后,我开始把这个原则用在所有信息系统上,在这个过程中,我也越来越明确 AI 和人的边界。
AI 适合扩大感知范围,持续收集、整理、压缩信息,并在需要的时候把相关材料推回到我面前,但它不应该替我决定什么值得关心,什么值得投入,什么应该进入长期问题,AI 可以帮我看见更多,但方向、边界和取舍不能完全交出去
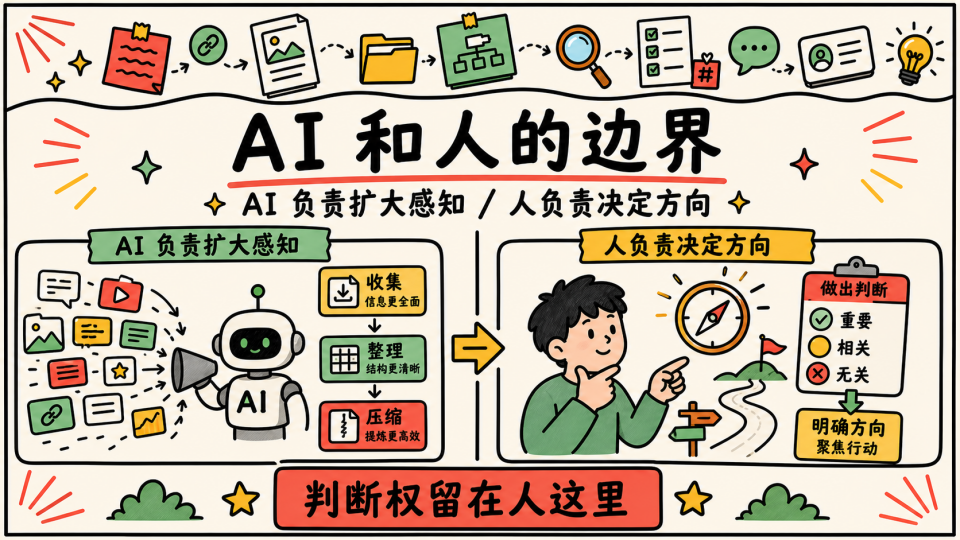
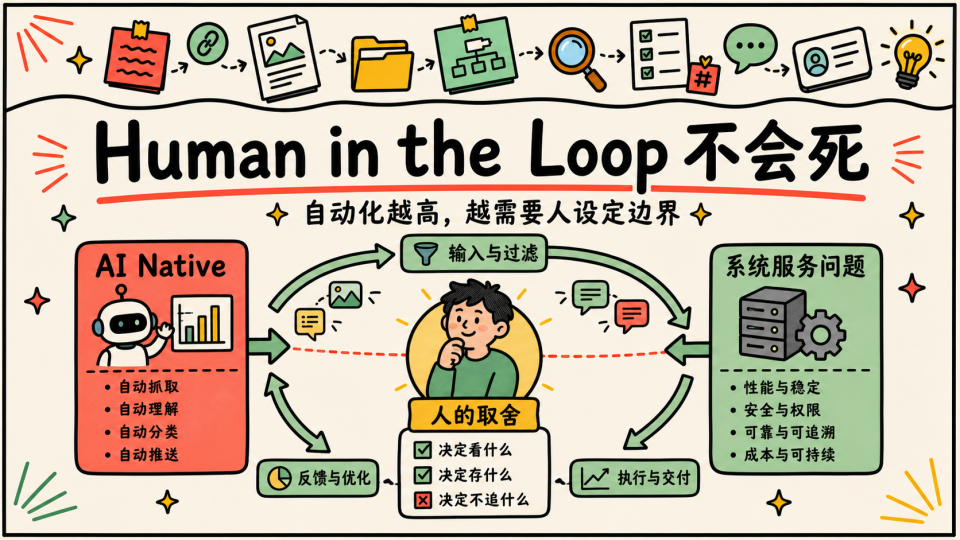
Human in the Loop 不会在 AI Native 的时代死去 (至少当前场景不会),相反,越是信息自动化程度高的系统,越需要人在关键位置上决定方向、设定边界、承担取舍。如果没有人持续定义问题,系统只会越来越擅长处理输入,却不一定更接近真正重要的问题。AI Native 不等于人退出判断,而是人的判断位置变得更关键,不然的话既然 AI 都知道,那我们还搞这套信息系统干嘛,要时刻记得这套系统的目的其实是帮助我们个人的成长,毫无意义不如不做,直接回家躺平睡大觉
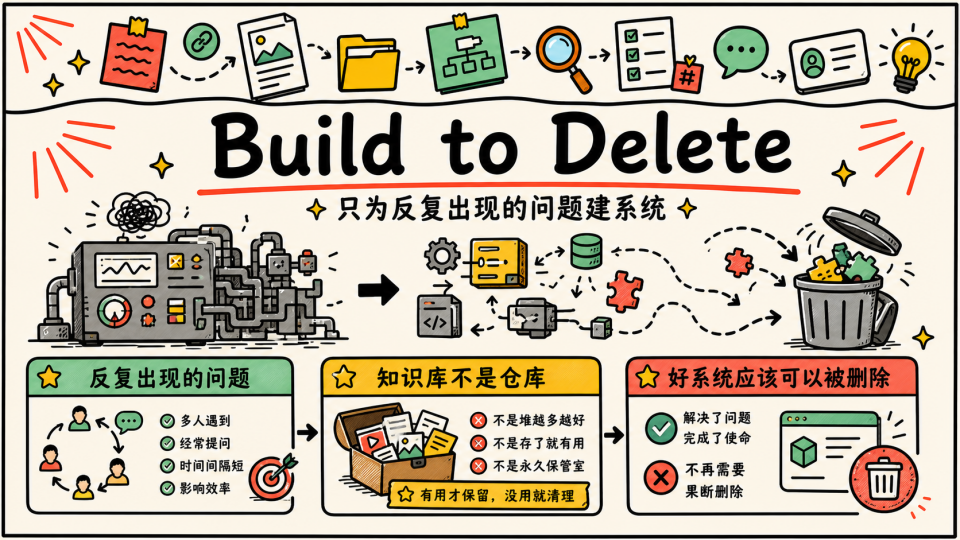
Build To Delete
后来我给自己定了一个很简单的原则,只有一种场景真的值得建全自动信息系统,你有明确边界的知道如何做评估的、短期内需要反复关注的问题,比如:
- 我反复需要判断某类 AI 安全风险,那就值得建立信息源和案例库
- 我反复需要追踪某类产品形态,那就值得做固定观察
- 我反复需要回答某个技术方案是否可行,那就值得积累评估维度和历史材料
另外如果一个 TODO 超过一周都没有再触动我,我现在倾向于直接删掉,说明它并没有那么重要,至少不值得继续占用心理空间
简单来说就是如果一个东西不再服务于真实问题,只是在维持一种 “我在持续学习” 的感觉时,它就应该被删掉、缩小,或者重建,这一点和 Harness 的一个概念有点一样 Build to Delete,信息系统是为了在特定阶段服务一个真实问题而存在的
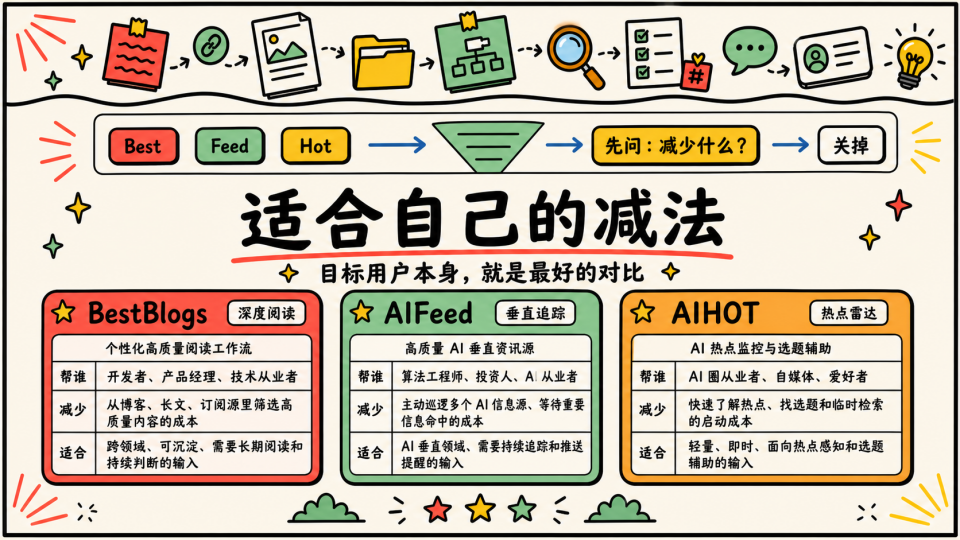
接下来做一个辅助证明,后面我关注到外面有很多现成地产品在做类似的事情,比如 BestBlogs、AIFeed、AIHOT 当然还有其他的,如果你打开看过体验过,就会有一种感觉,他们的信息收集和分发机制都不太一样,以前我没想清楚的时候只是在无脑互相拉踩,后面我才想清楚本质上是因为他们面向的受众不同,这也从侧面证明了减法的意义
| 维度 | BestBlogs | AIFeed | AIHOT |
|---|---|---|---|
| 核心定位 | AI 驱动的个性化高质量阅读工作流 | 高质量的 AI 资讯源 | AI 热点监控与选题辅助网站 |
| 目标用户 | 开发者、产品经理、技术从业者 | AI 领域的算法工程师、投资人、从业者 | AI 圈从业者、自媒体、爱好者 |
| 更像在减少什么 | 从大量博客、长文、订阅源里筛选高质量内容的成本 | 主动巡逻多个 AI 信息源,以及等待重要信息命中的成本 | 快速了解 AI 圈热点、找选题和临时检索的启动成本 |
| 更适合什么输入 | 跨领域、可沉淀、需要长期阅读和持续判断的输入 | AI 垂直领域、需要持续追踪和推送提醒的输入 | 轻量、即时、面向热点感知和选题辅助的输入 |
从这个角度看,它们其实不完全是在同一个层面竞争,也不存在某个工具好,另一个工具不好。
真正需要问的是:我现在到底需要哪一种输入?如果我需要的是深度,就不要用热点流假装学习。如果我需要的是提醒,就不要搭一个过度复杂的知识库。如果我只是想保持轻量感知,就不要因为别人都在做自动化系统,自己也跟着把所有信息都收进来。
减法不是无脑删到越少越好,也不是把所有工具都换成最极简的版本。减法应该是把不服务于自己真实问题的东西删掉,把和自己阶段、兴趣、工作方式不匹配的输入关掉
每个人的情况经历不一样,兴趣点也不一样,能承受的信息密度也不一样
适合自己的减法,比看起来更彻底的减法更重要
Not Just Too Much
但如果再往后想一步,这个结论其实还有另一面
真的只是因为 “信息量太大”,所以我不得不做取舍吗?
如果只是信息变多,那问题仍然可以被理解成效率问题:我需要更好的信息源、更好的过滤器、更好的摘要、更好的检索系统
但真正让我开始减少输入的原因,不只是信息变多,而是噪声开始系统性变多
AI 上半场的时候,很多内容确实有新鲜感,技术刚出来,边界还没有被充分探索,很多人是带着真实问题在试,文章、项目和讨论里经常能看到一手经验
但到了下半场,信息生态开始变得逐渐复杂
- 一部分内容是在认真记录实践
- 一部分内容是在复述共识
- 一部分内容是在包装概念
- 还有一部分内容,只是在借着焦虑制造流量
所以问题不只是我看不过来
更准确地说,是我不再愿意让这些噪声消耗我的注意力,从而错过了一些真正有意义的东西
这也是为什么我现在越来越觉得,筛选不是信息过载之后的被动防御,而是一种主动选择

What Sticks
所以最后留下来的,不是那些被收集过的文章、链接、日报、周报、月报、知识库
它们当然有用,但它们不是最重要的东西。
过去一年,我以为自己是在围绕信息建系统。
回头看,其实是在围绕思考本身,重建自己的注意力机制。
这也是我现在越来越理解为什么 memory 和个性化会变得重要。
不是因为人需要一个无限大的外部记忆,而是因为真正有价值的系统,应该理解你的问题、方向、偏好和历史判断,并且在合适的时候帮助你回到真正重要的东西上。
但在那之前,人自己也要先有一个判断:
- 什么值得进入我?
- 什么只是经过我?
- 什么会改变我?
信息过载时代,最稀缺的不是信息,也不是工具,而是能持续形成判断的注意力,我觉得这个是我在 ai 时代学习中最有收获的事情之一,借这个交流的机会分享给大家
