阅读: 9
“授人以鱼不如授人以渔”,为了提升黑盒模型的透明度,提升模型在高度动态网络环境下的鲁棒性、可维护性,我们通过无监督学习、可解释人工智能(eXplainable AI, XAI)、字符序列相似性分析等方法,实现了自动化的攻击特征提取工具——XAIGen。目前,XAIGen项目已经开源,项目地址为https://github.com/oasiszrz/XAIGen,项目开源信息可见前文《XAIGen:自动化攻击特征提取的项目开源啦》。
目前,XAIGen能够针对面向文本分析场景的有监督模型,进行模型知识的抽取,生成以关键词集合为基础的特征规则。本文将深入介绍XAIGen,概述从模型抽取知识规则的技术出发点与技术细节。
一、技术缘起
从攻击特征提取的任务目标出发,模型透明度的提升为我们提供了全新的机会。不止于获得模型给出的分类结果,回答“是什么”的问题,我们还能够撬开某个审视过大规模样本的模型的嘴巴,让它回答“为什么”的问题——来生成传统安全中最直观的各种特征规则。
那么,安全检测技术研究从基于经验的规则驱动,到基于模型的数据驱动方法,为何我们要探索基于模型来生成特征规则呢?
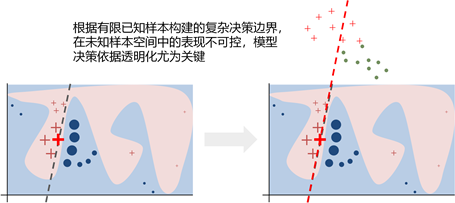
实际上,机器学习、深度学习模型的关键在于拟合学习,同时习得规律,保持泛化能力。然而,如图1所示,在有限已知样本空间中训练的模型,在面对未知样本进行分类时,该模型的复杂的决策边界很可能不在适用。这将导致模型分类性能的衰减,如果此时没有透明可视的决策依据说明,则模型所产生的错误结果将难以调试和运营,加剧人对模型的不信任。
因此,在网络安全检测、溯源、响应等各环节自动化任务中,唯有可解释、可运营的方法与策略才是可实战的。这正是我们探索通过对模型进行知识抽取,来提升模型实战能力的关键驱动力之一[1][2][3]。
那么如何从模型中抽取知识规则呢?以图1为例,针对明文的Webshell恶意流量的检测,专家一般会提取载荷中的关键词,例如函数方法名、变量名、HTTP方法名等,形成基于关键词特征的检测规则。与之相对的,通过有标签的、基于文本分析模型的学习方法,可训练得到在离线数据集上高分类准确性的机器学习分类模型,能够有效区分Webshell流量与正常业务流量的内容载荷。进而,结合经典的Post-hoc可解释人工智能等方法,能够把对分类决策产生重要影响的“关键词”呈现出来,而这些关键词,是与安全专家的经验直觉是一致的。
这无疑带给我们重要的启示:尽管在安全知识、安全语义的理解上与安全业务分析场景的需求有差距,但在数据规律的挖掘、高区分性特征的定位上面,数据驱动的模型能够弥补人的数据视野、分析精力的不足,辅助人进行关键特征的提取。
二、相关技术
实际上,已有不少研究工作尝试解决恶意流量特征规则的自动化提取问题,主要包括基于LCS(Longest Common Subsequence)算法[4][5]、基于模型学习等类型的方法[6]和启发式算法[7][8][9]等。Park等人提出LASER算法[4],基于LCS(Longest Common Subsequence)算法,提取恶意流量载荷中的公共子串形成规则。然而LCS只能针对载荷内容同质的场景,在大规模内容异构的攻击场景下难以工作;此外,该方法提取过程只针对恶意流量,未考虑所提取规则与正常流量的区分性。Lee等人提出LARGen一种基于LDA(Latent Dirichlet Allocation)主题模型的恶意软件流量特征提取算法[6],能够有效提取恶意主题中的关键字串。该方法虽然基于无监督模型,但算法的有效性仍然依赖准确的人工标注,规则提取性能在不同场景下稳定性难以保证。Rafique等人提出FIRMA[5],该方法基于协议解析、聚类以及标记提取等步骤进行恶意软件流量规则提取。该方所提取标记集合形成的规则具备较高的恶意与正常流量分类准确性,但该方法效果依赖协议解析效果,可拓展性较低。
XAIGen[10]的技术创新性在于,通过LIME(Local Interpretable Model-Agnostic Explanations)黑盒模型推断方法[11],从已训练的恶意流量与正常流量分类模型中提取特征规则,并通过聚类和优化的LCS算法,有效识别恶意流量中的扫描流量特征(包含同质载荷内容),有效提升规则的准确率。
三、整体架构
XAIGen特征规则自动化提取算法的整体架构如图3所示。该架构下,恶意流量特征提取模块的输入包括两个部分:待进行规则提取的恶意流量载荷集合,以及恶意流量检测分类器。该分类器可基于决策树、循环神经网络等机器学习或深度学习模型构建,以完成在识别恶意流量等文本分类任务。由于特征规则提取算法使用模型推断方法进行部分载荷的规则提取,因此提取特征的准确性依赖该分类器的检测准确性,为此,可选用分类性能较高的分类器模型。

当待分析的恶意流量集合输入特征提取模块,首先对该恶意流量载荷进行采样,采样是为提升在大规模流量情况下的处理效率,降低处理延迟。进一步,根据采样恶意流量载荷,进行字节级别的聚类,以将恶意流量中的扫描流量识别出来:扫描流量指包含同质载荷内容的流量集合,在聚类过程中将形成聚类簇。对每个聚类簇,使用基于LCS的算法提取扫描规则;对未归类到任何聚类簇内的非扫描流量,使用LIME模型推断方法,生成推断规则。进而,通过循环匹配,对所有所有规则进行压缩和去重。最后,使用生成的规则对以上恶意流量载荷集合和指定的正常流量载荷集合进行检测并得出预测标签,以评估所提取规则的分类性能,同时对于漏报的恶意载荷集合再次执行上述提取操作,以生成针对该类漏报恶意载荷的新规则。
通过识别并提取同质载荷中的公共字节序列形成规则,能够有效屏蔽掉大规模同质攻击载荷对规则提取处理性能的影响;同时能够降低模型推断中随机性的影响,提升规则的整体鲁棒性,降低规则集的规模,提升检测阶段的处理性能。
四、技术细节
以下技术细节实现中,以网络流量载荷分类场景中的恶意流量特征提取任务为例。除数据预处理外,
- 数据预处理
首先,网络流量预处理以网络数据流为基本单位,网络数据流由共享五元组(源地址,源端口,目的地址,目的端口,协议号)的所有数据包序列构成。同一个会话交互流程中的两条对向数据流称为双向流。流量预处理的目标是提取每个双向流流量载荷中的可读字符串。根据不同的业务目标,如webshell检测、应用层DDoS检测等,所提取的协议字段可能不同,例如只提取HTTP POST请求中的载荷内容。对于任意载荷内容,首先将所有非可读字节剔除,所有连续可读字符串形成“句子”;进而通过正则表达式对所有句子进行切割、Base64解码、最终进行分词,最终得到载荷对应的由“单词”集合组成的“文档”。值得注意的是,在分词等环节所使用的“词库”须与感知阶段恶意流量检测模型使用的“词库”保持一致,以实现与检测分类器相同的单词编码。
- 载荷聚类
为提升规则的覆盖率、准确性等指标,本文通过载荷字节级别的内容聚类来区分扫描类型流量和非扫描类型流量。扫描类型流量在载荷内容层面普遍存在内容同质的特性,即扫描数据流的载荷字节有大量的指令、路径字段重复,参数略有变化。基于该假设,本文通过字符串的相似性定义距离来衡量载荷的相似性,进而完成聚类操作。具有同质内容的扫描流量载荷将划分到不同的聚类簇中。本文使用Levenshtein距离[12]计算字符串的相似度,使用基于密度的DBSCAN算法[13]完成聚类操作,通过指定最大距离参数、最少样本数参数等控制聚类效果,以避免显式指定聚类簇个数。
- 特征规则提取
特征规则提取是所提算法的核心环节。针对扫描类型流量载荷,即对每个聚类簇,使用优化的LCS算法,递归LCS(Recursive Longest Common Subsequence, RLCS)遍历聚类簇内所有载荷,每个聚类簇提取一个对应的关键词集合。RLCS算法针对任意两个字符串s1,s2,提取满足长度阈值threshold要求的公共字串集合,具体方法如图15所示。

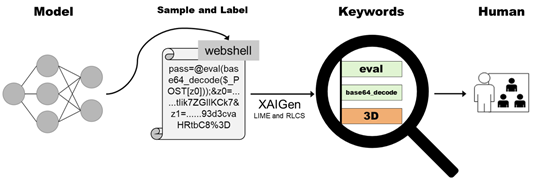
针对非扫描类型流量,即所有聚类簇外“离散”的载荷“文档”,使用模型推断方法LIME进行规则提取。模型推断是一类对黑盒机器学习模型进行逻辑推测的方法,经典方法包括基于采样拟合的LIME、面向深度学习模型的DeepLIFT[14]和基于博弈论的SHAP[15]等。LIME通过在待分析样本(如文本)的特征(如单词词频等)集合上进行局部采样,生成原样本的虚拟近邻样本集;进而使用原黑盒模型预测各近邻样本的标签;最终通过可解释的线性回归等模型,拟合近邻样本集特征值与其预测标签之间的关系,学习所得到的模型系数,即可用于近似表示黑盒模型在预测原样本时的推理逻辑。一个Webshell样本预测的模型推断流程如图16所示。
‘pass=@eval(base64_decode($_POST[z0]));&z0=......tIok7Zf23KCk7&z1=......9rd3cvdiutbC8%3D’
预处理后生成的文档为“词语”列表:{pass,eval, base64_decode,_POST,z0,…,z1,…, 3D}。以上文档由于篇幅原因有所省略。在检测模型识别该载荷内容为webshell的情况下,使用LIME算法能够得到模型将该载荷样本识别为恶意webshell的关键词及其贡献程度的置信度值。形式化可描述为关键词及其对应置信度的元组列表形式:{(eval,0.48),(z1,0.30),(_POST,0.23),(pass,-0.04),…}。以上信息能够直观的辅助决策者理解黑盒机器学习模型的判断依据,增加模型的透明度。本文基于以上逻辑基础,将置信度大于某一阈值α并且最小长度大于阈值threshold的“单词”集合作为该非扫描流量的特征关键词集合。
经过上述步骤,每个聚类簇包含的同质扫描流量生成一条对应扫描特征规则,能够有效覆盖对应簇内的扫描流量;每条非扫描流量生成一条对应的推断规则,该推断规则基于模型学习到的恶意流量判别“知识”,这些特征关键词继承了模型在正常流量与恶意流量之间的强区分性。此外,通过扫描与非扫描的聚类划分,能够有效识别扫描特征,降低规则总量的冗余度,提升规则匹配的效率。
- 规则压缩
前述规则提取过程,每条规则的提取实际上独立的过程,因此基于关键词的特征规则可存在重复(包含完全相同的关键词集合)、覆盖(集合包含关系)等冗余情况。本文通过将特征关键词转为正则表达式,并以循环遍历的方式,去除冗余规则实现压缩,保持规则的唯一性和原子性。
- 规则评估
压缩后的规则须经过分类性能评估。评估数据集(评估集)包含当前批次恶意流量载荷样本(采样率βm),以及正常样本(可与感知阶段检测模型使用相同训练数据集,采样率βn-his),以及与当前批次恶意流量在同一时间窗口 内的正常样本(采样率βn-cur)。基于以上关键词特征规则,记录所有样本的命中情况,命中即标记为恶意,将该分类标签与实际标签进行比较。算法的评估模块主要评估三个核心指标,恶意流量召回率TPR(True Positive Rate)、识别误报率FPR(False Positive Rate)以及整体准确率(Accuracy)。以上三个指标直接关系到入侵检测、DDoS防护等恶意流量阻断、检测设备的有效性。
基于以上评估结果,当评估结果不满足设定阈值时,丢弃高误报率的规则并将漏报的恶意流量载荷样本重新进行规则提取,直到提取循环次数达到上限(或超时),最终得到可用的规则集合。
五、总结
相信大部分从事安全领域数据科学研究的读者,也在实战场景下遇到了数据驱动模型缺乏可解释性带来的不可信任问题。XAIGen项目通过数据驱动的方法,尝试搭建数据规律与安全语义转化的桥梁,是实战中可信任、可运营智能模型的重要基础工作之一。欢迎感兴趣的读者试用XAIGen,并参与到可解释安全智能的研究工作中来。
参考文献
[1]《AISecOps智能安全运营技术白皮书》
[2]《XAI系列一:可信任安全智能与可解释性》
[3]《XAI系列二:模型可解释性技术概览》
[4]Park B, Won Y J, Kim M, et al. Towards automated application signature generation for traffic identification[C]. NOMS 2008 – 2008 IEEE Network Operations and Management Symposium, 2008: 160-167.
[5]Rafique M Z, Caballero J. FIRMA: Malware Clustering and Network Signature Generation with Mixed Network Behaviors[C]. Research in Attacks, Intrusions, and Defenses, 2013: 144-163.
[6]Lee S, Kim S, Lee S, et al. LARGen: Automatic Signature Generation for Malwares Using Latent Dirichlet Allocation[J]. IEEE Transactions on Dependable and Secure Computing, 2018, 15(5): 771-783.
[7]Cheng M, Xiaohong H, Jun W, et al. Network traffic signature generation mechanism using principal component analysis[J]. China Communications, 2013, 10(11): 95-106.
[8]Yoon S-H, Park J-S, Kim M-S. Behavior Signature for Fine-grained Traffic Identification[J]. Appl. Math, 2015, 9: 523-534.
[9]Sija B D, Shim K-S, Kim M-S. Automatic Payload Signature Generation for Accurate Identification of Internet Applications and Application Services[J]. KSII Transactions on Internet & Information Systems, 2018, 12(4).
[10]Zhang R, Tong M, Chen L, et al. CMIRGen: Automatic Signature Generation Algorithm for Malicious Network Traffic[C]. 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), 2020: 736-743.
[11]Ribeiro M T, Singh S, Guestrin C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier[C]. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016: 1135–1144.
[12]A guided tour to approximate string matching” (PDF). ACM Computing Surveys. 33 (1): 31–88.
[13]A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96)
[14]Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences[C]. Proceedings of the 34th International Conference on Machine Learning-Volume 70, 2017: 3145-3153.
[15]Lundberg S M, Lee S-I. A unified approach to interpreting model predictions[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 4768–4777.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。