这是我把最近学习记录整理成一个帖子,如果阅读不方便可以看
印象笔记链接
Unicorn 是一款非常优秀的跨平台模拟执行框架,该框架可以跨平台执行Arm, Arm64 (Armv8), M68K, Mips, Sparc, & X86 (include X86_64)等指令集的原生程序。
Unicorn 不仅仅是模拟器,更是一种“硬件级”调试器,使用Unicorn的API可以轻松控制CPU寄存器、内存等资源,调试或调用目标二进制代码,现有的反调试手段对Unicorn 几乎是无效的。 目前国内的Unicorn 学习资料尚少,防御手段也稀缺,官方入门教程虽短小精悍缺无法让你快速驾驭强大的Unicorn,故写这一些列文章。这几篇文章将带你学习Unicorn 框架并开发一款支持JNI的原生程序调用框架、o-llvm 还原脚本、静态脱壳机等。
分析基于https://github.com/AeonLucid/AndroidNativeEmu 开源项目做分析。本人能力微薄,冒昧对此项目进行完善,目前已经实现更多的JNI 函数和syscall,完善mmap映射文件等。参考我的项目:
https://github.com/Chenyuxin/AndroidNativeEmu。
我由衷地感谢AndroidNativeEmu 原作者提供函数hook及模拟JNI的思路,我曾日思夜想如何优雅地模拟JNI,没想到该项目的实现方式竟然十分优雅。
我希望通过这一系列的文章,让更多的人学习Unicorn 框架,学习如何模拟调用,也希望厂商重视对Unicorn的检测! 实践中,这都9102年了,我发现目前仍有加固产品能用Unicorn 跑出dex文件!这一些列的文章,不仅会学习Unicorn,还会学习到优秀的反汇编框架Capstone、汇编框架Keystone。
应用场景
Windows & Linux 跨平台调用Android Native 程序、Api监控、病毒分析、获取Code Coverage、加固方案分析、反混淆等。安全防御方面,简化Unicorn,魔改Unicorn,甚至可以打造一款让逆向工作者感觉云里雾里代码保护器。这里列出的应用场景只是冰山一角!
分析360加固的时候使用Unicorn , 反调试清晰可见
检查status和tcp 文件,只需模拟文件系统,就可以绕过。
360加固寻找解压缩函数地址的操作
Native 动态注册

JNI操作一览无余

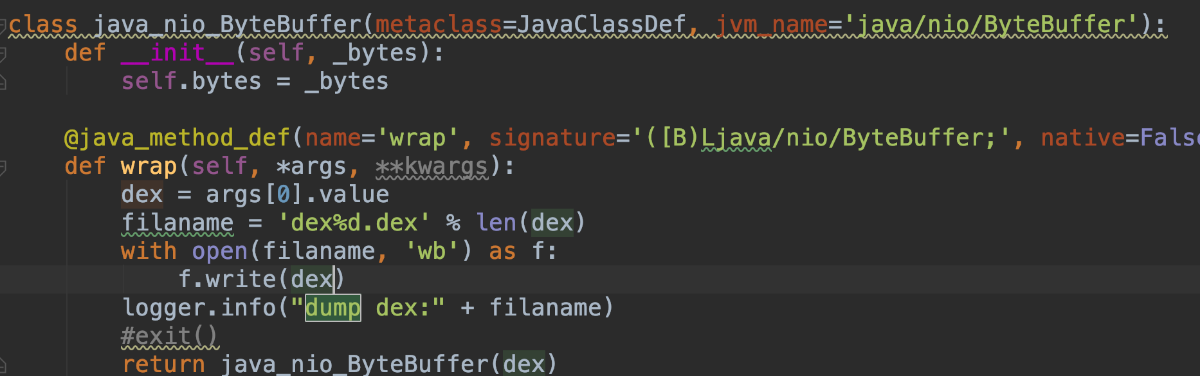
dump 某加固dex

多架构
Unicorn 是一款基于qemu模拟器的模拟执行框架,支持Arm, Arm64 (Armv8), M68K, Mips, Sparc, & X86 (include X86_64)等指令集。
多语言
Unicorn 为多种语言提供编程接口比如C/C++、Python、Java 等语言。Unicorn的DLL 可以被更多的语言调用,比如易语言、Delphi,前途无量。
多线程安全
Unicorn 设计之初就考虑到线程安全问题,能够同时并发模拟执行代码,极大的提高了实用性。
虚拟内存
Unicorn 采用虚拟内存机制,使得虚拟CPU的内存与真实CPU的内存隔离。Unicorn 使用如下API来操作内存:
- uc_mem_map
- uc_mem_read
- uc_mem_write
使用uc_mem_map映射内存的时候,address 与 size 都需要与0x1000对齐,也就是0x1000的整数倍,否则会报UC_ERR_ARG 异常。如何动态分配管理内存并实现libc中的malloc功能将在后面的课程中讲解。Hook 机制
Unicorn的Hook机制为编程控制虚拟CPU提供了便利。
Unicorn 支持多种不同类型的Hook。
大致可以分为(hook_add第一参数,Unicorn常量): 指令执行类
- UC_HOOK_INTR
- UC_HOOK_INSN
- UC_HOOK_CODE
- UC_HOOK_BLOCK
内存访问类
- UC_HOOK_MEM_READ
- UC_HOOK_MEM_WRITE
- UC_HOOK_MEM_FETCH
- UC_HOOK_MEM_READ_AFTER
- UC_HOOK_MEM_PROT
- UC_HOOK_MEM_FETCH_INVALID
- UC_HOOK_MEM_INVALID
- UC_HOOK_MEM_VALID
异常处理类
- UC_HOOK_MEM_READ_UNMAPPED
- UC_HOOK_MEM_WRITE_UNMAPPED
- UC_HOOK_MEM_FETCH_UNMAPPED
调用hook_add函数可添加一个Hook。Unicorn的Hook是链式的,而不是传统Hook的覆盖式,也就是说,可以同时添加多个同类型的Hook,Unicorn会依次调用每一个handler。hook callback 是有作用范围的(见hook_add begin参数)。
python包中的hook_add函数原型如下
def hook_add(self, htype, callback, user_data=None, begin=1, end=0, arg1=0):
pass
- htype 就是Hook的类型,callback是hook回调用;
- callback 是Hook的处理handler指针。请注意!不同类型的hook,handler的参数定义也是不同的。
- user_data 附加参数,所有的handler都有一个user_data参数,由这里传值。
- begin hook 作用范围起始地址
- end hook 作用范围结束地址,默认则作用于所有代码。
Hook callback
不同类型的hook,对应的callback的参数也不相同,这里只给出C语言定义。
Python 编写callback的时候参考C语言即可(看参数)。
UC_HOOK_CODE & UC_HOOK_BLOCK 的callback定义
typedef void (*uc_cb_hookcode_t)(uc_engine *uc, uint64_t address, uint32_t size, void *user_data);
- address: 当前执行的指令地址
- size: 当前指令的长度,如果长度未知,则为0
- user_data: hook_add 设置的user_data参数
READ, WRITE & FETCH 的 callback 定义
typedef void (*uc_cb_hookmem_t)(uc_engine *uc, uc_mem_type type,
uint64_t address, int size, int64_t value, void *user_data);
- type: 内存操作类型 READ, or WRITE
- address: 当前指令地址
- size: 读或写的长度
- value: 写入的值(type = read时无视)
user_data: hook_add 设置的user_data参数
invalid memory access events (UNMAPPED and PROT events) 的 callback 定义
typedef bool (*uc_cb_eventmem_t)(uc_engine *uc, uc_mem_type type, uint64_t address, int size, int64_t value, void *user_data);- type: 内存操作类型 READ, or WRITE
- address: 当前指令地址
- size: 读或写的长度
- value: 写入的值(type = read时无视)
user_data: hook_add 设置的user_data参数
返回值
返回真,继续模拟执行
返回假,停止模拟执行
Unicorn 支持多种编译和安装方式,本课程以Linux作为学习环境,Python3作为主要语言。Linux 下可以直接使用pip安装,方便快捷。
pip install unicorn
更多详细安装过程可以参考
官方安装教程
在python中导入Unicorn库
from unicorn import *
导入处理器相关的常量
Unicorn 支持多种不同的CPU指令集,每一种指令集都有自己独立的寄存器, Unicorn使用统一API管理多种不同的CPU指令集,并将寄存器名字映射成数字常量。
from unicorn.arm_const import * from unicorn.arm64_const import * from unicorn.m68k_const import * from unicorn.mips_const import * from unicorn.sparc_const import * from unicorn.x86_const import *
寄存器常量命名规则
UC_ + 指令集 + REG + 大写寄存器名
UC_ARMREG + 大写寄存器名 (UC_ARM_REG_R0)
UC_X86REG + 大写寄存器名 (UC_X86_REG_EAX)
本课程以python3 + arm指令集为例子,导入arm的常量
from unicorn import * from unicorn.arm_const import *
模拟执行的代码
为了简单起见,我们直接将要执行代码的数据硬编码。
ARM_CODE = b"\x37\x00\xa0\xe3\x03\x10\x42\xe0" # mov r0, #0x37; # sub r1, r2, r3
创建一个UC对象并设置异常处理
# Test ARM
def test_arm():
print("Emulate ARM code")
try:
# Initialize emulator in ARM mode
mu = Uc(UC_ARCH_ARM, UC_MODE_ARM)
# 其它代码添加到此处
except UcError as e:
print("ERROR: %s" % e)
Uc 是unicorn的主类,Uc对象则代表了一个独立的虚拟机实例,它有独立的寄存器和内存等资源,不同Uc对象之间的数据是独立的。Uc的构造函数有两个参数 arch 和 mode,用来指定模拟执行的指令集和对应的位数或模式。
arch常量参数一般以 UCARCH 开头,MODE常量以UCMODE 开头。
同一种指令集可以有多种模式,比如x86可以同时运行32位和16位的汇编,arm也有arm模式和Thumb模式,它们是向下兼容的,并可以通过特殊指令来切换CPU运行模式。 调用构造函数时的模式(mode)以第一条执行指令的模式为准。
映射内存
想用Unicorn模拟执行代码,是不能将代码字节流直接以参数形式传递给Unicorn,而是将要执行的代码写入到Unicorn 的虚拟内存中。Uc 虚拟机实例初始内存是没有任何映射的,在读写内存之前使用uc_mem_map函数映射一段内存。
# map 2MB memory for this emulation ADDRESS = 0x10000 mu.mem_map(ADDRESS, 2 * 0x10000)
这段代码在内存地址0x10000处映射了一段大小为2M的内存。mem_map函数特别娇气,要求 address 和 size 参数都与0x1000对齐,否则会报UC_ERR_ARG异常。
写入代码
我们要执行代码,就需要将欲执行代码的字节数据写入到虚拟机内存中。
mu.mem_write(ADDRESS, ARM_CODE)
mem_write的第二个参数也很娇气,只支持python的byte数组,不能是String或者bytearray。
给寄存器赋值
mu.reg_write(UC_ARM_REG_R0, 0x1234) mu.reg_write(UC_ARM_REG_R2, 0x6789) mu.reg_write(UC_ARM_REG_R3, 0x3333)
添加指令级的Hook
这个有点像单步调试的感觉。
mu.hook_add(UC_HOOK_CODE, hook_code, begin=ADDRESS, end=ADDRESS)
在begin...end范围内的每一条指令被执行前都会调用callback。
让我们来看看hook_code 的实现吧
# callback for tracing instructions
def hook_code(uc, address, size, user_data):
print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" %(address, size))
这段代码仅打印指令执行的地址和长度信息。 实际应用中可配合capstone反汇编引擎玩一些更骚的操作。
UC_HOOK_CODE的callback中可以修改PC或EIP等寄存器力来改变程序运行流程。实际上,unicorn调试器的单步调试就是以这个为基础实现的。
开机
原谅我用开机这个词汇吧!我们已经映射内存并将数据写入到内存,并设置好执行Hook以监视指令是否正常执行,但是虚拟机还没有启动!
# emulate machine code in infinite time mu.emu_start(ADDRESS, ADDRESS + len(ARM_CODE))
emu_start 可以通过timeout参数设置最长执行时长,防止线程死在虚拟机里面。原型如下
def emu_start(self, begin, until, timeout=0, count=0):
pass
emu_start 执行完成后,可以通过读取内存或寄存器的方式来获取执行结果。
获取结果
r0 = mu.reg_read(UC_ARM_REG_R0)
r1 = mu.reg_read(UC_ARM_REG_R1)
print(">>> R0 = 0x%x" % r0)
print(">>> R1 = 0x%x" % r1)
完整代码
from unicorn import *
from unicorn.arm_const import *
ARM_CODE = b"\x37\x00\xa0\xe3\x03\x10\x42\xe0"
# mov r0, #0x37;
# sub r1, r2, r3
# Test ARM
# callback for tracing instructions
def hook_code(uc, address, size, user_data):
print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" %(address, size))
def test_arm():
print("Emulate ARM code")
try:
# Initialize emulator in ARM mode
mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB)
# map 2MB memory for this emulation
ADDRESS = 0x10000
mu.mem_map(ADDRESS, 2 * 0x10000)
mu.mem_write(ADDRESS, ARM_CODE)
mu.reg_write(UC_ARM_REG_R0, 0x1234)
mu.reg_write(UC_ARM_REG_R2, 0x6789)
mu.reg_write(UC_ARM_REG_R3, 0x3333)
mu.hook_add(UC_HOOK_CODE, hook_code, begin=ADDRESS, end=ADDRESS)
# emulate machine code in infinite time
mu.emu_start(ADDRESS, ADDRESS + len(ARM_CODE))
r0 = mu.reg_read(UC_ARM_REG_R0)
r1 = mu.reg_read(UC_ARM_REG_R1)
print(">>> R0 = 0x%x" % r0)
print(">>> R1 = 0x%x" % r1)
except UcError as e:
print("ERROR: %s" % e)
小结
Unicorn 版的Hello world很好展示了Unicorn的使用过程。 美中不足的是,它过于简陋,没有涉及到栈操作、系统调用、API调用等,要知道,现在任何一段代码、一个函数都会至少涉及到其中的一项。
起始
前一篇文章中,我们学习了如何使用Unicorn 来模拟执行一段二进制代码。然而目前Unicorn 对于我们来说,几乎就等同于黑盒子。我们只知输入输出,对于代码中间执行过程的失败与否全然不知,如果出现BUG将难以调试。 为了解决这种难以调试的状况,我决定写一个Unicorn 调试器, 用来调试Unicorn 模拟执行的二进制代码。
功能 & 特性
- 硬件断点
- 读/写 寄存器信息
- 反汇编
- dump 内存
- 单步调试(步入/步过)
- 快速接入各种不同的Unicorn项目
如何实现
Unicorn 提供了强大的指令级Hook(UC_HOOK_CODE), 使得每一条指令执行前,我们都有机会处理。
UC_HOOK_CODE 的callback原型定义如下
typedef void (*uc_cb_hookcode_t)(uc_engine *uc, uint64_t address, uint32_t size, void *user_data);
- address: 当前执行的指令地址
- size: 当前指令的长度,如果长度未知,则为0
- user_data: hook_add 设置的user_data参数
调用hook_add 函数可以为指定的代码范围添加hook的callback。
python包中的hook_add函数原型如下
def hook_add(self, htype, callback, user_data=None, begin=1, end=0, arg1=0):
pass
UC_HOOK_CODE 的功能是每条指令执行前调用callback。
callback中,我们可以通过参数得知指令执行地址、指令执行长度、虚拟机指针。
有了虚拟机指针,我们可以很方便的访问各种寄存器、内存等资源。在UC_HOOK_CODE的callback中,也可以直接修改PC寄存器来改变流程。
调试器要支持的调试指令如下
def show_help(self):
help_info = """
# commands
# set reg <regname> <value>
# set bpt <addr>
# n[ext]
# s[etp]
# r[un]
# dump <addr> <size>
# list bpt
# del bpt <addr>
# stop
# f show ins flow
"""
print (help_info)
本文将编写一个UnicornDebugger 类,调试器的各种功能均在该类中实现, 调用该类的构造函数即可附加到一个Uc虚拟机对象上。
类的定义
class UnicornDebugger:
def __init__(self, mu, mode = UDBG_MODE_ALL):
pass
附加调试器
mu = Uc(UC_ARCH_ARM, UC_MODE_ARM) dbg = udbg.UnicornDebugger(mu, udbg.UDBG_MODE_ALL) dbg.add_bpt(0x1112233) mu.emu_start(......)
可见,这段代码在0x1112233处添加了一个断点,当程序执行到0x1112233处的时候就会停下来,陷入调试器的处理,等待调试者的指令。
反汇编
Unicorn 并没有反汇编功能,虽然它的内部一定有与反汇编相关的代码。我们只能自己想办法反汇编。Unicorn 有一个兄弟,它叫Capstone。Capstone是一款支持多种处理器和开发语言的反汇编框架。Capstone 官方地址 我将使用Capstone 作为调试模块的反汇编器。
安装 Capstone
Capstone 对python的支持特别好,我们的开发语言是python3,所以直接使用pip 安装capstone 即可。
pip install capstone
快速入门 Capstone
Capstone 很强大,也可以很简单, 下面一段代码就是Capstone的入门例子。
from capstone import *
from capstone.arm import *
CODE = b"\xf1\x02\x03\x0e\x00\x00\xa0\xe3\x02\x30\xc1\xe7\x00\x00\x53\xe3"
md = Cs(CS_ARCH_ARM, CS_MODE_ARM)
for i in md.disasm(CODE, 0x1000):
print("%x:\t%s\t%s" %(i.address, i.mnemonic, i.op_str))
上面这段代码的输出如下
1000: mcreq p2, #0, r0, c3, c1, #7 1004: mov r0, #0 1008: strb r3, [r1, r2] 100c: cmp r3, #0
可以看出,Capstone 十分简单, 而我们编写调试器的反汇编部分,也是如此简单。
实现反汇编
def dump_asm(self, addr, size):
md = self._capstone #构造函数中初始化的Capstone对象 Cs(CS_ARCH_ARM, CS_MODE_ARM)
code = self._mu.mem_read(addr, size)
for ins in md.disasm(code, addr):
print("%s:\t%s\t%s" % (self.sym_handler(ins.address), ins.mnemonic, ins.op_str))
dump 内存
Python的hexdump模块的偏移量不支持修改,所以我魔改了hexdump的代码实现了这个功能。
def dump_mem(self, addr, size):
data = self._mu.mem_read(addr, size)
print (advance_dump(data, addr))
魔改的hexdump
def advance_dump(data, base):
PY3K = sys.version_info >= (3, 0)
generator = hexdump.genchunks(data, 16)
retstr = ''
for addr, d in enumerate(generator):
# 00000000:
line = '%08X: ' % (base + addr * 16)
# 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
dumpstr = hexdump.dump(d)
line += dumpstr[:8 * 3]
if len(d) > 8: # insert separator if needed
line += ' ' + dumpstr[8 * 3:]
# ................
# calculate indentation, which may be different for the last line
pad = 2
if len(d) < 16:
pad += 3 * (16 - len(d))
if len(d) <= 8:
pad += 1
line += ' ' * pad
for byte in d:
# printable ASCII range 0x20 to 0x7E
if not PY3K:
byte = ord(byte)
if 0x20 <= byte <= 0x7E:
line += chr(byte)
else:
line += '.'
retstr += line + '\n'
return retstr
寄存器显示
Unicorn中的寄存器都是以常量来管理的,所以我们要把寄存器常量和文本映射起来。
REG_ARM = {arm_const.UC_ARM_REG_R0: "R0",
arm_const.UC_ARM_REG_R1: "R1",
arm_const.UC_ARM_REG_R2: "R2",
arm_const.UC_ARM_REG_R3: "R3",
arm_const.UC_ARM_REG_R4: "R4",
arm_const.UC_ARM_REG_R5: "R5",
arm_const.UC_ARM_REG_R6: "R6",
arm_const.UC_ARM_REG_R7: "R7",
arm_const.UC_ARM_REG_R8: "R8",
arm_const.UC_ARM_REG_R9: "R9",
arm_const.UC_ARM_REG_R10: "R10",
arm_const.UC_ARM_REG_R11: "R11",
arm_const.UC_ARM_REG_R12: "R12",
arm_const.UC_ARM_REG_R13: "R13",
arm_const.UC_ARM_REG_R14: "R14",
arm_const.UC_ARM_REG_R15: "R15",
arm_const.UC_ARM_REG_PC: "PC",
arm_const.UC_ARM_REG_SP: "SP",
arm_const.UC_ARM_REG_LR: "LR"
}
REG_TABLE = {UC_ARCH_ARM: REG_ARM}
........
self._regs = REG_TABLE[self._arch] #根据平台切换寄存器映射表,目前只有ARM
def dump_reg(self):
result_format = ''
count = 0
for rid in self._regs:
rname = self._regs[rid]
value = self._mu.reg_read(rid)
if count < 4:
result_format = result_format + ' ' + rname + '=' + hex(value)
count += 1
else:
count = 0
result_format += '\n' + rname + '=' + hex(value)
print (result_format)
##### 修改寄存器的值
def write_reg(self, reg_name, value):
for rid in self._regs:
rname = self._regs[rid]
if rname == reg_name:
self._mu.reg_write(rid, value)
return
print ("[Debugger Error] Reg not found:%s " % reg_name)
实现单步调试
使用list来记录所有断点的地址,当UC_HOOK_CODE的callback被调用的时候检查address是否在断点列表中,如果当前指令的执行地址没有断点,则直接返回,如果存在断点,则打印寄存器信息、最近的汇编代码、等待用户指令等操作。
单步分为两种:步入、步过。
步入:如果遇到call、bl指令会跟随进入(跟随每一条指令)
步过:遇到call、bl等指令不不进入(跟随每一条地址相邻的指令)
我这个思路可能有点牵强,因为按照地址相邻,会误判跳转指令,但是为了简单起见,我只好这么做。
下面是断点管理相关的代码。
def list_bpt(self):
for idx in range(len(self._list_bpt)):
print ("[%d] %s" % (idx, self.sym_handler(self._list_bpt[idx])))
def add_bpt(self, addr):
self._list_bpt.append(addr)
def del_bpt(self, addr):
self._list_bpt.remove(addr)
callback 中判断断点。
_tmp_bpt 是临时断点, 用于支持步过。
_is_step 步入标记,每条指令都停下来。
def _dbg_trace(mu, address, size, self): #self就是user_info传入
self._tracks.append(address)
if not self._is_step and self._tmp_bpt == 0:#步入 步过
if address not in self._list_bpt:
return
if self._tmp_bpt != address and self._tmp_bpt != 0:
return
处理调试指令
elif command[0] == 's' or command[0] == 'step': # 步入
self._tmp_bpt = 0 # 清除步过标记
self._is_step = True # 设置步入标记
break
elif command[0] == 'n' or command[0] == 'next': # 步过
self._tmp_bpt = address + size # 设置下一条指令地址断点
self._is_step = False # 清除步入标记
break
elif command[0] == 'r' or command[0] == 'run': # 运行
self._tmp_bpt = 0
self._is_step = False
break
完整代码
from unicorn import *
from unicorn import arm_const
import sys
import hexdump
import capstone as cp
BPT_EXECUTE = 1
BPT_MEMREAD = 2
UDBG_MODE_ALL = 1
UDBG_MODE_FAST = 2
REG_ARM = {arm_const.UC_ARM_REG_R0: "R0",
arm_const.UC_ARM_REG_R1: "R1",
arm_const.UC_ARM_REG_R2: "R2",
arm_const.UC_ARM_REG_R3: "R3",
arm_const.UC_ARM_REG_R4: "R4",
arm_const.UC_ARM_REG_R5: "R5",
arm_const.UC_ARM_REG_R6: "R6",
arm_const.UC_ARM_REG_R7: "R7",
arm_const.UC_ARM_REG_R8: "R8",
arm_const.UC_ARM_REG_R9: "R9",
arm_const.UC_ARM_REG_R10: "R10",
arm_const.UC_ARM_REG_R11: "R11",
arm_const.UC_ARM_REG_R12: "R12",
arm_const.UC_ARM_REG_R13: "R13",
arm_const.UC_ARM_REG_R14: "R14",
arm_const.UC_ARM_REG_R15: "R15",
arm_const.UC_ARM_REG_PC: "PC",
arm_const.UC_ARM_REG_SP: "SP",
arm_const.UC_ARM_REG_LR: "LR"
}
REG_TABLE = {UC_ARCH_ARM: REG_ARM}
def str2int(s):
if s.startswith('0x') or s.startswith("0X"):
return int(s[2:], 16)
return int(s)
def advance_dump(data, base):
PY3K = sys.version_info >= (3, 0)
generator = hexdump.genchunks(data, 16)
retstr = ''
for addr, d in enumerate(generator):
# 00000000:
line = '%08X: ' % (base + addr * 16)
# 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
dumpstr = hexdump.dump(d)
line += dumpstr[:8 * 3]
if len(d) > 8: # insert separator if needed
line += ' ' + dumpstr[8 * 3:]
# ................
# calculate indentation, which may be different for the last line
pad = 2
if len(d) < 16:
pad += 3 * (16 - len(d))
if len(d) <= 8:
pad += 1
line += ' ' * pad
for byte in d:
# printable ASCII range 0x20 to 0x7E
if not PY3K:
byte = ord(byte)
if 0x20 <= byte <= 0x7E:
line += chr(byte)
else:
line += '.'
retstr += line + '\n'
return retstr
def _dbg_trace(mu, address, size, self):
self._tracks.append(address)
if not self._is_step and self._tmp_bpt == 0:
if address not in self._list_bpt:
return
if self._tmp_bpt != address and self._tmp_bpt != 0:
return
return _dbg_trace_internal(mu, address, size, self)
def _dbg_memory(mu, access, address, length, value, self):
pc = mu.reg_read(arm_const.UC_ARM_REG_PC)
print ("memory error: pc: %x access: %x address: %x length: %x value: %x" %
(pc, access, address, length, value))
_dbg_trace_internal(mu, pc, 4, self)
mu.emu_stop()
return True
def _dbg_trace_internal(mu, address, size, self):
self._is_step = False
print ("======================= Registers =======================")
self.dump_reg()
print ("======================= Disassembly =====================")
self.dump_asm(address, size * self.dis_count)
while True:
raw_command = input(">")
if raw_command == '':
raw_command = self._last_command
self._last_command = raw_command
command = []
for c in raw_command.split(" "):
if c != "":
command.append(c)
try:
if command[0] == 'set':
if command[1] == 'reg':# set reg regname value
self.write_reg(command[2], str2int(command[3]))
elif command[1] == 'bpt':
self.add_bpt(str2int(command[2]))
else:
print("[Debugger Error]command error see help.")
elif command[0] == 's' or command[0] == 'step':
# self._tmp_bpt = address + size
self._tmp_bpt = 0
self._is_step = True
break
elif command[0] == 'n' or command[0] == 'next':
self._tmp_bpt = address + size
self._is_step = False
break
elif command[0] == 'r' or command[0] == 'run':
self._tmp_bpt = 0
self._is_step = False
break
elif command[0] == 'dump':
if len(command) >= 3:
nsize = str2int(command[2])
else:
nsize = 4 * 16
self.dump_mem(str2int(command[1]), nsize)
elif command[0] == 'list':
if command[1] == 'bpt':
self.list_bpt()
elif command[0] == 'del':
if command[1] == 'bpt':
self.del_bpt(str2int(command[2]))
elif command[0]=='stop':
exit(0)
elif command[0] == 't':
self._castone = self._capstone_thumb
print ("======================= Disassembly =====================")
self.dump_asm(address, size * self.dis_count)
elif command[0] == 'a':
self._castone = self._capstone_arm
print ("======================= Disassembly =====================")
self.dump_asm(address, size * self.dis_count)
elif command[0] == 'f':
print (" == recent ==")
for i in self._tracks[-10:-1]:
print (self.sym_handler(i))
else:
print ("Command Not Found!")
except:
print("[Debugger Error]command error see help.")
class UnicornDebugger:
def __init__(self, mu, mode = UDBG_MODE_ALL):
self._tracks = []
self._mu = mu
self._arch = mu._arch
self._mode = mu._mode
self._list_bpt = []
self._tmp_bpt = 0
self._error = ''
self._last_command = ''
self.dis_count = 5
self._is_step = False
self.sym_handler = self._default_sym_handler
self._capstone_arm = None
self._capstone_thumb = None
if self._arch != UC_ARCH_ARM:
mu.emu_stop()
raise RuntimeError("arch:%d is not supported! " % self._arch)
if self._arch == UC_ARCH_ARM:
capstone_arch = cp.CS_ARCH_ARM
elif self._arch == UC_ARCH_ARM64:
capstone_arch = cp.CS_ARCH_ARM64
elif self._arch == UC_ARCH_X86:
capstone_arch = cp.CS_ARCH_X86
else:
mu.emu_stop()
raise RuntimeError("arch:%d is not supported! " % self._arch)
if self._mode == UC_MODE_THUMB:
capstone_mode = cp.CS_MODE_THUMB
elif self._mode == UC_MODE_ARM:
capstone_mode = cp.CS_MODE_ARM
elif self._mode == UC_MODE_32:
capstone_mode = cp.CS_MODE_32
elif self._mode == UC_MODE_64:
capstone_mode = cp.CS_MODE_64
else:
mu.emu_stop()
raise RuntimeError("mode:%d is not supported! " % self._mode)
self._capstone_thumb = cp.Cs(cp.CS_ARCH_ARM, cp.CS_MODE_THUMB)
self._capstone_arm = cp.Cs(cp.CS_ARCH_ARM, cp.CS_MODE_ARM)
self._capstone = self._capstone_thumb
if mode == UDBG_MODE_ALL:
mu.hook_add(UC_HOOK_CODE, _dbg_trace, self)
mu.hook_add(UC_HOOK_MEM_UNMAPPED, _dbg_memory, self)
mu.hook_add(UC_HOOK_MEM_FETCH_PROT, _dbg_memory, self)
self._regs = REG_TABLE[self._arch]
def dump_mem(self, addr, size):
data = self._mu.mem_read(addr, size)
print (advance_dump(data, addr))
def dump_asm(self, addr, size):
md = self._capstone
code = self._mu.mem_read(addr, size)
count = 0
for ins in md.disasm(code, addr):
if count >= self.dis_count:
break
print("%s:\t%s\t%s" % (self.sym_handler(ins.address), ins.mnemonic, ins.op_str))
def dump_reg(self):
result_format = ''
count = 0
for rid in self._regs:
rname = self._regs[rid]
value = self._mu.reg_read(rid)
if count < 4:
result_format = result_format + ' ' + rname + '=' + hex(value)
count += 1
else:
count = 0
result_format += '\n' + rname + '=' + hex(value)
print (result_format)
def write_reg(self, reg_name, value):
for rid in self._regs:
rname = self._regs[rid]
if rname == reg_name:
self._mu.reg_write(rid, value)
return
print ("[Debugger Error] Reg not found:%s " % reg_name)
def show_help(self):
help_info = """
# commands
# set reg <regname> <value>
# set bpt <addr>
# n[ext]
# s[etp]
# r[un]
# dump <addr> <size>
# list bpt
# del bpt <addr>
# stop
# a/t change arm/thumb
# f show ins flow
"""
print (help_info)
def list_bpt(self):
for idx in range(len(self._list_bpt)):
print ("[%d] %s" % (idx, self.sym_handler(self._list_bpt[idx])))
def add_bpt(self, addr):
self._list_bpt.append(addr)
def del_bpt(self, addr):
self._list_bpt.remove(addr)
def get_tracks(self):
for i in self._tracks[-100:-1]:
#print (self.sym_handler(i))
pass
return self._tracks
def _default_sym_handler(self, address):
return hex(address)
def set_symbol_name_handler(self, handler):
self.sym_handler = handler
使用UnicornDebugger调试上一篇文章中的代码
from unicorn import *
from unicorn.arm_const import *
THUMB = b"\x83\xb0\x83\xb0\x83\xb0"
# sub sp, #0xc
# sub sp, #0xc
# sub sp, #0xc
def test_arm():
print("Emulate Thumb code")
try:
# Initialize emulator in ARM mode
mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB)
# map 2MB memory for this emulation
ADDRESS = 0x10000
mu.mem_map(ADDRESS, 2 * 0x10000)
mu.mem_write(ADDRESS, THUMB)
mu.reg_write(UC_ARM_REG_SP, 0x1234)
mu.reg_write(UC_ARM_REG_R2, 0x6789)
#debugger attach
udbg = UnicornDebugger(mu)
udbg.add_bpt(ADDRESS)
# emulate machine code in infinite time
mu.emu_start(ADDRESS, ADDRESS + len(THUMB))
r0 = mu.reg_read(UC_ARM_REG_SP)
r1 = mu.reg_read(UC_ARM_REG_R1)
print(">>> SP = 0x%x" % r0)
print(">>> R1 = 0x%x" % r1)
except UcError as e:
print("ERROR: %s" % e)
断点停下来后效果如下
Emulate Thumb code ======================= Registers ======================= R0=0x0 R1=0x0 R2=0x6789 R3=0x0 R4=0x0 R5=0x0 R6=0x0 R7=0x0 R8=0x0 R9=0x0 R10=0x0 R11=0x0 R12=0x0 SP=0x1234 LR=0x0 PC=0x10000 ======================= Disassembly ===================== 0x10000: sub sp, #0xc 0x10002: sub sp, #0xc 0x10004: sub sp, #0xc 0x10006: movs r0, r0 0x10008: movs r0, r0 0x1000a: movs r0, r0 0x1000c: movs r0, r0 0x1000e: movs r0, r0 0x10010: movs r0, r0 0x10012: movs r0, r0 >输入命令
小结
本篇文章仅仅实现了一个ARM/Thumb调试器,能满足一些基本调试,很多地方仍需改进。其它架构的也可以按照类似方法设计!与传统的调试器断点相比,UnicornDebugger采用的是一种类似硬件断点的技术,Unicorn的指令级Hook 难以被模拟执行的代码检测到。UnicornDebugger从一个很低的level去调试程序,这有点像是硬件调试器了!基于时间的反调试无济于事,因为unicorn 可以读写任何一条指令或则API的执行结果。也不能通过检测status或其它系统特性检测调试器,因为UnicornDebugger不属于操作系统的调试体系。Unicorn 的虚拟机中没有运行任何操作系统,基于系统特性检测虚拟机的方法也是无效的!UnicornDebugger 借助Unicorn 接口,站在上帝视角调试程序,很无敌!
Android是基于Linux开发的,Android Native原生库是ELF文件格式。Unicorn 并不能加载ELF文件,所以我们要自己将ELF文件加载到Unicorn虚拟机的内存中去。 加载ELF 文件是一个很复杂的过程,涉及到ELF文件解析、重定位、符号解析、依赖库加载等。
python 可以使用elftools库解析ELF 文件。
elftools 安装
pip install pyelftools
映射ELF 文件
ELF 文件有两种视图,链接视图和执行视图。elftools 是基于链接视图解析ELF格式的,然而现在有一些ELF文件的section信息是被抹掉的,elftools就无法正常工作,我也没时间重写一个elf loader,就只能凑合用一下elftools。
我已经在前面一篇文章介绍了内存分配方面的东西,加载ELF文件第一步需要将ELF文件映射到内存。如何映射呢?只需要找到类型为PT_LOAD的segment,按照segment的信息映射即可。
代码如下:
# - LOAD (determinate what parts of the ELF file get mapped into memory)
load_segments = [x for x in elf.iter_segments() if x.header.p_type == 'PT_LOAD']
for segment in load_segments:
prot = UC_PROT_ALL
self.emu.memory.mem_map(load_base + segment.header.p_vaddr, segment.header.p_memsz, prot)
self.emu.memory.mem_write(load_base + segment.header.p_vaddr, segment.data())
解析 init_array
ELF 的有一个列表,用于存储初始化函数地址,在动态链接的时候,linker会依次调用init_array中的每一个函数。init_array 中的函数一般用于初始化程序,偶尔也有ELF外壳程序在init_array中添加自解密代码,另外有一些字符串解密也是在init_array中完成的。想要模拟native程序,必然需要调用init_array 中的函数。
init_array 是一个数组, 一般情况下,每一项都是函数入口偏移, 然而也有为0的情况。因为init_array实际解析时机在重定位完成之后, init_array 也可能被重定位。 所以要解析init_array的时候还需要判断重定位表。
我的策略是,当读出init_array中为0的条目的时候就去重定位表中查找重定位值。
for _ in range(int(init_array_size / 4)):
# covert va to file offset
for seg in load_segments:
if seg.header.p_vaddr <= init_array_offset < seg.header.p_vaddr + seg.header.p_memsz:
init_array_foffset = init_array_offset - seg.header.p_vaddr + seg.header.p_offset
fstream.seek(init_array_foffset)
data = fstream.read(4)
fun_ptr = struct.unpack('I', data)[0]
if fun_ptr != 0:
# fun_ptr += load_base
init_array.append(fun_ptr + load_base)
print ("find init array for :%s %x" % (filename, fun_ptr))
else:
# search in reloc
for rel in rel_section.iter_relocations():
rel_info_type = rel['r_info_type']
rel_addr = rel['r_offset']
if rel_info_type == arm.R_ARM_ABS32 and rel_addr == init_array_offset:
sym = dynsym.get_symbol(rel['r_info_sym'])
sym_value = sym['st_value']
init_array.append(load_base + sym_value)
print ("find init array for :%s %x" % (filename, sym_value))
break
init_array_offset += 4
解析符号
32位ELF文件 symbol table entry 的定义如下。
typedef struct {
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
} Elf32_Sym;
当st_shndx字段的值为SHN_UNDEF时,表明该符号在当前模块没有定义,是一个导入符号,要去其它模块查找。为了便于管理已经加载模块的符号地址,应该用一个map,将name和address映射起来。
其它情况,简单起见,均看成导出符号,将地址重定位后加入到管理符号map。
# Resolve all symbols.
symbols_resolved = dict()
for section in elf.iter_sections():
if not isinstance(section, SymbolTableSection):
continue
itersymbols = section.iter_symbols()
next(itersymbols) # Skip first symbol which is always NULL.
for symbol in itersymbols:
symbol_address = self._elf_get_symval(elf, load_base, symbol)
if symbol_address is not None:
symbols_resolved[symbol.name] = SymbolResolved(symbol_address, symbol)
def _elf_get_symval(self, elf, elf_base, symbol):
if symbol.name in self.symbol_hooks:
return self.symbol_hooks[symbol.name]
if symbol['st_shndx'] == 'SHN_UNDEF': # 外部符号
# External symbol, lookup value.
target = self._elf_lookup_symbol(symbol.name)
if target is None:
# Extern symbol not found
if symbol['st_info']['bind'] == 'STB_WEAK':
# Weak symbol initialized as 0
return 0
else:
logger.error('=> Undefined external symbol: %s' % symbol.name)
return None
else:
return target
elif symbol['st_shndx'] == 'SHN_ABS':
# Absolute symbol.
return elf_base + symbol['st_value']
else:
# Internally defined symbol.
return elf_base + symbol['st_value']
重定位
# Relocate.
for section in elf.iter_sections():
if not isinstance(section, RelocationSection):
continue
#for relsection in elf.get_dynmic_rel():
for rel in section.iter_relocations():
sym = dynsym.get_symbol(rel['r_info_sym'])
sym_value = sym['st_value']
rel_addr = load_base + rel['r_offset'] # Location where relocation should happen
rel_info_type = rel['r_info_type']
# Relocation table for ARM
if rel_info_type == arm.R_ARM_ABS32:
# Create the new value.
value = load_base + sym_value
# Write the new value
self.emu.mu.mem_write(rel_addr, value.to_bytes(4, byteorder='little'))
elif rel_info_type == arm.R_ARM_GLOB_DAT or \
rel_info_type == arm.R_ARM_JUMP_SLOT or \
rel_info_type == arm.R_AARCH64_GLOB_DAT or \
rel_info_type == arm.R_AARCH64_JUMP_SLOT:
# Resolve the symbol.
if sym.name in symbols_resolved:
value = symbols_resolved[sym.name].address
# Write the new value
self.emu.mu.mem_write(rel_addr, value.to_bytes(4, byteorder='little'))
elif rel_info_type == arm.R_ARM_RELATIVE or \
rel_info_type == arm.R_AARCH64_RELATIVE:
if sym_value == 0:
# Load address at which it was linked originally.
value_orig_bytes = self.emu.mu.mem_read(rel_addr, 4)
value_orig = int.from_bytes(value_orig_bytes, byteorder='little')
# Create the new value
value = load_base + value_orig
# Write the new value
self.emu.mu.mem_write(rel_addr, value.to_bytes(4, byteorder='little'))
else:
raise NotImplementedError()
else:
logger.error("Unhandled relocation type %i." % rel_info_type)
Unicorn 采用虚拟内存机制,使得虚拟CPU的内存与真实CPU的内存隔离。Unicorn 使用如下API来操作内存:
- uc_mem_map
- uc_mem_read
- uc_mem_write
使用uc_mem_map映射内存的时候,address 与 size 都需要与0x1000对齐,也就是0x1000的整数倍,否则会报UC_ERR_ARG 异常。
内存对齐
UC_MEM_ALIGN = 0x1000
Unicorn map的内存基地址和长度都需要对齐到0x1000,对齐函数如下
# Thansk to https://github.com/lunixbochs/usercorn/blob/master/go/mem.go
def align(addr, size, growl):
to = ctypes.c_uint64(UC_MEM_ALIGN).value
mask = ctypes.c_uint64(0xFFFFFFFFFFFFFFFF).value ^ ctypes.c_uint64(to - 1).value
right = addr + size
right = (right + to - 1) & mask
addr &= mask
size = right - addr
if growl:
size = (size + to - 1) & mask
return addr, size
在 Unicorn 虚拟机中分配内存(用于加载模块)
Memory类用于分配内存
class Memory:
"""
:type emu androidemu.emulator.Emulator
"""
def __init__(self, emu):
self.emu = emu
self.counter_memory = config.BASE_ADDR
self.counter_stack = config.STACK_ADDR + config.STACK_SIZE
def mem_reserve(self, size):
(_, size_aligned) = align(0, size, True)
ret = self.counter_memory
self.counter_memory += size_aligned
return ret
def mem_map(self, address, size, prot):
(address, size) = align(address, size, True)
self.emu.mu.mem_map(address, size, prot)
logger.debug("=> Mapping memory page 0x%08x - 0x%08x, size 0x%08x, prot %s" % (address, address + size, size,
prot))
def mem_write(self, address, data):
self.emu.mu.mem_write(address, data)
def mem_read(self, address, size):
return self.emu.mu.mem_read(address, size)
heap 的实现
为了对malloc和free等函数提供支持,需要实现heap。 可喜可贺,Afl-Unicorn 开源项目中已经有一个heap例子,可以直接使用。
heap 实现代码
from unicorn import *
from unicorn.arm64_const import *
# Page size required by Unicorn
UNICORN_PAGE_SIZE = 0x1000
# Max allowable segment size (1G)
MAX_ALLOWABLE_SEG_SIZE = 1024 * 1024 * 1024
# Alignment functions to align all memory segments to Unicorn page boundaries (4KB pages only)
ALIGN_PAGE_DOWN = lambda x: x & ~(UNICORN_PAGE_SIZE - 1)
ALIGN_PAGE_UP = lambda x: (x + UNICORN_PAGE_SIZE - 1) & ~(UNICORN_PAGE_SIZE-1)
# Implementation from
# https://github.com/Battelle/afl-unicorn/blob/44a50c8a9426ffe4ad8714ef8a35dc011e62f739/unicorn_mode/helper_scripts/unicorn_loader.py#L45
class UnicornSimpleHeap:
""" Use this class to provide a simple heap implementation. This should
be used if malloc/free calls break things during emulation.
"""
# Helper data-container used to track chunks
class HeapChunk(object):
def __init__(self, data_addr, data_size):
self.data_addr = data_addr
self.data_size = data_size
# Returns true if the specified buffer is completely within the chunk, else false
def is_buffer_in_chunk(self, addr, size):
if addr >= self.data_addr and ((addr + size) <= (self.data_addr + self.data_size)):
return True
else:
return False
_uc = None # Unicorn engine instance to interact with
_chunks = [] # List of all known chunks
_debug_print = False # True to print debug information
def __init__(self, uc, heap_min_addr, heap_max_addr, debug_print=False):
self._uc = uc
self._heap_min_addr = heap_min_addr
self._heap_max_addr = heap_max_addr
self._debug_print = debug_print
# Add the watchpoint hook that will be used to implement psuedo-guard page support
# self._uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, self.__check_mem_access)
def malloc(self, size, prot=UC_PROT_READ | UC_PROT_WRITE):
# Figure out the overall size to be allocated/mapped
# - Allocate at least 1 4k page of memory to make Unicorn happy
data_size = ALIGN_PAGE_UP(size)
# Gross but efficient way to find space for the chunk:
chunk = None
for addr in range(self._heap_min_addr, self._heap_max_addr, UNICORN_PAGE_SIZE):
try:
self._uc.mem_map(addr, data_size, prot)
chunk = self.HeapChunk(addr, data_size)
if self._debug_print:
print("Allocating 0x{0:x}-byte chunk @ 0x{1:016x}".format(chunk.data_size, chunk.data_addr))
break
except UcError as e:
continue
# Something went very wrong
if chunk is None:
raise Exception("Oh no.")
self._chunks.append(chunk)
return chunk.data_addr
def calloc(self, size, count):
# Simple wrapper around malloc with calloc() args
return self.malloc(size * count)
def realloc(self, ptr, new_size):
# Wrapper around malloc(new_size) / memcpy(new, old, old_size) / free(old)
if self._debug_print:
print("Reallocating chunk @ 0x{0:016x} to be 0x{1:x} bytes".format(ptr, new_size))
old_chunk = None
for chunk in self._chunks:
if chunk.data_addr == ptr:
old_chunk = chunk
new_chunk_addr = self.malloc(new_size)
if old_chunk is not None:
self._uc.mem_write(new_chunk_addr, str(self._uc.mem_read(old_chunk.data_addr, old_chunk.data_size)))
self.free(old_chunk.data_addr)
return new_chunk_addr
def protect(self, addr, len_in, prot):
for chunk in self._chunks:
if chunk.is_buffer_in_chunk(addr, len_in):
# self._uc.mem_protect(chunk.data_addr, chunk.data_size, perms=prot)
return True
return False
def free(self, addr):
for chunk in self._chunks:
if chunk.is_buffer_in_chunk(addr, 1):
if self._debug_print:
print("Freeing 0x{0:x}-byte chunk @ 0x{0:016x}".format(chunk.data_addr, chunk.data_size))
self._uc.mem_unmap(chunk.data_addr, chunk.data_size)
self._chunks.remove(chunk)
return True
return False
处理内存管理方面的syscall
native程序可能直接通过syscall调用mmap2 映射内存。libc等库最底层也一定会调用mmap2分配内存。
self._syscall_handler.set_handler(0x5B, "munmap", 2, self._handle_munmap) self._syscall_handler.set_handler(0x7D, "mprotect", 3, self._handle_mprotect) self._syscall_handler.set_handler(0xC0, "mmap2", 6, self._handle_mmap2) self._syscall_handler.set_handler(0xDC, "madvise", 3, self._handle_madvise)
mmap2 实际并不是一个纯粹的内存管理函数,它还能映射文件到内存,这就涉及到文件系统的支持。我在原作者的基础上进行了修改。
def _handle_mmap2(self, mu, addr, length, prot, flags, fd, offset):
"""
void *mmap2(void *addr, size_t length, int prot, int flags, int fd, off_t pgoffset);
"""
# MAP_FILE 0
# MAP_SHARED 0x01
# MAP_PRIVATE 0x02
# MAP_FIXED 0x10
# MAP_ANONYMOUS 0x20
prot = UC_PROT_ALL
addr = self._heap.malloc(length, prot)
if fd != 0xffffffff: # 如果有fd
if fd <= 2:
raise NotImplementedError("Unsupported read operation for file descriptor %d." % fd)
if fd not in self._file_system._file_descriptors:
# TODO: Return valid error.
raise NotImplementedError()
file = self._file_system._file_descriptors[fd]
data = open(file.name_virt, 'rb').read(length)
self._mu.mem_write(addr, data)
return addr
hook libc中的内存管理函数.
既然我们的框架支持加载多个lib库,直接加载libc就可以了,为何还需要hook libc中的这些符号呢?
实际上,目前的模拟框架并不完善,很多系统信息模拟不到位,libc初始化不完善,使用libc的malloc经常会出现异常。所以直接接替为内置的heap 管理器。
#memory
modules.add_symbol_hook('malloc', hooker.write_function(self.malloc) + 1)
modules.add_symbol_hook('free', hooker.write_function(self.free) + 1)
modules.add_symbol_hook('calloc', hooker.write_function(self.calloc) + 1)
内存访问属性
我们知道,常见的内存权限有可读可写可执行, 一般可以调用mprotect 函数修改指定内存页面的权限。为了方便,我们将所有内存设置为可读可写可执行。
很多情况下,有一些系统API无法直接调用,就需要手动实现它,比如以下应用场景:
1、在libc没有完全初始化的情况下,直接调用malloc 可能会崩溃, 为了使程序更加稳定,就需要自己实现malloc和free。
2、实现dlopen,就可以使用框架的模块管理器来加载模块,而不用linker。
3、打出dlopen、dlsym等函数的日志,还可以分析native程序运行过程中会调用的API。
4、360加固,在反调试完成后,它会调用dlopen加载libz.so,并调用uncompress函数解压数据。 hook uncompress 就可以拿到解压的数据。
5、目前,许多加固的整体加固会调用art中的api来加载dex文件,如果这些函数被Hook,那么就可以直接拿到dex文件,岂不美哉?
6、JNI Functions 实现,需要Hook 技术支撑。
不幸的是,Unicorn 内部并没有函数的概念,它只是一个单纯的CPU, 没有HOOK_FUNCTION的callback, Hook 函数看上去困难重重。AndroidNativeEmu 为我们提供了一个很好的Hook思路。
AndroidNativeEmu 中的函数级Hook 并不是真正意义上的Hook,它不仅能Hook存在的函数,还能Hook不存在的函数。AndroidNativeEmu 使用这种技术实现了JNI函数Hook、库函数Hook。 Jni函数是不存的,Hook它只是为了能够用Python 实现 Jni Functions。有一些库函数是存在的,Hook只是为了重新实现它。
用 Python 实现 Unicorn 虚拟机内部的函数
用 Python 实现 Unicorn 虚拟机内部的函数,首先要解决 Unicorn 虚拟机内部如何与外部交互。AndroidNativeEmu 的实现类似于系统调用,它会为每一个Hook函数实现一个stub函数,stub函数中有一条“陷阱”指令,当虚拟CPU执行这一条”陷阱“指令的时候就会被HOOK_CODE 捕获,然后通过R4寄存器的值确定Python 的处理函数。
stub 函数代码如下:
PUSH {R4,LR}
MOV R4, Number
IT AL
POP {R4,PC}
HOOK_CODE的callback 直接检测PC寄存器指向内存的字节数据是否为"\xE8\xBF"来判断IT AL指令。如果是IT AL指令,则根据R4寄存器的值确定Python 回调的函数。
Native程序中可能会有许多IT AL指令,会误判吗?
HOOK_CODE 会trace每一条指令,这种方式效率岂不是很低?
这两个问题都很好解决,因为HOOK_CODE是有作用范围的,如果开辟一段空间,完全用于存放stub,然后将该callback设置在这个空间范围内,就可以很好的避免了冲突和效率问题!
def _hook(self, mu, address, size, user_data):
# Check if instruction is "IT AL"
if size != 2 or self._emu.mu.mem_read(address, size) != b"\xE8\xBF":
return
# Find hook.
hook_id = self._emu.mu.reg_read(UC_ARM_REG_R4)
hook_func = self._hooks[hook_id]
# Call hook.
try:
hook_func(self._emu)
except:
# Make sure we catch exceptions inside hooks and stop emulation.
mu.emu_stop()
raise
使用 keystone 动态编译 stub
Keystone 是一款很牛逼的汇编框架,Unicorn的兄弟!
使用pip安装
pip install keystone
keystone 使用方法十分简单,不需要额外学习即可理解接下来的代码。write_function函数将python的func函数映射到Unicorn虚拟机,并返回虚拟机中的函数地址, 如果在虚拟机中调用该地址就会被Python捕获并调用func函数。
def write_function(self, func):
# Get the hook id.
hook_id = self._get_next_id()
hook_addr = self._hook_current
# Create the ARM assembly code.
# Make sure to update STACK_OFFSET if you change the PUSH/POP.
asm = "PUSH {R4,LR}\n" \
"MOV R4, #" + hex(hook_id) + "\n" \
"IT AL\n" \
"POP {R4,PC}"
asm_bytes_list, asm_count = self._keystone.asm(bytes(asm, encoding='ascii'))
if asm_count != 4:
raise ValueError("Expected asm_count to be 4 instead of %u." % asm_count)
# Write assembly code to the emulator.
self._emu.mu.mem_write(hook_addr, bytes(asm_bytes_list))
# Save results.
self._hook_current += len(asm_bytes_list)
self._hooks[hook_id] = func
return hook_addr
symbol hook
上一个小结中讲到如何实现stub,那么如何hook 呢?AndroidNativeEmu实现了Symbol Hook。这种HOOK与平时常见的IAT HOOK、GOT Hook 原理是一样的。 调用add_symbol_hook函数,可以将符号和新地址关联起来, 模块加载的时候,查找符号优先从该表中获取地址。 这种实现方式有点bug,比如有一些Native 程序,自身会got hook,那么这种方式可能就会出问题。
例子:使用Hook 实现 AAssetManager_open
modules.add_symbol_hook('AAssetManager_open', hooker.write_function(self.AAssetManager_open) + 1)
@native_method
def AAssetManager_open(self, mu, mgr, filename_ptr, mode):
filename = memory_helpers.read_utf8(mu, filename_ptr)
filename = "assert/" + filename
logger.info("AAssetManager_open(%s,%d)" % (filename, mode))
fd = self._open_file(filename, 0, mode)
if fd == -1:
fd = 0
return fd
python 实现 Native 函数修饰 @native_method
大家可能对Python 装饰器的语法不太熟悉,可以参考廖雪峰老师博客:Python 装饰器
简单的讲,装饰器可以自定义修改函数,为目标函数套一层外壳。native_method主要功能是处理参数数据,这样就能很优雅地编写Native 函数,不用再函数中冗杂地调用寄存器读写函数。
def native_method(func):
def native_method_wrapper(*argv):
"""
:type self
:type emu androidemu.emulator.Emulator
:type mu Uc
"""
emu = argv[1] if len(argv) == 2 else argv[0]
mu = emu.mu
args = inspect.getfullargspec(func).args # 判断参数个数
args_count = len(args) - (2 if 'self' in args else 1)
if args_count < 0:
raise RuntimeError("NativeMethod accept at least (self, mu) or (mu).")
native_args = []
if args_count >= 1: # 从寄存器取参数
native_args.append(mu.reg_read(UC_ARM_REG_R0))
if args_count >= 2:
native_args.append(mu.reg_read(UC_ARM_REG_R1))
if args_count >= 3:
native_args.append(mu.reg_read(UC_ARM_REG_R2))
if args_count >= 4:
native_args.append(mu.reg_read(UC_ARM_REG_R3))
sp = mu.reg_read(UC_ARM_REG_SP) # 参数大于4个,从栈中取参数
sp = sp + STACK_OFFSET # Need to offset by 4 because our hook pushes one register on the stack.
if args_count >= 5:
for x in range(0, args_count - 4):
native_args.append(int.from_bytes(mu.mem_read(sp + (x * 4), 4), byteorder='little'))
if len(argv) == 1:
result = func(mu, *native_args)
else:
result = func(argv[0], mu, *native_args)
if result is not None:
native_write_arg_register(emu, UC_ARM_REG_R0, result)
else:
mu.reg_write(UC_ARM_REG_R0, JNI_ERR)
return native_method_wrapper
小结
这篇文章讲了如何实现 Unicorn 内部的函数级Hook,原理是在模块加载重定位阶段,填充stub函数地址到目标函数的 got表。 stub函数是Unicorn 内部环境与外部环境的一个桥梁,使用小巧的IT AL和R4寄存器实现交互,像极了系统调用。使用Python的装饰器,简化了Python 编写Hook 函数的难度。
系统调用是操作系统给应用程序提供的最底层的基础接口。应用程序读写文件、访问网络等操作都需要操作系统支持。
Unicorn 拦截系统调用只需要添加UC_HOOK_INTR的callback,该callback的参数定义如下:
typedef void (*uc_cb_hookintr_t)(uc_engine *uc, uint32_t intno, void *user_data);
- intno: 中断号
- user_data: user data
我们只需要用hook_add 添加一个 UC_HOOK_INTR 的callback 就能够处理中断了。根据intno 中断号分发不同的中断处理函数。
实现getpid
self._syscall_handler.set_handler(0xe0, "getpid", 0, self._getPid)
def _getpid(self, mu):
return 0x1122
实现文件系统需要拦截的syscall
我们将在文件系统章节详细讨论如何实现文件系统。
syscall_handler.set_handler(0x3, "read", 3, self._handle_read) syscall_handler.set_handler(0x4, "write", 3, self._handle_write) syscall_handler.set_handler(0x5, "open", 3, self._handle_open) syscall_handler.set_handler(0x6, "close", 1, self._handle_close) syscall_handler.set_handler(0x92, "writev", 3, self._handle_writev) syscall_handler.set_handler(0xC5, "fstat64", 2, self._handle_fstat64) syscall_handler.set_handler(0x142, "openat", 4, self._handle_openat) syscall_handler.set_handler(0x147, "fstatat64", 4, self._handle_fstatat64) syscall_handler.set_handler(0x14e, "faccessat", 4, self._faccessat) syscall_handler.set_handler(0x14d, "fchmodat", 4, self._fchmodat) syscall_handler.set_handler(0x8c, "_llseek", 5, self._llseek) syscall_handler.set_handler(0x13, "lseek", 3, self._lseek)
实现内存管理的syscall
self._syscall_handler.set_handler(0x5B, "munmap", 2, self._handle_munmap) self._syscall_handler.set_handler(0x7D, "mprotect", 3, self._handle_mprotect) self._syscall_handler.set_handler(0xC0, "mmap2", 6, self._handle_mmap2) self._syscall_handler.set_handler(0xDC, "madvise", 3, self._handle_madvise)
其它杂项syscall
这些实现都非常的简单,就不过多展开了。
self._syscall_handler.set_handler(0x4E, "gettimeofday", 2, self._handle_gettimeofday) self._syscall_handler.set_handler(0xAC, "prctl", 5, self._handle_prctl) self._syscall_handler.set_handler(0xF0, "futex", 6, self._handle_futex) self._syscall_handler.set_handler(0x107, "clock_gettime", 2, self._handle_clock_gettime) self._syscall_handler.set_handler(0x119, "socket", 3, self._socket) self._syscall_handler.set_handler(0x11b, "connect", 3, self._connect) self._syscall_handler.set_handler(0x159, "getcpu", 3, self._getcpu) self._syscall_handler.set_handler(0x14e, "faccessat", 4, self._faccessat) self._syscall_handler.set_handler(0x14, "getpid", 0, self._getpid) self._syscall_handler.set_handler(0xe0, "gettid", 0, self._gettid) self._syscall_handler.set_handler(0x180, "null1", 0, self._null) self._syscall_handler.set_handler(0x7e, "sigprocmask", 0, self._null) self._syscall_handler.set_handler(0xaf, "rt_sigprocmask", 0, self._null) self._syscall_handler.set_handler(0x10c, "sigaction", 0, self._tgkill) self._syscall_handler.set_handler(0x43, "sigaction", 0, self._sigaction) self._syscall_handler.set_handler(0xf8, "exit", 0, self._null) self._syscall_handler.set_handler(0x16e, "accept4", 0, self.accept4)
如果想尽可能完美的模拟Android Native程序,那就必须加入虚拟文件系统的支持。虚拟文件系统可以将Unicorn 虚拟机内部访问文件的操作映射到主机。
思路
Hook 拦截文件操作相关的系统调用,转换成对主机的文件操作。
为了安全性,我们要在主机上划分一个用于专门虚拟文件系统的目录。 处理系统调用的时候,将路径转换成虚拟文件系统目录的路径。
实现
需要处理的syscall已经在上一篇文章介绍过了
syscall_handler.set_handler(0x3, "read", 3, self._handle_read) syscall_handler.set_handler(0x4, "write", 3, self._handle_write) syscall_handler.set_handler(0x5, "open", 3, self._handle_open) syscall_handler.set_handler(0x6, "close", 1, self._handle_close) syscall_handler.set_handler(0x92, "writev", 3, self._handle_writev) syscall_handler.set_handler(0xC5, "fstat64", 2, self._handle_fstat64) syscall_handler.set_handler(0x142, "openat", 4, self._handle_openat) syscall_handler.set_handler(0x147, "fstatat64", 4, self._handle_fstatat64) syscall_handler.set_handler(0x14e, "faccessat", 4, self._faccessat) syscall_handler.set_handler(0x14d, "fchmodat", 4, self._fchmodat) syscall_handler.set_handler(0x8c, "_llseek", 5, self._llseek) syscall_handler.set_handler(0x13, "lseek", 3, self._lseek)
_handle_open 处理 open syscall
def _handle_open(self, mu, filename_ptr, flags, mode):
"""
int open(const char *pathname, int flags, mode_t mode);
return the new file descriptor, or -1 if an error occurred (in which case, errno is set appropriately).
"""
filename = memory_helpers.read_utf8(mu, filename_ptr)
return self._open_file(filename, flags, mode)
进一步分析_open_file
这个函数先对路径进行一些简单检验,判断是否为特殊文件,如果不是,则调用translate_path转换安全路径,并调用os.open打开本地文件,最后调用_store_fd转换文件句柄。
def _open_file(self, filename, flags, mode):
# Special cases, such as /dev/urandom.
orig_filename = filename
if filename == '/dev/urandom':
logger.info("File opened '%s'" % filename)
return self._store_fd('/dev/urandom', None, 'urandom')
file_path = self.translate_path(filename)
if os.path.isfile(file_path):
logger.info("File opened '%s'" % orig_filename)
flags = os.O_RDWR
if hasattr(os, "O_BINARY"):
flags = os.O_BINARY
return self._store_fd(orig_filename, file_path, os.open(file_path, flags=flags))
else:
logger.warning("File does not exist '%s'" % orig_filename)
return -1
读文件分析
def _handle_read(self, mu, fd, buf_addr, count):
"""
ssize_t read(int fd, void *buf, size_t count);
On files that support seeking, the read operation commences at the current file offset, and the file offset
is incremented by the number of bytes read. If the current file offset is at or past the end of file,
no bytes are read, and read() returns zero.
If count is zero, read() may detect the errors described below. In the absence of any errors, or if read()
does not check for errors, a read() with a count of 0 returns zero and has no other effects.
If count is greater than SSIZE_MAX, the result is unspecified.
"""
if fd <= 2:
raise NotImplementedError("Unsupported read operation for file descriptor %d." % fd)
if fd not in self._file_descriptors:
# TODO: Return valid error.
raise NotImplementedError()
file = self._file_descriptors[fd]
if file.descriptor == 'urandom':
if OVERRIDE_URANDOM:
buf = OVERRIDE_URANDOM_BYTE * count
else:
buf = os.urandom(count)
else:
buf = os.read(file.descriptor, count)
result = len(buf)
mu.mem_write(buf_addr, buf)
return result
调用JNI是工程量最大的一部分,不仅需要实现JNI Functions,还要模拟JNI Env和Java类似的引用管理。
在前面的文章中已经学习了如何在虚拟机中调用主机的Python函数,接下来就学习如何实现JNI Functions里面的所有函数。
模拟实现 Jni Function Table
可以参考 Jni Functions
Jni Function Table 是一个函数地址表,里面记录了Jni 函数地址。
(self.address_ptr, self.address) = hooker.write_function_table({
4: self.get_version,
5: self.define_class,
6: self.find_class,
7: self.from_reflected_method,
8: self.from_reflected_field,
9: self.to_reflected_method,
10: self.get_superclass,
11: self.is_assignable_from,
12: self.to_reflected_field,
13: self.throw,
14: self.throw_new,
15: self.exception_occurred,
16: self.exception_describe,
17: self.exception_clear,
18: self.fatal_error,
19: self.push_local_frame,
20: self.pop_local_frame,
21: self.new_global_ref,
22: self.delete_global_ref,
.......................
232: self.get_object_ref_type
})
write_function_table 函数实现了创建一个Function 地址表。
实现如下:
def write_function_table(self, table):
if not isinstance(table, dict):
raise ValueError("Expected a dictionary for the function table.")
index_max = int(max(table, key=int)) + 1
# First, we write every function and store its result address.
hook_map = dict()
for index, func in table.items():
hook_map[index] = self.write_function(func)
# Then we write the function table.
table_bytes = b""
table_address = self._hook_current
for index in range(0, index_max):
address = hook_map[index] if index in hook_map else 0
table_bytes += int(address + 1).to_bytes(4, byteorder='little') # + 1 because THUMB.
self._emu.mu.mem_write(table_address, table_bytes)
self._hook_current += len(table_bytes)
# Then we write the a pointer to the table.
ptr_address = self._hook_current
self._emu.mu.mem_write(ptr_address, table_address.to_bytes(4, byteorder='little'))
self._hook_current += 4
return ptr_address, table_address
Jni Functions Table 中有 200 多个函数,全部实现的话工作量十分巨大。默认实现如下:
@native_method
def call_boolean_method_a(self, mu, env):
raise NotImplementedError()
抛出异常可以保证当Native调用一个没有实现的JNI函数时能够及时发现,并实现它。
Classloader
AndroidNativeEmu 支持使用Python类来代替Jvm中Java类,这是如何实现的呢?
class android_content_context(metaclass=JavaClassDef, jvm_name="android/content/Context",
jvm_fields=[JavaFieldDef("CONNECTIVITY_SERVICE", "Ljava/lang/String;", True, "")]):
def __init__(self):
pass
@java_method_def(native=False, name="getPackageName", signature="()Ljava/lang/String;")
def getPackageName(self, *args, **kwargs):
return "com.test"
emulator.java_classloader.add_class(android_content_context) # load class
jvm_super 指定父类
jvm_name 定义对应的类名
jvm_fields 定义字段,是一个列表,每一项都是由JavaFieldDef定义的字段,JavaFieldDef(name, signature, is_static, static_value=None)
如果不是static字段,则还需要在init 中创建这个这个私有的成员变量。
metaclass=JavaClassDef 是Python的元类机制,参考廖雪峰老师文章
元类可真的是魔法!它可以动态修改类的定义,比如给类增加成员变量,增加方法等。
JavaClassDef 将class 定义指定的jvm_name 和 jvm_fields保存到成员变量,并添加了find_method、find_method_by_id、find_field等函数,用于实现JNI。
注册方法
# Register all defined Java methods.
for func in inspect.getmembers(cls, predicate=inspect.isfunction):
if hasattr(func[1], 'jvm_method'):
method = func[1].jvm_method
method.jvm_id = next(JavaClassDef.next_jvm_method_id)
cls.jvm_methods[method.jvm_id] = method
注册字段
# Register all defined Java fields.
if jvm_fields is not None:
for jvm_field in jvm_fields:
jvm_field.jvm_id = next(JavaClassDef.next_jvm_field_id)
cls.jvm_fields[jvm_field.jvm_id] = jvm_field
查找字段的函数
支持类继承,Java是单继承,查找的时候先从基类开始递归查找。
def find_field_by_id(cls, jvm_id):
try:
if cls.jvm_super is not None:
find = cls.jvm_super.find_field_by_id(jvm_id)
if find is not None:
return find
except KeyError:
pass
return cls.jvm_fields[jvm_id]
metaclass 修饰了定义的java类,隐藏了类解析背后的细节,使得添加一个java类很方便。java类定义后,还需要添加模拟器的class管理。
def add_class(self, clazz):
if not isinstance(clazz, JavaClassDef):
raise ValueError('Expected a JavaClassDef.')
if clazz.jvm_name in self.class_by_name:
raise KeyError('The class \'%s\' is already registered.' % clazz.jvm_name)
self.class_by_id[clazz.jvm_id] = clazz
self.class_by_name[clazz.jvm_name] = clazz
保存的是类的定义而不是实例。
引用管理
目前实现两种类型的引用,一种jobject和jclass。jobejct是用来引用实例对象,jclass用来引用类。
Python 实现java的类,如果返回一个String,那么就会自动创建一个String引用,然后把引用id返回给Native 函数。Native 函数再调用GetStringUtfChars获取引用的字符串。 GetStringUtfChars 的实现如下。
@native_method
def get_string_utf_chars(self, mu, env, string, is_copy_ptr):
logger.debug("JNIEnv->GetStringUtfChars(%u, %x) was called" % (string, is_copy_ptr))
if is_copy_ptr != 0:
raise NotImplementedError()
str_ref = self.get_reference(string) #通过引用ID获取引用对象
str_val = str_ref.value # 获取该引用的值
str_ptr = self._emu.native_memory.allocate(len(str_val) + 1)
logger.debug("=> %s" % str_val)
memory_helpers.write_utf8(mu, str_ptr, str_val)
return str_ptr
引用还分为局部引用和全局引用。局部引用的生命周期是进入native 函数到native 函数返回。 全局引用则作用于模拟器整个生命周期。
self._locals = ReferenceTable(start=1, max_entries=2048) self._globals = ReferenceTable(start=4096, max_entries=512000)
实现 GetEnv
class JavaVM:
"""
:type class_loader JavaClassLoader
:type hooker Hooker
"""
def __init__(self, emu, class_loader, hooker):
(self.address_ptr, self.address) = hooker.write_function_table({
3: self.destroy_java_vm,
4: self.attach_current_thread,
5: self.detach_current_thread,
6: self.get_env,
7: self.attach_current_thread
})
self.jni_env = JNIEnv(emu, class_loader, hooker)
@native_method
def get_env(self, mu, java_vm, env, version):
logger.debug("java_vm: 0x%08x" % java_vm)
logger.debug("env: 0x%08x" % env)
logger.debug("version: 0x%08x" % version)
mu.mem_write(env, self.jni_env.address_ptr.to_bytes(4, byteorder='little'))
logger.debug("JavaVM->GetENV() was called!")
return JNI_OK
Native / Java 函数调用
我们目前已经实现了Java 调用native 的过程,native再回调java是否可以实现呢?实际上,在class定义的时候就解析了所有带@java_method_def 装饰器的成员函数。native通过JNI调用java函数,我们可以模拟对应的JNI函数,使其在所有加载的类中查找是否有对应签名的函数,如果有则直接调用。
@java_method_def 装饰器不仅描述了函数的签名,还转换函数的参数数据和返回值信息。
这个修饰器的定义如下:
def java_method_def(name, signature, native=False, args_list=None, modifier=None, ignore=False):
def java_method_def_real(func):
def native_wrapper(self, emulator, *argv): # native 方法,进入虚拟机
return emulator.call_native(
native_wrapper.jvm_method.native_addr,
emulator.java_vm.jni_env.address_ptr, # JNIEnv*
self, # this
# method has been declared in
*argv # Extra args.
)
def normal_wrapper(*args, **kwargs): # 普通方法,直接调用
result = func(*args, **kwargs)
return result
wrapper = native_wrapper if native else normal_wrapper # 判断是否没native函数,分别进入不同的wrapper
wrapper.jvm_method = JavaMethodDef(func.__name__, wrapper, name, signature, native,
args_list=args_list,
modifier=modifier,
ignore=ignore)
return wrapper
return java_method_def_real
参数转换
Java 调用 Native 的时候要把非数字类型转换为对象引用。
Native 调用 Java 或者 返回的时候要把引用转换成对象,转换方法实现如下:
def native_write_args(emu, *argv):
amount = len(argv)
if amount == 0:
return
if amount >= 1:
native_write_arg_register(emu, UC_ARM_REG_R0, argv[0])
if amount >= 2:
native_write_arg_register(emu, UC_ARM_REG_R1, argv[1])
if amount >= 3:
native_write_arg_register(emu, UC_ARM_REG_R2, argv[2])
if amount >= 4:
native_write_arg_register(emu, UC_ARM_REG_R3, argv[3])
if amount >= 5:
sp_start = emu.mu.reg_read(UC_ARM_REG_SP)
sp_current = sp_start - STACK_OFFSET # Need to offset because our hook pushes one register on the stack.
for arg in argv[4:]:
emu.mu.mem_write(sp_current - STACK_OFFSET, native_translate_arg(emu, arg).to_bytes(4, byteorder='little'))
sp_current = sp_current - 4
emu.mu.reg_write(UC_ARM_REG_SP, sp_current)
def native_translate_arg(emu, val):
if isinstance(val, int):
return val
elif isinstance(val, str):
return emu.java_vm.jni_env.add_local_reference(jstring(val))
elif isinstance(val, list):
return emu.java_vm.jni_env.add_local_reference(jobjectArray(val))
elif isinstance(val, bytearray):
return emu.java_vm.jni_env.add_local_reference(jbyteArray(val))
elif isinstance(type(val), JavaClassDef):
# TODO: Look into this, seems wrong..
return emu.java_vm.jni_env.add_local_reference(jobject(val))
elif isinstance(val, JavaClassDef):
return emu.java_vm.jni_env.add_local_reference(jobject(val))
else:
raise NotImplementedError("Unable to write response '%s' type '%s' to emulator." % (str(val), type(val)))
def native_write_arg_register(emu, reg, val):
emu.mu.reg_write(reg, native_translate_arg(emu, val))
## 返回值转换
result_idx = self.mu.reg_read(UC_ARM_REG_R0)
result = self.java_vm.jni_env.get_local_reference(result_idx)
附录:
Unicorn 优秀项目:http://www.unicorn-engine.org/showcase/
最后于 11小时前 被无名侠编辑 ,原因:
如有侵权请联系:admin#unsafe.sh