I’m in fast-follow mode here, with more Topfew reportage. Previous chapters (reverse chrono order) 2021-04-01 04:00:00 Author: www.tbray.org(查看原文) 阅读量:155 收藏
I’m in fast-follow mode here, with more Topfew reportage. Previous chapters (reverse chrono order) here, here, and here. Fortunately I’m not going to need 3500 words this time, but you probably need to have read the most recent chapter for this to make sense. Tl;dr: It’s a whole lot faster now, mostly due to work from Simon Fell. My feeling now is that the code is up against the limits and I’d be surprised if any implementation were noticeably faster. Not saying it won’t happen, just that I’d be surprised. With a retake on the Amdahl’s-law graphics that will please concurrency geeks.
What we did ·
I got the first PR from Simon remarkably soon after posting
Topfew and Amdahl.
All the commits are here, but to summarize: Simon knows the Go API landscape
better than I do and also spotted lots of opportunities I’d missed to avoid allocating or extending memory. I spotted one place
where we could eliminate a few million map[] updates.
Side-trip: map[] details · (This is a little bit complicated but will entertain Gophers.)
The code keeps the counts in a map[string]*uint64. Because the value is a pointer to the count, you
really only need to update the map when you find a new key; otherwise you just look up the value and say something like
countP, exists = counts[key]
if exists {
*countP++
} else {
// update the map
}It’d be reasonable to wonder whether it wouldn’t be simpler to just say:
*countP++
map[key] = countP // usually a no-opExcept for, Topfew keeps its data in []byte to avoid creating millions of short-lived strings.
But unfortunately, Go doesn’t let you key a map with []byte, so
when you reference the map you say things
like counts[string(keybytes)]. That turns out to be efficient because of
this code,
which may at first glance appear an egregious hack but is actually a fine piece of pragmatic engineering: Recognizing when a map
is being keyed by a stringified byte slice, the compiled code dodges creating the string.
But of course if you’re updating the map, it has to create a string so it can retain something immutable to do hash collision resolution on.
For all those reasons, the if exists code above runs faster than updating the map every time, even when almost all those updates
logically amount to no-ops.
Back to concurrency · Bearing in mind that Topfew works by splitting up the input file into segments and farming the occurrence-counting work out to per-segment threads, here’s what we got:
A big reduction in segment-worker CPU by creating fewer strings and pre-allocating slices.
Consequent on this, a big reduction in garbage creation, which matters because garbage collection is necessarily single-threaded to some degree and thus on the “critical path” in Amdahl’s-law terms.
Modest speedups in the (single-threaded, thus important) occurrence-counting code.
But Simon was just getting warmed up. Topfew used to interleave filtering and field manipulation in the segment workers with a batched mutexed call into the single-threaded counter. He changed that so the counting and ranking is done in the segment workers and when they’re all finished they send their output through a channel to an admirably simple-minded merge routine.
Anyhow, here’s a re-take of the Go-vs-Rust typical-times readout from last time:
Go (03/27): 11.01s user 2.18s system 668% cpu 1.973 total
Rust: 10.85s user 1.42s system 1143% cpu 1.073 total
Go (03/31): 7.39s user 1.54s system 1245% cpu 0.717 total
(Simon’s now a committer on the project.)
Amdahl’s Law in pictures · This is my favorite part.
First, the graph that shows how much parallelism we can get by dividing the file into more and more segments. Which turns out to be pretty good in the case of this particular task, until the parallel work starts jamming up behind whatever proportion is single-threaded.
You are rarely going to see a concurrency graph that’s this linear.

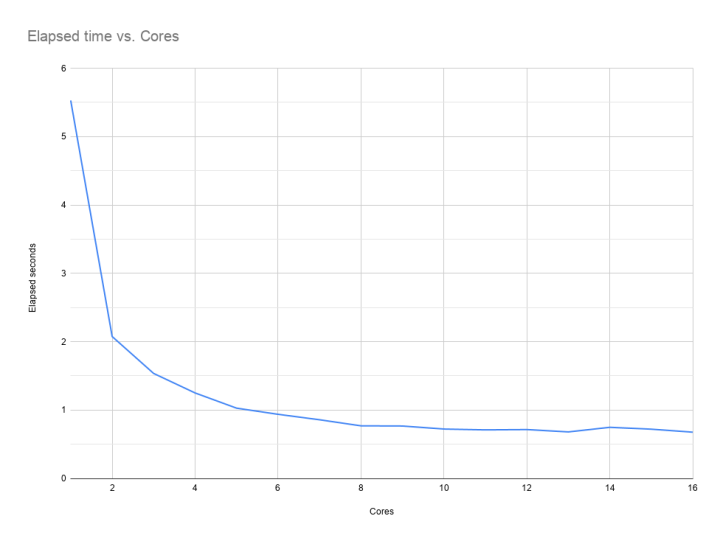
Then, the graph that shows how much execution speeds up as we deal the work out to more and more segments.

Which turns out to be a lot up front then a bit more, than none at all, per Amdahl’s Law.
Go thoughts · I like Go for a bunch of reasons, but the most important is that it’s a small simple language that’s easy to write and easy to read. So it bothers me a bit that to squeeze out these pedal-to-the-metal results, Simon and I had to fight against the language a bit and use occasionally non-intuitive techniques.
On the one hand, it’d be great if the language squeezed the best performance out of slightly more naive implementations. (Which by the way Java is pretty good at, after all these years.) On the other hand, it’s not that often that you really need to get the pedal this close to the metal. But command-line utilities applied to Big Data… well, they need to be fast.
By .
The opinions expressed here
are my own, and no other party
necessarily agrees with them.
A full disclosure of my
professional interests is
on the author page.
如有侵权请联系:admin#unsafe.sh