
2020-12-02 09:46:43 Author: medium.com(查看原文) 阅读量:261 收藏
Or, documentation + source code = knowledge, profit(?)
![]()
I’m a big fan of the old school approach to hacking. The core idea being: learn everything about the target. Back in the day, it was done by sometimes digging through trash, and other times “borrowing” hard copy documentation about the system that you would want to hack.
Luckily, today, most of it is somewhere online, and in most cases, it can be accessed for free. But, Wappalyzer isn’t capable of detecting all of the systems out there, unfortunately. That’s when you have to use a bit of logic, a lot of intuition, and whatever comments you can find inside html source code.
Getting to know your target:
After you have determined that the website is running something unknown to you and to Wappalyzer, it’s time to approach learning about it in a way that the old school hackers used to do it: get the source code.
In the case of something like jira, it’s utterly simple — download the jira zip file and make a wordlist from it. Now, I know, there are already wordlists for jira, and for django, wordpress, etc., but jira is just an example.
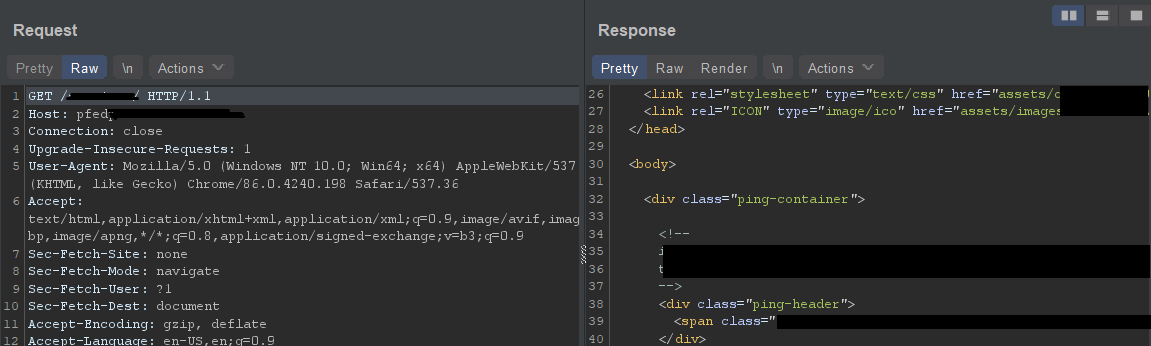
The real-world scenario is stumbling on a website that happens to have https://website.com/pf or /pfed, etc. But, that isn’t enough. That’s when even something like html source code can be of help:
Digging deeper:
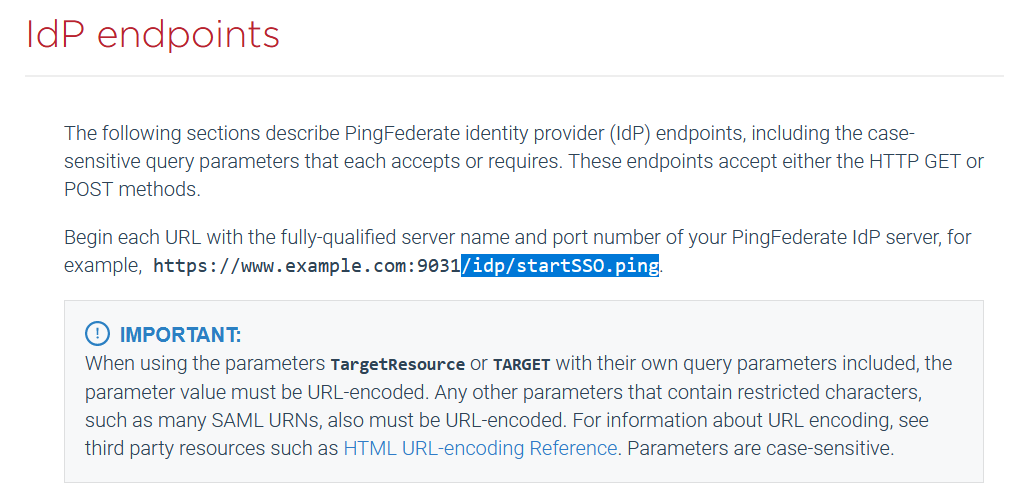
It’s also useful if you can find documentation that lists the endpoints, their parameters, headers, etc., and how it all works:
Quantity v. Quality:
When it comes to bruteforcing either for files/folders or subdomains, the greatest chance to find something truly critical/useful is by using the biggest wordlist. But, the bigger the wordlist the longer it takes for the results. Granted, if the huge wordlist happens to have a particular endpoint that the target website has as well, and that endpoint is a way to achieve RCE or not blind SSRF, then the wait is worth it. But, it’s far better, more efficient, to use a wordlist that doesn’t include unrelated endpoints. No need to use jira endpoints against a website that doesn’t have jira. This is not to say that you should skip the huge wordlist testing. Do both. If nothing else you may end up having some fun with endpoints that will most definitely be present while waiting for the huge wordlist to be done.
Important note: you may have to adjust the wordlists and/or the ffuf/dirsearch/similar tools to not include additional “/”. While many websites will provide the same result to: /userinfo, //userinfo, there are those that will either redirect to the home page or 404 page.
Quick way to solve this (for ffuf):
sed “s/^\///g” with-slashes-at-start-wordlist.txt > no-slashes-at-start-wordlist.txt
And while the lesser-known platforms may have no (known/public) bugs, it doesn’t mean that those who installed it followed instructions to the letter. I’m talking about leaving interesting endpoints unprotected by mistake, or simply not changing the default credentials.
While this should be well known and used more frequently, I don’t mind repeating it — read the documentation. Also, use found words as search keywords. It could potentially lead to a related discussion on some forum which should then help in identifying additional functionalities/features/bugs.
如有侵权请联系:admin#unsafe.sh