子模式
在使用正则表达式的时候,我们经常会使用()把某个部分括起来,称为一个子模式。
子模式有Capturing和Non-Capturing两种情况。
Capturing指获取匹配or捕获匹配 ,是指系统会在幕后将所有的子模式匹配结果保存起来,供我们查找或者替换。如后向引用的使用;
Non-Capturing指非获取匹配or非捕获匹配 ,这时系统并不会保存子模式的匹配结果,子模式的匹配更多的只是作为一种限制条件使用,如正向预查,反向预查,正向肯定预查,正向否定预查等。
后向引用(也叫反向引用)
使用"\数字"代表前面某个子模式的匹配内容。
我们使用正则表达式,在很多场景下的作用是为了查找和替换。在查找时,使用后向引用来代表一个子模式,语法是"\数字",而在替换中,语法是"$数字"。数字 表示这里引用的是前面的第几个子模式。可参考命名捕获分组
预查、正向、反向、肯定、否定
预查
包括正向预查,反向预查,细分了还各自有肯定预查和否定预查。
特点:
所有的预查都是非获取匹配,不消耗字符。也就是说,在一个匹配发生后,在匹配字符之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
正向
匹配后面跟着的东西是否等于/不等于
反向
匹配前面跟着的东西是否等于/不等于
肯定
匹配后面/前面跟着的东西是否等于
否定
匹配后面/前面跟着的东西是否不等于
正向肯定预查
(?=pattern) 预测后面的字符串必须匹配上pattern
先给一个简单的例子:
匹配英文句子中带ing的单词,但是不要ing。
varcon="coming soon,going gogogo" varreg = /\b[\w]+(?=ing\b)/g;//匹配带ing的单词,但是不要ing。注意:如果ing后不加\b,类似于goingabc也会匹配。console.log(con.match(reg));
结果匹配到["com", "go"]。先匹配单词边界\b,然后+匹配前面多次或者一次,然后到这个正向预查,(?=ing)表示先向后探测,看看有没有ing。
如果有,则把前面的匹配出来;如果没有,则光标往后移一位,继续探测。
这个过程就是正向预查:预先判断为某个值。然后匹配到的东西不包含这个元素,这里也就是ing。
官方原话是该匹配不需要获取供以后使用,是一个非捕获匹配。
正向否定预查
(?!pattern) 预测后面的字符串必须匹配不上pattern
反向肯定预查
(?<=pattern) 预测前面的字符串必须匹配上pattern
反向否定预查
(?<!pattern) 预测前面的字符串必须匹配不上pattern
反向预查,pattern长度必须是固定的,也就是说pattern中不能出现诸如*.等这类字符使得pattern匹配的长度不固定;但是正向没有这个要求。
示例
考虑这样一个应用情景:对于一个大的数值,比如35689412,西方国家习惯三位一个量级,中间以逗号隔开,方便一眼看出大小,也即是35,689,412。那么现在有一堆数,请用正则表达式完成替换,替换成诸如35,689,412的格式。
题目分析:也就是从右往左数,每隔三个数,如果前面还有数的话就在前面加个逗号。也就是找到这些特定的位置,在该位置处加上“,”。
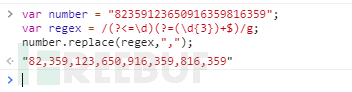
varnumber = "82359123650916359816359"; varregex = /(?<=\d)(?=(\d{3})+$)/g; number.replace(regex,",");
例子中使用的正则表达式:/(?<=\d)(?=(\d{3})+$)/g;
(\d{3})+ 作用:匹配3个数字 6个数字 或9个数字……
(\d{3})+$ 作用:匹配3个数字结尾, 6个数字结尾 或9个数字结尾……
(?=(\d{3})+$) 作用:匹配后面跟着 “3个数字结尾, 6个数字结尾 或9个数字结尾…… ” 的位置
(?<=\d) 作用:匹配前面跟着一个数字的位置,这就确保不会把“123,456” 转成“,123,456”
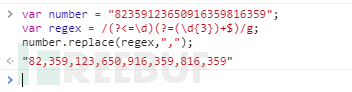
该正则表达式全由预查结构组成,没有匹配任何字符(如果用match()函数看的话,结果是多个空字符串,看下图),但是却匹配了一堆位置。再用:replace(",”),即可完成问题要求。$的作用可以优先匹配行末
捕获&非捕获
需要注意的点:与消费不消费字符 不能混为一谈
捕获:
可以通过一个正则表达式的模式,或者部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。
举例:
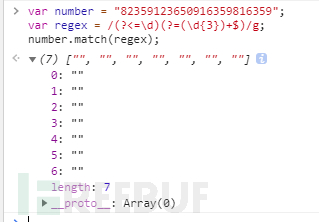
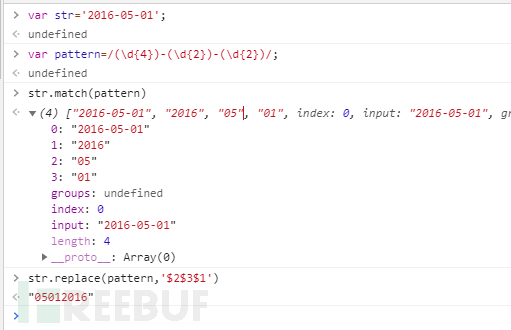
1varstr='2016-05-01'; 2varpattern=/(\d{4})-(\d{2})-(\d{2})/; 3str.match(pattern) 4str.replace(pattern,'$2$3$1')
非捕获:
如果我们不想捕获我们的文本,可以使用非捕获元字符 '?:'、'?=' 或 '?!' ,这种分组正则表达式引擎不会捕获它所匹配的内容即不会为非捕获型分组分配组号,也就是不放在我们的内存当中,这样也能提高我们的性能。
贪婪与懒惰
贪婪匹配
当正则表达式中包含能接受重复的量词(指定数量的代码,例如*,{5,12}等)时,通常的行为是匹配尽可能多的字符。考虑这个表达式:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
懒惰匹配
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的量词都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab。
(?:pattern)匹配检验
(?:pattern)则跟预查那四种匹配模式根本就不是一类东西,只是长得比较像,他们的最大区别就是:(?:pattern)是匹配字符,也就是会消耗字符。
(?:pattern)是和(pattern)相对应的,他们的区别在于:(pattern)是获取匹配,pattern内容会出现在匹配结果的中;(?:pattern)是非获取匹配。
(?:pattern)相比(pattern)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像(pattern)那样被捕获到某个组里面
例:

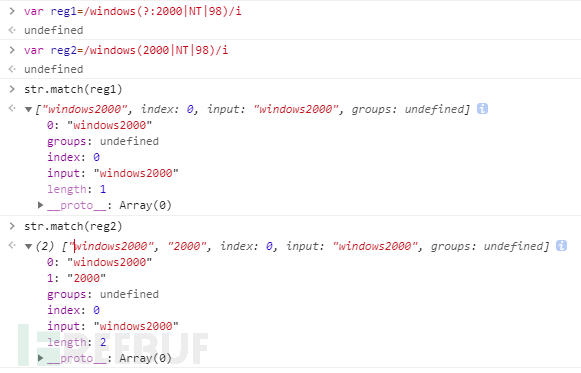
var reg1=/windows(?:2000|NT|98)/i var reg2=/windows(2000|NT|98)/i var str='windows2000' str.match(reg1) // ["windows2000", index: 0, input: "windows2000"] str.match(reg2) // ["windows2000", "2000", index: 0, input: "windows2000"] reg1.test(str) //true reg2.test(str) //true
可以注意到 第一个正则匹配返回的结果中没有子匹配的返回内容
reg1和reg2匹配"windows2000"字符串都可以完全被匹配到。
?:的结果中:只是2000没有作为单独的匹配结果放到组里。
位置
匹配一个位置,也就是不获取字符串,不消费字符
| 代码/语法 | 说明 |
|---|---|
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| \B | 匹配不是单词开头或结束的位置 |
| (?=exp) | 匹配后面跟着exp的位置,也就是exp前面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (?<=exp) | 匹配前面跟着exp的位置,也就是exp后面的位置 |
| (?<!exp) | 匹配前面不是exp的位置 |
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/2?68828[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/8?F7VdN[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/10?Qem6s[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/9?60644[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/4?53953[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/2?qyqku[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/10[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/5?YigcM[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/4?hrjvd[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/3?57571[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/1?yiucg[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/9?agsao[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/8[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/3?HJ3l5[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/9?K8eYk[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/4[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/10?02280[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/5?awkgg[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/7?9Dr7B[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/3?vdhjx[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/7?17939[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/2?8EmM2[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/7[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/4?D7J7r[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/1?04402[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/6?m48cS[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/6?44804[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/6[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/8?71191[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/9[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/10?scmuk[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/1?Ay4Ue[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/1[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/8?lxrbj[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/5[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/7?tltnn[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/5?40448[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/3[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/6?euysu[/url]
[url]https://github.com/efjfqjw8/wgecuocgyi/discussions/2[/url]
如有侵权请联系:admin#unsafe.sh