大家对“指纹”并不陌生,但听说过“声纹”吗?“违法犯罪变得越来越困难了。如今罪犯都没法使用电话了,因为侦探们可以通过他们在话筒上留下的声纹来追踪他。”一则刊登在1918年10月的《田纳西人日报》中的笑话首次提及“声纹”,并将其比作“指纹”,能用来定位到具体的犯人,帮助警方刑侦调查。后来玩笑逐渐变成了现实,虽然声音所过之处并不会留下任何痕迹,但是声音本身却蕴藏着身份的蛛丝马迹。与“指纹”一样,每个人拥有独一无二的“声纹”。
随着深度学习时代的到来,声纹识别领域自然而然地形成了“百家争鸣”的局面,许多实际应用应运而生。本文将介绍内容安全场景下基于深度学习及神经网络的声纹识别方法,让机器自动定位声音主人的身份。
声纹识别简介
声纹识别,也叫说话人识别,是一种通过声音来判别说话人身份的技术。声纹虽然不如指纹、人脸这样,个体差异明显,但是由于每个人的声道、口腔和鼻腔(发音要用到的器官)具有个体差异性,反映到声音上,也各不相同。
比如,当我们在接电话的时候,通过一声"喂",我们就能准确的分辨出接电话的人是谁。我们人耳作为身体的接收器生来就具有分辨声音的能力,那么我们也可以通过技术的手段,使声纹成为与人脸、指纹一样的“个人身份认证”的重要信息。
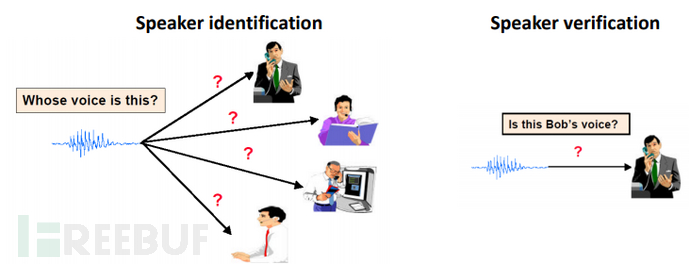
声纹识别任务根据使用场景分,主要有有说话人辨认和说话人确认两个应用场景,如图一所示,其中说话人辨认(Speaker identification)判定待测试语音属于几个参考说话人其中之一,是一个多选一的问题,而说话人确认(Speaker verification)用于确定待测语音与其特定参考说话人是否相符,是二选一的是非问题,即确认(肯定)或拒绝(否定)。由于两者背后依托的技术手段类似,故而本文重点介绍说话人确认这一应用场景。
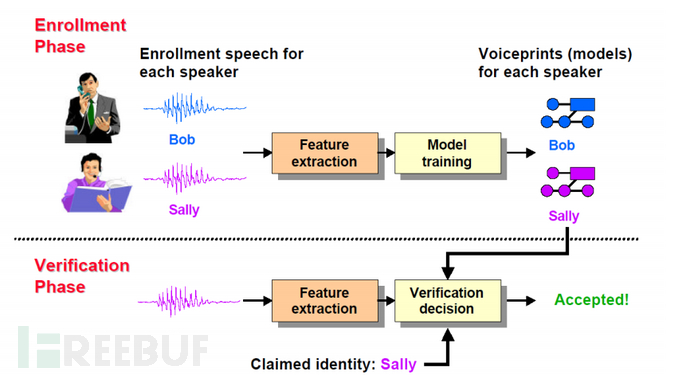
 图一 声纹识别任务说话人确认按流程可以分为,注册阶段(Enrollment Phase)和确认阶段(Verification Phase),如图二所示,在注册阶段,我们需要搜集所有语者的语音,为“说话人确认系统”提供支持,然后提取声学特征并训练模型,最终得到每个人的声纹特征(Voiceprints)。
图一 声纹识别任务说话人确认按流程可以分为,注册阶段(Enrollment Phase)和确认阶段(Verification Phase),如图二所示,在注册阶段,我们需要搜集所有语者的语音,为“说话人确认系统”提供支持,然后提取声学特征并训练模型,最终得到每个人的声纹特征(Voiceprints)。
在确认阶段,我们将待确认语者的特征和它声称的语者的特征做相似度计算,最终判断是否接受。如图二中,在验证阶段,一段声称为Sally的语音送入验证系统,验证系统计算语音和Sally的声纹特征的相似度,并最终决定是否接受输入语音为Sally产生的。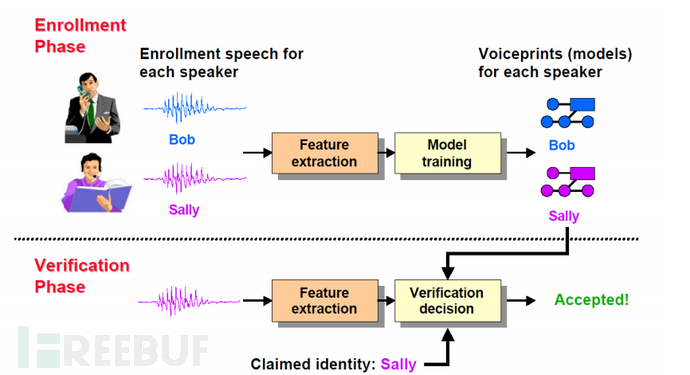 图二 说话人确认流程图
图二 说话人确认流程图
声纹识别的技术演进
对声纹识别的研究大概经历了三个阶段。如图三所示,对声纹识别的研究第一阶段处于1930s-1980s,停留在特征工程阶段。1945年,贝尔实验室借助肉眼完成语谱图匹配,首次提出“声纹”概念,之后又有人提出用LPC,MFCC等特征,采用模板匹配和模式匹配的方法来进行声纹识别。
之后对声纹识别的研究进入了第二个阶段,在1990年,D. Reynolds提出GMM-UBM结构,是声纹识别从实验室走向实用,2008年和2011年,P.Kenny和N. Dehak依次提出JFA和i-vector模型,得到低维说话人向量。2014年,随着P.Kenny和N. Dehak相继提出了DNN-i-vector模型,进一步提升系统性能。
由此,业界认为对声纹识别的研究进入第三个阶段,在深度学习阶段,一些基于端到端和深度特征学习等方法也相继应用于声纹识别中。由于深度学习的相关算法极大地提升了声纹识别的效果,所以我们重点介绍下深度学习下,声纹识别的主要研究内容。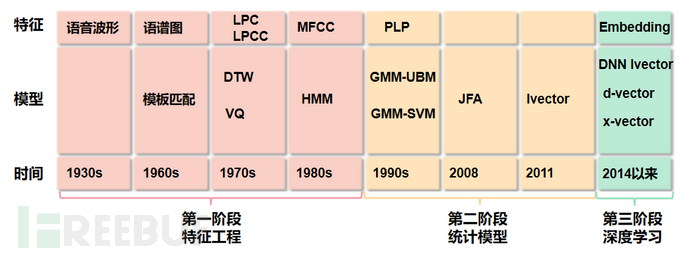 图三 声纹识别发展历程
图三 声纹识别发展历程
深度学习赋能声纹识别
在此阶段,对于声纹识别的研究主要集中在数据、模型结构、损失函数等三大块的研究。接下来,本文将分别介绍这三块内容。
一是数据层面的研究。因为训练数据的质量和数量对于声纹识别系统性能起着重要的作用,所以对于数据的研究也就有了很重大的意义。而围绕数据层面的研究,对于数据增强的研究占据了很大的比重。
如图四所示,文献[1][2]中利用在训练数据中加入噪声、音乐以及混响等方式做数据增强,这极大地提升了模型的性能。在文献[3]中,作者观察到当训练和测试存在场景不匹配的情况下,传统的声纹识别模型性能表现较差,于是作者提出了基于熵的变帧率(entropy-based variable frame rate)增强方式来改变语音的说话方式,这一技术优化了注册和验证场景不匹配下声纹识别系统的性能。
文献[4]中,作者提出了SpecAugment的方法,与在原始音频上做数据增强不同的是,它直接在输入神经网络的声学特征,例如在FBank上做数据增强。除了这些增强方式,也有学者利用声音转换(Voice Conversion)[5]和语音合成(Text to Speech)[6][7]等技术来做数据增强。
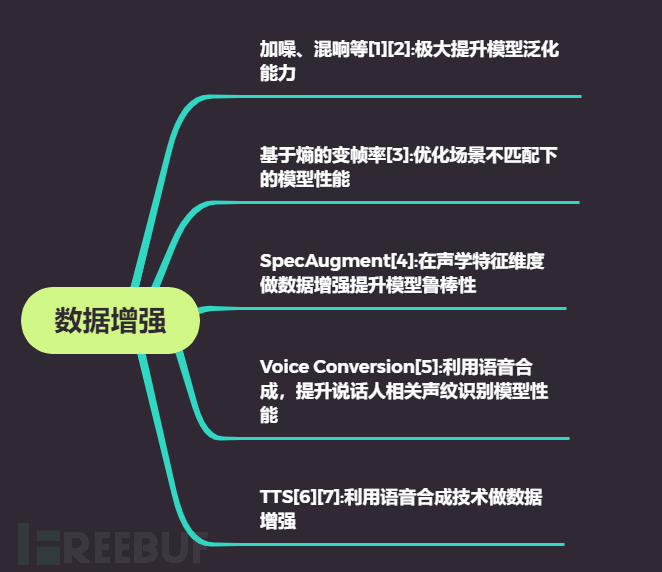 图四 数据增强在声纹识别中的应用
图四 数据增强在声纹识别中的应用
二是模型结构层面的研究。这方面的研究主要集中在主干网络和将不定长语音转变成定长声纹特征的方式这两个方向。首先主干网络方向的研究,主要有Resnet[8]及其相关变种[10][11][12]和TDNN[2]及其相关变种[9]两大类,如图五所示。Resnet在图像分类领域有着很强的地位,它同时也广泛被用于声纹识别中,在这基础上也衍生出了一些变种,如为了优化网络的时间开销,有学者将Resnet每一个残差块的通道数减为原来的四分之一。
为了兼顾时间和性能,有学者将Resnet每一残差块的通道数减为原来的二分之一等。TDNN提取的Xvector,第一次全面超越传统声纹特征Ivector,高斯超矢量等。学术界对其相关变种的研究也很多,比如E-TDNN[13],F-TDNN[14],ARET[14]等,最近提出的ECAPA-TDNN[9]引入了注意力机制,并将浅层和深层特征做融合,取得了SOTA的效果。
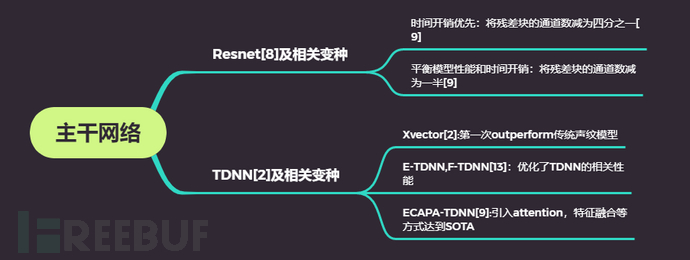 图五 声纹识别主干网络的发展对于将不定长语音变成定长声纹特征的方式,学术界的尝试主要有以下几种LSTM[15],statistic pooling[2],self-attentive pooling[16],attentive statistic pooling[17]等,如图六所示。LSTM天然就能从时序信号中提取特征,但是当语音时长过长的时候,容易出现梯度消失的问题,并且不适合并行运算。
图五 声纹识别主干网络的发展对于将不定长语音变成定长声纹特征的方式,学术界的尝试主要有以下几种LSTM[15],statistic pooling[2],self-attentive pooling[16],attentive statistic pooling[17]等,如图六所示。LSTM天然就能从时序信号中提取特征,但是当语音时长过长的时候,容易出现梯度消失的问题,并且不适合并行运算。
Statistic pooling认为每一帧语音信号对应的特征(主干网络的输出),它们的统计信息对于声纹识别至关重要,所以它计算每一帧语音特征的一、二阶统计量,并把他们首尾相连,得到最终的声纹特征。Self-attentive pooling引入自注意力机制,用每一帧语音信号对应的特征(主干网络的输出)计算出每一帧的权重,并通过加权平均得到最终的声纹特征,而attentive statistic pooling则结合了上述两种方式。 图六 特征融合方式
图六 特征融合方式
三是损失函数层面的研究。损失函数的研究,主要包含分类相关的Softmax loss,人脸识别相关的AM softmax[18][19],AAM softmax[20]等,以及度量学习相关的损失函数,包括Triplet loss[23],Prototypical loss[21]和Angular Prorotypical loss[22]等。
分类相关的损失函数,由于训练任务只是做分类,所以在测试阶段,对于闭集的数据效果较好,但是由于无法学习到足够的discriminative声纹特征,在面对开集的情况下,往往需要搭配PLDA等后端打分算法才能有较好的性能。相比之下,人脸识别相关的AAM softmatx以及度量学习相关的Triplet loss等学到的声纹特征,要求内类距小类间距大,具有较好的开集泛化性能。
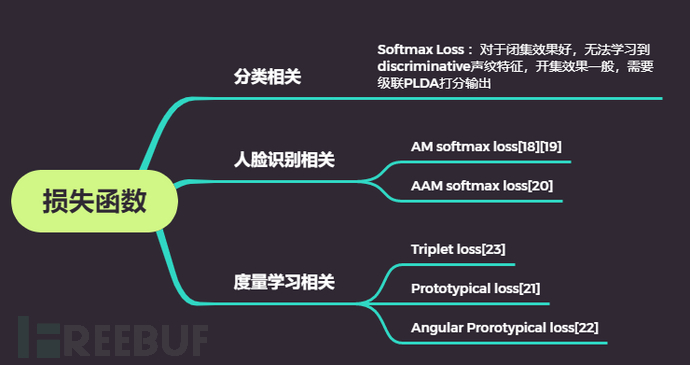 图七 声纹识别中的损失函数
图七 声纹识别中的损失函数
声纹识别在实际应用中遇到的挑战和经验
尽管声纹识别取得了较快的发展,但是对于实际应用场景还是面临了很多的挑战。领域不匹配是常见的问题之一,主要表现为跨信道,跨语种。首先是跨信道问题,由于我们使用的训练数据比较干净,且大部分数据都为安静环境通过麦克风采集,而验证阶段将面对实际业务场景下复杂多变的音频数据,包括强噪声,强背景音乐等。
这让在训练过程中加入“数据增强”和“语音增强”显得必不可少,数据增强不仅仅停留在传统的加噪、加混响等操作,更应该加上实际业务场景中音频数据的类型。其次是跨语种问题,在实际业务中测试数据往往是各个语种都有,这就需要我们采取一些训练技巧,如难例挖掘,或者通过PLDA自适应等解决方案进行优化。在构建声纹识别系统的过程中,我们也总结了一些一般性的经验。
注意力机制的重要性。无论是在模型主干中还是在信息融合阶段中,注意力机制都能提升声纹识别的性能。
在训练数据较大时,相比Softmax Loss,人脸识别相关的loss(例如AAM softmax loss)更具有优势。理论上来讲,AAM softmax loss要求同类之间的声纹特征距离尽可能小,不同类之间的声纹特征距离尽可能大,但这个目标是需要数据量去做支撑的。
度量学习相关的loss表现出更好的召回性能,而人脸识别相关loss更适用于精度优先的场景。但是度量学习相关的loss在训练过程中对batchsize大小的敏感程度较大。
内容安全场景下的声纹识别
声纹识别在内容安全场景下的应用主要为:识别线上语音是否为敏感人员及其相关恶搞语音。我们针对敏感人员声音的特点,以及线上实际遇到的数据情况,从数据、模型、loss选择以及模型训练的技巧,再到整个解决方案等多方面做了多轮的迭代优化,为多家客户采用,并且申请了2项专利。
总结
声纹识别技术的研究贯穿数十年,并搭上深度学习的快车迎来飞跃式发展,成为与“指纹”、“人脸”、“虹膜”并立的重要识别途径,具有广阔的应用场景。本文从数据处理,模型结构,将帧级别特征融合成语句级别特征,以及损失函数的选择这些方面介绍了声纹识别研究领域在近几年取得的进展。在研究领域取得了巨大发展的同时,我们发现在现实场景中,声纹识别系统需要应对的测试数据或者攻击数据往往更加多变,例如低信噪比,远场以及跨语种等复杂场景。这就要求我们继续探索更加鲁棒的算法,包括语音增强,语音合成,语音转换,去混响和域适应等算法来提升声纹识别系统的能力。
参考文献
[1] D. Snyder, G. Chen, D. Povey,”MUSAN: A Music, Speech, and Noise Corpus”,arViv:1510.08484,2015.[2]D. Snyder, D. Garcia-Romero, G. Sell, D. Povey and S. Khudanpur, "X-Vectors: Robust DNN Embeddings for Speaker Recognition," 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5329-5333.[3]Amber Afshan, Jinxi Guo, Soo Jin Park, Vijay Ravi, Alan McCree, Abeer Alwan,"Variable frame rate-based data augmentation to handle speaking-style variability for automatic speaker verification" ,Interspeech 2020,Oct. 2020,pp 4318-4322.[4]Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, et al., “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” in Proc. Interspeech 2019, 2019, pp. 2613–2617.[5]X. Qin, Y. Yang, L. Yang, X. Wang, J. Wang, M. Li”Exploring Voice Conversion based Data Augmentation in Text-Dependent Speaker Verification,” ICASSP 2021.[6]C. Du, B. Han, S. Wang, Y. Qian and K. Yu, "SynAug: Synthesis-Based Data Augmentation for Text-Dependent Speaker Verification," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 5844-5848.[7]H. Huang, X. Xiang, F. Zhao, S. Wang, Y. Qian,”Unit selection synthesis based data augmentation for fixed phrase speaker verification,” ICASSP 2021.[8]K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.[9]B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn:Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” in Proc. Interspeech, 2020.[10]W. Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system,” in Speaker Odyssey, 2018.[11] W. Xie, A. Nagrani, J. Chung, and A. Zisserman, “Utterance-level aggregation for speaker recognition in the wild,” in Proc. ICASSP, 2019.[12] Y., S. Chung, and H. Kang, “Intraclass variation reduction of speaker representation in disentanglement framework,” Proc. Interspeech, 2020.[13]D. Snyder, D. Garcia-Romero, G. Sell, A. McCree, D. Povey, and S. Khudanpur, “Speaker recognition for multi-speaker conversations using x-vectors,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 5796–5800.[14] R. Zhang, J. Wei, W. Lu,”ARET: Aggregated Residual Extended Time-delay Neural Networks for Speaker Verification”. INTERSPEECH 2020.[15] S. Hochreiter, J. Schmidhuber "Long short-term memory". Neural Computation. 9 (8): 1735–1780,1997.[16]W. Cai, J. Chen, and M. Li, “Exploring the encoding layer and loss function in end-to-end speaker and language recognition system,” in Speaker Odyssey, 2018.[17]K.i Okabe, T. Koshinaka, and K. Shinoda, “Attentive statistics pooling for deep speaker embedding,” in Proc. Interspeech, 2018[18] F. Wang, J. Cheng, W. Liu, and H. Liu, “Additive margin softmax for face verification,” IEEE Signal Processing Letters, vol. 25, no. 7, pp. 926–930, 2018.[19] H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, “Cosface: Large margin cosine loss for deep face recognition,” in Proc. CVPR, 2018, pp. 5265–5274.[20] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in Proc. CVPR, 2019, pp. 4690–4699.[21]J. Chung, J. Huh, S. Mun, M. Lee, H. Heo, S. Choe, C. Ham, S.Jung, B. Lee, and I. Han, “In defence of metric learning for speaker recognition,” in Proc. Interspeech, 2020.[22]J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” in NIPS, 2017, pp. 4077–4087.[23]Schroff, F.; Kalenichenko, D.; Philbin, J. (June 2015). FaceNet: A unified embedding for face recognition and clustering. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 815–823.
如有侵权请联系:admin#unsafe.sh