
Fuzzing helps detect unknown vulnerabilities before software is released. Learn when and where to integrate and automate fuzz testing in your SDLC.

Fuzz testing is a highly effective technique for finding weaknesses in software. It’s performed by delivering malformed and unexpected inputs to target software while monitoring it to detect unwanted behavior and log failures. Fuzzing is widely recognized as a valuable technique for improving the security, robustness, and safety of software, and it’s an integral part of some of the best-known secure software development life cycle (SDLC) frameworks.
Over the last decade, software development tools and methodologies have become more integrated into continuous integration / continuous delivery (CI/CD) pipelines and security testing processes. Some testing methodologies integrate more easily than others though, so adoption and integration depth can vary widely.
The fuzz testing maturity model (FTMM) was created to measure the extent to which software builders and buyers have used fuzzing. FTMM describes six levels of testing maturity:
- Immature (level 0): This is software that has never been fuzzed.
- Initial (level 1): In this level, there has been initial exposure to fuzz testing. Although it’s not comprehensive, it’s an excellent first step for organizations looking to make quick improvements in robustness and security.
- Defined (level 2): In this level, companies are using a more defined approach for performing fuzz testing. The starting point is an attack surface analysis of the target.
- Managed (level 3): This level emphasizes completeness and documentation so it’s easy to observe and improve the fuzzing process. This is an excellent baseline for builders.
- Integrated (level 4): This level increases the fuzzing time per fuzzer type to one week. Fuzzing must be incorporated in the organization’s automated testing.
- Optimized (level 5): This level increases fuzz testing time to 30 days for each fuzzing type, and requires the use of at least two different fuzzers per fuzzing type.
FTMM sets the requirements for the types of fuzzers, the amount of testing, instrumentation, acceptable failures, processes, and documentation for each level. This blog post focuses on the benefits of leveraging fuzzing in existing SDLC processes and extending its use in CI/CD pipelines. It also addresses integration concerns with fuzzing technology.
Benefits of fuzz testing maturity model
In the Managed level of FTMM (level 3), fuzz testing is integrated into the secure software development process to detect vulnerabilities before the software is released. However, the process to set up the target software, configure and run the test tool, and report the findings is entirely manual. Fuzzing, as well as other dynamic application security testing (DAST) tools, require runtime verification of compiled, packaged, configured, and running software. The fuzz test tool must also be configured—it’s a good amount of work and multiple steps. If that work is left on human shoulders, chances are the first round of tests may not match the second, which will slow down subsequent diagnosis, fixing, and testing.
Repeatability
Therefore, repeatability is the #1 benefit of moving to the Integrated level of FTMM (level 4). The CI pipeline can be used to perform the build, static analysis, and software composition analysis of the code to locate quality issues and known vulnerabilities before the target software is deployed in the test infrastructure for fuzzing. The CI pipeline ensures the deployment is done in a repeatable manner—it handles the configuration of the target software to control the exposure of attack vectors to the system. It can also configure the fuzzer, connect it with the target software, start the test, and provide a report when the test is complete. In a best-case scenario, the CI system has a repeatable configuration as code covering tests for the whole attack surface.
Collaboration
Integrating the CI/CD pipeline with fuzz testing can also improve collaboration. Often, the security team is responsible for attack surface analysis and fuzz test planning, assisted by the development team. In the Managed level of FTMM (level 3), the security or QA team executes the tests, and the development team fixes discovered issues. When fuzzing is integrated into the CI pipeline, the tests are defined by the security team but developers also get direct access to results on a regular basis. If a test goes red, the development team checks for details of the fail, performs the analysis, and delivers a fix. As security teams have less trouble reporting issues, they can use more time on attack surface analysis and increase coverage over the attack surface.
Earlier issue detection in smaller increments of codebase changes
One of the benefits of integrating fuzzing with the CI/CD pipeline is earlier feedback. However, fuzzing is an open-ended pursuit—an infinite space problem. Can it keep up with the feedback rate expected and improve development speed?
Fuzzing takes time: Template fuzzers start with an example input, and the quality and feature coverage of the example affect how quickly the fuzzer starts producing meaningful tests. The speed is often great, but testing requires a large number of iterations. In generational fuzzing or model-based fuzzing tools such as Defensics®, all the test cases are “smart” but there are a lot of them, and the fuzzer takes time to encode and decode exchanged messages on each iteration. Fuzzing of a single attack vector easily takes hours. You could continue fuzzing infinitely, but at some point the likelihood of finding new issues is low.
The benefit of integrating fuzzing with the CI/CD pipeline might be less about testing speed and more about detecting issues earlier and getting feedback for smaller increments of codebase changes. Even though you would not trigger a fuzzer on every commit or even on every merge, there’s a chance to fuzz much more frequently than on major releases. Fuzzing on a nightly or weekly basis can bring benefits.
When you should integrate fuzzing
There are important activities in secure software development, such as attack surface analysis, that cannot be automated and that are essential in selecting what to fuzz. Begin the analysis by documenting any information you have on the attack surface, such as exposed physical and logical interfaces and ports. Then document protocols and file formats that can be used for interacting with the system under test (SUT). Based on the attack surface analysis, you should be able to choose what to fuzz test first.
The first fuzz test of the SUT can be performed manually. There are, however, things you can do that will help you later automate these steps. For example, save the fuzzer configuration as well as the SUT configuration in case you need to repeat the test or start integration in the test pipeline.
Setting up the test environment and triggering the test run based on a schedule or a code merge event can be automated. A fuzz test report can also be generated automatically. And in case of a fail, a notification can be immediately sent to relevant development team.
First, automate the SUT deployment. You can often reuse a deployment setup for functional integration tests or other DAST tools. Second, automate the fuzzer configuration. Then triggering the fuzzer can be done manually. It makes sense to enable integrated fuzzing when the software being tested is robust enough that fuzz tests don’t cause systematic fails. Introducing a full integration too early can result in continuously failing pipelines and unnecessary frequent testing. Often, first enabling fuzzing in the test pipeline on developer’s request is useful. Automating the reporting and notifications for failures is recommended at this point in any case.
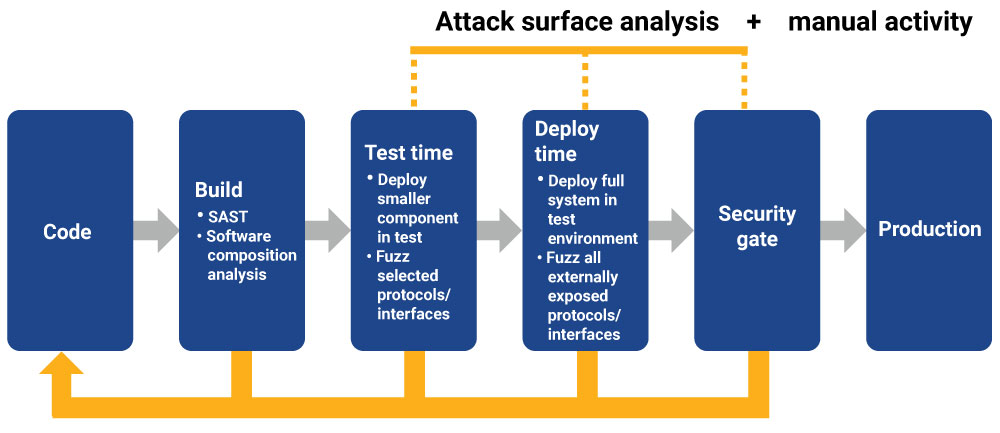
When a baseline of SUT robustness is achieved, fuzzing can be triggered automatically. Fails in fuzz testing results are often security issues that should break the build—notify development team to start a manual process to analyze and fix the issue, and optionally auto-block the software increment road to the production branch or production deployment. Once basic robustness is achieved via fuzz testing and penetration testing, QA and security teams might want to focus on adding depth and breadth of testing to cover more of the attack surface, and add closer instrumentation to detect issues better. All this is recommended before release, but it’s just as important to ensure that the software stays robust and secure over its whole life cycle and maintenance time. This is best achieved with fully automated fuzzing.
Use a dedicated test environment for fuzzing
Fuzzing, as well as other DAST techniques, requires that the SUT is running. This adds challenges to setting up the testing environment, but it also has advantages. Since there’s no source code required, DAST can be run against any runnable target, including third-party components and binaries for which source code may not be available.
Fuzzing shouldn’t be done in a production environment. Testing in production may sometimes be desirable, but fuzzing with anomalous messages is by nature less predictable than the more common testing techniques, so it can more easily cause issues in not just the main SUT but also in all other connected services. This is especially true for lower-layer networks and routing protocols such as DNS, DHCP, STP, BGP, and the like. Having a dedicated staging or preproduction environment that’s completely isolated for these sorts of tests is highly recommended.
A dedicated testing environment also helps maintain a high level of repeatability. Having a static, known state as the starting point for both the fuzzer and the SUT and its running environment is an important factor in having repeatable tests. Virtualization and containerization are good ways to provide an easily repeatable configuration for the testing environment. When designing a suitable test environment, it’s vital to know your SUT and what it needs. Fuzzing application layer protocols is usually a lot simpler than routing protocols, and it can usually be done in containers. The tests of lower-layer protocols may include spoofed MAC/IP addresses though, which often are blocked by virtualization environments by default and so require greater care in the environment’s configuration.
The type of environment and how it’s set up may also require special consideration when it comes to instrumentation. For example, container orchestrators, like Kubernetes, often come with automated self-healing and scaling capabilities that may mask crashes and other issues from connection-style instrumentation methods. Make sure to tailor your instrumentation to catch any noteworthy failure events that happen in your environment. For example, Defensics recently added an instrumentation agent capable of detecting crashes in Kubernetes environments.
Start small and slowly add coverage and instrumentation
Some systems and software might have a large attack surface that is exposing lots of features and alternative communication channels. Fuzz testing doesn’t have to cover absolutely everything from the start. The configuration of the fuzzer can start small and grow, adding tests for one attack vector or protocol at a time.
Externally exposed interfaces should be prioritized in testing as they are the gateway to exploiting weaknesses. System hardening and reducing attack surfaces are good ways to reduce security risk. However, there’s a benefit to testing and fuzzing internal components as well. For example, fuzzing an internal component that’s responsible for subset of functionality instead of fuzzing a proxying public interfacing component can better expose unwanted behavior. And black box fuzzing can check that valid requests are continuing to be served as expected during fuzzing.
Load balancers and automated error recovery can make it difficult to detect issues that don’t immediately crash the observable behavior. For example, if you were developing a website where users post their own images and do simple editing such as adding funny text, the externally exposed interface of the service would include an HTTP API for posting an image file, and another HTTP endpoint for editing the image. A fuzzer could post an anomalous JPEG image and make another call to trigger the editing function. By observing the HTTP response codes, the fuzzer could detect, for example, “500,” indicating that something unexpected happened. But it couldn’t really tell if it was a problem in the image parsing, some other business logic, or the database. If fuzzing had been done for the image processing library in isolation, it would have been straightforward to associate the problem with the image processor and develop a fix.
Another benefit of fuzzing internal components instead of full systems is simplified test environment setup. Even though internal components with issues may not expose an exploitable attack vector, you may still want to detect and fix the quality issue.
Fuzzing can cause unwanted behavior such as crashes, kernel panics, unhandled exceptions, assertion failures, busy loops, and resource consumption issues that will be detected by the instrumentation function of the fuzzer. By default, Defensics does black box instrumentation by observing the behavior of the software from the outside. It ensures that the software is still responsive, and valid requests are being processed by the software as expected. Crashes and DoS typically get revealed this way, and some unexpected responses may reveal logic and parsing issues in the implementation. This kind of instrumentation comes with some transient failures, especially when testing networking software. Requests timing out due to an unrelated network glitch can be expected and should be allowed in results. If they start to become a hindrance in inspecting results though, it’s a good idea to see if something can be done.
It’s important to ensure there are no issues that can compromise the target software. Transient issues are are harder to reproduce, so analyzing for them is more difficult, but some may be real issues so you don’t want to ignore them. Be sure to minimize the amount of other traffic and changes in the network while testing and see if it helps to keep transient issues away.
If the fuzzer doesn’t discover any failures, check if closer instrumentation would reveal issues. By observing the software’s ability to process valid functions from the outside, you may miss problems often visible to system administrators and developers only. For example, a resource consumption peak may temporarily slow down the service externally but it may heal itself quickly and go unspotted by the fuzzer. We encountered these kinds of obstacles while working on the recent Jetty vulnerability. On the other hand, such problems may become exploitable with a simple loop. If you only have access to binaries of the software, you can often add tooling on the host machine to monitor memory and CPU consumption, watch for log files typically available to system admins, and subscribe to system events. In addition, if you have access to the source code you may have more options to address sanitization. An instrumented source code issue log can give very good hints for determining the root causes of issues.
Defensics can hook to many different instrumentation data sources, some of which can be enabled with a few configuration options, and others that will need the user to run a prebuild agent binary on the test target host machine. Each instrumentation agent does specific monitoring, and multiple agents can run simultaneously. Extending instrumentation with a custom agent is possible as well. A good way to start is to create a list of the various system health areas you would manually check and then automate instrumentation for them. The main limiting factors are access to the host machine running the software, access to the source code, and your imagination.
Manage fuzzing time

Whatever fuzzing schedule you choose to implement—nightly, weekly, or by request—the fuzzer can allow you to limit the time used for fuzzing. Carefully consider how to get good feature coverage during the available time. When doing template-based fuzzing, make sure the sample data covers the feature, and the testing time is spread out appropriately. With model-based generational fuzzing, allocate testing time per protocol/file format and ensure the features for a single protocol are tested in a balanced manner within test time limits. Defensics makes it easy to pick a default set of test cases specific to the protocol, limit test execution time, and define the number of test cases to run.
One way to increase the fuzzing time per software increment is to parallelize fuzzing, and then use the saved linear time to either get fuzzing feedback more frequently or add feature coverage. If the target software has multiple protocol implementations or multiple configurations to test, there’s a substantial benefit to running those test configurations in parallel. In practice, it’s beneficial to invest in a test infrastructure that can deploy multiple instances of the target software at the same time, so you can run a variety of fuzzer configurations. It’s often possible to run multiple fuzzer instances against a single running test target, but the difficulty is in interpreting the test results—it would be hard to tell which test caused which symptom. Only after the desired number of tests, feature coverage, and instrumentation depth is achieved would it make sense to increase testing time and the number of anomalous inputs.
How to integrate Defensics in CI/CD
Defensics allows headless test integration via a Jenkins plugin, CLI, and the recently renewed REST API. All three integration interfaces allow a basic workflow of configuring the fuzzer, running and tracking test progress, and exporting test reports. Defensics test cases are highly repeatable and test reports ease communication between stakeholders.
Learn more about Defensics fuzz testing
![]()
如有侵权请联系:admin#unsafe.sh