阅读: 0
自动化,快速准确地实现攻击溯源是网络空间防御体系向着智能化方向发展的重要基础。尽管学术界和工业界已经有了很多针对网络攻击溯源技术的研究,但是自动化攻击溯源本身却并没有取得实质性的突破。本文以真实的攻击溯源案例为基础,从数据获取和数据关联两个方面分析了自动化攻击溯源所面临的困难。
简介
“溯源”技术在生产生活的多个领域中有着广泛的应用,从供应链管理,到最近的新冠病毒传播路径分析,都属于溯源技术的应用。在网络攻防对抗中,“溯源”指的是找到谁攻击了我,攻击点在哪,以及相关的攻击路径,以此制定更有针对性的防护或反制措施。因此,自动化、快速准确地实现攻击溯源是网络空间防御体系向着智能化安全运营(AISecOps)方向发展的重要基础。
当前,学术界和工业界已经有了很多针对网络攻击溯源技术的研究,同时,ATT&CK框架,知识图谱等技术也被引入到了攻击溯源的研究中。虽然有各种新技术与模型的引入,自动化的攻击溯源本身却并没有取得实质性的突破,自动化溯源仍然无法有效地完成。其原因一方面是因为网络攻击溯源的入口不容易被发现。目前溯源的重要入口是安全设备产生的告警,如何从海量告警中找到重要的高危告警是安全运维过程中的一大难题,具体可以参阅之前的文章;另一方面,即使找到了高危的告警,自动化攻击溯源仍然面临着很多其他的困难,包括数据采集,数据分析与关联等都面临着多种困难。
攻击溯源按照最终的目标可以分为溯源到发起攻击的IP和溯源到攻击者本人两个层面。在进行攻击团伙分析,或者进行APT追踪,威胁情报生成的过程中往往只需要溯源到发起攻击的IP。而当前的一些大规模的攻防对抗演练中除了溯源到发起攻击的IP以外,还要求能够定位到攻击者本人。因此本文以一个企业内部真实的攻防对抗中的溯源事件为例,从溯源到发起攻击的IP和溯源到攻击者本人两个层面来分析自动化的攻击溯源的过程中遇到的问题。
案例
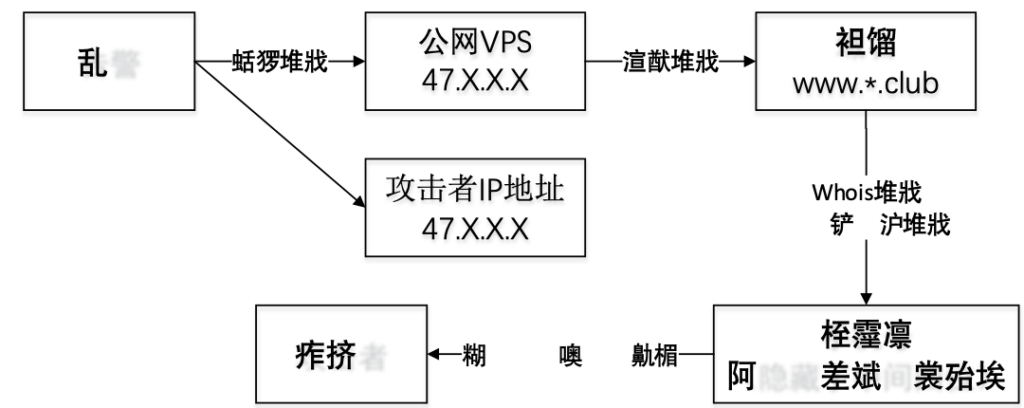
下面给出一个真实的攻击溯源案例。这个案例是在某公司内部的一次攻防对抗演练中成功实现攻击溯源的事件。溯源的流程如图 1所示。

- 从安全设备的告警日志中发现攻击方发起Jenkins远程命令执行攻击行为。
- 根据请求内容确定是利用公网VPS 47.X.X.X(阿里云)进行反弹shell,查看归一化日志反弹成功。
- 分析情报发现这个公网IP的VPS 47.X.X.X绑定的域名是www.*.club。
- 根据域名注册信息,找到了攻击者的姓氏,同时结合阿里云的密码找回机制,定位到手机号(隐藏了中间四位)。
- 根据内部通讯录定位到具体的攻击方人员。
在以上的溯源过程中,第一步和第二步所需的信息可以从安全设备的告警日志中直接获得。第三步可以由威胁情报获得。第四步需要查询域名的whois信息,同时还要在阿里云上模拟密码找回的操作,找到了已被部分脱敏的手机号。这一步所需要的数据无法通过被动的方法收集,必须主动出击才能获取到。第五步需要利用特定的数据集(内部通讯录)进行关联分析。
溯源过程分析
基于以上案例,接下来具体分析溯源过程中的难点。在溯源到发起攻击的IP和溯源到攻击者本人两个层面中所需要的溯源技术差别很大。从以上的案例可以看出,攻击溯源主要包含两项工作:其一是收集大量的数据,其二是对数据进行分析与关联,逐步找到攻击的源头。而在实际的溯源过程中,以上两项工作都面临着巨大的挑战。
溯源到发起攻击的IP
溯源到发起攻击的IP相对来说较容易。数据收集方面,主要需要收集安全设备的告警日志,并从中找到溯源的入口。这部分需要用到前面提到的告警评估部分的工作。同时,这部分需要对告警日志进行分析。例如在以上的案例中,确定攻击者使用了公网VPS 47.X.X.X(阿里云)的方法就是对告警日志payload中的请求内容进行分析获得。而告警日志的payload是非结构化数据,这给自动化分析带来了困难。在分析过程中,需要引入大量的专家知识,通过专家知识结合智能算法才能够自动化的找出告警payload中特定的请求信息。
在这个案例中,攻击者所采用的攻击手法并不复杂,同时告警信息较完备,所以溯源到发起攻击的IP较容易。在很多复杂的网络攻击中,网络拓扑信息,告警质量,流量数据和终端数据的质量都会影响自动化的溯源效果。因此,收集更多的网络数据,可以提升自动化溯源的效果。
溯源到攻击者本人
溯源到攻击者本人需要收集更多的数据。在以上的案例中,除了告警信息以外,还需要收集域名信息,用户在公网资源上的注册信息等。这类信息数量大,同时非常繁杂,在攻防对抗演练之前无法有效的获得。例如在上述案例中,在已经获得了攻击者使用的VPS信息和域名注册信息以后,定位攻击者的手机号的过程中,利用了阿里云的密码找回机制,即业务系统的特定功能。该机制可以返回略去中间四位的用户手机号码。出于对用户隐私保护的需要,域名,姓氏,手机号码对应的信息无法在攻防对抗演练之前获得,只能在需要的时候根据相关网站业务系统的特点来进行主动地获取。
另外,社会工程数据在攻击溯源的过程中扮演着重要的角色。在以上的案例中,从域名注册信息和阿里云获得了已经被脱敏的用户信息后,需要在公司内部的通讯录中进行模糊查找才最终定位到攻击者本人。这类数据往往不能被动的收集,只能在溯源的过程中根据经验和需要来主动获取,在获取的过程中也需要用到多种技术,同时还有很大的运气成分。
总结
以上以一个成功的攻击溯源案例为基础简要介绍了自动化的攻击溯源所面临的困难。在溯源到发起攻击的IP的过程中,一般只需要对告警日志,网络数据进行分析就能够定位到攻击者所使用的IP。而如果需要进一步溯源到攻击者本人,由于很多数据无法提前获得,因此需要采用更多的社会工程技术。在以上的案例中,攻击者在攻击的过程中并没有采取社会工程的手段,仅仅是以技术手段进行网络攻击,在溯源的过程中就要引入社会工程技术才能够溯源到攻击者本人。而在真实的网络攻击中,攻击者往往同时采用技术手段结合社会工程的方法进行攻击,这将导致攻击溯源变得更加复杂。因此,攻击溯源的研究,尤其是在溯源到攻击者本人的问题中,应该针对一些非常具体的场景来分析,找出针对特定场景的溯源方法,使得针对特定场景的自动化溯源成为可能。