非常感谢!我是李月锋, moony, wotongyi, 乙方安全公司架构,从PC,osx,mobile上的安全沙箱转moibile,IOT漏洞攻防与0day挖掘。之前有幸参加过blackhat会议,这是第一次有幸受段老师邀请参加国内大型安全会议,非常有幸能够结识国内安全圈子的人。
我这次主要是讲一下安卓0day平台上的漏洞检测、漏洞挖掘和检测,主要是基于沙箱系统的设计和实现,里面涉及到整体设计原则和大致怎么实现的坑,给同行做以借鉴
这是我要讲的Agenda:项目背景介绍、项目设计与实现、Summary。
我个人主要是在乙方做安全架构,前几年主要是做Windows、mac上沙箱系统的开发,最近几年转到Mobile0day漏洞挖掘,还有攻防对抗,有幸参加过几次blackhat会议,跟国外同行接触得相对多一点。
首先快速过一下安卓攻防对抗尤其是0day漏洞相关的演进。大家知道,漏洞我们都称之为是攻防上尤其是攻击这块的“安全王冠”,它相当于普通的APT或者Malware攻击在植入方式更加先进,一般我们把它分为1-Click攻击、0-Click攻击等不同类型。1-Click远程攻击比如URL访问,当发给你短信链接,你打开之后,对方可以远程执行你的微信等权限,再利用本地的漏洞提权成root。乃至还可以支持所谓的0-Click攻击,假设你的手机有WiFi、基带、蓝牙相关漏洞,理论上不需要受害者做任何处理,他开放的服务就会被黑客攻击。
攻防本质就是对抗,安卓系统本身在0day漏洞也在不断完善。我们可以看看从安卓1.0到安卓7,它加入了非常多的从用户态到内核态的,尤其像CPU里面我们做漏洞挖掘经常遇到类似于这样一些机制,它相当于内核态不能执行以后态的代码,内核态不能读写用户态相关的代码。
我们看一下近期安卓8、安卓9,以及马上要发布的安卓Q,里面也加入一些新的,像Post-init read-only memory,Hardened Usercopy,关键API做了加强,还有APN,KASLR。到安卓9都在CFI做了代码,Integer Overflow Sanitization,在地址和代码越界做了更深的check。安卓Q在lld linker做了更深级别的CFI。
像刚才讲的那样,攻和防,就是漏洞利用和漏洞发现,或本身就是一种对抗,我们左边可以认为是安全厂商,尤其是像谷歌这样操作系统可能会产生的采用手段,右边是普通的黑客或者高级黑客通过挖掘相关的漏洞,我们大概总结了一些,比如典型的oob和UAF相关漏洞,等等这些我们称为基础的漏洞类型,利用各种各样的技巧转换成任意代码执行,然后再配合一些,比如它开始smap的机制,可能需要leak内核态地址为堆喷做准备,然后利用相关的技巧去过左边的这些mitigations。Mitigations也分内核态和用户态的mitigation,演化进程就像刚才提到的列表。
这是另外一张更加好看一点的mitigation的对抗图,左边的也一样,一般通过找到用户态内核态的bug,这些bug是相对来讲是比较初始的。我们要绕过的一些对象,就是图里面用红框框起来的那些各种各样的mitigation,比如pxn、pan、cfi。

dev目录是像谷歌这样的厂商为了减少攻击界面,在设备初始化时,它会初始化它的设备数,这个设备数会往dev,然后通过iosctrl渠道注册内核态的,像Windows有些不必要的,不允许那些低权限的去访问,乃至直接从dev目录里把用户态可以访问的渠道cut掉。把一些还有一些没有必要暴露给用户态的Sys call减少掉,也会减少很大的攻击量。
下面selinux有点类似于分权的概念,就像mac里的root,即使你拿到到root权限,要做高权限事情的时候,比如访问或者读写关键的文件目录结构,或者访问高级别的servers时,都会受限。
古语说“知己知彼、百战不殆”,我们先从攻击界面和可选方案上大致梳理一下思路。左边是一个典型的安卓系统,看它大致可能会从哪些渠道被攻击,右边是站在防御或者防守的角度,我们可能会采取哪些溯源或者方案。

要梳理攻击界面,我们需要对安卓架构有相对比较深入的了解。我们用户态一般分高级和低级,高级别的它主要是指高权限的system servers,低权限的就是mobile user权限或者adb shell权限。另外浏览器的JS engine比如Wekit,V8引擎等也是一个很常见的攻击渠道。
因为普通的APP都是受限的沙箱环境里,如果我拿到了APP权限之后还需要额外的沙箱逃逸漏洞去逃逸到外面去执行更多行为,乃至如果需要的话我可以提供系统权限,这个内核态度或者能访问的就会更多。这个时候就可能要通过一些Driver、Socket等等,尤其高通闭源的driver的漏洞提前拿到一些权限。
从这样的角度来看,大家可以看到,一般真正安卓的攻击,典型的像远程相关的可能是一些js脚本,或者字体、多媒体等文件解析,典型的像2016年左右有一个的多媒体解MP4时出现了libstagefright远程代码执行的bug,这样只需要发某一种畸形的MP4文件的文件交给那个库去做解析,这个库恰好是高权限的serivce,相当于我远程可以拿到它系统权限。
它有这样一些,像音频视频这种文件类的,还有蓝牙、WiFi这样的近场或者远程的攻击渠道,最后一种是像APK,APK一般是用于典型的root提权漏洞,比如最新出现. 的Binder水滴漏洞是因为在底层的Binder驱动中出现了一个权限竞争,导致可以root安卓9之前的所有版本。这是所有攻击面的大概描述。
可选方案呢?大家做过沙箱方案的同事应该有一个印象是什么?普通的沙箱处理的是普通的File文件,它最大的问题是它可能跑出部分攻击行为来,但是我如果想还原出攻击第一环,比如远程越界的第一环,假如它是从流量打过来的,往往需要知道它的第一次访问的URL是什么,乃至它的URL具体对应的js脚本是什么。这样就有一个需求,往往都需要把某一个异常,比如某一个新创建的,之前的浏览器访问相关的Traffic包拿下来,做流量分析,有必要的话做些流量重放。
因为这里面会带一些除了APK之外,可执行文件的js脚本或者URL,它们打的本身就是像safari、chrome等这样的浏览器。这块其实需要类似于像webkit、V8引擎等等,我们需要对js脚本做emulation,可能会发现更多反混淆或者js上的潜在恶意行为乃至漏洞epxloit行为。
沙箱这块大部分是用户态的,可以通过一些Frida框架去拿到更多apk的so级别的行为分析,乃至我可以需要引入一些全系统的基于安卓整个虚拟机沙箱的经验。不管是动态还是静态,都有各自的优缺点,这也是为什么我们把静态、动态等方式综合在一起的原因所在,静态可能会有反逆向的手段和技巧来逃避检测,动态最大的问题是它的某些关键行为可能会有各种各样的条件依赖,导致这些代码虽然存在,但在动态环境下根本无法执行到,这涉及到很大的一个Anti-sandbox的领域,比如它会检测你当前的UI,用户是不是有特定操作,比如检测请求,看它的进程、文件、固件、CPU时差等这些信息等等。
还有比较一点是分阶段执行,拿到第一阶段的apk往往是很简单的一个壳,它本身不会做非常复杂的行为,它可能是等待时机,然后才会server端把后续重量级的有恶意行为的payload Down下来,这都没有非常好的工程化方案去解决。
所以站在全程的角度来看,我们基本把它分成几个阶段:第一阶段是sourcing,主要是从可能会存在的去Socket一些情报或者数据源下来,第二阶段,我们Sourcing到了那么多URL、APK,可能是几千万个或者上亿个,你怎么能够快速从里面去识别哪些可能包含漏洞?你可能会把几十万、几百万、几亿的数量级降到比如几万的级别,这主要是通过一些类似启发式的方法来筛选出最可疑的那一部分,最后再进行Dynamic分析,Dynamic相当于是更加精准去判定存在哪些恶意行为或者漏洞利用。最后情报feedback,假设当前url包含js脚本导致apk本身提权为root,这样比如它来自哪个市场,它的访问server、签名证书来自哪里、关键的string字段等等相关情报信息又可以反馈sourcing。
所以从sourcing Channel这、来看,站在乙方最大的一个来源之一就是Googlepaly和其它的第三方市场,还有偏researcher相关的来自人的情报,比如twitter或者github放一些热门漏洞的攻击POC,EXP等等,这也一个比较好的sourcing的渠道。
站在内部角度,我可能以那个爬Googleplaystore为例,需要这边的机制把相关的APK去下载下来,分门别类的逆向之后去入库,再经过我们分析,主要是针对so二进制的分析,再加上一些总结。右边的情况的分析主要是上半部分针对用户态的行为分析,还有针对内核态的。
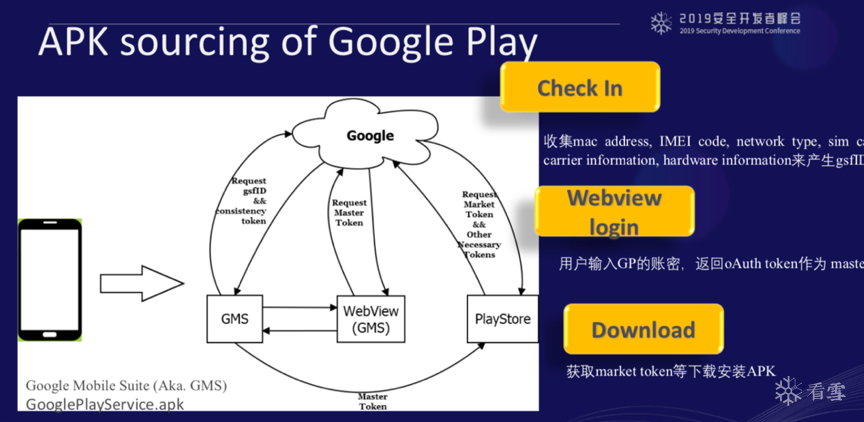
先讲一下以GoogleplayStore为例,这使个典型的我们普通用户去通过APP应用,用户去访问和下载某一个APP的典型流程这块都是逆向出来的。像checkin这个步骤主要是什么?刚才提到Googleplay有自己的机制,它会收集当前用户的地址、手机号、SIM卡等乱七八糟的信息,这些信息往往都是绑定手机,会产生一个id,有了这个这个id后续有一个类似于web访问页面,你输入Googlepaly帐号密码等等去登陆上以后,它会返回一个token,这个token相当于你当时登陆时的唯一凭证,它有了这个凭证之后再去Googlepaly的server上查看APP相关信息,比如它的链接、它的评论、它的下载量等等。

所以站在Crawl角度,为了过谷歌这一套反爬机制,其实有很多坑。右半部分是你要做一些反爬,把相关的data不停的变换,让Googleplay认为当前是不同的机器。因为同样一台机器、同样一个IP频繁的去访问Googleplay的话,它肯定会挡你的。
为了做到更加精准的Crawl,我们可能需要做设备上的模拟,除了对右边的那些关键点之外,你要去模拟像pixel等等不同型号的手机,如果有需要的话,假设哪家财大气粗,可以在不同的真机上通过Xpose或者Frida德国框架去做hook来模拟不同设备。
下面这个阶段,你下载了这么多APK之后,下面进入专家经验,做一些预过滤处理。我们当时是这样的设计逻辑,我们是把pattern分解,这个肯定是五花八门,针对不同的攻击界面,它对用户态比如最新bnider的漏洞,真正出问题的是在内核态里的binderdriver有个条件竞争导致UAF,但是它用户态利用时非常简单,它只是有一些会发起去看很正常的的binder请求,给那个受害的binder servers,同它发起的API的参数和API的名字来看,没有太大可以当作pattern的点。但有些漏洞比如DirtyCow漏洞,它调用异常的API mdvise和调用相关参数就可以作为比较好的Pattern点。
另外一块是exploit,这块相对来讲比较通用,而且看起来可以发现未知0day漏洞的。我们刚才提到各种有效手段漏洞,做exploit技巧上是有相对通用性的,比如它做堆喷时肯定会选择跟目标那个size相同,而且不停的有些循环,去做调用内核态的某些特定API去做Object堆喷,在它so用户态代码里肯定有类似这样的代码特征。其他的还有ROP,如果它保存在so里面,每个gadget肯定会跟一个内核态的相关地址,那个地址本身也会有一些特征。另外,开发者也会偷懒,它执行bash脚本,这个bash脚本可能是直接调用常见的API或者cmd,所以通过提取这些脚本,或者这个脚本里可能带一些hacktool,像刚才提到的busy box和su和其它的,如果他再偷懒的话会可能会用到metasploit相关的一些tool比如meterpreter工具,这些都是可以选择取的pattern点。
有了这个pattern,有了静态分析和动态分析,这个系统就会输出一些分析,就是哪些API或者哪些API组合参数,这些信息都会被枚举出来,这样它就出来一个对比,就是静态分析、动态分析的结果去判定,根据刚才那些pattern结果去判定,我们当时用了一个打分系统,它是不是足够可疑,它可疑在什么位置,其实也有一些细节。如果你想偷懒的话,可以针对每个pattern或者写一个Python脚本,针对这些特征可以做自己的,如果你想做得比较精细的话,可以参考像Drools这样的开源推理引擎的这套。
大家可以看看这边的Rule,它的意图是,当某个条件成立时它去执行某些Action,同时对当前的行为进行打分score,如果需要的话会设置某些全局变量状态实现不同的状态切换,后续新的rule可以利用之前的rule里的全局状态的值作为上下问来更新新的score,并且它是并发全节点的推理,这样它可以描述非常复杂的推理逻辑。
静态分析这块也有一些坑。我们提出了三种模式:像rough模式主要是提取出相关的一些API里面或者里的字符串做全匹配;Pattern模式可以用YaraRule,可以做二进制里的pattern,也可以支持简单的条件组合;我们最后采取的是第三种,精准模式,对目标文件做CFG或者xref to,xref from等这些产生相关的依赖,拿这些伪代码去判断,比如第几个参数或者返回值等符合哪些约束等等更精细的控制。
以这个为例,这个是DirtyCow漏洞,当时通过这个rought模式分析,找到差不多30万个malicious APP,这类APP主要是通过内核提权之后,它当时好像是在以电信发送一些软件,去预定一些收费服务。
我们看dirtyCow漏洞本身的核心点,右边部分是怎么去触发的图。这个本质是一个内核态里做内存访问时引起了条件竞争,引起了一个bug。大家可以看到,那个open第一个参数是打开了当前进程的memory空间,然后发起一个像madvise请求,这个发起会不停对内存做特定的访问,大家注意,madvis的第3个一定要是4,所以这个可以当作API特征上的一个强特征,包括open特定的dev string也可以当作pattern的强特征,其他是可有可无的,这个我们可以当成加分项。

刚才提到YaraRule,可以看到48 89 D6xxx 表明它是不是elf文件等等,乃至看E8 xxx代码是看代码中是否存在特定的jmp或者call。大家看到最后那行,其实是看它是不是发现出现了3次或者几次特定的字符串等等,这个逻辑都可以自己控制。
精准模式相对YaraRule模式更加精细化,这个是我们当时去扫的关键代码。刚才我们提到要求它必须要符合某些精准的特征,比如反汇编相关代码产生针对特定关键函数的cfg或者生成伪代码,在搜索这些cfg算分的时候,我会产生一个约束条件,比如要求mdvise要求第2个参数一定是4,其他的比如open的cfg也有针对第一个参数的约束。最后计算总分的时候,可以看这些cfg里这里面有没有相同的节点,既调了open又调了device,这两个节点可能是兄弟关系,也可能是旁兄弟关系,不一定在相同的分支上,然后针对不同的情况分别要有打分策略。一般来讲,这涉及到经验,比如0-30分可能是OK的、没问题的,30-60分是suspicious的,超过60分就直接判定danger。
我们通过这个系统,不同的模式下,它们能够match到的数量差异挺大的,像典型的rough模式可能全网或者全数据库里搜出来有17万个这么多,但是通过那种精准模式去查的话可能就到了几十个规模,这种规模非常适合后续通过动态方式去做更细致的确认。
关于Dynamic这块,我们把它分为了Kemel mode和UserMode,这张是dynamic部分的架构图,为什么要引这两种不同的内核和用户态?因为这还是取决于这个漏洞,像Binder水滴漏洞在用户态里能够调用的那些API往往没有什么典型的特征,但是它在内核态里出现的条件竞争的那个的就是固定的特征,所以它适合在内核态里去做hook。但是有些漏洞是出现在用户态上的特征比较多,在内核态也有,但用户态也有刚才提到的某几个参数一定要符合什么条件的这样强特征。所以我们最终在用户态选择现在非常流行的frida框架,去写相关漏洞和监控的脚本。
内核态监控也有一些技巧,希望跟大家去讲一下。内核态第一个可用的是谷歌推出来的SaftyNet,谷歌的代码是开源的,在每一个安全漏洞修bug时,会写相关的标志。还有就是像HeapSpray,刚才它到它肯定有相关的特征,包括它连续分配相同的块大小,而且整个分配组合在一起超过了100兆或者一个上限,这是本身就是可以用来推理用的特征。所以在runtimeAllocation也做了些检测。
另外一块是ROP的检测,这个都是借鉴之前像微软EMET那个思路,核心就是检测它某一个关键的API发生的时候反查他的调用是不是来自于正常的call 或者jmp 指令。

最后就是Post exploit阶段,payload会调高权限的service或者执行特定命令或者访问本来不可以访问的资源等等,也可以对这些关键的API进行hook比如exec API,bin/bash等启动, system目录访问等。
从最后Summary来讲,大家可以看到攻和防永远是对抗的,“未知攻、焉知防”,都是提升自己相应的技术能力,道高一尺魔高一丈的过程。
另外建议大家,首先,利用专家经验人工打通这个的漏洞hunt各个环节,然后针对这些做半自动化的辅助,最后是尝试重复性的东西做全自动化,最后这些信息一定要做好很好的feedback,这样才是完整的攻防闭环。
最后于 10分钟前 被wotongyi编辑 ,原因:
如有侵权请联系:admin#unsafe.sh