
作者:灵巧@蚂蚁安全实验室
原文链接:https://mp.weixin.qq.com/s/oILVBQSIG5PDpBS4rCCh8A
同济大学教授史扬:
拜占庭将军问题的研究始于1982年,由LeslieLamport等学者提出。它以古代拜占庭帝国的将军们围攻城市为背景,讲述了一个关于忠诚与背叛的故事,并且巧妙的蕴含了现代分布式系统的一致性问题。正是由于在分布式和并行系统的理论与实践方面的巨大成就, Lamport在2013年成为图灵奖得主。
拜占庭容错(BFT)则给出了存在“叛徒”时解决拜占庭问题的方法,它不仅仅在许可链中受到高度的重视,在公有链中也有广泛的应用,例如由另一位图灵奖得主Sivio Micali 等设计的Algorand 这一PoS机制中,相关技术也被反复的使用。
蚂蚁安全实验室的这篇分享首先介绍了BFT的基本概念,随后以Fabric和DPoS协议等为例介绍了BFT在区块链中的应用;在此基础上,对BFT协议的威胁模型展开探讨,分别分析了理想世界和现实世界的威胁模型,以及在BFT协议被攻破后,对区块链安全会有哪些影响。文章内容丰富,叙述详尽,可以供研究和开发区块链系统的读者们参考,相信会对分析甚至是提高区块链系统的安全性有所裨益。
关于区块链安全,特别是智能合约的安全性方面,蚂蚁安全实验室还发表了一系列颇有价值的文章。希望蚂蚁安全实验室可以继续为提高区块链系统与应用的安全性做出的贡献,也非常感谢他们的分享。
共识算法是区块链的核心基石,是区块链系统安全性的重要保障。区块链的共识算法中,除了常见的工作量证明(PoW,Proof of Work)和权益证明(PoS,Proof of Stake)外,还有拜占庭容错(Byzantine Fault Tolerance, BFT)共识算法。拜占庭容错(Byzantine Fault Tolerance, BFT)共识算法是由拜占庭将军问题衍生出来的共识算法。
拜占庭将军问题(Byzantine Generals Problem),首先由 Leslie Lamport 与另外两人在1982年提出。故事大概是这么说的:
一组拜占庭将军分别各率领一支军队共同围困一座城市。为了简化问题,将各支军队的行动策略限定为进攻或撤离两种。因为部分军队进攻、部分军队撤离可能会造成灾难性后果,因此各位将军必须通过投票来达成一致策略,即所有军队一起进攻或所有军队一起撤离。因为各位将军分处城市不同方向,他们只能通过信使互相联系。在投票过程中每位将军都将自己投票给进攻还是撤退的信息通过信使分别通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以知道共同的投票结果而决定行动策略。
这就是拜占庭将军问题。解决拜占庭将军问题的协议称为拜占庭将军协议,也称拜占庭容错协议 Byzantine Fault Tolerance,简称 BFT 协议。
Byzantine错误,或者称为任意错误,指实体(服务器或者客户端)被攻击者完全控制,攻击者可以根据自己的意愿和环境情况执行各种操作。当实体发生Byzantine错误时,行为是不可预测的,常见的可能行为包括:
●停机,错误实体不响应其他服务器和客户端所发送的信息;
●发送正确或错误的消息,造成网络拥塞,使得其它正确的服务器和客户端不能正常地接收、发送和处理信息;
●篡改和转发消息,使得频繁地出现操作冲突,降低系统性能。
BFT 协议讨论的是允许存在少数节点发生 Byzantine 错误的场景下如何达成共识的问题。BFT 协议最主要的目的是保证运行协议的各服务节点保持状态一致,即:
●相同的处理逻辑。通常,各服务器运行相同代码。
●相同的初始状态。在系统初始化时,配置为相同的初始状态。
●执行相同的操作序列。各服务器按照一致顺序处理客户端的多个请求消息,保证状态变化的一致性。
BFT 协议早在区块链提出之前,就在一些行业被广泛应用,如航空、航天、核电行业。这些行业和区块链账本一样,对稳定性和一致性的要求非常之高,要求即使一些节点发生了 Byzantine 错误,也要保证系统稳定和一致地运行下去。这在区块链上就表现为链不停摆、不分叉。
BFT 协议对编程语言没有要求,只要能够实现协议算法,满足实现过程中没有漏洞,可以使用任何编程语言。但是在实际的实现和运行过程中,很难做到没有漏洞,现实世界中 BFT 协议面临多种威胁。当 BFT协议作为区块链的共识算法时,攻击 BFT 会对区块链产生怎样的影响呢?
本文共分为上下两集:上集第 2 节介绍了BFT协议在区块链的应用,我们选取了有代表性的应用案例。下集第 1 节分析BFT协议的威胁模型,分别分析了理想世界和现实世界的威胁模型。第 2 节分析了BFT协议被攻破后,对区块链安全会有哪些影响。第 3 节做了简要总结。
2.1 PBFT -- Fabric 共识协议
PBFT 是第一个性能能满足实用要求的协议,也是后续众多变种协议主要的参考对象。PBFT 由 n=3f + 1 台服务器组成,最多容忍 f 台 Byzantine 错误服务器,算法复杂度为O(N²)。由于随着节点的增加,PBFT 的性能会显著下降,所以 PBFT 更多的是应用在联盟链中,如 Fabric。
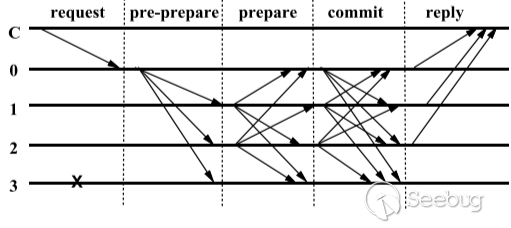
在正常情况下,PBFT 使用如下通信过程协商请求消息的操作顺序 。由特定的、负责确定顺序的服务器(称为 Primary 图中的 0)发起操作 。当 Primary 收到客户端的请求消息后,确定相应的顺序,转发给其它服务器,通过 2 步通信(Pre-prepare 和 Prepare)保证至少 f+1 台正确服务器就客户端请求的执行顺序达成一致,然后再经 1 步 Commit 通信通知各服务器。
-
1.REQUEST:
客户端c向主节点p发送
<REQUEST, o, t, c>请求。o: 请求的具体操作,t: 请求时客户端追加的时间戳,c:客户端标识。REQUEST: 包含消息内容m,以及消息摘要d(m)。客户端对请求进行签名。 -
2.PRE-PREPARE:
主节点收到客户端的请求,需要进行以下交验:
a. 客户端请求消息签名是否正确。
非法请求丢弃。正确请求,分配一个编号n,编号n主要用于对客户端的请求进行排序。然后广播一条
<<PRE-PREPARE, v, n, d>, m>消息给其他副本节点。v:视图编号,d:客户端消息摘要,m:消息内容。<PRE-PREPARE, v, n, d>进行主节点签名。n是要在某一个范围区间内的[h, H],具体原因参见垃圾回收部分。 -
3.PREPARE:
副本节点i收到主节点的PRE-PREPARE消息,需要进行以下交验:
a. 主节点PRE-PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了一条在同一v下并且编号也是n,但是签名不同的PRE-PREPARE信息。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。正确请求,副本节点i向其他节点包括主节点发送一条
<PREPARE, v, n, d, i>消息, v, n, d 与上述 PRE-PREPARE消息内容相同,i是当前副本节点编号。<PREPARE, v, n, d, i>进行副本节点i的签名。记录PRE-PREPARE和PREPARE消息到log中,用于View Change过程中恢复未完成的请求操作。 -
4.COMMIT:
主节点和副本节点收到PREPARE消息,需要进行以下交验:
a. 副本节点PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. n是否在区间[h, H]内。
d. d是否和当前已收到PRE-PPREPARE中的d相同。
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的PREPARE消息,则向其他节点包括主节点发送一条
<COMMIT, v, n, d, i>消息,v, n, d, i与上述PREPARE消息内容相同。<COMMIT, v, n, d, i>进行副本节点i的签名。记录COMMIT消息到日志中,用于View Change过程中恢复未完成的请求操作。记录其他副本节点发送的PREPARE消息到log中。 -
5.REPLY:
主节点和副本节点收到COMMIT消息,需要进行以下交验:
a. 副本节点COMMIT消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的COMMIT消息,说明当前网络中的大部分节点已经达成共识,运行客户端的请求操作o,并返回
<REPLY, v, t, c, i, r>给客户端,r是请求操作结果,客户端如果收到f+1个相同的REPLY消息,说明客户端发起的请求已经达成全网共识,否则客户端需要判断是否重新发送请求给主节点。记录其他副本节点发送的COMMIT消息到log中。垃圾回收:
在上述算法流程中,为了确保在View Change的过程中,能够恢复先前的请求,每一个副本节点都记录一些消息到本地的log中,当执行请求后副本节点需要把之前该请求的记录消息清除掉。最简单的做法是在Reply消息后,再执行一次当前状态的共识同步,这样做的成本比较高,因此可以在执行完多条请求K(例如:100条)后执行一次状态同步。这个状态同步消息就是CheckPoint消息。
副本节点i发送
<CheckPoint, n, d, i>给其他节点,n是当前节点所保留的最后一个视图请求编号,d是对当前状态的一个摘要,该CheckPoint消息记录到log中。如果副本节点i收到了2f+1个验证过的CheckPoint消息,则清除先前日志中的消息,并以n作为当前一个stable checkpoint。这是理想情况,实际上当副本节点i向其他节点发出CheckPoint消息后,其他节点还没有完成K条请求,所以不会立即对i的请求作出响应,它还会按照自己的节奏,向前行进,但此时发出的CheckPoint并未形成stable,为了防止i的处理请求过快,设置一个上文提到的高低水位区间[h, H]来解决这个问题。低水位h等于上一个stable checkpoint的编号,高水位H = h + L,其中L是我们指定的数值,等于checkpoint周期处理请求数K的整数倍,可以设置为L = 2K。当副本节点i处理请求超过高水位H时,此时就会停止脚步,等待stable checkpoint发生变化,再继续前进。
View Change:
如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性。如果主节点掉线或者作恶不广播客户端的请求,客户端设置超时机制,超时的话,向所有副本节点广播请求消息。副本节点检测出主节点作恶或者下线,发起View Change协议。
副本节点向其他节点广播
<VIEW-CHANGE, v+1, n, C, P, i>消息。n是最新的stable checkpoint的编号,C是2f+1验证过的CheckPoint消息集合,P是当前副本节点未完成的请求的PRE-PREPARE和PREPARE消息集合。当主节点p = v + 1 mod |R|收到2f个有效的VIEW-CHANGE消息后,向其他节点广播
<NEW-VIEW, v+1, V, O>消息。V是有效的VIEW-CHANGE消息集合。O是主节点重新发起的未经完成的PRE-PREPARE消息集合。PRE-PREPARE消息集合的选取规则:1.选取V中最小的stable checkpoint编号min-s,选取V中prepare消息的最大编号max-s。
2.在min-s和max-s之间,如果存在P消息集合,则创建
<<PRE-PREPARE, v+1, n, d>, m>消息。否则创建一个空的PRE-PREPARE消息,即:<<PRE-PREPARE, v+1, n, d(null)>, m(null)>, m(null)空消息,d(null)空消息摘要。副本节点收到主节点的NEW-VIEW消息,验证有效性,有效的话,进入v+1状态,并且开始O中的PRE-PREPARE消息处理流程。
在 PBFT 中,通过如下设计,使其在正常情况下的性能有显著优化:
●使用快速的消息认证码和 hash 计算代替计算量大的数字签名计算;
●采用缓存机制,批量的处理客户端请求;
●仅由某一台服务器向客户端发送完整的响应消息,其余服务器只发送 hash 值验证已响应消息的正确性。
但是 PBFT 也存在一些不足之处:
1.客户端请求的处理延时较大,在 5 步通信后才会返回执行结果(使用暂态优化执行仍需要 4 步通信延时)。这是因为正确服务器需要确定至少 f 台其他正确服务器就执行顺序达成一致后才会处理请求消息。
2.服务器间的广播通信量巨大 ,导致容错扩展性方面表现不佳 。对于 n 台服务器,通信复杂度是 O(N²)。随着容忍的拜占庭错误服务器数目增加,通信量急剧上升,正常情况下的性能也会明显下降 。
2.2 DPOS - aBFT -- EOS2.0 共识协议
要理解 EOS 平台的 DPoS+aBFT 就要先介绍 DPos 机制。在最早的 EOS 技术白皮书中,EOS主要采用的是 DPoS 机制,而在新版的白皮书中,做了一些改进,采用了 aBFT+DPoS共识机制。
2.1.1 什么是DPoS呢?
DPoS:Deligated Proof of Stake,也称委托股权证明,在 EOS 的白皮书中对 EOS 为何使用 DPoS 进行了详尽的解释,简单摘录如下:
EOS.IO软件架构中采用目前为止唯一能够复合上述性能要求的区块链共识算(DPOS)。根据这种算法,全网持有代币的人可以通过投票系统来选择区块生产者,一旦当选任何人都可以参与区块的生产。
EOS.IO里预计每3秒生产一个区块。任何时刻,只有一个生产者被授权产生区块。如果在某个时间内没有成功出块,则跳过该块。
EOS.IO架构中区块产生是以21个区块为一个周期。在每个出块周期开始时,21个区块生产者会被投票选出。前20名出块者首选自动选出,第21个出块者按所得投票数目对应概率选出。所选择的生产者会根据从块时间导出的伪随机数进行混合。以便保证出块者之间的连接尽量平衡。
如果出块者错过了一个块,并且在最近24小时内没有产生任何块,则这个出块者将被删除。这确保了网络的顺利运行。
在正常情况下,DPOS块链不会经历任何分叉,因为块生产者合作生产区块而不是竞争。如果有区块分叉,共识将自动切换到最长的链条。具有更多生产者的区块链长度将比具有较少生产者的区块链增长速度更快。此外,没有块生产者应该同时在两个区块链分叉上生产块。如果一个块生产者发现这么做了,就可能被投票出局。
2.1.2 那么什么又是 aBFT+DPoS?
aBFT+DPoS: asynchronous Byzantine Fault Tolerance- Deligated Proof of Stake,又称具有异步拜占庭容错机制的DPoS。典型的 DPoS 区块链有100%的区块生产者参与。从广播时间开始平均0.25秒后,可以认为交易具有99.9%的确定性。除 DPoS 外,EOS.IO 还添加了异步拜占庭容错(aBFT),以更快地实现不可逆性。aBFT 算法可在1秒内提供 100% 的不可逆性确认。
拜占庭容错的“异步”属性克服了对容错的挑战,即时序问题。很多 BFT 协议都假定在达成共识时存在最大消息延迟阈值。异步拜占庭容错(aBFT)网络消除了这种假设,并允许某些消息丢失或无限期地延迟。
DPOS 共识加上 aBFT 算法后,验证时不再按照出块顺序由超级节点一个个验证区块内容,而是让出块节点成为主节点,出块后同时向剩下 20 个节点进行广播,并获得节点的验证反馈,如果有超过 2/3 的节点验证通过,则该区块成为不可逆区块。aBFT可以使得EOS的区块确认速度显著增加。
该机制的具体过程是:EOS 的持有者通过投票系统对各个超级节点竞选者进行投票,选出 21 个节点为超级节点。然后这 21个超级节点以自身的网络资源状况商议出一个出块权拥有顺序,在每个超级节点拥有出块权时,以间隔为500毫秒(500毫秒是EOS团队通过大量实验测试得出的当前网络状态下可达到的最小的稳定状态下的出块间隔)连续产生 6 个新区块,然后切换到下一个超级节点连续产生之后的 6 个区块。
该方式可以保证一个超级节点可以连续以500毫秒的间隔产生区块,因为在同一超级节点产生新区块时不受当前网络状况的影响,但由于网络的延迟很难使得其他节点对已经产生的区块进行确认,使其成为不可逆区块。使用上aBFT+DPoS 协议就可以使得 EOS 的出块间隔从原来的3秒降低到500毫秒,这也使得跨链通信的时延大大缩短,单位时间内可确认的交易数量大大提升。
如果网络状况完美,一笔交易被打包后,在0.5秒内就可完全确认。当然,网络不可能一直这么完美,很有可能上一个超级节点出块后,下一个超级节点还没来得及确认这个块,自己就要产生新块了。为避免因出块速度过快而漏块,EOS中21个超级节点的出块顺序是精心确定的。EOS的超级节点按照其他的地理位置依次轮流成为主节点,尽可能减少超级节点的网络延迟。比如超级节点有中国、美国、加拿大、日本,那么成为主节点的顺序是中国>日本>美国>加拿大或者反过来,总之保证相邻最近的超级节点要依次交接主节点角色。
除此之外,还有另外一个机制来避免这一点。在EOS中,虽然出块时间降为0.5秒,但每个超级节点在一轮中连续出 6 个块,也就是说,仍然负责 3 秒时间的出块,只不过是由 1 个块变成了 6 个块。这样,前面几个块肯定有足够时间经过确认,不存在整个超级节点被跳过的现象。可以看出每轮记账节点的出块总时间还是 3 秒钟,在这 3 秒里,因为他对他自己出的块是信任的,所以可以持续出块。一边出块一边广播,3 秒之内率先广播的区块肯定能够得到确认,在网络通畅的情况下,6 个区块都会可能得到确认。
EOS共识处理分叉问题非常简单,和比特币一样,节点只会认可最长的链作为合法链。假如某个节点开始作恶,自己出块并生成自己的链,也就是每次轮到它就产生 6 个块。但是超级节点总共 21 个,每轮产生理论 126 个块。根据选择最长链作为主链原则,肯定作恶的链得不到认可。所以 EOS 不会发生分叉问题。
总结起来,aBFT+DPoS共识算法相比于单纯的DPOS算法的优势在于:
1.一致性和安全性得到提升;
2.出块速度可以更快,吞吐性能更强;
3.BFT提供了不可逆确认功能,这也是跨链通信的关键属性,适合于侧链通信,为EOS的侧链生态构建提供了基础。
2.3 BABE-GRANDPA -- 波卡混合共识协议
波卡被誉为 2020 最受期待的公链项目,其不断攀升的市值也印证了大家的期待。当我们谈到 Polkadot 的共识协议时,大家经常看到两个缩略词,GRANDPA 和 BABE。我们同时提到了这两个词是因为 Polkadot 使用的是混合共识。
Polkadot使用带有两个子协议的混合共识协议:BABE和GRANDPA,合在一起称为“快速转发”。BABE 使用可验证的随机函数(VRF)为验证者分配插槽。GRANDPA 对链投票而不是对单个块投票。BABE可以一起编写候选块以扩展最终链,而GRANDPA可以分批完成它们(一次最多数百万个块)。
2.3.1 BABE
BABE (Blind Assignment for Blockchain Extension)是在验证节点之间运行并确定新块生产者的区块生成机制。BABE 作为一种算法可以与 Ouroboros Praos 相比较,在链选择规则和 slot (验证人插槽)时间调整方面有一些关键的区别。BABE 根据 stake 和使用 Polkadot 随机循环机制将区块生产的 slot 分配给验证人。
BABE中leader的选举是通过一个随机函数(VRF)来实现的,在每个slot阶段,每一个节点会通过运算VRF函数来获得一个数值,如果这个数值小于网络中预先规定好的阈值,那么节点就会认为自己就是这个时间段的leader,于是节点就开始出块了。
值得注意的是在上述的过程中,由于VRF函数是随机生成数字的,所以可能造成在某一slot中没有leader或者有多个节点算出自己的VRF值小于阈值进而产生多个leader的情况。我们依次分析两种情况:
当没有leader产生时,Polkadot就规定按照顺序来决定谁是leader,这个顺序是预先确定好的。
当出现多个leader的时候,Polkadot允许多个节点都提交区块,而最终区块的确认则由GRANDPA来决定。
2.3.2 GRANDPA
GRANDPA(GHOST-based Recursive ANcestor Deriving Prefix Agreement) 是用来做区块确认的,BABE 会对Polkadot的交易进行出块,这些块最终就是由GRANDPA来确定的。
像其他PBFT的衍生算法一样,GRANDPA的时间复杂度也是O(N²)。它在一个部分同步的网络模型中工作,要求 2/3 的节点是诚实的。但是Polkadot之所以采用GRANDPA是因为GRANDPA并不是每次只确认一个区块,它每一次都会确定好几个区块来做确认,所以效率比普通的 PBFT 更高。算法的主要流程如下:
1.一个主节点广播之前一轮确认后的区块高度;
2.等待网络延迟以后,每个节点都广播他们认为的可以被确认的最高的区块(pre-vote);
3.每个节点对步骤2接受到的区块集进行计算,算出他们认为的能够被确认的最高区块,并且将结果广播出去(pre-commit);
4.当节点接收到足够的pre-commit的消息能够确认区块后就会形成commit的消息,一般认为大于2/3就可以被确认了。
通过结合BABE和GRANDPA我们可以看到在出块的时候Polkadot采用BABE出块,此时节点之间只要发送一次块信息即可,这样的话时间复杂度仅仅是O(N),在出块之后节点之间再采用GRANDPA进行块确认,此时由于确认阶段节点之间要通过二次确认来保证确认块结果的一致性,时间复杂度是O(N²),不过由于是多个块一次性进行确认,所以两者结合的混合共识是非常高效的,比普通的PBFT共识要高效很多。
2.4 小 结
PBFT算法由于每个副本节点都需要和其他节点进行P2P的共识同步,因此随着节点的增多,性能会下降的很快,但是在较少节点的情况下可以有不错的性能,并且分叉的几率很低。所以在区块链中,更多应用于联盟链或私有链场景中。如 Fabric 和蚂蚁链。
如果能够结合类似 DPOS 这样的节点代表选举规则的话也可以应用于公链,并且可以在一个不可信的网络里解决拜占庭容错问题,有些公链对此进行了有益的尝试。
为了适应公有链场景中的大规模扩展需求,有不少项目大胆采用了 PBFT,比较知名的有 EOS 链首先采用了 DPoS + aBFT 共识协议,后起之秀波卡采取了 BABE + GRANDPA 的混合共识协议,这两个公链都是先用一些方法在众多的公链节点中选举出参与共识的节点,然后再进行 BFT 共识。采用这种方法会有效减少节点的数量,使性能能够满足公链的需求。所以 BFT 协议在联盟链和公链都可以广泛应用。
本文主要介绍了BFT 协议概念及在区块链的应用,本系列的下集在次条更新,欢迎关注。
本文图片来源于:
刘秋杉. Practical Byzantine Fault Tolerance[EB/OL].2014-09-09.
区块链安全:基于区块链网络攻击的方式原理详解
参考资料
https://academy.binance.com/zh/articles/what-is-social-engineering
https://mp.weixin.qq.com/s/uE_3NhH0mlEejJoUCfEchQ
https://www.jianshu.com/p/5fea30b25f0a
https://www.chainnews.com/articles/066979964730.htm
https://learnblockchain.cn/2019/08/29/pbft/
https://blog.csdn.net/yuanfangyuan_block/article/details/79872614
https://bihu.com/article/1427644620
https://bihu.com/article/1870080193
https://segmentfault.com/a/1190000019011651
https://zhuanlan.zhihu.com/p/42493898
https://colobu.com/2018/11/28/EOS-whitepaper/
https://docs.neo.org/docs/zh-cn/tooldev/consensus/consensus_algorithm.html
https://www.theblockbeats.com/news/2634
https://www.jinse.com/blockchain/397228.html
https://www.idcbest.com/idcnews/11002090.html
https://www.jianshu.com/p/78e2b3d3af62
https://www.chainnews.com/articles/469245604416.htm
https://www.hyperchain.cn/news/282.html
https://people.eecs.berkeley.edu/~luca/cs174/byzantine.pdf
http://pmg.csail.mit.edu/papers/osdi99.pdf
https://www.usenix.org/legacy/events/osdi06/tech/full_papers/cowling/cowling.pdf
https://eprint.iacr.org/2016/199.pdf
https://juejin.cn/post/6844903732736425992
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1643/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1643/
如有侵权请联系:admin#unsafe.sh