本文为看雪论坛优秀文章
看雪论坛作者ID:有毒
TL;DR
1
背景
2
Lighouse的基本使用
import idaapi, os; print(os.path.join(idaapi.get_user_idadir(), "plugins"))3
drcov文件格式
(1)简介
(2)详细格式
DRCOV VERSION: 2DRCOV FLAVOR: drcov
Module Table: version 2, count 39Columns: id, base, end, entry, checksum, timestamp, path0, 0x10c83b000, 0x10c83dfff, 0x0000000000000000, 0x00000000, 0x00000000, /Users/ayrx/code/frida-drcov/bar1, 0x112314000, 0x1123f4fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/dyld2, 0x7fff5d866000, 0x7fff5d867fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libSystem.B.dylib3, 0x7fff5dac1000, 0x7fff5db18fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libc++.1.dylib4, 0x7fff5db19000, 0x7fff5db2efff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libc++abi.dylib5, 0x7fff5f30d000, 0x7fff5fa93fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libobjc.A.dylib8, 0x7fff60617000, 0x7fff60647fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/system/libxpc.dylib... snip ...
Format used in DynamoRIO v6.1.1 through 6.2.0eg: 'Module Table: 11'Format used in DynamoRIO v7.0.0-RC1 (and hopefully above)eg: 'Module Table: version X, count 11'
DynamoRIO v6.1.1, table version 1:eg: (Not present)DynamoRIO v7.0.0-RC1, table version 2:Windows:'Columns: id, base, end, entry, checksum, timestamp, path'Mac/Linux:'Columns: id, base, end, entry, path'DynamoRIO v7.0.17594B, table version 3:Windows:'Columns: id, containing_id, start, end, entry, checksum, timestamp, path'Mac/Linux:'Columns: id, containing_id, start, end, entry, path'DynamoRIO v7.0.17640, table version 4:Windows:'Columns: id, containing_id, start, end, entry, offset, checksum, timestamp, path'Mac/Linux:'Columns: id, containing_id, start, end, entry, offset, path'
id: 生成模块表时分配的序号,稍后用于将基本块映射到模块。
start, base: 模块开始的内存基地址。
end: 模块结束的内存地址。
path: 模块在硬盘上的存储路径。
BB Table: 861 bbs<binary data>
typedef struct _bb_entry_t {uint start; /* offset of bb start from the image base */ushort size;ushort mod_id;} bb_entry_t;
start: 距离基本块入口开始的模块的基地址的偏移。
size: 基本块的大小。
mod_id: 发现的基本块所在模块的id,与前面模块表中的id是对应的。
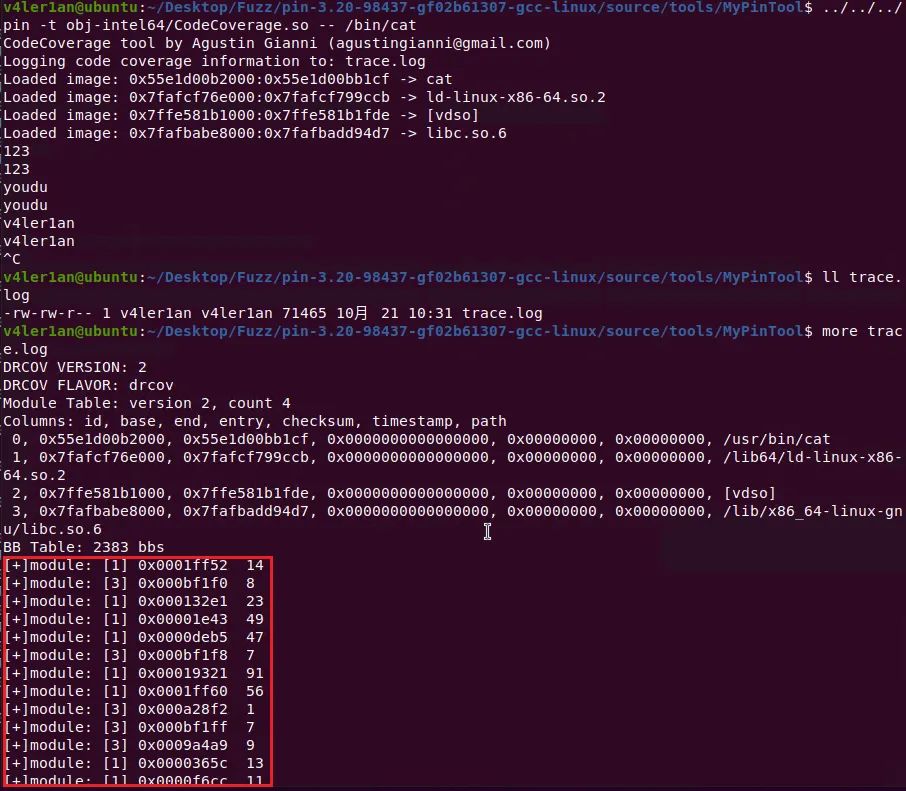
(3)修改输出方式为明文(以Pin插件为例)
# CodeCoverage.cppstatic VOID OnFini(INT32 code, VOID* v){...snap...drcov_bb tmp;for (const auto& data : context.m_terminated_threads) {for (const auto& block : data->m_blocks) {auto address = block.first;auto it = std::find_if(context.m_loaded_images.begin(), context.m_loaded_images.end(), [&address](const LoadedImage& image) {return address >= image.low_ && address < image.high_;});if (it == context.m_loaded_images.end())continue;tmp.id = (uint16_t)std::distance(context.m_loaded_images.begin(), it);tmp.start = (uint32_t)(address - it->low_);tmp.size = data->m_blocks[address];context.m_trace->write_binary(&tmp, sizeof(tmp));}}}
struct __attribute__((packed)) drcov_bb {uint32_t start;uint16_t size;uint16_t id;};
tmp.id = (uint16_t)std::distance(context.m_loaded_images.begin(), it);tmp.start = (uint32_t)(address - it->low_);tmp.size = data->m_blocks[address];
context.m_trace->write_binary(&tmp, sizeof(tmp));void write_binary(const void* ptr, size_t size){if (fwrite(ptr, size, 1, m_file) != 1) {std::cerr << "Could not log to the log file." << std::endl;std::abort();}}
void write_string(const char* format, ...){va_list args;va_start(args, format);if (vfprintf(m_file, format, args) < 0) {std::cerr << "Could not log to the log file." << std::endl;std::abort();}va_end(args);}
// drcov_bb tmp; 这里要注释掉。否则有的环境会报编译不通过for (const auto& data : context.m_terminated_threads) {for (const auto& block : data->m_blocks) {auto address = block.first;auto it = std::find_if(context.m_loaded_images.begin(), context.m_loaded_images.end(), [&address](const LoadedImage& image) {return address >= image.low_ && address < image.high_;});if (it == context.m_loaded_images.end())continue;uint16_t id = (uint16_t)std::distance(context.m_loaded_images.begin(), it);uint32_t start_addr = (uint32_t)(address - it->low_);int size = data->m_blocks[address];context.m_trace->write_string("[+]module: [%d] 0x%08x %d\n", id, start_addr, size);}}
看雪ID:有毒
https://bbs.pediy.com/user-home-779730.htm
# 往期推荐
球分享
球点赞
球在看
点击“阅读原文”,了解更多!
文章来源: http://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458406718&idx=1&sn=667e281647a2019cc17ba5ad9f87b54a&chksm=b18f7fb486f8f6a2f929dc950efcf49429869153d917296904592993194cbe1fc388520d17aa#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh