0x01 基本介绍
这篇文章主要是记录基于语法的模糊测试,我将描述有关如何尝试Fuzzing一些PDF软件(例如Foxit和Adobe)的步骤。
为此,我使用了以下工具:
· domato!(https://github.com/googleprojectzero/domato)
· Debenu Quick PDF Library,撰写本文时的当前版本是17.11。
· BugId帮助我们对Crashs进行分类。
· 你最喜欢的PDF解析器/软件!
我们将安装Debenu Quick PDF库并利用其SDK和函数。为什么说的是基于大量复杂格式(例如PDF)的语法?PDF文件格式包括文本,图像,多媒体,JavaScript,并且具有非常复杂的解析代码。尽管可以使用诸如Checkpoint的智能Fuzzer,但我们可以利用该库的优势,该库提供了大量函数,从处理HTML对象到添加图像,字体,甚至添加自定义javascript!
0x02 基于语法的模糊测试
智能(基于模型,基于语法或基于协议的Fuzzer)利用输入模型生成更大比例的有效输入。例如,如果可以将输入建模为抽象语法树,则基于智能突变的Fuzzer将采用随机变换将完整的子树从一个节点移动到另一个节点,如果输入可以通过形式语法建模,则基于智能生成的Fuzzer将实例化生产规则以生成相对于有效的输入。但是,通常必须明确提供输入模型,如果模型是专有的,未知的或非常复杂的,则很难做到这一点。
简而言之,基于语法的算法了解输入结构,而不是暴力Fuzzing,我们无需了解目标/文件/网络协议规范就可以简单地对字节进行更改,现在对结构也有所了解了(例如此处介绍的API),并且我们将根据该规范生成测试用例。
有很多教程,但是我建议你看看domato的文档,在这里你可以完全了解它的工作原理。如前所述,我们将创建一个语法,因此该函数如下:
int DPLDrawHTMLText(int InstanceID, double Left, double Top, double Width, wchar_t * HTMLText)
可以伪造 但有效的输入,如下列:
DrawHTMLText(1,2,1,"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"); DrawHTMLText(0.285839975231,4.0,10000000.0,"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"); DrawHTMLText(5.0,4294967295.0,2147483647.0,"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"); DrawHTMLText(65.862385207,9.2399248386,8.01963632388,"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA");
0x03 DebenuPDF库入门
安装了试用版,需要注册ActiveX DLL。可以通过以DLL的%systemroot%\System32\regsvr32.exe64位版本(DebenuPDFLibrary64AX1711.dll)或%systemroot%\SysWoW64\regsvr32.exe注册32位版本(DebenuPDFLibraryAX1711.dll)的方式来完成操作,在此期间,请务必记下TRIAL_LICENSE_KEY.TXT以后将需要它来生成文件。
浏览该库并阅读文档,可以看到该库提供了多种绑定:从C#,C ++,Delphi,Objective-C到Perl,PHP,VB6,VBScript和Visual Basic(.NET)。如果你想尝试,请继续访问此页面!此外,该库提供了许多可以作为目标的函数组:
https://www.debenu.com/products/development/debenu-pdf-library/help/samples/
我最终使用了Visual Basic和Perl绑定。创建语法后,很容易修改模板并使用另一种语言,这就是基于语法的Fuzzing之美!
使用下面的Visual Basic示例:
' Debenu Quick PDF Library Sample
' * Remember to set your license key below
' * This sample shows how to unlock the library, draw some
' simple text onto the page and save the PDF
' * A file called hello-world.pdf is written to disk
WScript.Echo("Hello World - Debenu Quick PDF Library Sample")
Dim ClassName
Dim LicenseKey
Dim FileName
ClassName = "DebenuPDFLibraryAX1711.PDFLibrary"
LicenseKey = "" ' INSERT LICENSE KEY HERE
FileName = "hello-world.pdf"
Dim DPL
Dim Result
Set DPL = CreateObject(ClassName)
WScript.Echo("Library version: " + DPL.LibraryVersion)
Result = DPL.UnlockKey(LicenseKey)
If Result = 1 Then
WScript.Echo("Valid license key: " + DPL.LicenseInfo)
Call DPL.DrawText(100, 500, "Hello world from VBScript")
If DPL.SaveToFile(FileName) = 1 Then
WScript.Echo("File " + FileName + " written successfully")
Else
WScript.Echo("Error, file could not be written")
End If
Else
WScript.Echo("- Invalid license key -")
WScript.Echo("Please set your license key by editing this file")
End If
Set DPL = Nothing使用DLL的32位版本执行它会产生以下输出:
用福昕软件打开它,我们可以确认我们的文件已经生成!
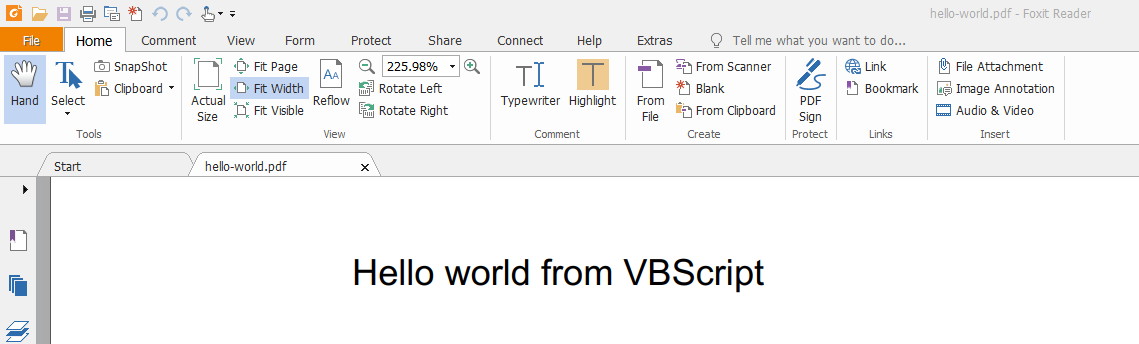
几分钟后,我们设法建立了测试用例库,获取了一些示例代码并生成了有效的PDF文件。
0x04 创建测试用例
为了演示domato的功能,我们以以下示例函数为目标:
如你所见,此函数需要四个参数: double Left, double Top, double Width, wchar_t * HTMLText)
因此,SDK需要以下调用:
DrawHTML(200.0, 400.0, 800.0,"my text")
用domato构建上述函数调用并创建语法很简单,我们只需要定义一个符号并分配其相应的值即可。该值可以是类似MAX_INT或MIN_INT的值,它们可能导致常见的有符号/无符号整数上溢/下溢或不确定行为的通用值。
= "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA" = 32768 = 65535 = 65536 = 1073741824 = 536870912 = 268435456 = 4294967295 = 2147483648 = 2147483647 = -2147483648 = -1073741824 = -32769 = -1.0 = 0.0 = 1.0 = 2.0 = 3.0 = 4.0 = 5.0 = 10.0 = 1000.0 = 10000.0 = 10000000.0 = = = = = ,, = DrawHTMLText(,)
继续,由于我们将生成代码,因此必须包含!begin linesand !end lines关键字:
!begin lines $QP->; !end lines
遵循API规范并创建HTMLText方法可以在几行内完成:
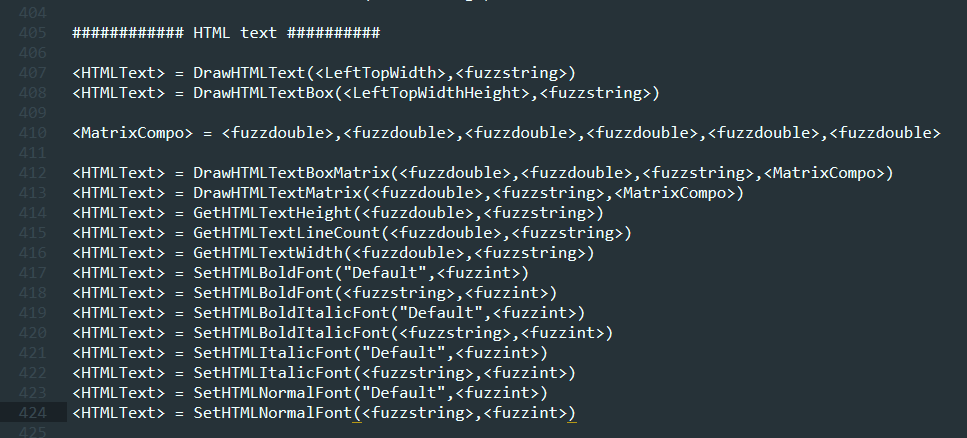
创建template.pl
掌握了基本语法后,我们如何在绑定中调用这些函数?实际上,查看先前的github代码,我们只需要提供经过稍微修改的示例代码即可,如下所示:
https://github.com/googleprojectzero/domato/blob/master/canvas/template.html
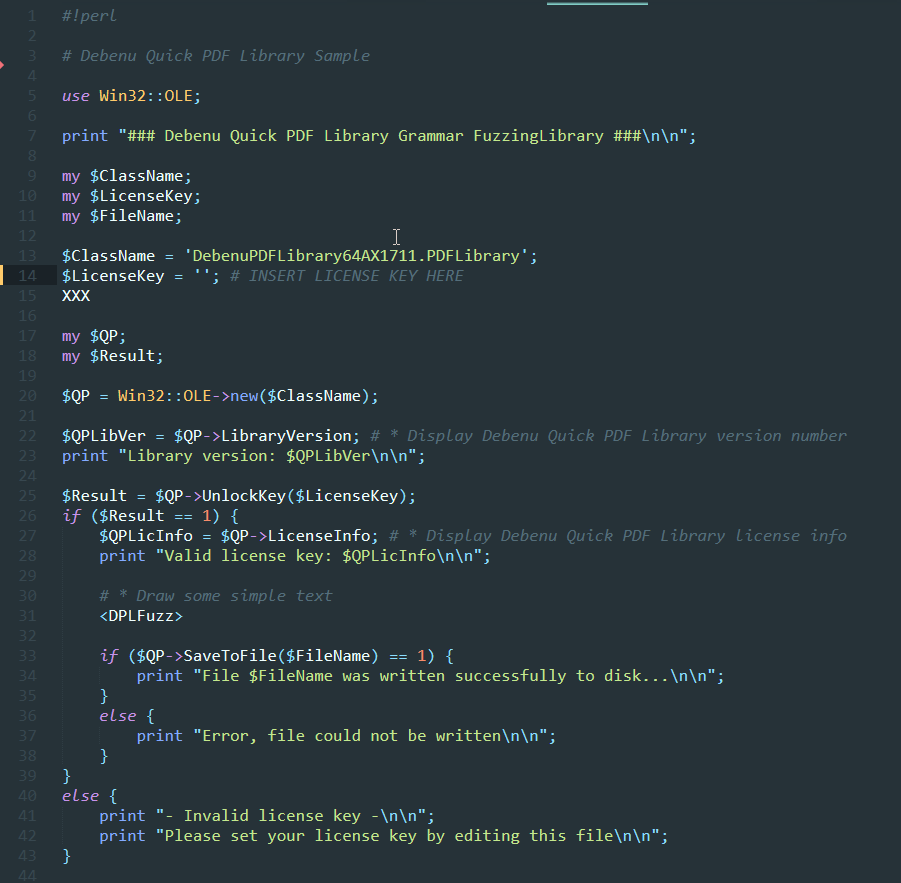
从上面的截图中,你可以看到:
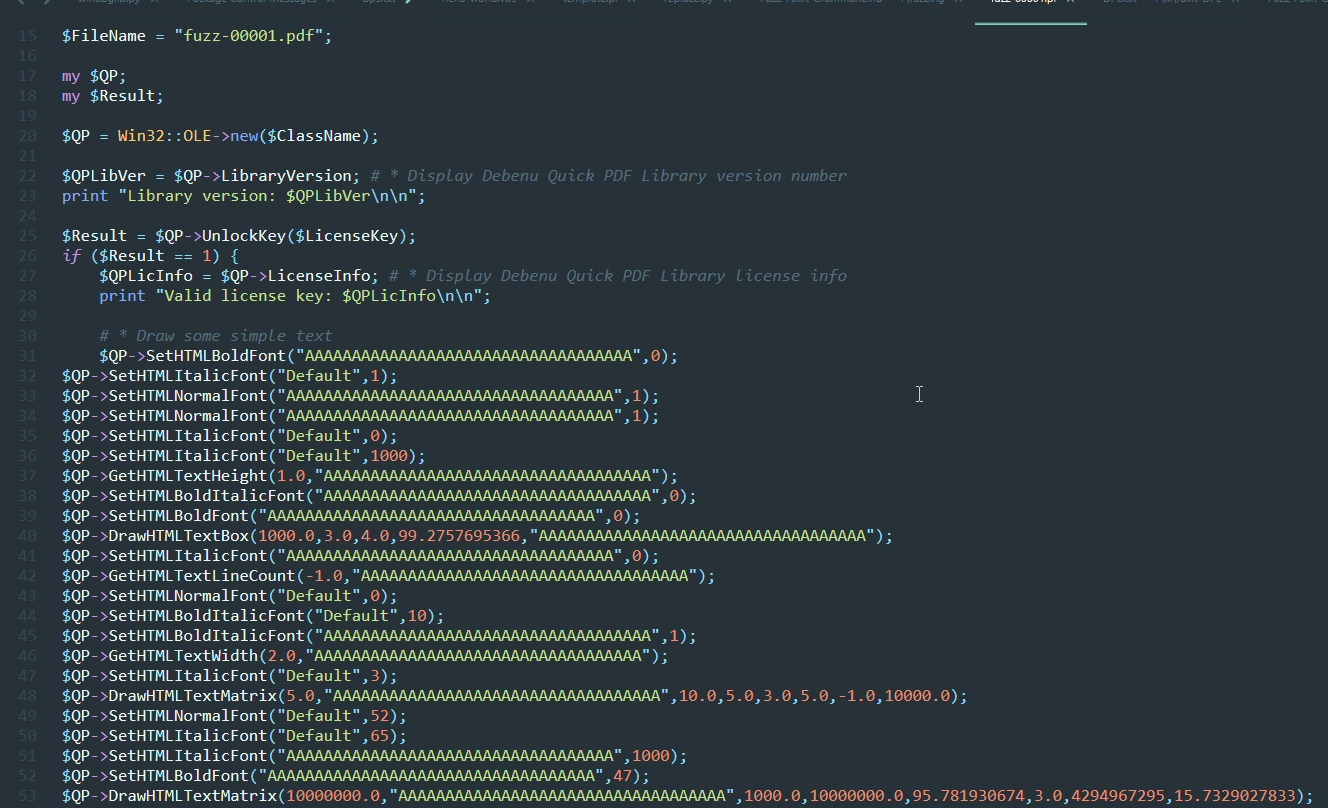
现在,我们的下一步是创建一个文件,在该文件中生成此语法(称为generator)。这可以通过使用已有的文件(例如Ivan的generator.py)进行一些修改来实现:
# Domato - main generator script
# -------------------------------
#
# Written and maintained by Ivan Fratric #
# Copyright 2017 Google Inc. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import os
import re
import random
import sys
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), os.pardir))
sys.path.append(parent_dir)
from grammar import Grammar
_N_MAIN_LINES = 50
_N_EVENTHANDLER_LINES = 25
def generate_function_body(jsgrammar, num_lines):
js = jsgrammar._generate_code(num_lines)
return js
def GenerateNewSample(template, jsgrammar):
"""Parses grammar rules from string.
Args:
template: A template string.
htmlgrammar: Grammar for generating HTML code.
cssgrammar: Grammar for generating CSS code.
jsgrammar: Grammar for generating JS code.
Returns:
A string containing sample data.
"""
result = template
handlers = False
while '' in result:
numlines = _N_MAIN_LINES
if handlers:
numlines = _N_EVENTHANDLER_LINES
else:
handlers = True
result = result.replace(
'',
generate_function_body(jsgrammar, numlines),
1
)
return result
def generate_samples(grammar_dir, outfiles):
"""Generates a set of samples and writes them to the output files.
Args:
grammar_dir: directory to load grammar files from.
outfiles: A list of output filenames.
"""
f = open(os.path.join(grammar_dir, 'template.pl'))
template = f.read()
f.close()
jsgrammar = Grammar()
err = jsgrammar.parse_from_file(os.path.join(grammar_dir, 'DPL.txt'))
if err > 0:
print('There were errors parsing grammar')
return
for outfile in outfiles:
result = GenerateNewSample(template, jsgrammar)
if result is not None:
print('Writing a sample to ' + outfile)
try:
f = open(outfile, 'w')
f.write(result)
f.close()
except IOError:
print('Error writing to output')
def get_option(option_name):
for i in range(len(sys.argv)):
if (sys.argv[i] == option_name) and ((i + 1) < len(sys.argv)):
return sys.argv[i + 1]
elif sys.argv[i].startswith(option_name + '='):
return sys.argv[i][len(option_name) + 1:]
return None
def main():
fuzzer_dir = os.path.dirname(__file__)
multiple_samples = False
for a in sys.argv:
if a.startswith('--output_dir='):
multiple_samples = True
if '--output_dir' in sys.argv:
multiple_samples = True
if multiple_samples:
print('Running on ClusterFuzz')
out_dir = get_option('--output_dir')
nsamples = int(get_option('--no_of_files'))
print('Output directory: ' + out_dir)
print('Number of samples: ' + str(nsamples))
if not os.path.exists(out_dir):
os.mkdir(out_dir)
outfiles = []
for i in range(nsamples):
outfiles.append(os.path.join(out_dir, 'fuzz-' + str(i).zfill(5) + '.pl'))
generate_samples(fuzzer_dir, outfiles)
elif len(sys.argv) > 1:
outfile = sys.argv[1]
generate_samples(fuzzer_dir, [outfile])
else:
print('Arguments missing')
print("Usage:")
print("\tpython generator.py ")
print("\tpython generator.py --output_dir --no_of_files ")
if __name__ == '__main__':
main()保存测试用例
在继续之前,请注意在提供的示例代码(hello-world.vbs)上,此行负责保存文件名: FileName = "hello-world.pdf"。这是硬编码的,当然不适合我们。为了解决这个问题,我编写了一个非常简单的代码,一个python脚本,它会找到“占位符”,它是硬编码值XXX,并将其替换为fuzz-
0x05 BugId 介绍
如果你还没有阅读这篇Fuzz文章,请花一些时间,看看如何将BugId集成到你的Fuzzing工作流程中。
https://blog.skylined.nl/20181017001.html
我们不是在Fuzzing浏览器,而是一个接一个地循环生成的案例。我修改了一些部分以显示这些更改,如下所示:

本质上,我们在这里执行Domato的生成器,用实际的文件名替换XXX标记,从domato执行perl生成的案例,最后将生成的PDF保存到我们的测试文件夹中。
经过上述修改,执行BAT文件后,将为我们提供以下截图:

0x06 组装在一起
将所有这些步骤组合在一起,运行cmd文件,并查看其进展情况:

通过使用开源工具,并且经过不懈的努力,我们现在不仅可以Fuzzing Foxit软件,而且可以Fuzzing所有PDF解析器!
出人意料的是,尽管从创建语法到修改BugId都花了很多功夫,但不幸的是,我设法获得的唯一Crashs是一些毫无意义的NULL指针取消引用。
0x07 注意事项
有趣的是,我最初使用了Visual Basic绑定,但是,一旦将非常大的整数传递给这些方法,Visual Basic就会无法生成大小写,如下所示:

请注意,如果参数或分配错误,它还会通知用户。
0x08 分析总结
在这篇文章中,我们介绍了基于语法的模糊测试的。我们使用了Quick PDF库,可以在其中应用这些知识,并演示了如何从头开始创建语法。我们还在API生成结构感知的测试用例中Fuzzing了示例函数。最后,我们使用BugId来遍历我们的情况,以防发现崩溃。这种模糊测试不仅可以用于特定的库,而且可以用于基于文本甚至是编程语言的每种文件格式!
本文翻译自:https://symeonp.github.io/2020/04/18/grammar-based-fuzzing.html如若转载,请注明原文地址:
如有侵权请联系:admin#unsafe.sh