-

-
-
[原创]Linux e1000网卡收包分析
- 2019-7-8 14:12 609
-
内核编译
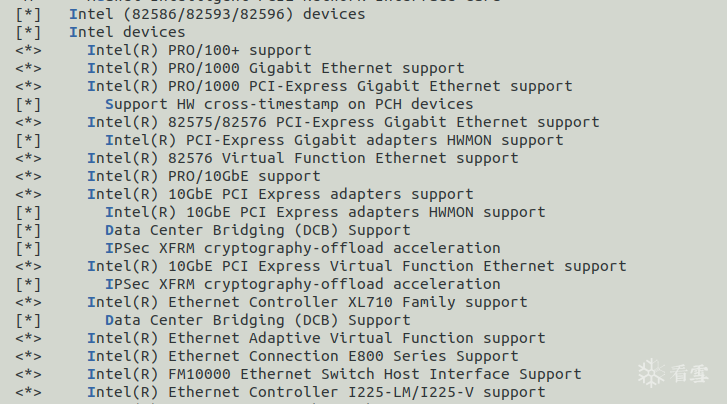
内核版本是5.2.0-rc4,调试是在QEMU下进行的,默认的网卡是e1000,为了方便调试将e1000的驱动编译进内核里

图1
分析
在网卡分析前,图2和图3是抓取的收包和发包过程

图2

图3
其中e1000_clean_rx_irq()和e1000_xmit_frame()分别是网卡的收包和发包的核心函数。
其中e1000_clean_rx_irq()定义如下

图4
参数rx_ring中保存的从网卡中接收到的数据包,work_to_do这个变量是查询网卡中已经是否有接受好的数据的次数。work_done是表示在这些次数中,接收好的有几个。这样的设计是为了增加网卡的数据吞吐量并减少中断次数提升性能。网卡采用中断加轮询的方式。
rx_ring 的结构体定义如下

图5
其中desc,dma和buffer_info这三个变量是从网卡接收到内核的关键变量。首先是desc和dma的关系如下面代码所示。

图6
desc是dma的虚拟地址,并把这段连续地址分成若干个struct e1000_rx_desc结构体形成一个数组。结构如下

图7
buffer_addr是指向接收数据的缓冲区。最后将dma写入到网卡的寄存器里面

图8
struct e1000_rx_desc中buffer_adder指向struct e1000_rx_ring中的buffer_info数组里面的dma,关系如下

图9
struct e1000_rx_ring中的buffer_info数组,调试知道是256个,分配缓冲区大小是网卡mtu的大小。

图10
通过以上分析e1000_clean_rx_irq()的代码就很好理解了,通过查询每个buffer_info对应的desc来知道网卡是否收好。如果接收好就将数据拷贝到skb中进行向上传递。网卡发包的过程类似,不在赘述。
对应skb的数据结构是struct sk_buff ,可以参考[1]去理解一下。
参考
[公告]LV6级以上的看雪会员可以免费获得《2019安全开发者峰会》门票一张!!
最后于 2019-7-8 14:14 被linuxfuns编辑 ,原因:
如有侵权请联系:admin#unsafe.sh