阅读: 8
所谓Spam,就是在互联网上通过邮件、短信等方式群发给大量用户的消息。发送这些垃圾短信或垃圾邮件的目的有很多,可能是广告推广、钓鱼或传播恶意软件。不管它的目的如何,都会给普通用户的日常生活带来干扰,所以Spam检测也是威胁检测里的热门方向之一。
RSAC 2021会议中《AI vs AI: Creating Novel Spam and Catching it with Text Generating AI》议题,提出了一种针对Spam进行检测的模型GPT_pplm。GPT_pplm与之前基于内容的Spam检测模型最大的区别,在于这个模型可以自己生产Spam样本供自己学习。这样做会带来什么好处呢?具体是怎么实现的呢?本文将对于这个议题进行详细解读。
一、 需要更多训练样本的原因
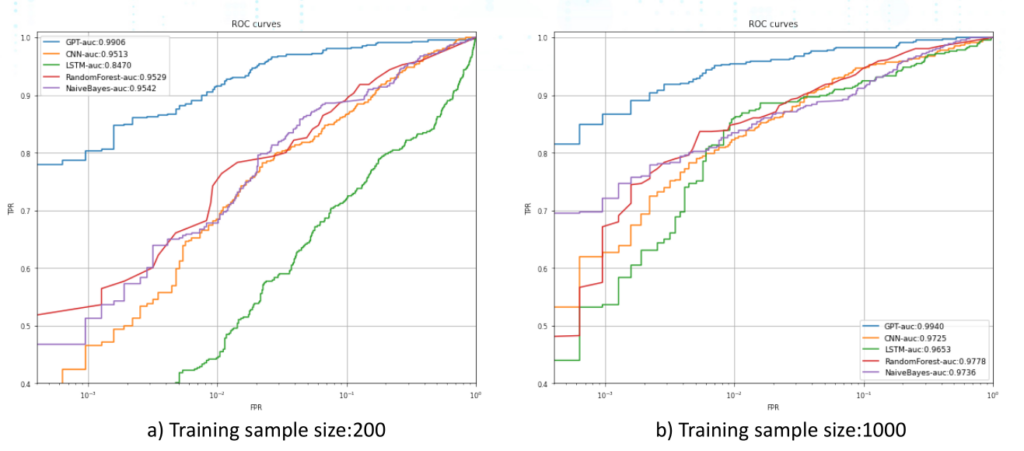
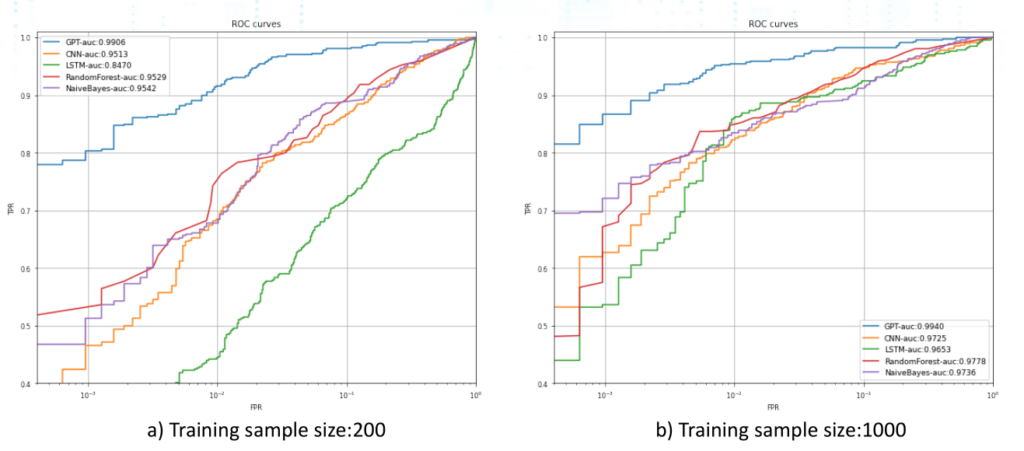
首先,作者在200个样本和1000个样本的条件下,分别对多种检测模型如GPT/CNN/LSTM/随机森林/朴素贝叶斯进行了实验。从图中我们可以看到,在训练样本数量变多的情况下,各个模型的效果也会变好,例如GPT的准确度在1000个样本的情况下准确度为0.9940,高于200个样本下相同模型的准确度0.9906。
更多的训练样本可以带来更好的模型效果,但人工收集数据并打标却需要付出一些代价。
- 高昂的价格
- 拖慢工期:可能80%的时间花在打标上,而只剩20%的时间用于模型调优
- 可能对数据集带来负面影响:模型只在用于训练它的数据上效果好
所以,如果有一个自己生产训练样本给自己学习的模型,无疑是既可以优化模型效果,又可以避免人工打标带来的问题,这也就是我们下面将进行详细解读的GPT_pplm模型。
二、自行生成Spam样本并检测的整体结构
鉴于多个模型在两种大小的样本集上进行比对的实验里,GPT模型的效果一直优于其他模型,而PPLM模型是一种文本生成模型,所以作者就将GPT模型和PPLM结合起来,形成GPT_pplm模型。
三、如何生成Spam样本
PPLM是一个可以不需要修改预训练好的语言生成模型,即可以控制生成的文本所对应的话题及观点的语言生成模型。
PPLM的主体思路就是:
p(x|a) ∝ p(a|x)p(x)
如果以a表示某种风格,而x表示生成的文本,那么p(x|a)即表示生成特定风格的文本。而预训练好的文本生成模型得到的文本为p(x),此时再在后面跟上一个或者多个属性模型,这些属性模型用于得到p(a|x)即判断预训练模型生成的文本是否属于指定风格。那么这样一个预训练模型加上一个多个属性模型,就可以达到生成特定风格文本的效果。
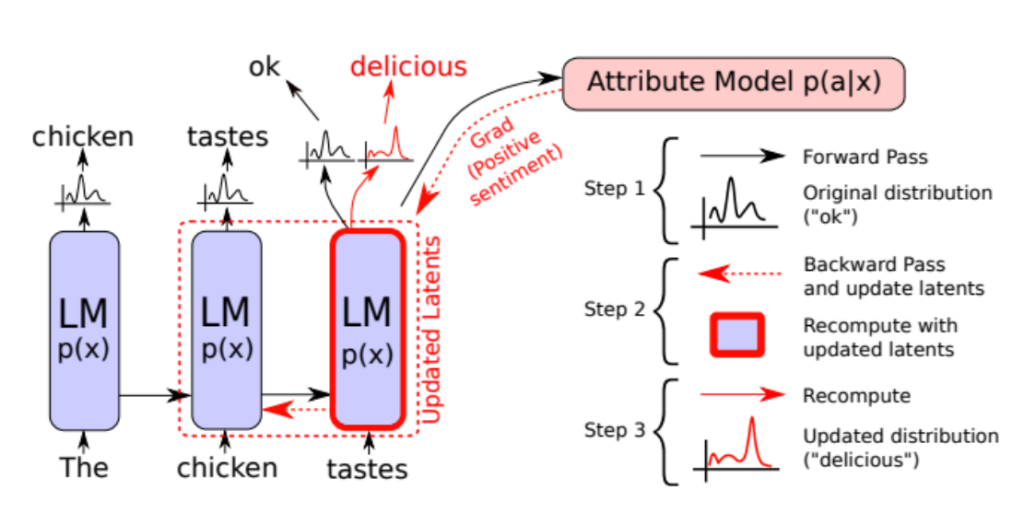
如图所示,需要生成积极观点的文本。第一轮时,判断生成文本所属的风格分类,如果不符合要求,此时将会反向传播调整内部相关变量。然后再基于调整后的变量重新生成文本并计算得到结果,反复多次之后,直至生成的文本符合风格主题的相关需求。
PPLM模型的源码路径:https://github.com/uber-research/PPLM
那么,使用PPLM模型可以基于已有的Spam样本进行扩充,扩充方式如下:
- 基于已有的Spam样本,每个训练样本再生成N个新样本
- 使用已有样本里的头5个词,用PPLM模型扩充为完整样本

四、如何检测
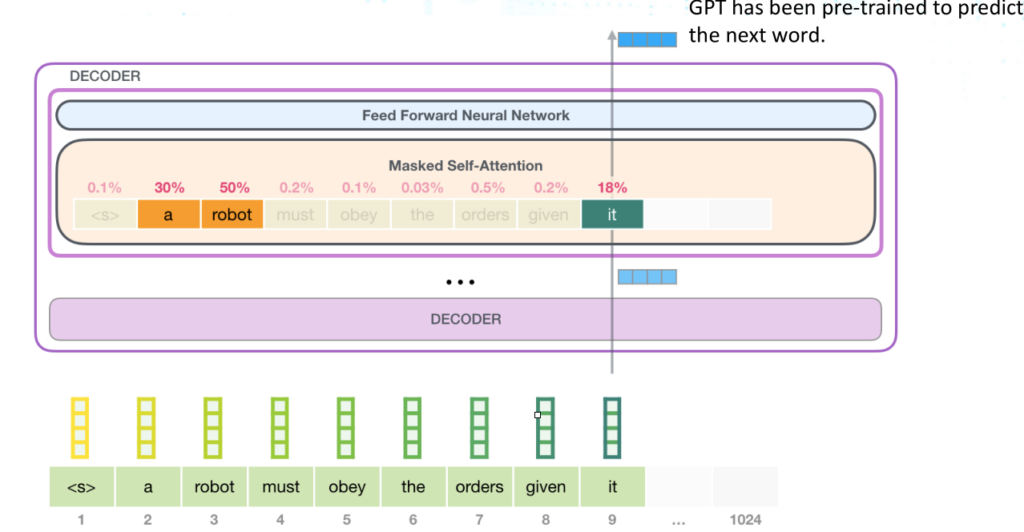
如图所示,GPT可以根据词前一个词预测下一个词,大多数情况下都用作文本生成,不过议题作者将它用作了检测Spam。
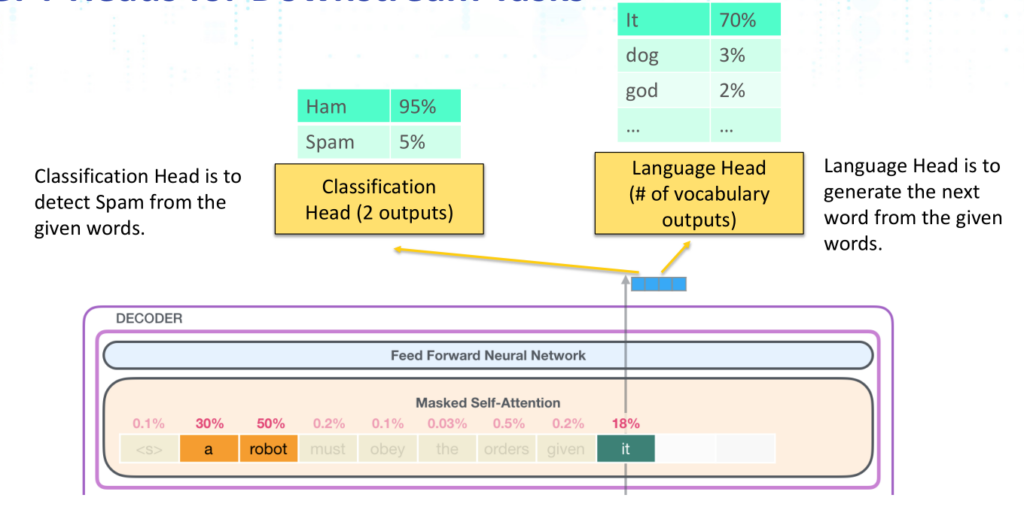
之所以可以用于检测Spam,是因为除了GPT模型有Language Head用于根据指定的词生成下一个词外,还令GPT模型有一个Classification Head用于对于给定词进行分类(二分类,Spam或者非Spam)。
五、效果对比
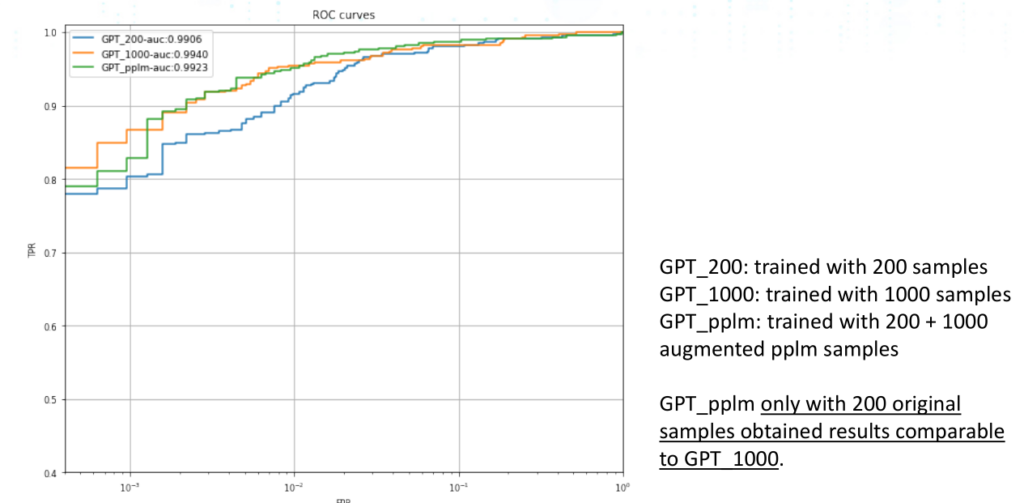
如图所示,结合了PPLM和GPT的模型GPT_pplm在只有200个训练样本(自行生成1000个训练样本)情况下的准确率为0.9923,与在1000个样本下训练的普通GPT模型的准确率0.9940非常接近。这也证明,自己构造样本学习的模型在小规模训练集下的效果很好。
六、一些启示
在使用机器学习分类算法时,很多时候都受困于训练数据很少、采集和标注数据代价过高等问题,将模型改造为可以基于现有样本构建出更多样本以供自己学习也是解决此类问题的方法。
参考资料
《AI vs AI: Creating Novel Spam and Catching it with Text Generating AI》
《PLUG AND PLAY LANGUAGE MODELS : A SIMPLE A PPROACH TO CONTROLLED TEXT GENERATION》
《Improving Language Understanding by Generative Pre-Training》
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。