作者:Koalr
原文链接:https://koalr.me/posts/core-concept-of-yarx/
xray 得益于 Go 语言本身的优势,没有那么多不安全的动态特性,唯一动态是一个表达式引擎(CEL),用的时候也加了各种类型校验,和静态代码没有什么区别了,因此基本不可能实现 RCE 之类的反制效果。那么我们换个思路,有没有办法让 xray 直接无法使用呢。
无法使用有两个表现,一个是让其直接崩溃掉,效果就是如果用 xray 扫描一个恶意 server,xray 直接 panic 退出。xray 0.x.x 之前的某些版本确实有这种 bug,我当时耗费了很大的精力去这个定位问题然后开心的修掉了,这里就不细说这个点了,因为版本太老说了也没有太大意义。
另一方面呢,想想之前比较热门的 CobaltStrike 反制,做法是设法取得 CS 的通信密钥然后模拟其上线流量,Server 端会瞬间上线无数机器,使得 CS 无法正常使用。那么我们能否给 xray 喂屎,使得它能瞬间扫出无数漏洞来让正常的扫描失效呢,我顺着这个思路做了一些探索,这篇文章就来说下我在编写这样一个”反制“工具的过程中遇到的困难以及我是如何解决的。
入手
想让扫描器能扫出漏洞,只需要满足扫描器对一个漏洞的规则定义即可。xray 的 poc 部分是开源的,意味着我们可以知道 xray 在扫描时是怎么发的包,以及什么样的响应会被定义为漏洞存在。那么我们只要能定义一个 server ,让 server 按照 poc 中定义的的响应去返回数据,就可以欺骗 xray 让其认为漏洞存在!看一个最简单的例子:
rules:
r0:
request:
method: GET
path: /app/kibana
expression: response.status == 200 && response.body.bcontains(b".kibanaWelcomeView")
expression: r0()在这个例子中,只要让 /app/kibana 这个路由返回.kibanaWelcomeView 并且状态码是 200,就能扫出 poc-yaml-kibana-unauth 这个漏洞。这太简单了,我们只需要批量解析一下所有 poc,然后基于规则构建一下返回的数据就可以了,事实的确如此,不过过程可能稍显曲折。来看下另一个例子:
set:
rand1: randomLowercase(10)
rules:
r0:
request:
method: GET
path: /enc?md5={{rand1}}
expression: response.body.bcontains(bytes(md5(rand1)))
output:
search: 'test_yarx_(?P<group_id>\w+)".bsubmatch(response.body)'
group_id: search["group_id"]
r1:
request:
method: GET
path: /groups/{{group_id}}
expression: response.headers["Set-Cookie"].contains(group_id, 0, 8)
expression: r0() && r1()这个例子复杂了亿点,其复杂性主要来自于这几方面:
- 整体存在两条规则
r0() && r1(),且两条规则都满足才行 - path 中存在变量,无法直接将 path 作为路由使用
- 第二条规则的
group_id来自于第一条规则的响应进行匹配得到的值,即两条规则存在联系 - 对响应的判断没有使用常量,而是需要将变量经过部分运算后返回给扫描器才有效
可能有同学会问,实际的 poc 真有这么复杂吗,答案是有过之而无不及。这种逻辑复杂还有层级关系的 poc 极大的阻碍了我们上面一把梭的想法。我们需要重新整理一下思路,寻找一下破局的方法。
破局
yaml poc 中的 expression 部分用于漏洞存在性判断,它是一条规则在执行过程最终的终点,从这里出发去寻找解决方案是一个不错的思路。 expression 部分是由 CEL 标准定义的表达式,下面这些形式都是合法且常见的:
reponse.status != 201
response.header["token"] == "lwq"
reponse.body.bcontains(bytes(md5("yarx")))需要反连的漏洞先不谈,宏观来讲一个响应我们可以控制的点只有4个:
- 状态码
- 响应头
- 响应体
- 响应时间
最后一个一般用于盲注检测的指标也暂时不看,其余三个就可以涵盖绝大部分的 yaml poc 的判定规则。因此对于一条 expression,我们只需要确定下列三点就可以做自动化构建:
- 修改的位置(status,body,header)
- 修改方式(contains, matches, equals)
- 修改的值(body 或 header value 等)
那么如何对每条 expression 确定这三点呢?也许简单的 case 我们可以直接用正则匹配实现,但正则解决不了诸如 reponse.body.bcontains(bytes(md5("yarx")))的情况,而这样的情况有很多,因此为了降低复杂度。我从 AST 层面入手解决了这个问题。老生常谈的做法这里就不展开了,经过一坨的遍历和分析之后,可以把表达式解析成下面的形式:

可以发现前两个的规则其实是静态的,这种静态规则我们可以在分析的时候就计算出正确的数据,然后在响应返回即可。比较棘手的是第三个例子的情况,判断条件种包含了 r1这样一个变量,这个变量由 xray 生成,在请求的某个角落被发送过来。换句话说,我们需要先获取到这个变量的值,然后才能代入到表达式中计算获取最终的结果,那么怎么获取这个变量呢?举个栗子
set:
rand1: randomLowercase(8)
rules:
...
request:
path: /?a=md5({{rand1}})
expression: response.body.bcontains(bytes(md5(rand1)))当上述 poc 被加载运行时,作为服务端会收到一个类似这样的 path: /?a=md5(abcdefgh) 这里的 abcdefgh 就是我们要获取的变量的值。聪明的你不难想到,我们只需要做一个正则转换就可以实现这个目标(别忘了正则需要转义):
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>\w+)\)甚至基于randomLowercase(8) 这个上下文,我们可以写出一个更完美的正则:
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>[a-zA-Z]{8})\)基于这个思想,我们可以把请求的各个位置都变成正则表达式,这些正则将在收到对应的请求时被执行,并将提取出的变量储存起来供表达式使用。可是,如何使用这些变量?
变量
变量是 poc 的利器,也是我们的绊脚石。不如就 ”以变制变“ 来解决变量带来的一系列问题。我在解析表达式的时候没有分析到底,而是以下面的这些函数或者运算符作为终止条件,并记下他们的参数。
=、!=contains、bcontainsmatches、bmatches
这样有什么好处呢,就是可以借助表达式的部分执行 (PartialEval) 来简化分析流程。比如 contains 的参数可能是这些
"SQL Admin"
md5("koalr")
substr(md5(r1), 0, 8)如果我头铁去解析到底,这复杂度和重写一个表达式语言差不多了。我发现这些参数实际都是合法的 CEL 表达式,当相关变量成功获取后,它们也可以被 CEL 正常执行。当表达式被执行后,它便成为了我们最喜欢的常量类型,这种只执行参数的操作就被我定义为 PartialEval 。
"SQL Admin" => "SQL Admin"
md5("koalr") => "f2ebd1b28583a579fe12966d8f7c6d4b"
substr(md5(r1),0,8) => "210cf7aa" # if r1 = 'admin'接下来,我们可以将每种函数或是运算符视为一种匹配模式。比如 contains 就是让参数直接包含在响应里;再比如 matches 的参数应被视为一个正则,我们需要根据正则去生成一个假数据再填充到响应里。
"response.header['token'] == 'yarx'" => resp.Header().Set('token', 'yarx')
"'ad[m]{2}in'.bmatches(resp.body)" => resp.Body.Write([]byte("admmin"))这样每种模式都可以写成一个处理函数,其逻辑基本都是这样的流程:
- 从多个地方获取变量的值
- 把参数作为表达式执行,获取执行结果
- 将参数做对应处理然后写入到响应
经过上面这些处理,我们就有了一堆分析好的处理函数, 离 xray poc 的逆解析又近了一步!
流程
新版的 xray 规则在最外层增加了一个 expression,可以借助它自定义执行流程,比如假设在 rules 部分定义了 4 个规则,那么 expression 可以任意的去构造:
rules:
r1: ...
r2: ...
r3: ...
r4: ...
expression: r1() && r2() && r3() && r4()
expression: (r1() && r2()) || (r3() && r4())
expression: r1() || (r2() && (r3() || r4()))我们在编写 server 时也要符合这个定义才行,比如第一个要顺序执行4条规则且全部满足才可以。而后面两个我们可以取个最短路径来简化逻辑,比如最后一个我们可以只满足 r1 即可,这其实就是大家都学过的二叉树的深度问题,取最浅的一条能到达叶子节点的路径即可。
和执行流程相关的还有动态变量的问题,就是下面的这种情况:
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
output:
search: 'test_yarx_(?P<id>\w+)".bsubmatch(response.body)'
yarx_id: search["id"]
r1:
request:
method: GET
path: /{{yarx_id}}
expression: response.status == 200
expression: r0() && r1()在这个例子中 r1 会用到 r0 的响应中的变量。这个乍看很复杂,不过稍加思考就会发现,服务端的响应我们是完全可控的,因此我们可以将 r0 的响应在解析的时候就固定下来,xray 收到响应一定会提取出和我们一样的变量值,所以后面用到该变量的地方也可以被直接替换成常量。对于这个例子,如果固定生成的 id 是 deadbeef ,那么这个规则实际上变成了下面的写法,这样做不仅简单了,还对减少下面要说到的路由冲突的问题有很大帮助。
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
r1:
request:
method: GET
path: /deadbeef
expression: response.status == 200
expression: r0() && r1()缝合
经过了前面这么多的准备工作,我们终于可以开始着手编写服务端逻辑了,这其实就是把一堆的处理逻辑缝合在一起的过程。缝合的方式很简单,就是基于路由去调用。路由信息在 poc 中已经标明了,我们只需要将规则中的 method、path、header 等提取成一个唯一的特征,利用这个唯一的特征可以映射到上面写的处理函数,进而走通流程。我起初以为这个很简单,没想到这个点耗费了我编写这个项目最多的时间,其难点在于处理路由冲突,即有些情况下没法提取出唯一的特征。
比如下面这两个 poc,他们请求部分完全相同仅仅是表达式的判断不同,请求可能会命中其中任意一个规则进行处理,这就导致只能扫出其中的某一个漏洞。
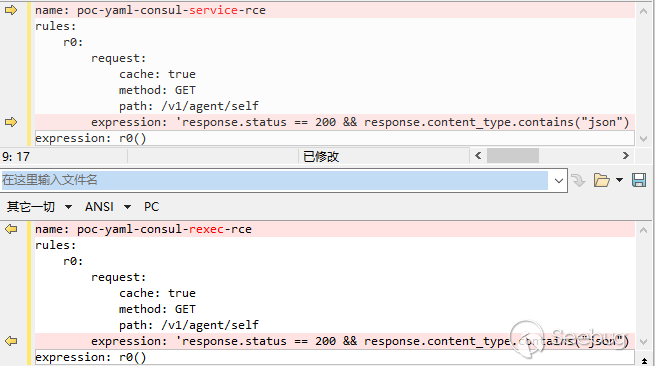
我对这类情况的处理是做一次合并,合并后的规则会包含原有的两个规则的响应处理。由于 poc 中基本都是 contains 相关的处理,因此这种合并基本都是兼容的。当然,也有不兼容的情况,比如:
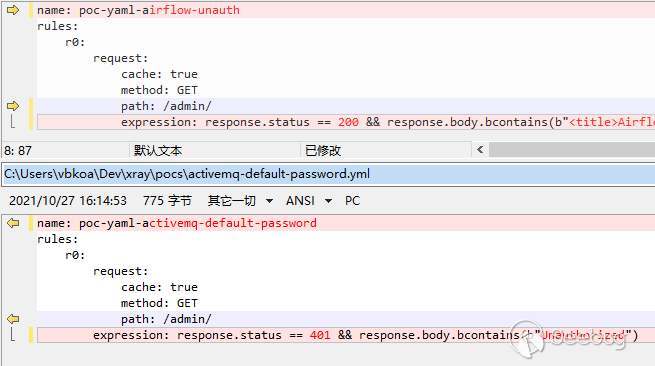
这里的 status 就是不兼容的,我们不可能让一个响应既是 200 又是 401。除此之外,还有更棘手的动态路由问题:

这些 poc 的路径过于简单又包含变量,导致诸如 /admin.php 的路径可能被任意一个匹配到,这显然是不合理的。上面的两个问题困扰了我好久,我最开始是计划支持所有 xray poc 的检测的,这个问题犹如心头刺让我很难受,挣扎几日之后最终承认当前版本下这是一个无解的问题。在此过程中我尝试减少冲突的思路有:
-
动态变量的静态化
就是上面说到的 output 的处理过程 -
变量值的再确认
同一个变量在 poc 的一次运行中是不变的值,而变量可能在不同的规则中匹配出多次 -
调整路由顺序
我写了一个巨大的排序规则来让 server 运行前把路由排个序,比如没有变量的要好于有变量的,path 长的好于 path 短的,包含 header 的好于不包含的以此来让静态路径优先匹配 -
添加层级判断
就是给 poc 的运行添加状态,比如第一个请求之后应该是第二个请求,如果第二个请求没来那么第一个请求就不应该被处理
这些方法除了最后一个我都实现了,而且确实是有效。相比之下最后一点并非实现不了,而是由于其不可避免的会影响并发扫描的效率被我去掉了。尽管用了这么多的 trick,但依然无法支持所有的 poc 同时扫描,后面我也不再钻牛角,我决定将一些过于灵活的 poc 直接去掉不加载,这个策略反而大幅提升了整体的检出率。
把上面的思想包装成代码,再稍微踩点坑就诞生了 https://github.com/zema1/yarx 这个项目。截至到这篇文章写完时已经可以单端口瞬间检测出 280+ 漏洞(官方约 340个 poc),这个数据伴随着后期的优化升级还会不断增加。
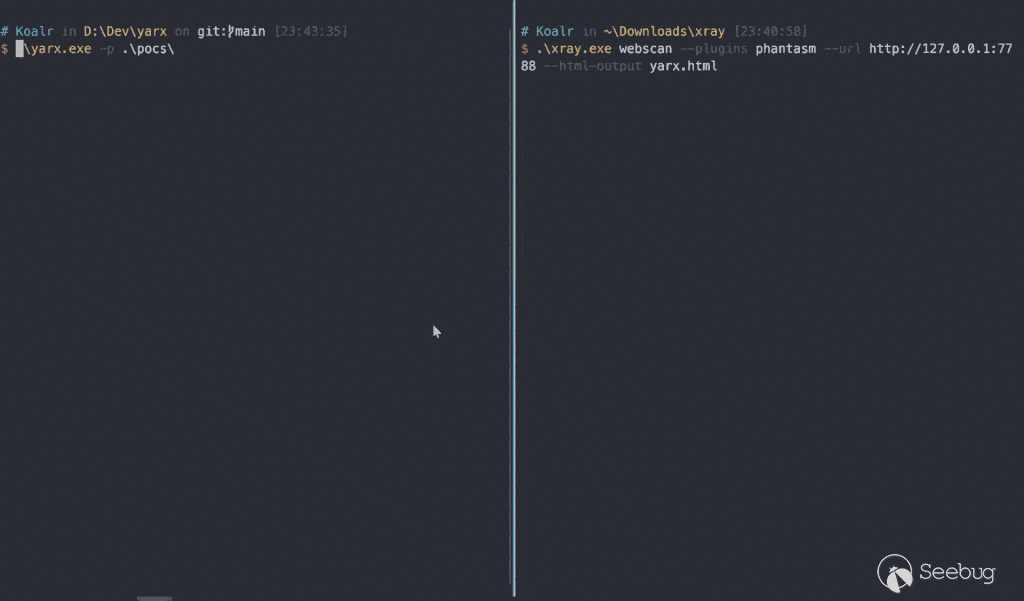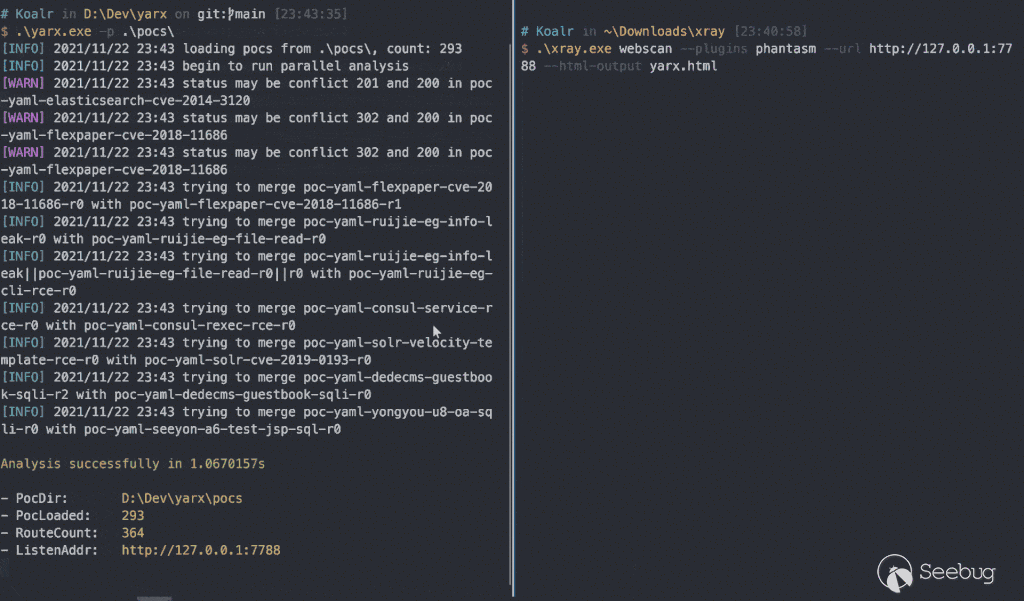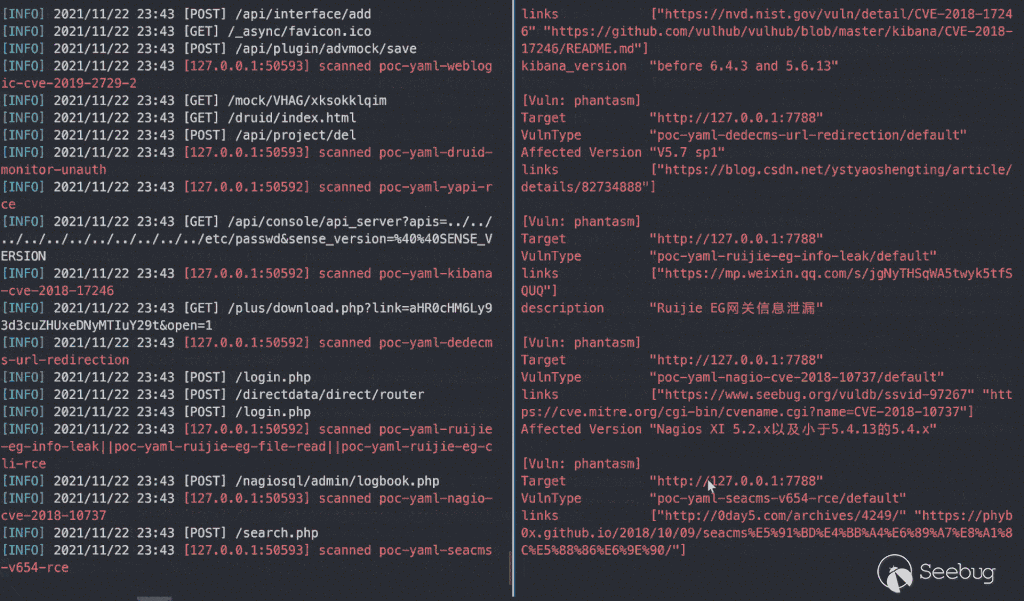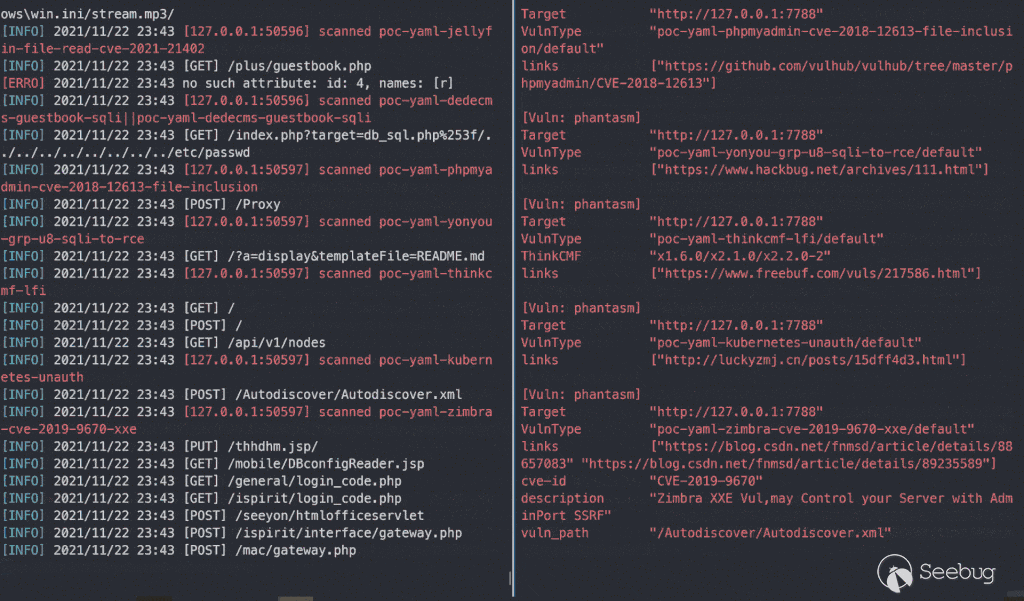
总结
我作为曾经的 xray 核心开发者做反制 xray 这种事看似有点过河拆桥,但其实 yarx 这反而有利于 xray 的发展。除了通过污染漏洞报告来 “反制” xray 外,还有至少这样两个有趣的用途:
-
做 xray-like 的漏扫的集成测试
可以检查集成了 xray 的漏扫产品从 yaml 输入到扫描出漏洞的整个流程是否按预期工作。借助 yarx 我还真发现了几个 xray 的陈年老 bug,提了个 issue 详情在这 Issue 1493 -
做 xray 相关的蜜罐
蜜罐类产品可以添加一个类别叫 xray-sensor,精准探测 xray 用了哪个 poc 发了什么包,感觉做成产品整个界面还挺好玩的。还有一种可行的情况是在网关处针对 xray 的扫描流量做一下转发,网关处的流量识别可以做的粗一点,比如只支持静态类型的 url 匹配,识别后再转到 yarx 进行处理,这样可以迷惑一下攻击者。
虽然这不是真正意义上的 xray 反制,但也算是填补了常见安全工具反制的一块拼图,这波是利好蓝队了。另外,文中的思路其实适用于任何扫描器,比如 nuclei 之类的也都可以用类似思路。甚至如果有同学乐意可以比社区常见的扫描器都搞一搞,扫描器没法用了才是脚本小子真正的末日(
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1773/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1773/
如有侵权请联系:admin#unsafe.sh