

Hello guys, It’s HolyBugx I started writing this after this tweet, as I saw many interested people wanted me to do it, So I decided to share my knowledge with you The original post is on ZDresearch, but I also shared it here. Without further explanation Let’s get to the point.

A CDN allows for the quick transfer of assets needed for loading Internet content including HTML pages, Javascript files, stylesheets, images, and videos. The popularity of CDN services continues to grow, and today the majority of web traffic is served through CDNs, including traffic from major sites like Facebook, Netflix, and Amazon.
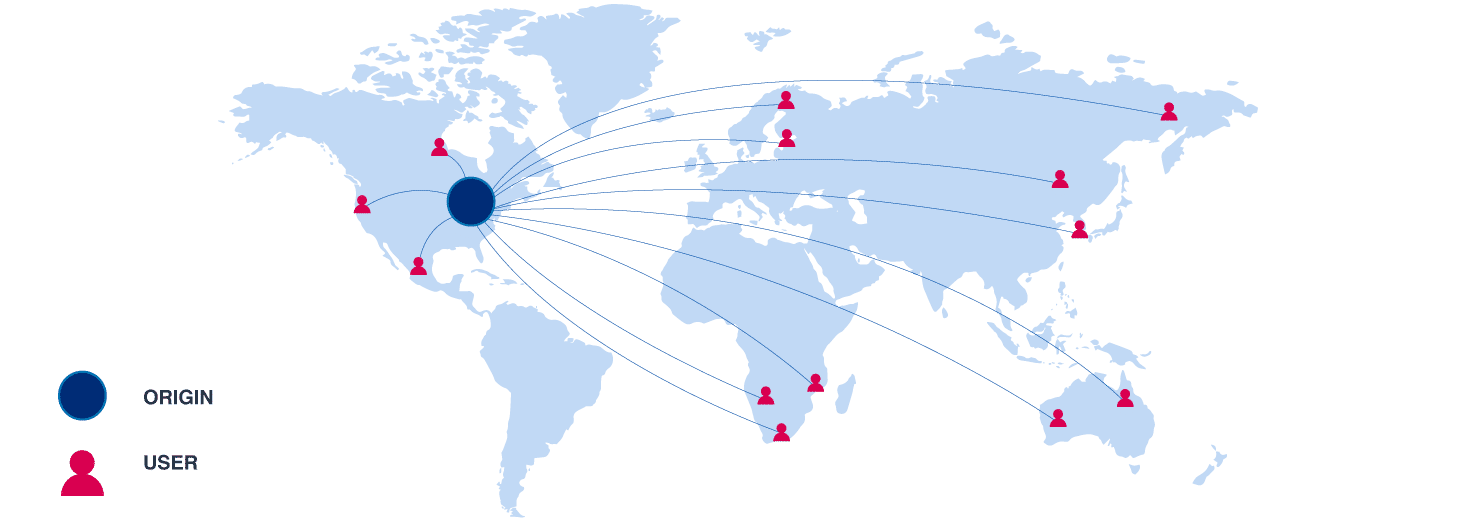
Performance matters, If the website doesn’t use a CDN, all of its users should send their requests to a single server, as this will put a lot of loads on the server, the Performance of the website reduces. Nowadays most websites use a CDN, as it will help them have a better load speed, reducing the bandwidth costs, improving security, etc.
CDNs also offer many specific benefits to different types of businesses and organizations, such as:
- E-Commerce
- Government
- Finance
- Media/Publishing
- Mobile Apps
- Technology and SaaS
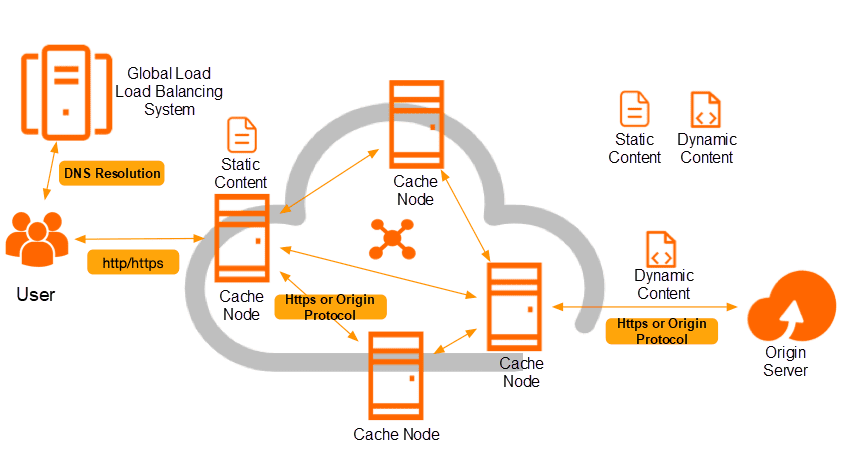
- Improving Website Speed and load times.
- Reducing Bandwidth Costs.
- Improving Website Security.
- SEO Advantages
- Traffic spikes and scalability
- Better conversion rates
- Reliability
- etc.
So if you want to have a reliable website with good performance you should consider using a CDN.
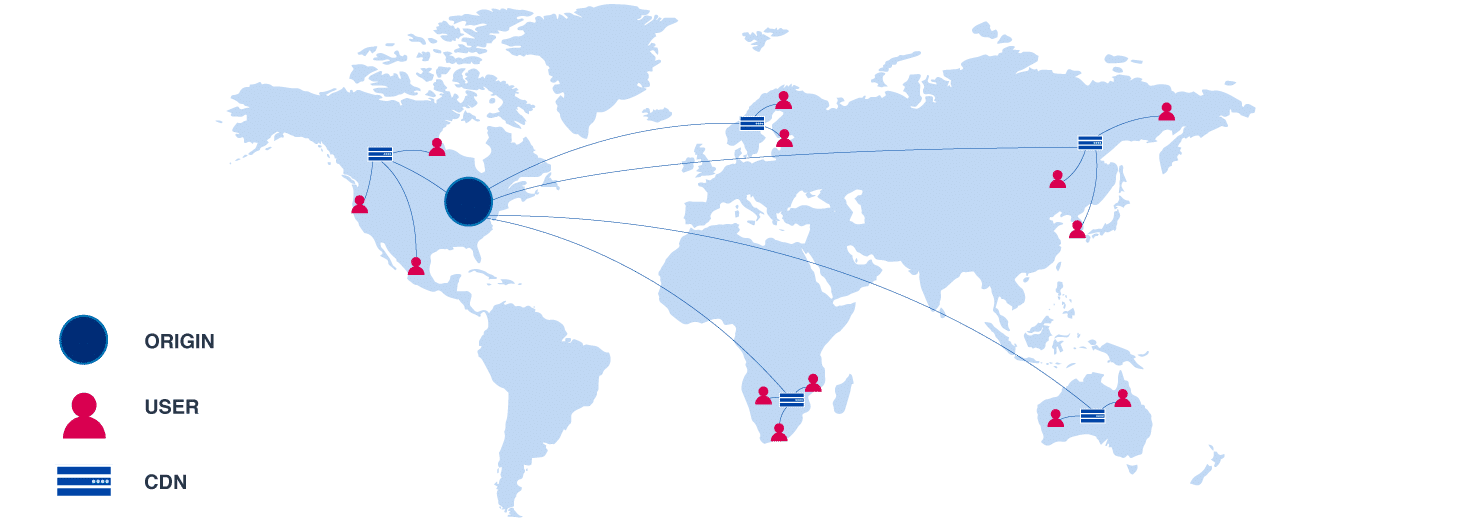
After using a CDN all of the users requesting the contents of the website will get a cached version of it from the closest CDN server, therefore the contents will load much faster, and the performance of the website improves.
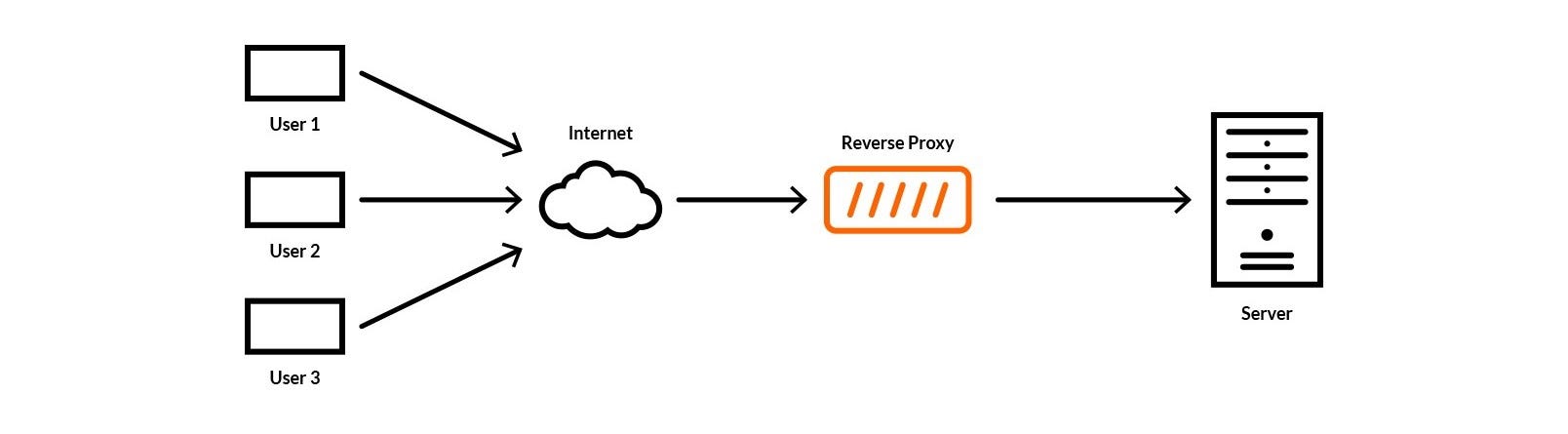
A reverse proxy is a server that takes a client request and forwards it to the backend server. It is an intermediary server between the client and the origin server itself. A CDN reverse proxy takes this concept a step further by caching responses from the origin server that are on their way back to the client. Therefore, the CDN’s servers are able to more quickly deliver assets to nearby visitors. This method is also desirable for reasons such as:
- Load balancing and scalability
- Increased website security
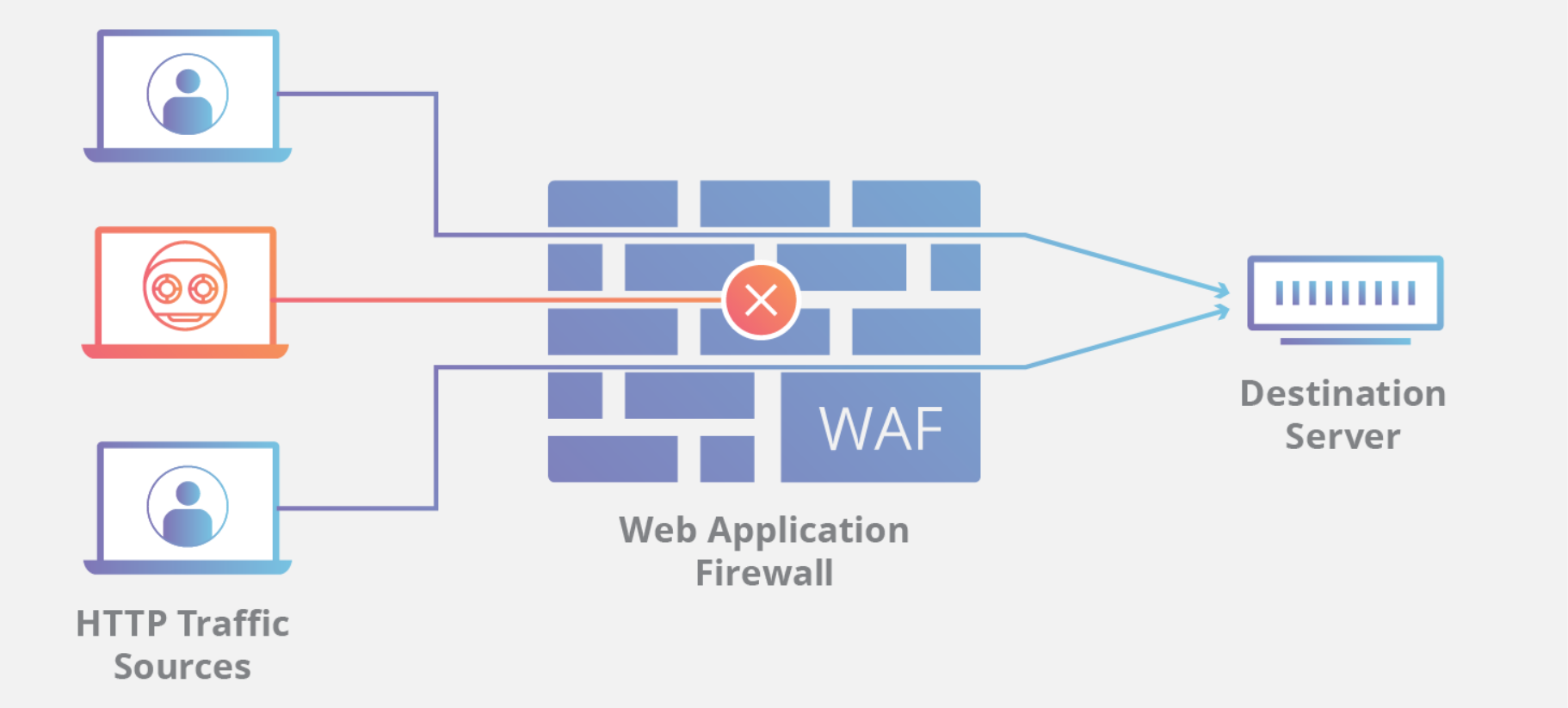
CDNs by themselves cannot block bad bots from infecting a website, CDNs are vulnerable on their own, which is why you need to use a WAF.
A WAF or Web Application Firewall helps protect web applications by filtering and monitoring HTTP traffic between a web application and the Internet.
It typically protects web applications from attacks such as Cross-Site Scripting (XSS), file inclusion, and SQL Injection, among others.
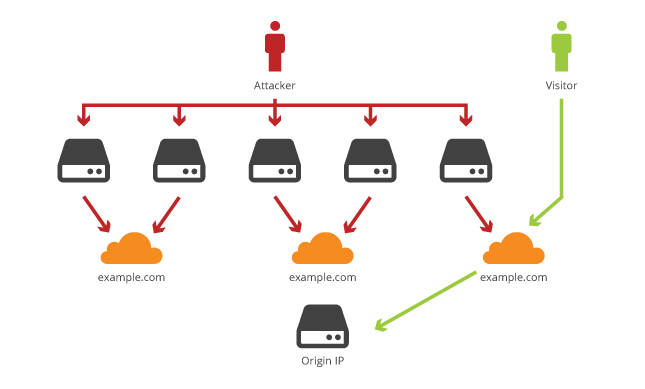
Lots of websites use the protections mentioned above to hide their Origin IP to prevent attackers from DDoS attacks, and other malicious things attackers can do.
These websites mostly use cloud-based security, proxy, or DNS-based services, which makes it a little bit tricky to find the Origin IP.
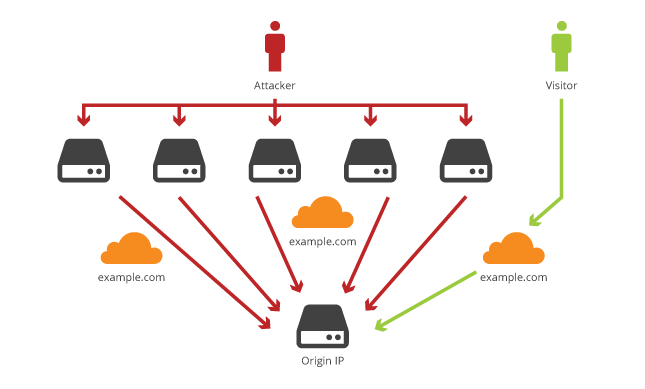
The answer is pretty easy and brief; once you have the Origin IP of a website you can bypass all protections a CDN is providing.

As I mentioned on my Twitter, there are a couple of ways you should try to find the Origin IP Behind a CDN/WAF. We are going to discuss various methods we can use as an attacker.

Whenever you want to bypass something, put yourself in place of your adversary and reverse engineer your thinking process, think as a Blue teamer, and try to find out their security implementation!

This is the common list of things CDN Providers/Blue Teamers do to hide the Origin IP of their Website:
- Keeping all their subdomains on the same CDN
Using other subdomains compared to the Root Domain, they have a higher chance of success, as they might serve files that could lead to Information Disclosure vulnerabilities, therefore leaking the Origin IP.
- Not to initiate an outbound connection based on user action
If we can get the webserver to connect to an arbitrary address, we will reveal the origin IP. Features like “upload from URL” that allow the user to upload a photo from a given URL should be configured so that the server doing the download is not the website origin server. This is important because if an attacker can choose the URL entered, they can set up a website specifically to monitor who connects to it, or use a public service that monitors the IPs that contact unique URLs.
- Changing their Origin IP while configuring CDN
DNS records are many places where historical records are archived. These historical DNS records will contain the website Origin IP Using CDN.
- Restricting Direct Access to the website using IP Address
Another interesting option defenders have, is to restrict the users trying to reach the website using an IP Address, thus the website only loads when the domain name is provided. Let’s explore how we can do this on Nginx
To disable/block direct access to IP for port 80 we create a new server configuration as follows:
server {
listen 80 default_server;
server_name _;
return 404;
}To disable/block direct access to IP for port 443 we use the following in one of our server configurations blocks:
if ($host != "example.com") {
return 404;
}Example:
server {
listen 443 ssl;
server_name example.com ssl_certificate /etc/nginx/ssl/example.com.crt;
ssl_certificate_key /etc/nginx/ssl/example.com.key;
if ($host != "example.com") {
return 404;
}
}
this will block all traffic to https://YOUR_IP_ADDRESS
We are going to discuss bypassing this limitation using an interesting method.
- Whitelisting
A possible solution for allowing only requests from the CDN is simply to whitelist the CDN, as this method might seem promising and enough for defenders to hide their Origin Server, this is rather challenging in practice as they only have 3 methods, and only one of them may work:
Option A: Whitelisting IP Addresses
The problem with whitelisting IP addresses is that they must have the IP addresses of all their CDN edge servers that may access their origin.
This is somewhat problematic. Many CDNs do not give out the list of their IP addresses, and even if they do so, they may add an IP address or even change it and forget to notify them. These whitelists need to be regularly updated not to break the site.
Option B: Whitelisting a Unique Identifier in a Request
The idea is quite simple. The CDN will send a unique Identifier in its requests to the origin server that they can use on the origin to identify the CDN and allow its requests. However, this method is not entirely foolproof. The request can also be freely set by attackers. That is if we know the CDN provider they use and if we also know how the CDN provider identifies itself to the origin server. Attackers can easily spoof the request if they have this information.
Option C: Unguessable Origin Hostname
This is probably the most reliable solution for defenders, as if attackers try to reach the Web Server, they will be unable to locate it. Defenders create some random, long set of alphanumeric characters and use them as the subdomain. For example, if their domain name is “HolyBugx.com” then they set a subdomain name like “2547d0jeid15ma.HolyBugx.com”.
Then this hostname will only be known to them and their CDN Provider, and they can whitelist requests that have this hostname.
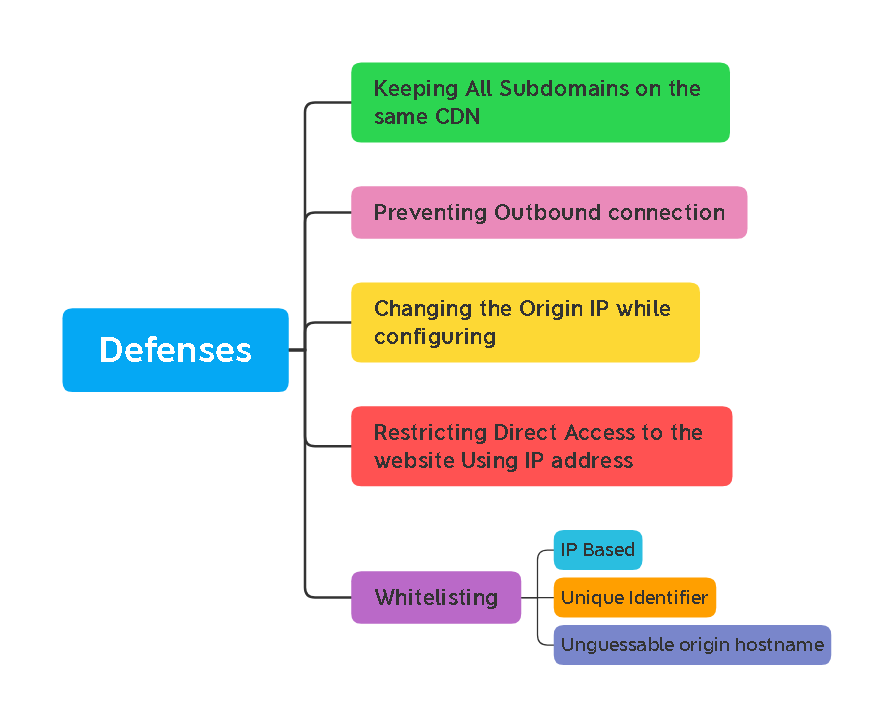

We Just get a Basic understanding of the defender’s point of view trying to protect their Origin Website, Knowing this information we have a Mindmap of what we are going to do, in our thinking process while trying to Bypass these limitations and find the Origin IP of the Web Server.
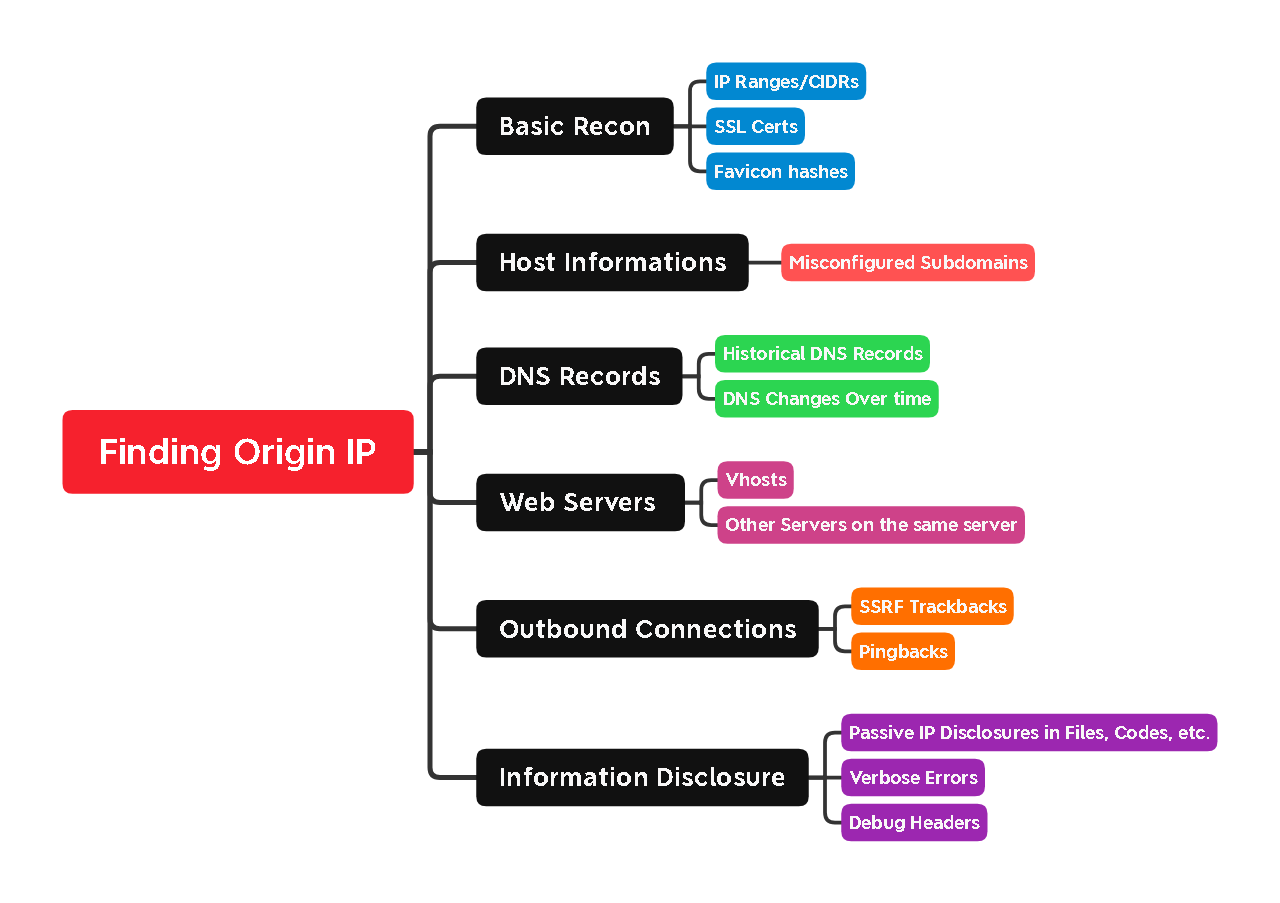
Above is a simple Mindmap on things we should try while testing for the Origin IP Leakage of a website, Let’s deep dive into that.

The most important part is to do some basic recon to get as much information as possible. Our idea is to find Useful information such as:
- IP Ranges/CIDRs
- Host Related Information
- DNS Records
- Web Servers
- Vhosts
- Hosted Servers on the same server as the Web Server (Eg Mail Servers)
- Information Disclosure Vulnerabilities

DNS records are many places where historical records are archived. These historical DNS records will likely contain the website Origin IP Using CDN.
As I mentioned before, there is a possibility that some websites have misconfigured DNS records from which we can gather useful information.
1- SecurityTrails

SecurityTrails enables you to explore complete current and historical data for any internet assets. IP & DNS history, domain, SSL, and Open Port intelligence.
We are going to do a simple Query on our target to see its historical data, Specially for DNS Records, as it let you find out current and historical data of A, AAAA, MX, NS, SOA, and TXT records.
This can be handy to find out the real server’s IP when the website was running directly on the server’s IP and later was moved to CDN.
Then we are going to click on “Historical Data” and view useful information about our target.
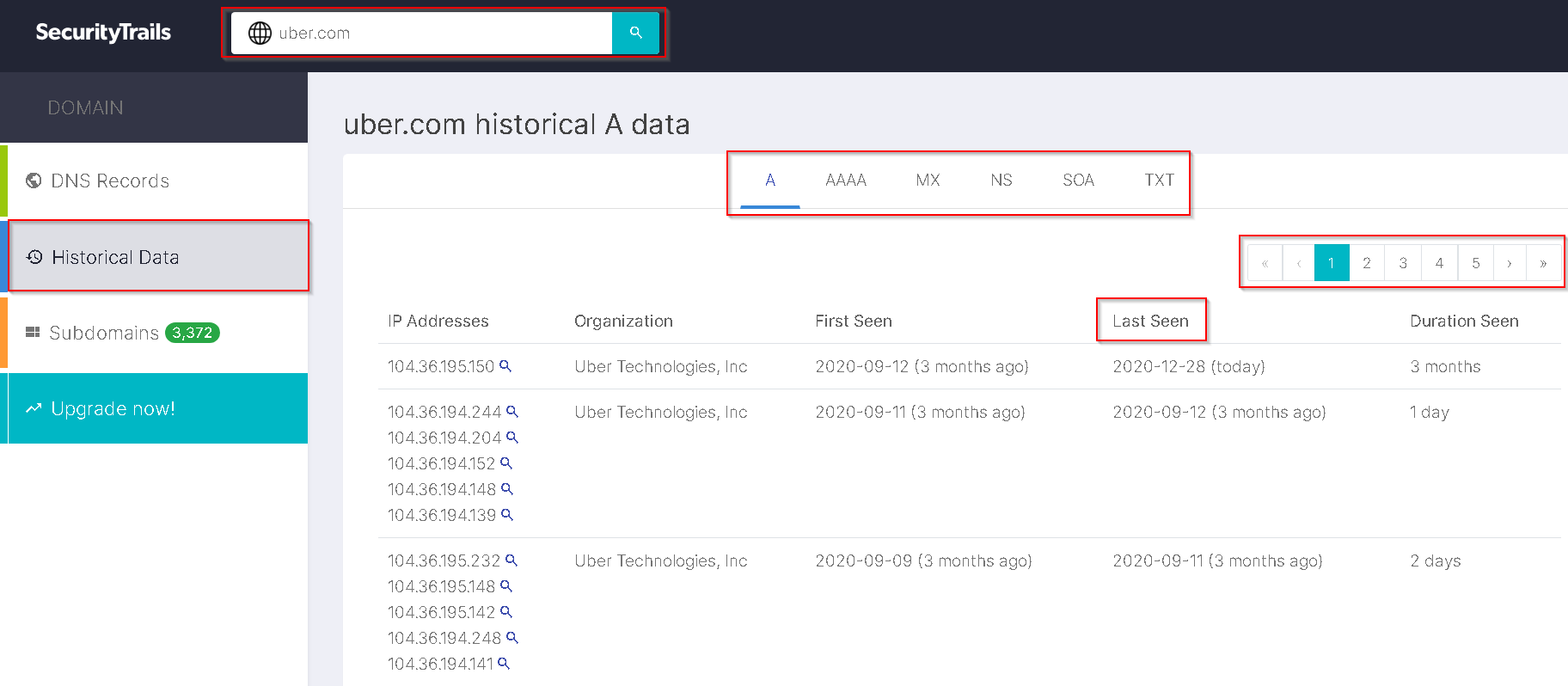
None of the DNS records should contain any mention of the origin IP, Take a close look at any SPF and TXT records to make sure if they contain any information about the origin.
Simply An A, AAA, CNAME, or MX record pointed to the origin server will expose the origin IP.
2- Dig
You can use dig to do some simple Queries for you and also find out if the target is using famous providers such as Cloudflare.
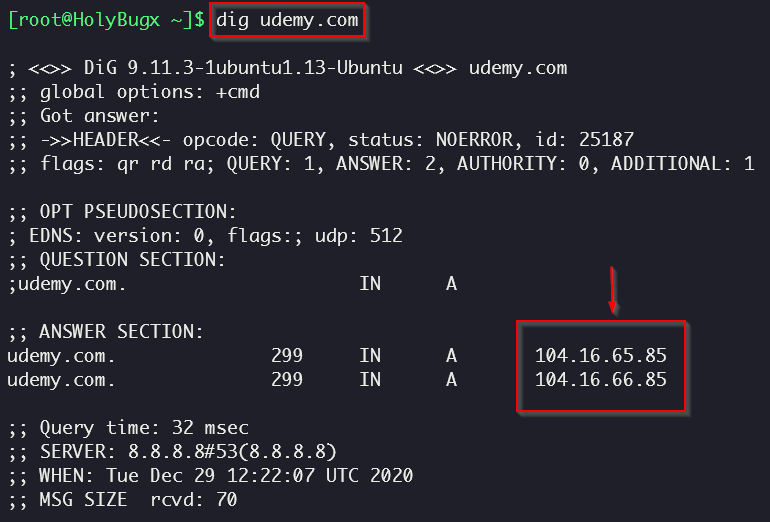
That’s the Cloudflare IP Range, to confirm we can use whois on the A record IP address we found:
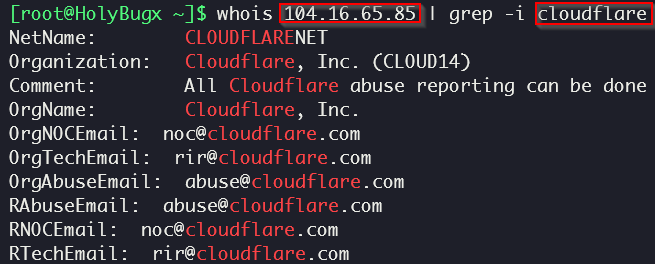
Also, there is another method to find out if the target is behind Cloudflare or not, and that’s by using curl:
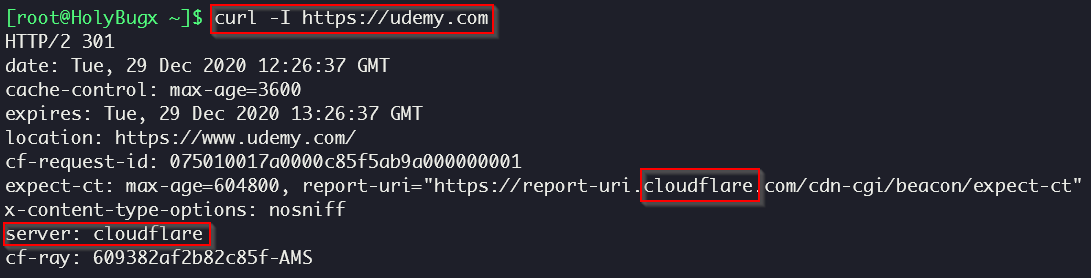
MX records are one of the most favored methods, as to how easy it could be sometimes to find the origin IP. If the mail server is hosted by the same IP as the Web Server, an attacker could find the IP address from an outgoing email.
1- Mail Headers & Reset Password

If the Mail server hosted by the same IP as the Web Server, another interesting option we have is to use “Reset Password” functionality, so we can simply create an account on the target website, and use the Reset Password, the received email, will probably reveal the Origin Server IP.
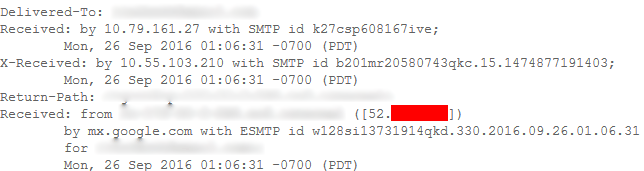
Note that you should gather all the IP addresses you can see in the received email, and try them manually to see if it’s the server Origin IP. Eg Sometimes the value of “Return-Path” can become handy.
2- Outgoing Email

There is another interesting method you can use, sending an email to a non-existent email address to “[email protected]” will cause a bounce; because the user doesn’t exist, the delivery will fail, and you should receive back a notification containing the Origin IP of the server sending you that email.
Once you find the Web Servers, you have a list of Web Servers and their IP addresses, you should find out if the domain you are targeting is configured on those servers as a Virtual Host.
For Vhosts discovery I Suggest Pentest-Tools if you like GUI, and if you are into CLI tools like me, I Suggest these tools:
Using these tools you can find Vhosts, and if your target is configured as a Vhost, then you have the chance to find the Origin IP.

A misconfiguration can be considered easy to exploit, for example, the URL of the contents to load is pointing to an IP that’s not part of a CDN that can be connected to you, like the actual IP of the server.
Q: But one could set up a server with just a CSS file and nothing else (for example), how can you say that IP is the actual IP that we are looking for?
A: Well, actually we are not looking for any real IP of the server behind CDN. We are looking for information to validate, and only after that, we’ll make our conclusions.
Basically, we are looking for IPs that are not part of CDNs.

IoT Search engines are our best friends when we want to do some basic recon about our target and its assets. There are some IoT Search engines that we can query for useful information about our target.
1- Censys

Censys is a platform that helps information security practitioners discover, devices that are accessible from the Internet. With the help of Censys, you could find valuable information such as:
- IP Address
- Open Ports
- SSL Certs
- Hosting Providers
- etc.
The Query for our Article subject is quite straightforward, we can just simply query for the Domain itself and see if there are any IP leaks.
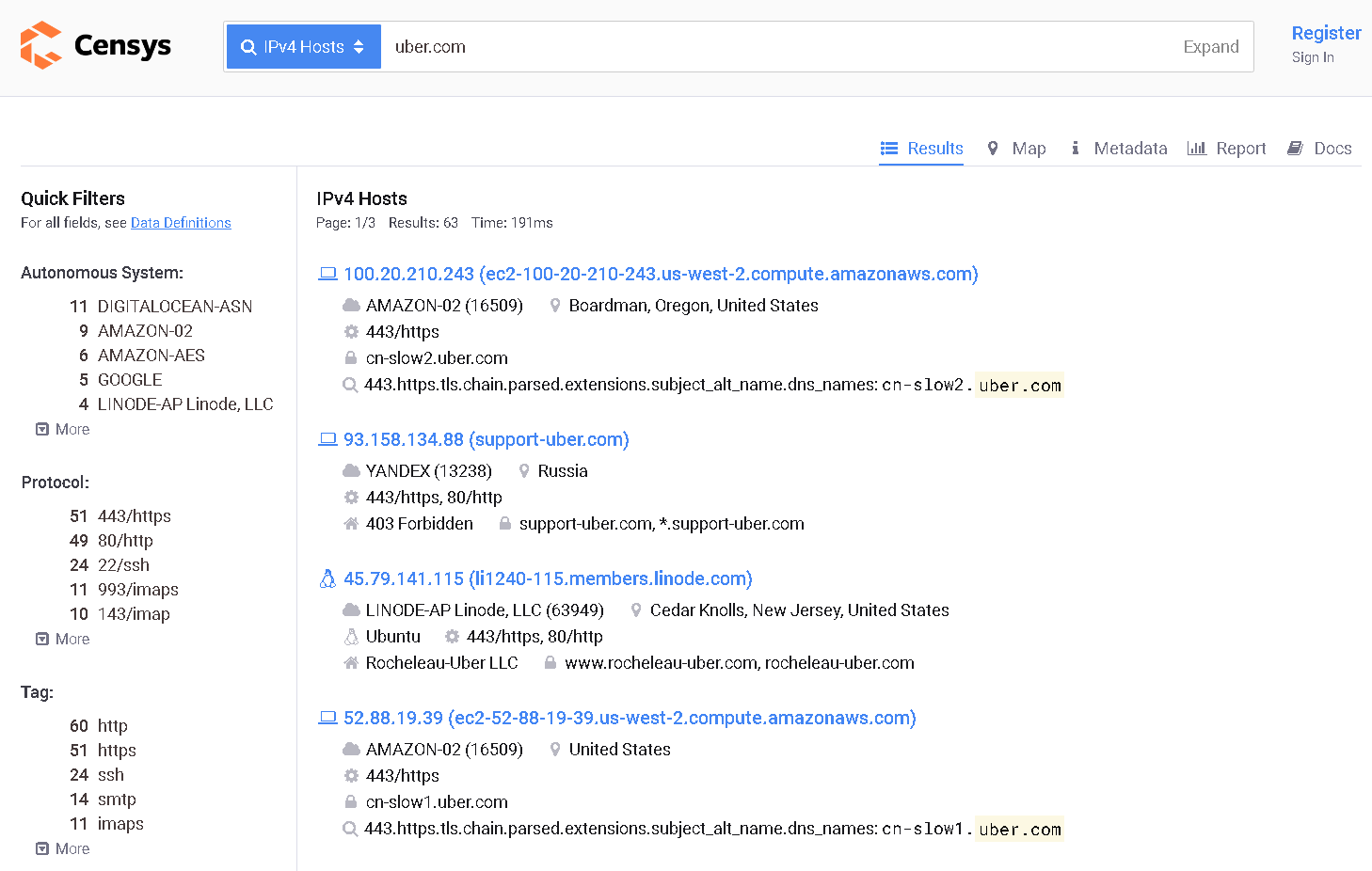
The other method to use is to search using Certificates, Just simply choose Certificates from the blue bar, and search for your target.
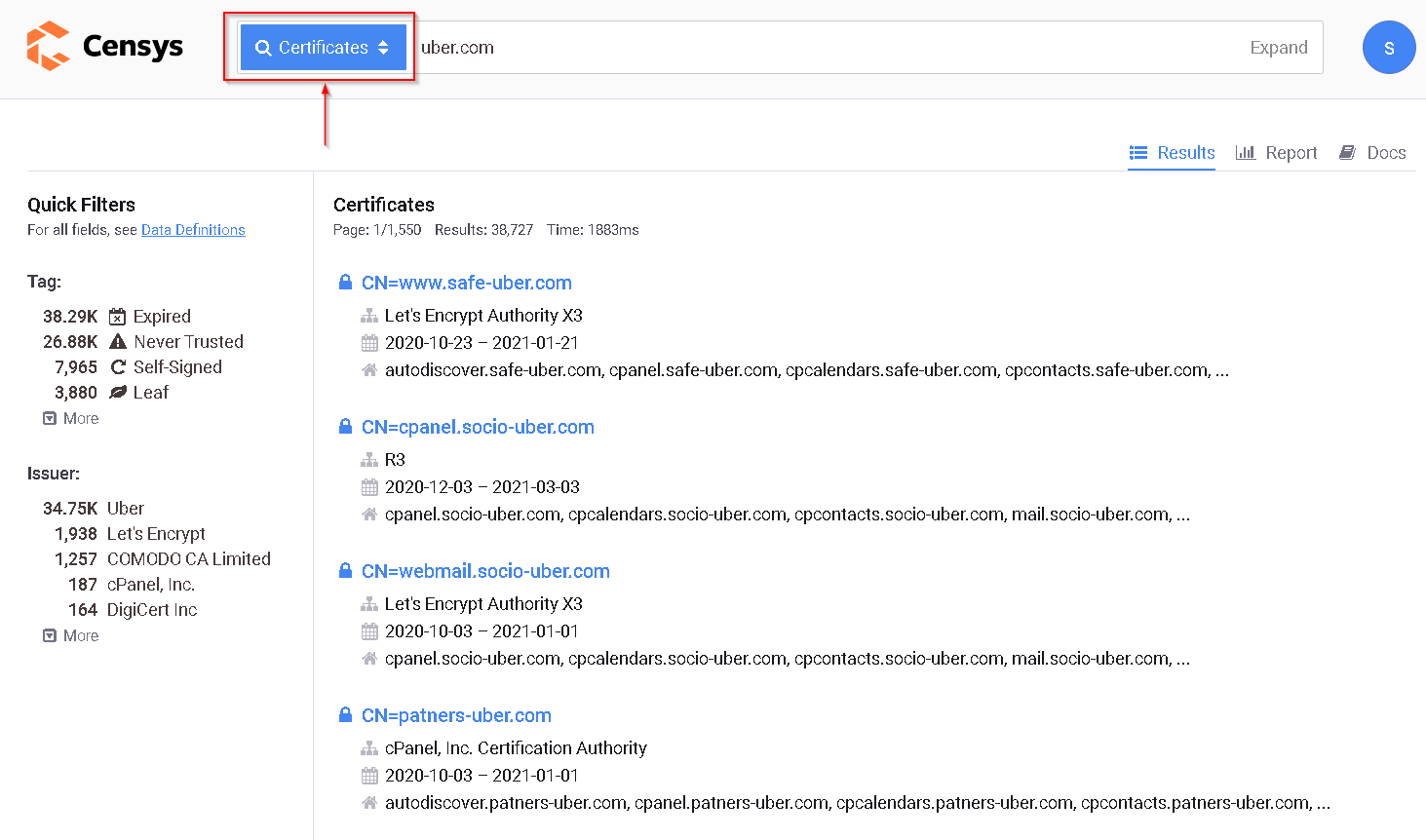
Now open every result to display the details and, from the “Explore” menu at the right, choose “IPv4 Hosts”:
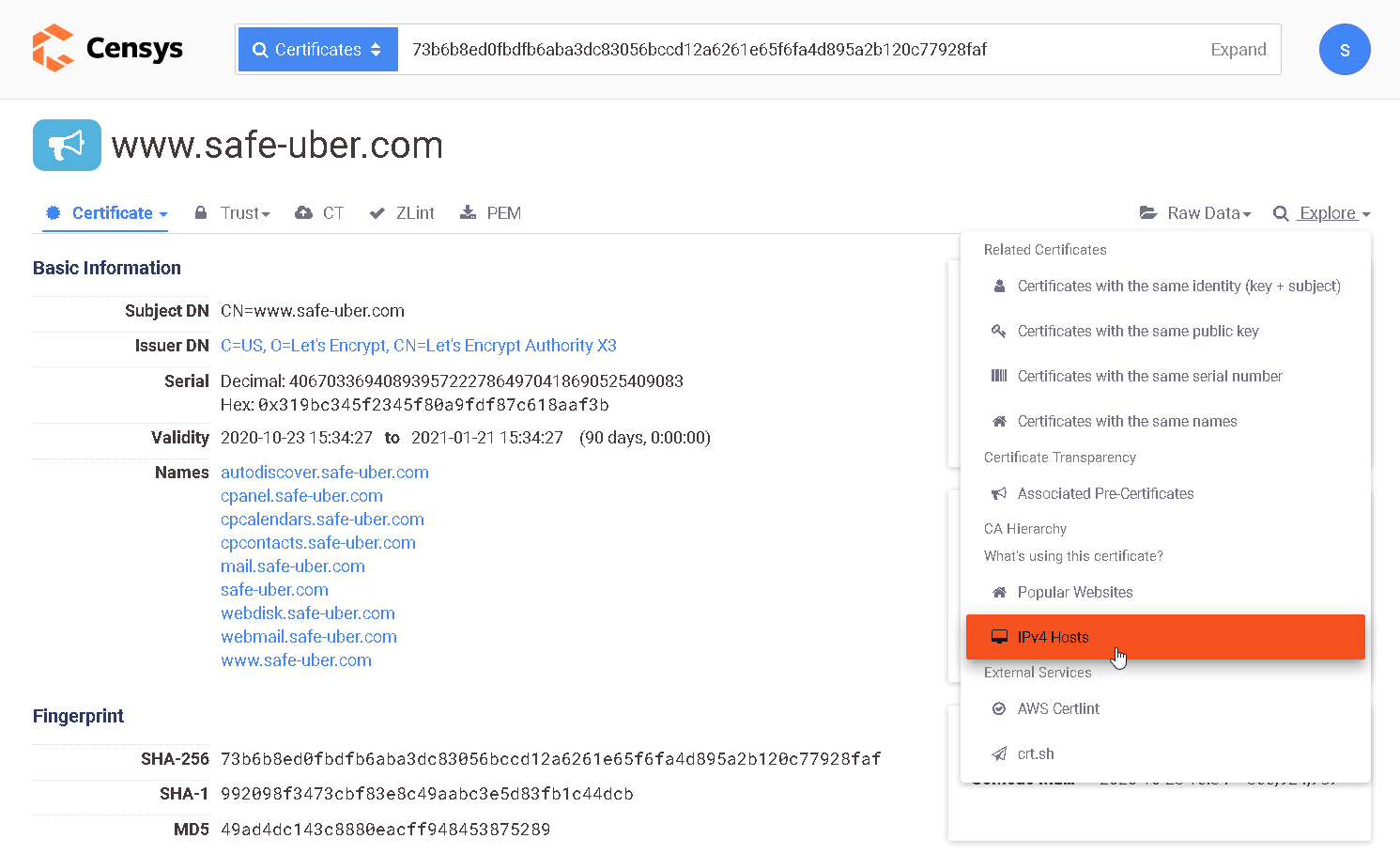
Simply analyze your target, to see if there are any IP leaks, and try to reach your targets using their IP.
To show you how Censys can sometimes lead to the complete IP leakage of the target, I’ll now show you a target I was recently working on, and with the simple IPv4 Query I realized the IP behind CDN:
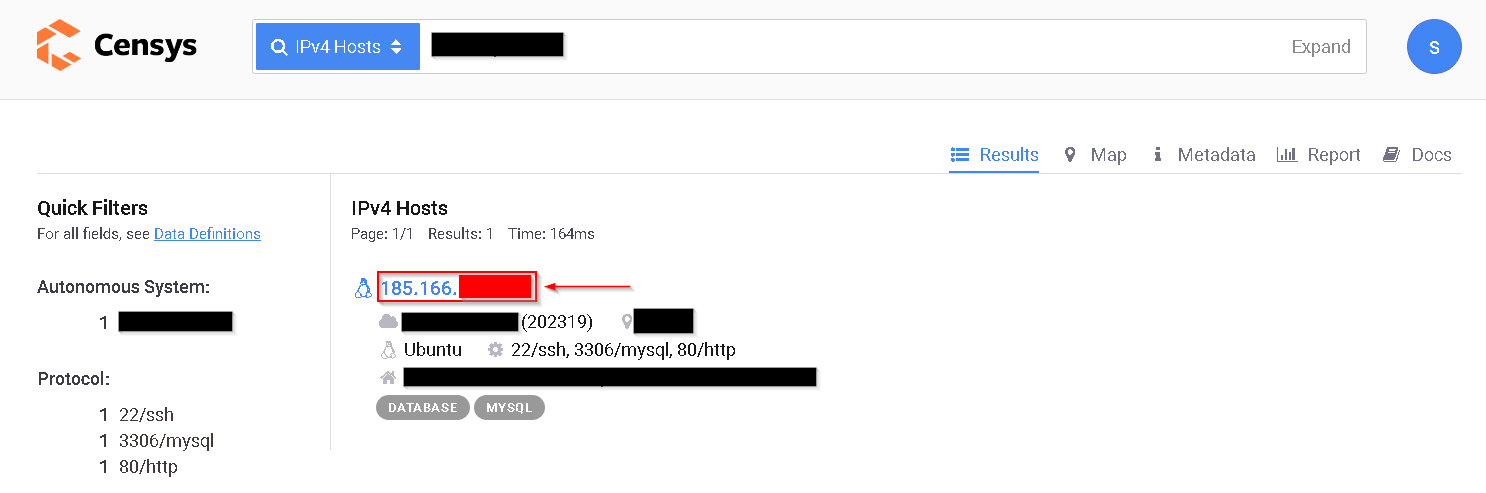
As you can see above, there is an IP that I explored and realized that it’s the Origin IP of the website.
2- Shodan

Shodan is another IoT search engine, It can be helpful for security researchers to find useful information about the target they are approaching.
There is a lot to search for in Shodan, I highly recommend you to check out Shodan Filters Guideline, For the sake of this article, we can just simply query the domain and search for IPs.
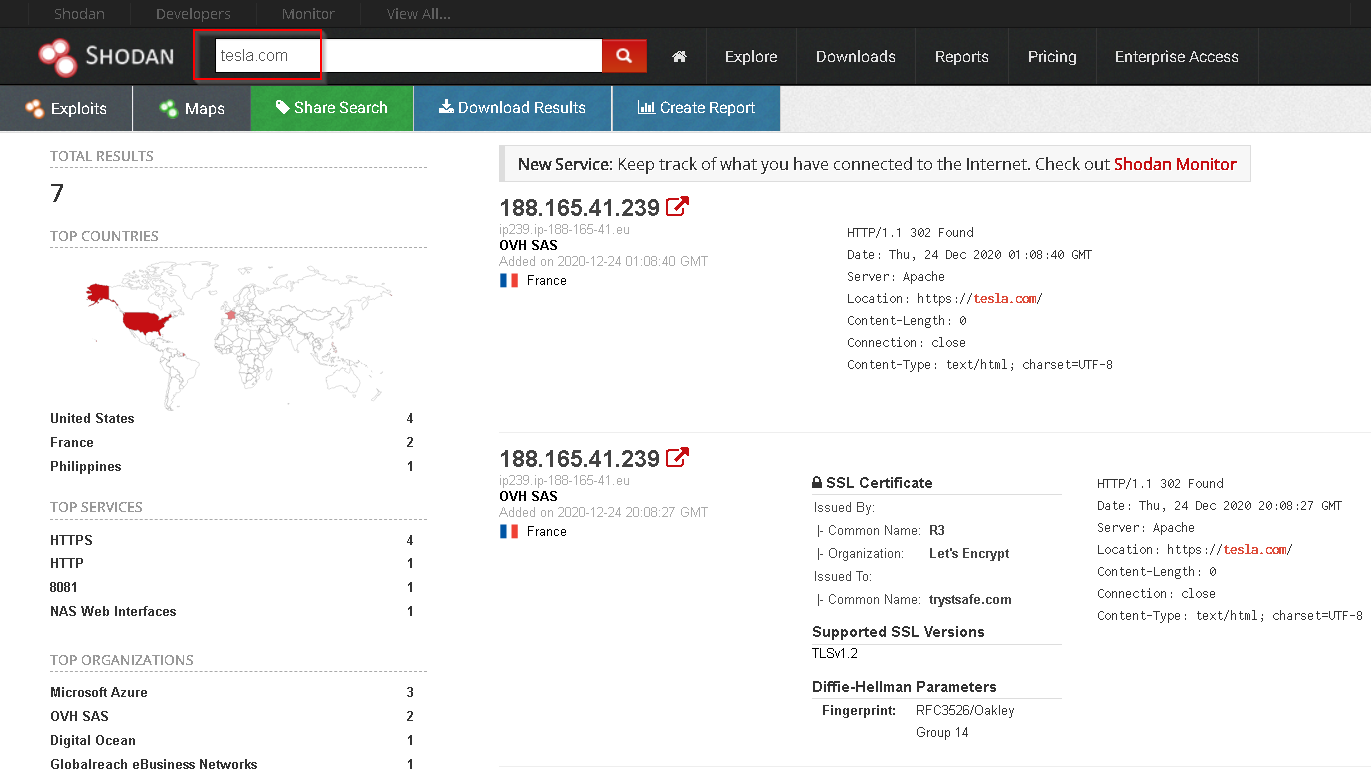
Using Shodan you can query other interesting filters:
- Organizations
- ASNs
- Favicon Hashes
- SSL Certificates
- etc.
3- Zoomeye

ZoomEye is yet another IoT Search engine and can be used to discover:
- Web Server
- IP & Ports
- Headers & Status Codes
- Vulnerabilities
- etc.

As I mentioned earlier about this method:
Another interesting option defenders have, is to restrict the users trying to reach the website using an IP Address, thus the website only loads when the domain name is provided.
We are going to discuss bypassing this limitation using an interesting method.
Let’s think outside the box. What if we scan the IP Range of our target CDN Provider, then do some magic Curl stuff?
To find the IP Range we can do DNS Bruteforcing, therefore, finding the IP Range, and then we can continue using the command below:

As you can see, we are scanning the IP Range of our target. Then we are finding the live ones using Httpx. Then we are using curl to provide a Host header containing our target domain, therefore bypassing all the limitations.

Favicons are sometimes quite useful to find interesting information about certain technologies the website using.
Shodan allows favicon hash lookup via http.favicon.hash. Hash refers to the MurmurHash3 of the favicons file content in base64.
Python3 Script for generating the hash:
import mmh3
import requests
import codecsresponse = requests.get('https://<website>/<favicon path>')
favicon = codecs.encode(response.content, 'base64')
hash = mmh3.hash(favicon)
print(hash)
Check out the following Blogpost for deep dive: Asm0d3us — Favicon hashes
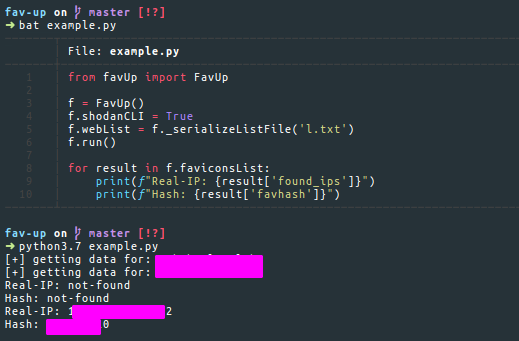
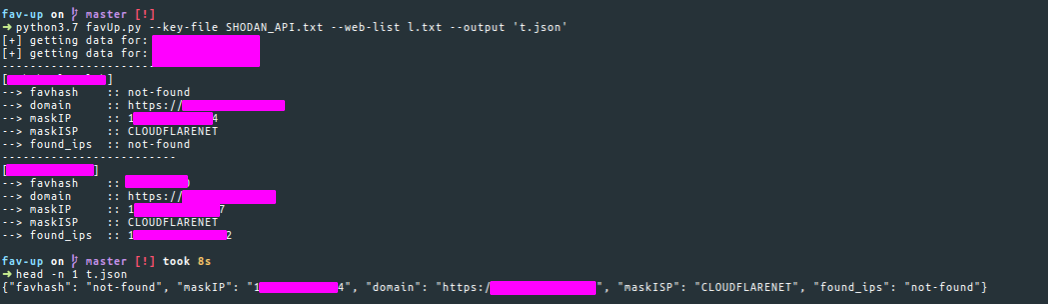
Another useful tool you can use is Fav-Up by pielco11. Using this tool you can look up for real IP starting from the favicon icon and using Shodan.
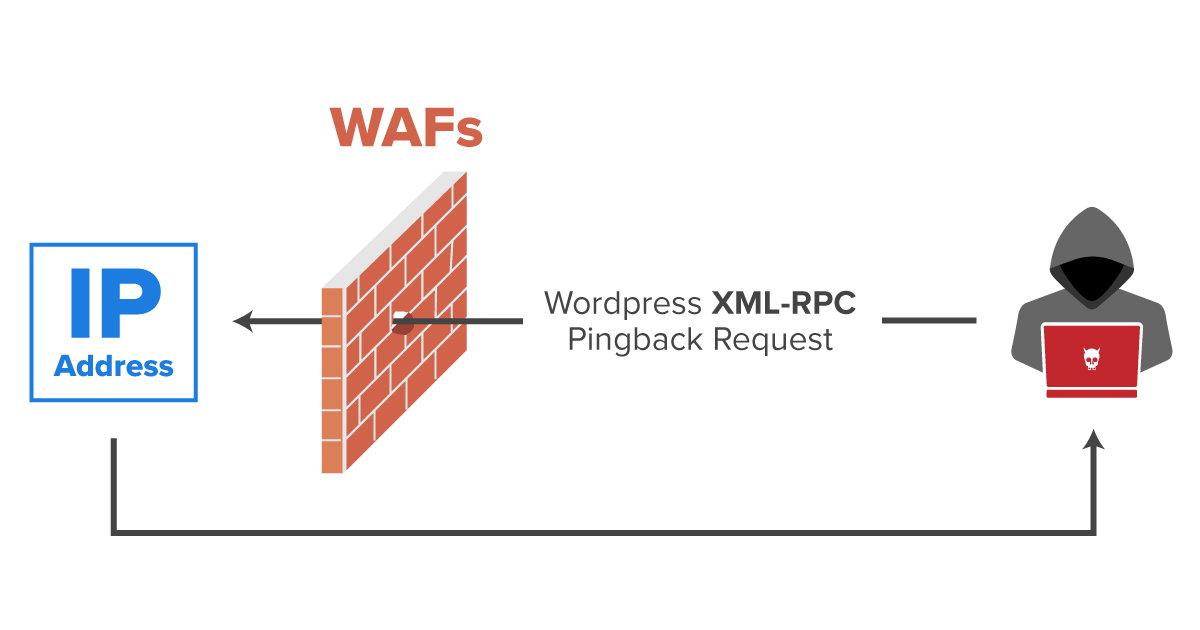
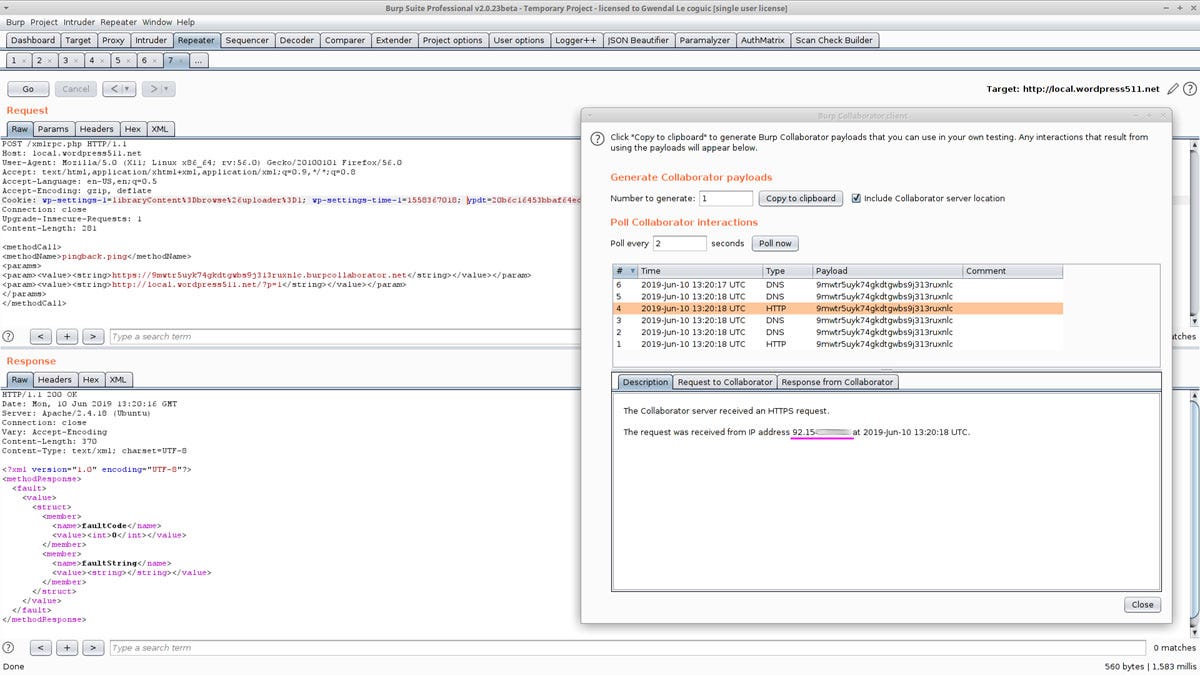
The XML-RPC allows administrators to manage their WordPress website remotely using XML Requests.
A pingback is the response of a ping. A ping is performed when site A links to site B, then site B notifies site A that it is aware of the mention. This is the pingback.
You can easily check if it’s enabled by calling https://www.target.com/xmlrpc.php. You should get the following:XML-RPC server accepts POST requests only.
You can also use XML-RPC Validator.
According to the WordPress XML-RPC Pingback API, the functions take 2 parameters sourceUri and targetUri. Here is how it looks like in Burp Suite:
Cloudflare.com
CDN.net
Sitelock.com
knoldus.com
keycdn.com
Imagekit.io By Rahul Nanwani
GeekFlare.com By Chandan Kumar
Detectify.com By Gwendallecoguic
Secjuice.com By Paul dannewitz
Nixcp.com By Esteban Borges
Pielco11.ovh By pielco11
WAF Evasion Techniques By Soroush Dalili
You guys deserve Love! I tried my best to write an article that could help you understand the full process of How CDN Works, Blue Teamers POV, and Attackers options to try finding the Origin IP of the WebServer.
If you Have any Related Questions or Feedback, feel free to DM me on Twitter.
Written by: HolyBugx
如有侵权请联系:admin#unsafe.sh