作者:蚂蚁安全非攻实验室
公众号:蚂蚁安全实验室
一、背景
上一篇中我们初步分享了 CORBA 通信过程以及各种名词去了解这个协议,并且搭建了一个 demo,接下来会使用这个 demo 进行分析 CORBA 中的一些风险点。
二、思路分析
安全分析方向有两个:
-
在解析 server 返回的 response 时,可能存在 jdk 原生反序列化
-
在 client 端生成 stub 类时,很有可能存在类加载逻辑,甚至是加载远程类
三、反序列化分析
发生在 stub 的使用阶段,在 client 发起 dii request 后,恶意服务器可以精心构造返回数据,进而控制 client 端对 response 的反序列化操作流程,其中存在 JDK 原生反序列化,由此触发 java 反序列化 rce。
1、原理分析
漏洞触发代码如下:
Request request = hello._request("sayHello");
request.invoke();
System.out.println(request.result().value());
request.invoke(); 调用处理流程如下:
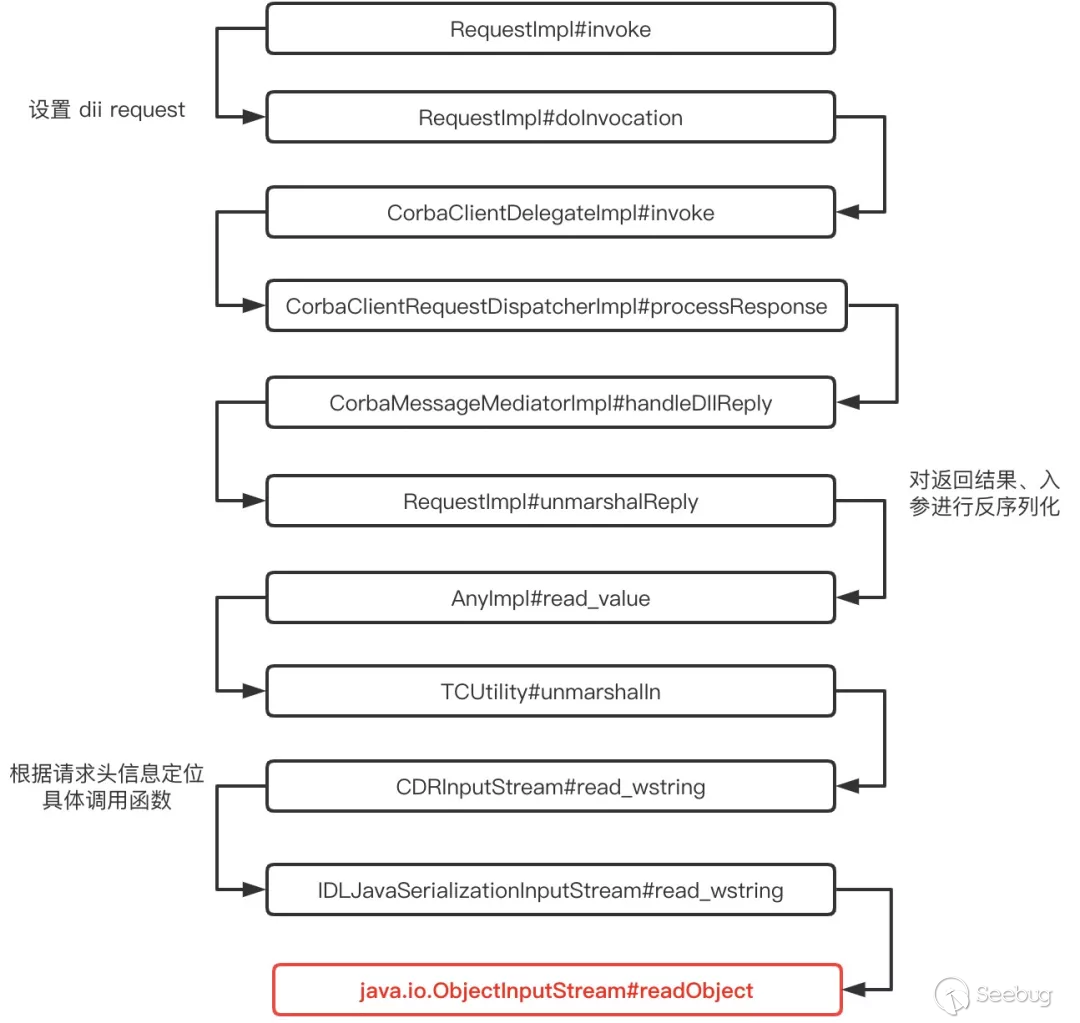
由上图可见,在使用 dii request 发起 rpc 请求时,能够触发 ObjectInputStream#readObject ,引发 JDK 原生反序列化。
其中 IDLJavaSerializationInputStream 不是 CORBA 通信过程中默认的反序列化工具,默认的是 CDRInputStream_x_x (x_x 根据版本决定),那么我们接下来深入分析下如何创建 IDLJavaSerializationInputStream 对象作为反序列工具的,流程如下:
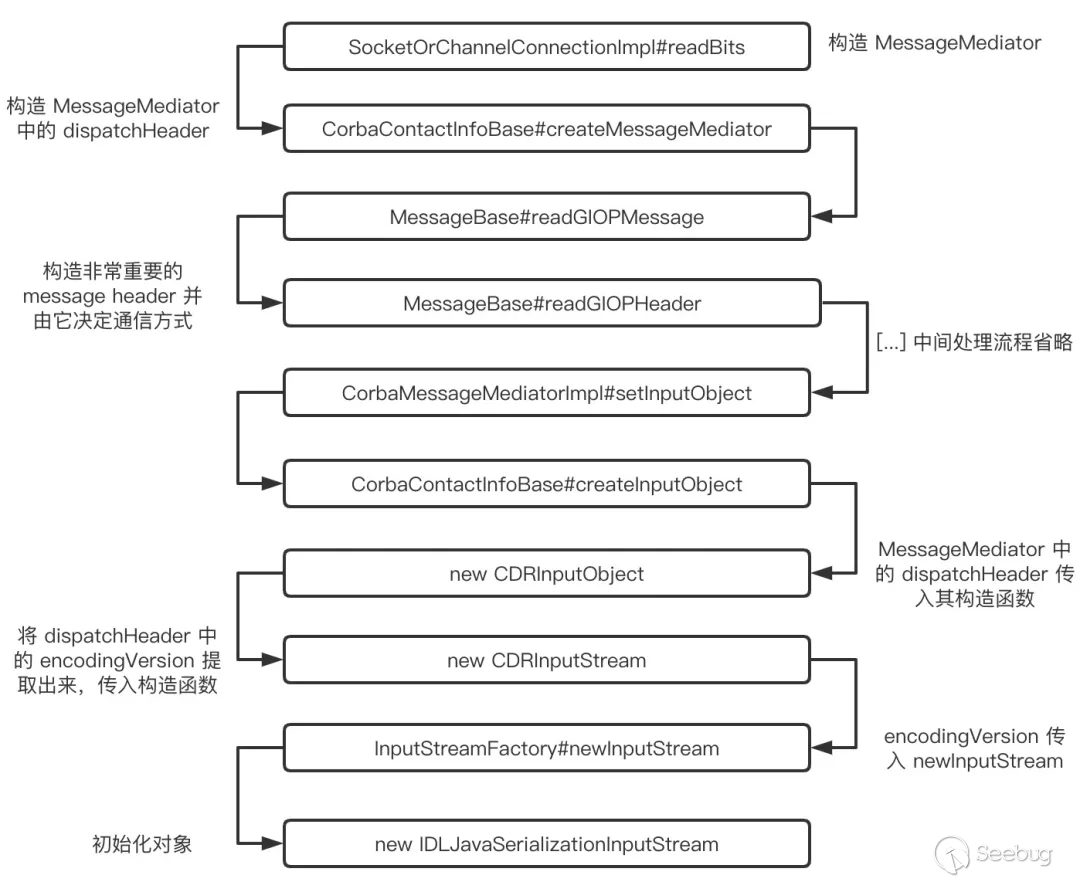
整个 IDLJavaSerializationInputStream 对象生成流程如上所述,最关键的地方只有一处调用:MessageBase#readGIOPHeader
这一处调用主要功能是处理 server 端的返回信息,是根据 server 端的返回数据生成 message header,依次控制后续对数据的拆包、解析操作。其流程中,requestEncodingVersion 变量就是控制通信实现方式,默认是 CDR 的形式,最后会生成 CDRInputStream_x_x 来进行解析操作(例如,调用 impl.read_wstring() 的时候,就会调用 CDRInputStream_X_X)。
此处的流程能观察到,requestEncodingVersion 是可以由 server 端返回流进行控制的,即 server 端可以控制 client 端的拆包解析方式。
经过深入分析,就算 server 端可以控制一部分 client 端的行为,要想触发到 JDK 反序列化代码,还必须要求 client 端含有如下配置,以此开启 JDK 序列化功能支持:
props.put("com.sun.CORBA.encoding.ORBEnableJavaSerialization", "true");
ORB orb = ORB.init(args, props);
2、风险前置条件
两个前置条件:
-
client 端需要开启 JDK 序列化功能支持
-
client 端需要发起 dii 请求,并且需要预先指定:调用返回结果类型 or 调用参数类型
第一个条件,需要在初始化 ORB 时,需要开启 iiop 协议的 jdk 序列化技术支持。
注:实际上就是从 CDR 支持转为 jdk 序列化支持,默认情况下是 CDR 支持 。
第二个条件,需要 client 端在 dii 请求发起前,手动设置调用返回结果类型或是调用参数类型,才会在 response 处理时,触发到 JDK 反序列化。
原因在于如下图(com.sun.corba.se.impl.corba.RequestImpl#unmarshalReply):
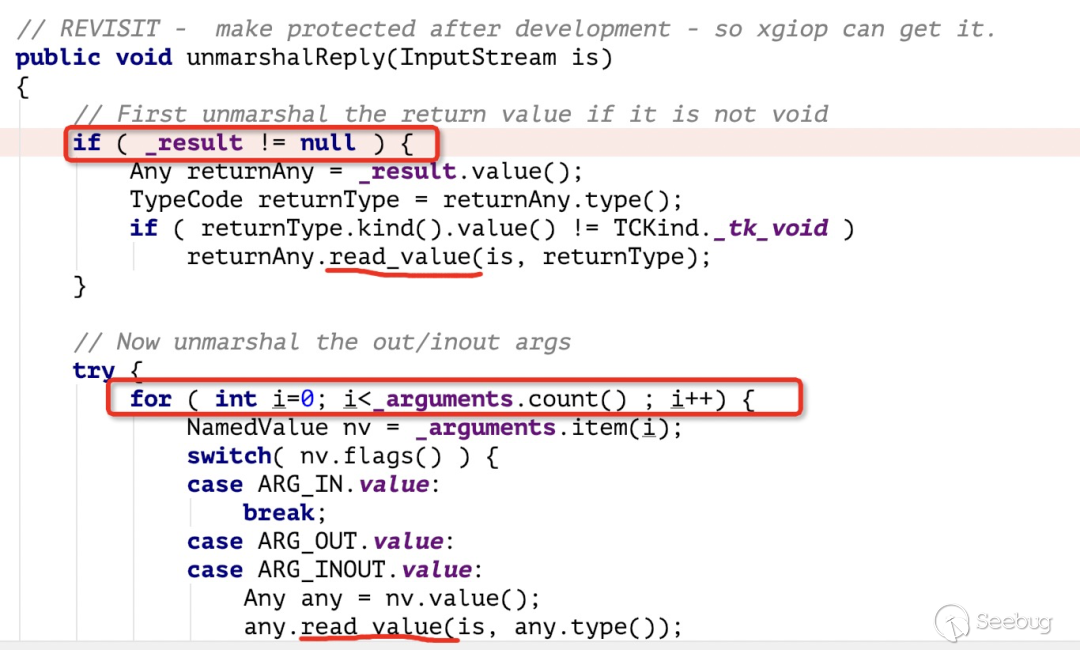
如上图,该流程是在 server 端返回 response 后的 client 端对数据进行解包的流程,默认情况下 _result 、 _arguments 都是为 null 的。需要在初始化创建时候,传入相关配置才能在解析返回结果时触发 read_value 调用,最终能够触发 JDK 反序列化。
附上存在反序列化风险的 client 端代码:
public void run(String[] args) throws Exception {
Properties props = new Properties();
// 生成一个ORB,并初始化,这个和Server端一样
props .put("org.omg.CORBA.ORBInitialPort", "1050");
props.put("org.omg.CORBA.ORBInitialHost", "127.0.0.1");
// allowed java serial
props.put("com.sun.CORBA.encoding.ORBEnableJavaSerialization", "true");
final ORB orb = ORB.init(args, props);
// 获得根命名上下文
org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");
// 用NamingContextExt代替NamingContext.
NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);
// 通过名称获取服务器端的对象引用
String name = "Hello";
Hello hello = HelloHelper.narrow(ncRef.resolve_str(name));
//调用远程对象
Request req = hello._create_request(null, "sayHello", null, new NamedValue() {
@Override
public String name() {
return null;
}
@Override
public Any value() {
Any any = new AnyImpl((com.sun.corba.se.spi.orb.ORB) orb);
any.insert_wstring("1");
return any;
}
@Override
public int flags() {
return 0;
}
});
req.invoke();
}
三、远程类加载分析
发生在 stub 的生成阶段,恶意服务器可以指定 codebase ,client 端会从 codebase 指定地址进行远程类加载。
1、原理分析
我们可以去查看下 _HelloStub#readObject 函数,源码如下:
private void readObject (java.io.ObjectInputStream s) throws java.io.IOException
{
String str = s.readUTF ();
String[] args = null;
java.util.Properties props = null;
org.omg.CORBA.ORB orb = org.omg.CORBA.ORB.init (args, props);
try {
org.omg.CORBA.Object obj = orb.string_to_object (str);
org.omg.CORBA.portable.Delegate delegate = ((org.omg.CORBA.portable.ObjectImpl) obj)._get_delegate ();
_set_delegate (delegate);
} finally {
orb.destroy() ;
}
}
如上,根据规定 readObject 函数会还原一个 _HelloStub 对象 ,那么上述代码块中:
org.omg.CORBA.Object obj = orb.string_to_object (str);
这一句代码就是将协议串转换为 client stub 的操作,协议串可以是 IOR: /corbaname:/ corbaloc: 开头
经过分析, orb.string_to_object (str); 调用整个处理过程如下:
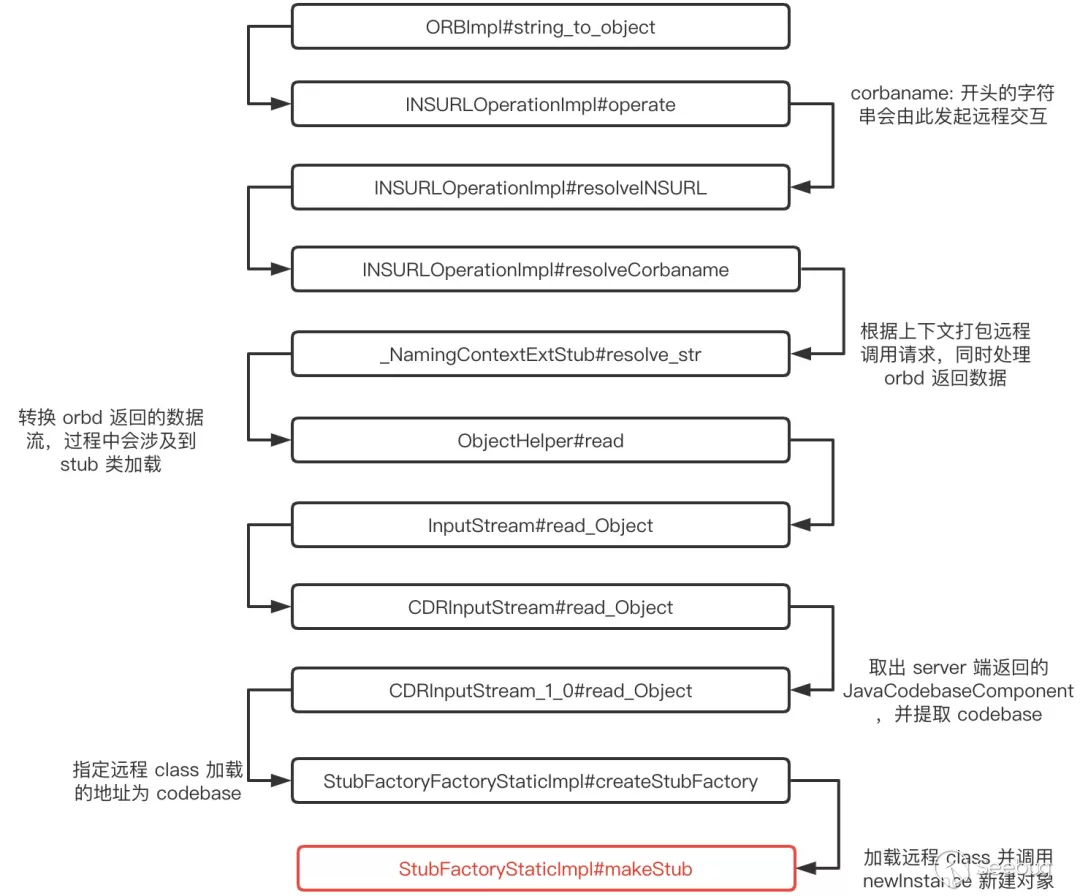
如上图,最主要的是 _NamingContextExtStub#resolve_str 这一步调用,大致功能是由 NamingContext 从 orbd 中获取 stub 类,其中涉及到了类加载的过程。
从 _NamingContextExtStub#resolve_str 往后的调用过程,和正常的 client 端从 NamingServer 获取对象引用的操作是一样的,如下:
// 通过名称获取服务器端的对象引用 String name = "Hello"; Hello hello = HelloHelper.narrow(ncRef.resolve_str(name)); // 调用 resolve_str
由此可见,无论是 stub 类的 readObject 函数,还是正常的 client rpc 调用,都可能会触发到远程类加载流程。
2、风险前置条件
需要 client 端允许 RMI 上下文环境访问远程 codebase。
StubFactoryFactoryStaticImpl#createStubFactory 中的类加载使用的是 RMIClassLoader ,虽然 useCodebaseOnly 为 false ,但是在反序列化 stub 上下文中,没有允许访问 codebase,会导致 SecurityManager 权限校验不通过

3、分析小结
· Message:
每一次 request 和 reponse 的运载物都是它。在 corba 通信过程中,CorbaMessageMediatorImpl 就是它们的代表,其中包含 requestHeader, replyHeader, messageHeader,这三者分别管控 request 包的序列化/反序列化,replay(response)包的序列化/反序列化,message的序列化/反序列化,主要作用是控制通信数据格式。
· request & response:
request 和 response 都可能是 CDRInputObject 或者 CDROutputObject,站在分析者的角度,主要关注 CDRInputObject。在根据 requestHeader, replyHeader, messageHeader 反序列化时,都是使用 CDRInputObject 作为操作对象对数据进行处理的
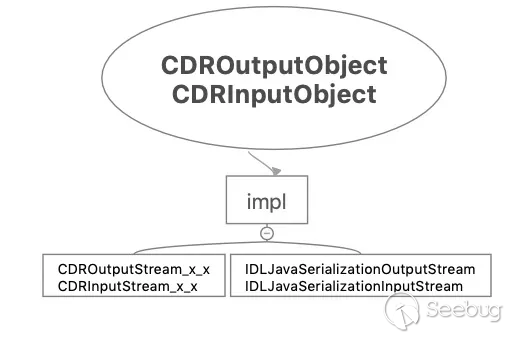
数据底层处理类:
-
CDROutputObject
-
CDRInputObject
实际在序列化/反序列化数据时,是由它们的 impl 属性实现的,可以分为 IDLJavaSerializationX 和 CDRX 系列,如下图关系:
四、思路分析
server 端是先绑定 rpc 实现( 注册 servant ),然后会和 client 端进行交互。
经过分析没有发现远程类加载的情况,但是存在和 client 端的反序列化风险类似的问题,因为本质上都会有底层数据经过 CorbaMessageMediator 的处理过程,不过触发 JDK 反序列化的入口点不一样。
五、反序列化分析
该风险发生在 client 端发起 rpc 请求时产生,在 server 端调用实际 rpc 服务函数实现前触发。
1、原理分析
过程在分派请求时发生,我们重写 hello.idl 如下:
module com { interface Hello{ string sayHello (in wstring name); }; };
如上代码,定义 sayHello 入参类型为 wstring ,接着查看 HelloPOA#_invoke ,源码如下
public org.omg.CORBA.portable.OutputStream _invoke (String $method,
org.omg.CORBA.portable.InputStream in,
org.omg.CORBA.portable.ResponseHandler $rh)
{
org.omg.CORBA.portable.OutputStream out = null;
java.lang.Integer __method = (java.lang.Integer)_methods.get ($method);
if (__method == null)
throw new org.omg.CORBA.BAD_OPERATION (0, org.omg.CORBA.CompletionStatus.COMPLETED_MAYBE);
switch (__method.intValue ())
{
case 0: // com/Hello/sayHello
{
String name = in.read_wstring ();
String $result = null;
$result = this.sayHello (name);
out = $rh.createReply();
out.write_string ($result);
break;
}
default:
throw new org.omg.CORBA.BAD_OPERATION (0, org.omg.CORBA.CompletionStatus.COMPLETED_MAYBE);
}
return out;
} // _invoke
如上,在调用真正的 sayHello 函数服务之前,_invoke 函数先还原了入参 name ,调用的是 CDRInputStream#read_wstring ,后续的处理流程于 Client 反序列化分析中流程相同。
2、风险前置条件
server 端要存在入参,且参数类型可以触发到 JDK 反序列化流程,例如 any 、wstring 等
3、注意
以上所述都是通过 Oracle JDK 搭建的最简单 Corba 通信环境分析出来的,在其他大型中间件/容器等对 Corba 的扩展实现中可能会存在更多的 JDK 反序列化风险点,其调用链路可能也有所不同,但是漏洞原理大多是一致的。
例如 read_any 函数调用也会触发到反序列化,这是今年 weblogic 和 websphere 被刷的 IIOP 反序列化漏洞入口。
ORBD
全称:The Object Request Broker Daemon
orbd 是用于产生 NameService 的服务,在 server 端进行 corba 服务实现注册的之前,首先需要运行 orbd。
简介见:https://docs.oracle.com/javase/1.5.0/docs/guide/idl/orbd.html
六、前置知识
orbd 其实在 jdk 中有所实现,见 com.sun.corba.se.impl.activation.ORBD 。
注:需要调试的话,在 idea Configuration 中配置好 Program arguments :
-port 1050 -ORBInitialPort 1049 -ORBInitialHost 127.0.0.1
orbd 主要是为 server 端提供长期存储服务/存储上下文/计数等功能。client 端也是首先通过它取得 server 端的信息,在最后的 rpc 调用时,才会直接和 server 端通信,在查找 name service / 查找 corba servce 时,都是与 orbd 通信的。
orbd 中进行数据的采集和整理也是使用的 CorbaMessageMediatorImpl#handleInput,通过 CorbaServerReqeustDispatcherImpl#dispath 进行请求分派。
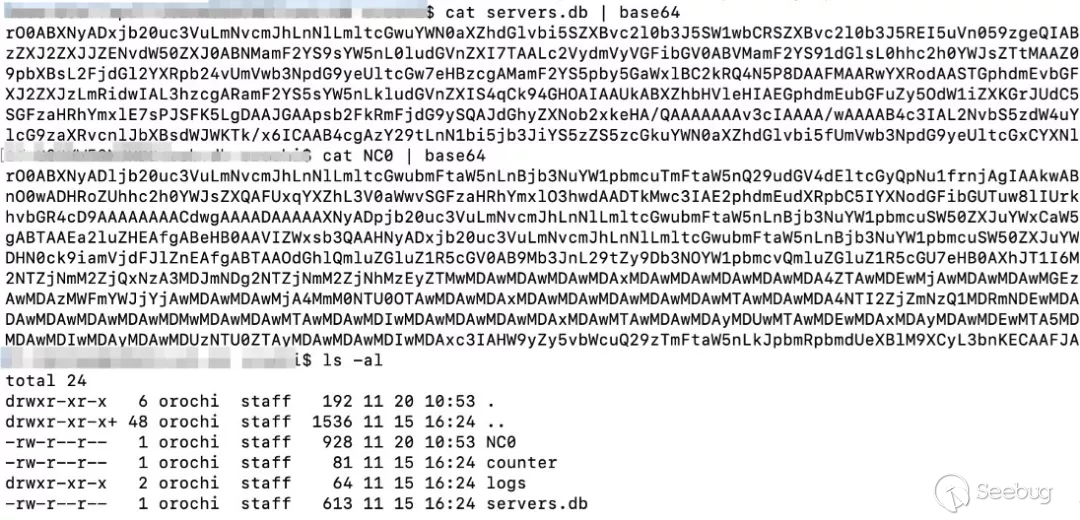
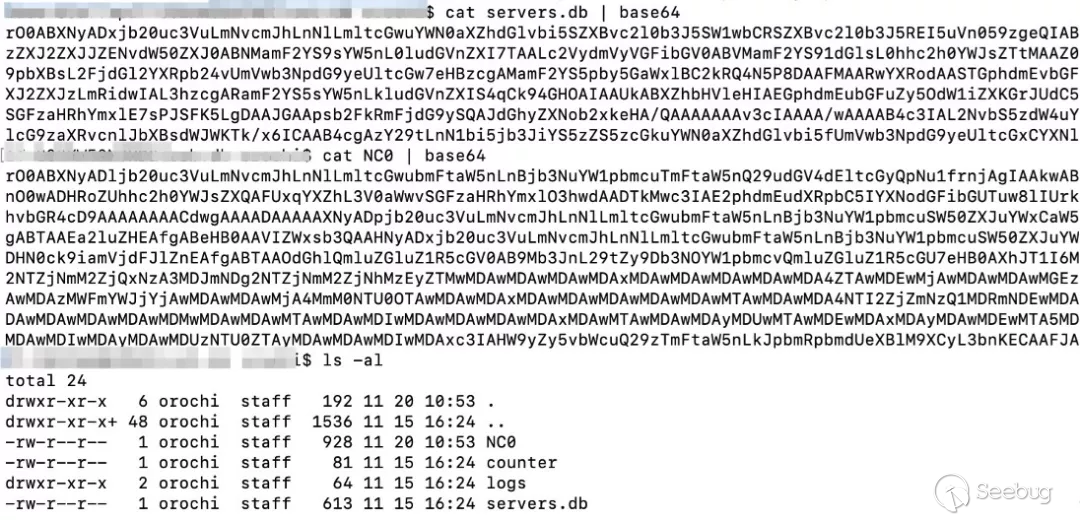
在直接使用 orbd 时,会在工作目录下创建 orb.db 目录,该目录下存储了 server / 上下文(NamingContextImpl) 等信息,目的是为了保持 corba 服务相关对象的持续保存,如下图:
七、反序列化分析
在 corba client 角色发起调用请求时会出现反序列化的操作,会将 orb.db 文件夹下的 NC0 文件内容进行反序列化,路径是 client 角色端可控的。
注:server 端 / client 端都会充当 corba client 角色,只要是调用了 org.omg.CORBA.portable.ObjectImpl#_request 接口都可视作 client 角色。
1、原理分析
orbd 可以将 NamingContextImpl / server 等信息持续化保存(序列化过程),那么一定会有机会将它们从本地磁盘导入到程序中(反序列化过程)。
这里我们直接查看反序列化过程,如下
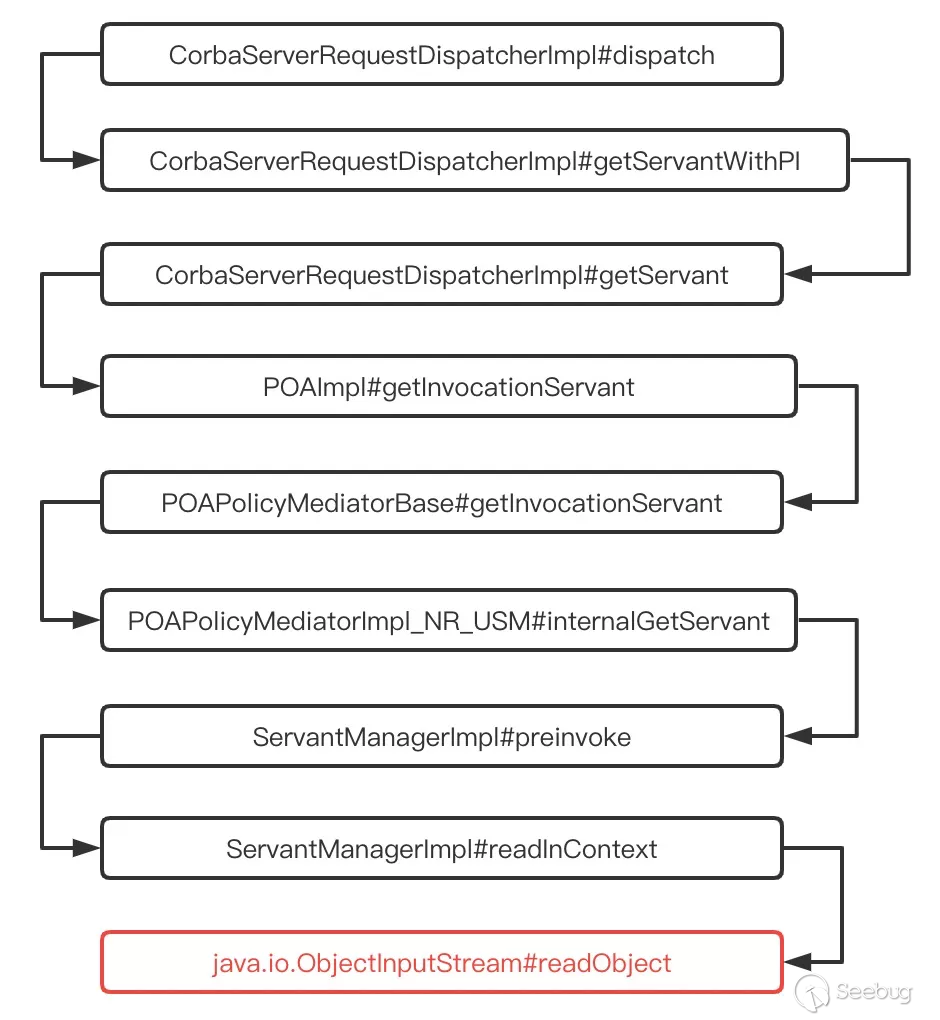
通过前文对 Server 的派遣请求流程的分析,我们能够观察到 ORBD 在接收到请求后分派的处理方式大致相同,不过这里多一个预处理流程,在预处理流程中就存在 JDK 反序列化的操作。
其中 ServantManagerImpl#readInContext 代码如下
public NamingContextImpl readInContext(String objKey)
{
NamingContextImpl context = (NamingContextImpl) contexts.get(objKey);
if( context != null )
{
// Returning Context from Cache
return context;
}
File contextFile = new File(logDir, objKey);
if (contextFile.exists()) {
try {
FileInputStream fis = new FileInputStream(contextFile);
ObjectInputStream ois = new ObjectInputStream(fis);
context = (NamingContextImpl) ois.readObject();
context.setORB( orb );
context.setServantManagerImpl( this );
context.setRootNameService( theNameService );
ois.close();
} catch (Exception ex) {
}
}
if (context != null)
{
contexts.put(objKey, context);
}
return context;
}
如上代码,该处理过程是将 objKey 当作 logDir 目录的子文件,然后提取文件内容,直接调用 readObject 函数,触发 jdk 原生反序列化。
那么 objKey 是从哪儿获取的呢?
在 client 角色方得到 _NamingContextExtStub 对象后,就可以直接调用 Name service 提供的服务,例如 rebind、unbind、bind 等等,其中 _NamingContextExtStub 含有 orbd 的相关信息,将其中 IOR 提取出来后,可以看见一些 corba server 制定的数据处理规则等,其中有一个 ObjectId 的对象,它里面的 id 属性就是 objKey 的 byte[] 格式,如下图:
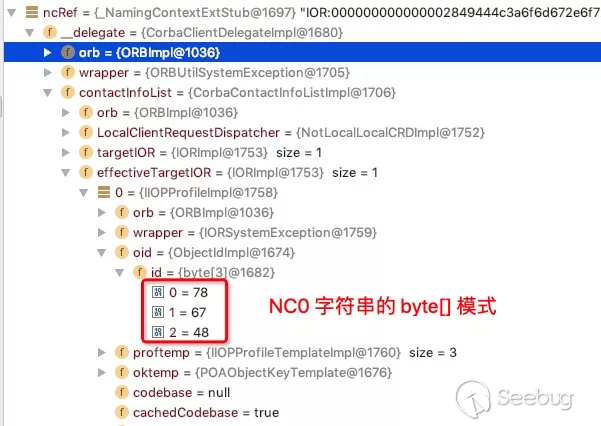
这里产生的安全风险是,orbd 居然将 client 角色传递过来的 ObjectId 进行还原,然后在处理过程中转换为 ojbKey ,简而言之,client 角色可以自行修改 ObjectId 中的任何信息,并且 orbd 不仅会还原它,还会将其制作为 ojbKey ,接着进行 NamingContextImpl 的预加载。
恶意 Client 可以通过控制 ObjectId 间接控制 ORBD 中的 NC0 文件路径,在 ORBD 服务器中如果存在含有恶意序列化数据的文件,那么就可以通过 ObjectId 可以将反序列化文件的路径指向恶意文件,最终会导致 ORBD 服务器触发 JDK 反序列化漏洞。
2、风险前置条件
需要 ORBD 服务器中存在恶意 Java 序列化数据的文件。
不过,orbd 在标准的 corba 通信中,是直接使用命令行运行的,并不会带上其他依赖,也不需要。即使存在恶意文件,但是最终无法使用目前已知的反序列化 gadget 进行攻击,至少都得需要 jdk 原生反序列化的 gadget 才会导致任意代码执行。
八、分析小结
client & server:
绝对的 server 端是 orbd,它永远只提供数据转发、name service 服务这些功能,绝对的 client 是 corba client ,它对 orbd 、corba server 发请求,而 corba server 是一会儿 client 角色,一会儿 server 角色。在 corba 通信过程中,client 角色总会发起 invoke 请求(发包 request),然后收到 reply(接包 response),server 端自然总是收到 request ,然后返回 response。
ORBD 这一角色渐渐被 Corba Server 所整合,在某些容器中是不用特意去配置 ORBD 的,直接使用 JNDI 的方式注册、发布 service 即可。但是 ORBD 含有的功能不会被抹去,在其他 Corba 实现/扩展中肯定还是会存在功能模块,负责处理 ORBD 原本的工作。
RMI-IIOP
1、简介
曾经 JAVA 中分布式解决方案只有 RMI 和 CORBA,两者并不能共存,而 CORBA 又有跨语言的有点,所以推出了 RMI-IIOP 解决方案,此后 RMI 服务器对象可以使用 IIOP 协议,并与任何语言编写的 CORBA 客户端对象进行通信。(请参阅在 IIOP 上运行 RMI 程序时的一些限制,扫描下方二维码查看)

RMI-IIOP 结合了 RMI 的易用性与 CORBA 的跨语言互操作性,将 Java 语言进一步推向了目前服务器端企业开发的主流语言的领先地位。
2、前置知识
IIOP (Internet Inter-ORB Protocol):IIOP 是 CORBA 的通信协议,用于 CORBA 对象RPC请求之间的交流。
IDL :IDL 全称接口定义语言,是用来描述软件组件接口的一种规范语言。用户可以定义模块、接口、属性、方法、输入输出参数。Java 中提供了 idlj 命令用来编译 IDL 描述文件,用以生成 Java 语言的 客户端 java 文件等。
corba & RMI 差异
| corba | RMI | |
|---|---|---|
| 定义接口 | idl 代码生成接口 | interface 定义 |
| 实现类 | 继承 idlj 生成的 _NameImplBase | 继承 UnicastRemoteObject |
| 使用语言 | 独立于语言的,兼容性强 | Java to Java |
| 查找对象 | 使用 CosNaming(nameserver) | 使用 JNDI 定位远程对象 |
| 序列化/反序列化 | 默认采用 CDR 序列化数据 | 使用 JDK 原生反序列化 |
rmi 和 corba 都差不多,都是桩和框架的设计。它们在 java 中都可以相互调用,这就归功于 rmi-iiop。
实现简述
笼统地来说,rmi-iiop 是把 corba 整个实现给包装了一次,在 corba 实现中,只能传递简单的数据,没法像 rmi 这样能够直接利用序列化/反序列化传递对象(这里可能有误,但暂时不知道如何通过 corba 直接传递对象),在 r mi-iiop 实现中,把 corba 的通信模式 GIOP-TCP 包装了一层,间接的实现了对象的传递,如下图:
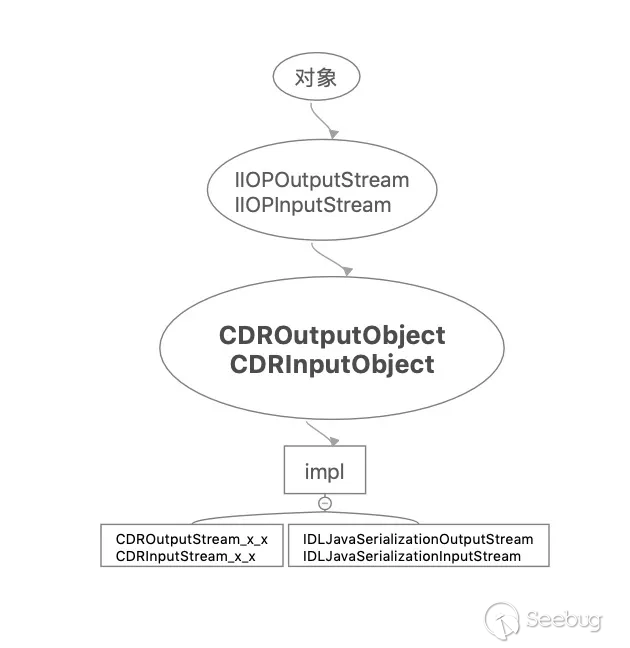
比起 corba 的底层数据处理,多出来了 IIOP 这么一层,它的工作是将对象拆分,对象数据就是由对象中的属性构成,直接传输对象的属性,就能够间接的传递对象了。
调用流程差异
github 上一个 rmi-iiop 例子:https://github.com/uro/cobra-rmi-iiop
client 端:

这么三句代码,就能拿到 stub,都是 jndi 的功劳。其中 lookup 函数可以传入 corbaloc 、corbaname 等协议串,例如:ctx.lookup("corbaname::localhost:1050#PhoneDirectoryService")。
server 端:

同样也是三句代码就能绑定 corba 服务实现,这也是 jndi 的功劳。
注:以上都需要使用 作者给出的 jndi.properties ,也可以直接指定 jvm 参数(因为要用到 ORBD)。
demo 补充
如果想测试一下 rmi-iiop 关于 对象 传递的demo,可以在上述例子中加入如下类:
package zad1;
public class SerClass implements java.io.Serializable {
// members
private int x;
private String myString;
// constructor
public SerClass(int x, String myString) throws java.rmi.RemoteException {
this.x=x;
this.myString=myString;
}
// some accessor methods
public int getX() { return x;}
public void setX(int x) { this.x=x; }
public String getString() { return myString; }
public void setString(String str) { myString=str; }
}
PhoneBookClient 中获取 stub 后,添加一个调用:
SerClass sc = new SerClass(5, "Client string! ");
// pass the class to be altered on the server
// of course behind the scenes this class is being
// serialized over IIOP
sc = pd.alterClass(sc);
// now let's see the result
System.out.println("Serialization results :\n"+
"Integer was 5 now is "+sc.getX()+"\n"+
"String was \"Client String! \"" +
"now is \""+sc.getString()+"\"");
PhoneDirectoryInterface 增加接口函数
package zad1; import java.rmi.Remote; import java.rmi.RemoteException; public interface PhoneDirectoryInterface extends Remote { String getPhoneNumber(String name) throws RemoteException; boolean addPhoneNumber(String name, String num) throws RemoteException; boolean replacePhoneNumber(String name, String num) throws RemoteException; public SerClass alterClass(SerClass classObject) throws java.rmi.RemoteException; }
PhoneDirectory 增加函数实现:
@Override
public SerClass alterClass(SerClass classObject) throws RemoteException {
// change the values of SerClass and return it.
// add 5 to X
classObject.setX( classObject.getX() + 5 );
// alter the string
classObject.setString( classObject.getString() + " : I've altered you" );
return classObject;
}
九、反序列化分析
其实从设计上来看,安全分析思路已经很明显了,利用 IIOP 的序列化/反序列化能力,构造恶意 jdk serial 数据让目标对其反序列化。
这里的承载对象就要好好考量一下了(因为 IIOP 在反序列化数据处理时,都是根据调用者(servant) 或者 stub 指定的预期类型(expectType)来确定反序列化的处理流程),风险最大的情况的就是使用 java.lang.Object 作为远程调用函数参数、远程调用函数返回值。
IIOP 有关目标对象创建、反序列化处理等都发生在 IIOPInputStream 这个类中,反序列化入口在 com.sun.corba.se.impl.io.IIOPInputStream#simpleReadObject 。
其处理流程如下:
-
先根据 expectType 新建一个对象,并判断该类是否含有 readObject 函数(实现了 Serialization 接口),如果有,则调用该函数
-
如果没有该函数,那么通过反射,取出该对象的所有 field ,然后从 IIOPInputStream 读取值,塞入各个 field 中。其中,如果 field 不是基本类型,那么根据其类型创建对象,重复步骤1
上述过程发生在如下情况中:
-
client 端发起请求后,反序列化 server 端的返回结果
-
server 端在接受到 client 端到请求后,反序列化请求参数
风险种类和场景根据角色的不同而不同。
注意,IIOPInputStream 主要是将 CDRInputObject 包装,然后在读取各种数据时,实际上还是利用的 CDRInputStream_X_X 或 IDLJavaSerializationInputStream
但是 IIOPInputStream 本身也存在风险点,那就是会首先判断反序列化目标是否存在 readObject 函数,然后对其进行调用,由此会触发 JDK 反序列化风险。
RMI-IIOP 具体存在的安全风险,形如最原始的 rmi 攻击 rmiserver 那般,server 端存在入参类型为 java.lang.Object 或其属性中含有 java.lang.Object 类型等情况 ,此时恶意 client 端可以在 rpc 调用的时候,传入恶意类,然后使用 java.lang.Object 来承载该类的服务端进行反序列化。
rmi 攻击分析见:https://xz.aliyun.com/t/6660#toc-6
安全建议
建议在实际业务场景中尽量减少涉及到序列化功能的接口/服务的公开,如非必须可以选择将其关闭,例如 weblogic 可选择关闭 IIOP / T3 协议支持。
现阶段,JAVA ODD类型反序列化安全没有永绝后患的解决方案。如果你的设计落入了ODD模式,那么注定是一个安全梦魇,正如近几年整个安全业界面临fastjson不停爆出0day时张皇失措的情景。现在fastjson也提供了安全模式,关闭开放动态类型反序列化模式,这个是解决此类安全隐患的正途。
在因为种种原因无法规避ODD时,可以选择通过 JEP290 防护机制设置全局黑白名单,但是需要将 JDK 版本升级到 JDK9 或是 8u121、7u131 和 6u141。在实际场景中推荐结合业务而配置白名单,如果实在不行可以退而求其次配置恶意类黑名单。但是注意黑名单容易被绕过,这个也是fastjson社区之前常年鸡飞狗跳的原因。
另外,由于这两年业界在RASP/安全切面领域的实践,对于ODD漏洞类型的紧急止血可以从传统WAF的痛苦中解脱出来。比如可以用RASP/安全切面机制禁止危险反序列化函数调用高危操作,在面对未知0day漏洞时能够有效缓解漏洞造成的影响。
注:JEP290 默认只会开启 RMI 安全防护,如果要配置全局反序列化黑白名单,需要在配置文件 conf/security/java.properties 中的 jdk.serialFilter 条目设置反序列化黑白名单列表,配置参考(扫描下方二维码查看)。

作者感想
本着以安全技术分析、思路分享的态度发文,文章没有经过太多雕琢,如有错误欢迎大佬们指正。
2019年9月分析完了 JDK CORBA ,但是没有及时向上分析JAVA框架/应用层面错失了很多 0day。
总的来说,本系列文章都是围绕反序列化/类加载/类初始化等角度去进行安全分析,没有从 CORBA 协议本身的一些设计角度去分析,CORBA 中很重要的功能就是分布式对象管理和调遣,并且 JAVA 语言也是面向对象的典范,所以本系列文章更多的关注在“对象”这个点上,如果读者感兴趣可以从协议设计安全角度深入分析。
参考文献
什么是 RMI、IIOP和RMI-IIOP:https://www.ibm.com/support/knowledgecenter/zh/SSYKE2_7.0.0/com.ibm.java.lnx.70.doc/rmi-iiop/overview.html
jndi 对 corba 的支持:https://docs.oracle.com/javase/8/docs/technotes/guides/jndi/jndi-cos.html
java 中 rmi 和 corba 的区别:https://blog.csdn.net/njchenyi/article/details/468402
RMI、CORBA、IIOP简单实例:https://blog.csdn.net/javamxj/article/details/282664
关于作者
蚂蚁安全非攻实验室:隶属于蚂蚁安全九大实验室之一。蚂蚁安全非攻实验室致力于JAVA安全技术研究,覆盖蚂蚁自研框架和中间件、经济体开源产品以及行业中广泛使用的第三方开源产品,通过结合程序自动化分析技术和AI技术,深度挖掘相关应用的安全风险,构建可信的安全架构解决方案。

 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1446/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1446/
如有侵权请联系:admin#unsafe.sh