PNG HeaderPNG ChunksIHDR ChunkIDAT ChunksTool OperationYesterday I had to extract some data from hid 2018-02-26 08:27:49 Author: parsiya.net(查看原文) 阅读量:103 收藏
Yesterday I had to extract some data from hidden chunks in PNG files. I realized the PNG file format is blissfully simple.
I wrote some quick code that parses a PNG file, extracts some information, identifies chunks and finally extracts chunk data. The code has minimal error handling (if chunks are not formatted properly). We also do not care about parsing PLTE and tRNS chunks although we will extract them.
Code is at:
Golang's https://golang.org/src/image/png/reader.go does a decent job of explaining the rendering. But we are not interested in rendering.
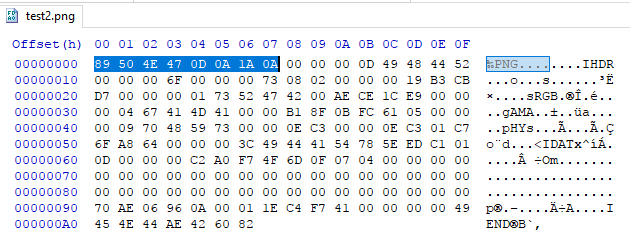
Instead we look at libpng documentation at http://www.libpng.org/pub/png/spec/1.2/PNG-Contents.html. I am going to use a simple example (just a black rectangle which was supposed to be a square lol) to demonstrate:
 Example
Example
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
00000010 00 00 00 6f 00 00 00 73 08 02 00 00 00 19 b3 cb |...o...s......³Ë|
00000020 d7 00 00 00 01 73 52 47 42 00 ae ce 1c e9 00 00 |×....sRGB.®Î.é..|
00000030 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 05 00 00 |..gAMA..±..üa...|
00000040 00 09 70 48 59 73 00 00 0e c3 00 00 0e c3 01 c7 |..pHYs...Ã...Ã.Ç|
00000050 6f a8 64 00 00 00 3c 49 44 41 54 78 5e ed c1 01 |o¨d...<IDATx^íÁ.|
00000060 0d 00 00 00 c2 a0 f7 4f 6d 0f 07 04 00 00 00 00 |.... ÷Om.......|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000090 70 ae 06 96 0a 00 01 1e c4 f7 41 00 00 00 00 49 |p®......Ä÷A....I|
000000a0 45 4e 44 ae 42 60 82 |END®B`.|PNG starts with an 8-byte magic header:
89 50 4E 47 0D 0A 1A 0Aconst pngHeader = "\x89PNG\r\n\x1a\n"from https://golang.org/src/image/png/reader.go.
When you open a PNG file, you can see PNG in the signature.
After the signature, there are a number of chunks.
 PNG header
PNG header
Each chunk has four fields:
uint32length in big-endian. This is the length of the data field.- Four-byte chunk type. Chunk type can be anything 1.
- Chunk data is a bunch of bytes with a fixed length read before.
- Four-byte CRC-32 of Chunk 2nd and 3rd field (chunk type and chunk data).
| |
First chunk or IHDR looks like this:
 IHDR chunk
IHDR chunk
Converting big-endian uint32s to int is straightforward:
| |
Note (05-Apr-2020): int is dangerous. On 32-bit systems it's int32 and on 64-bit systems it's int64. So on my machine I am converting int64 to uint32 because I am running a 64-bit OS. On a 32-bit machine (e.g., Go playground) int is int32. In retrospect, I should have probably used int32 in the struct or come to think of it uint32 could have been a better choice. For more information please see int vs. int.
Trick #1: When reading chunks, I did something I had not done before. I passed in an io.Reader. This let me pass anything that implements that interface to the method. As each chunk is populated, reader pointer moves forward and gets to the start of next chunk. Note this assumes chunks are formatted correctly and does not check the CRC32 hash.
| |
IHDR Chunk
IHDR is a special chunk that contains file information. It's always 13 bytes and has:
// Width: 4 bytes
// Height: 4 bytes
// Bit depth: 1 byte
// Color type: 1 byte
// Compression method: 1 byte
// Filter method: 1 byte
// Interlace method: 1 byteThese will go directly into the PNG struct:
| |
Trick #2: chunks does not start with a capital letter. It's not exported, so it is not parsed when we convert the struct to JSON.
Parsing the header pretty easy:
| |
Our example's IHDR is:
{
"Width": 111,
"Height": 115,
"BitDepth": 8,
"ColorType": 2,
"CompressionMethod": 0,
"FilterMethod": 0,
"InterlaceMethod": 0,
"NumberOfChunks": 6
}IDAT Chunks
IDAT chunks contain the image data. They are compressed using deflate. If you look at the first chunk, you will see the zlib magic header. This stackoverflow answer lists them:
78 01- No Compression/low78 9C- Default Compression78 DA- Best Compression
Another answer has more info:
Level | ZLIB | GZIP
1 | 78 01 | 1F 8B
2 | 78 5E | 1F 8B
3 | 78 5E | 1F 8B
4 | 78 5E | 1F 8B
5 | 78 5E | 1F 8B
6 | 78 9C | 1F 8B
7 | 78 DA | 1F 8B
8 | 78 DA | 1F 8B
9 | 78 DA | 1F 8B I have seen a lot of random looking blobs starting with 78 9C when reversing custom protocols at work. I have never seen the other two headers.
In Go we can inflate the blob (decompress them) with zlib.NewReader:
| |
Note that each chunk is not compressed individually. All IDAT chunks need to be extracted, concatenated and decompressed together.
In our case, IDAT chunk has the 78 5E header:
00000000 78 5e ed c1 01 0d 00 00 00 c2 a0 f7 4f 6d 0f 07 |x^íÁ..... ÷Om..|
00000010 04 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 70 ae 06 96 0a 00 01 |.....p®.....|Everything else is straightforward after this.
Operation is pretty simple. PNG is passed by -file. Tool will display the PNG info like height and width. -c flag will display the chunks and their first 20 bytes. Chunks can be saved to file individually. Modifying the program to collect, decompress and store the IDAT chunks is also simple.
 Tool in action
Tool in action
如有侵权请联系:admin#unsafe.sh