
引言
Log4j2远程代码执行漏洞(CVE-2021-44228)已爆出并发酵了一段时间了,关于如何修复该漏洞各大安全厂商也给出了相应的解决方案,本篇文章着重分析如何在流量层面识别和拦截攻击请求以实现精准检测和防护的目的。
Log4j2语法格式解析
想要实现精准检测首先需要理解log4j的lookup查询方法,即${prefix:name}语法。这是log4j给的一种表达式查询方法,有点类似脚本语言的函数,prefix部分就是“函数名”,name部分就是“函数变量”。lookup方法是支持嵌套使用的,目前已公开的绕过规则主要都是基于lookup方法的嵌套查询去分割关键字从而绕过正则表达式的匹配。我们以${${lower:jnd${lower:i}}:xxx}这个嵌套为例,跟一下${prefix:name}的语法解析流程: 定位pattern.MessagePatternConverter,字符串中发现两个连续的字符"$"和"{"后,会把整个"${XXXX}xxx"作为value传给lookup.StrSubstitutor的replace方法。
定位pattern.MessagePatternConverter,字符串中发现两个连续的字符"$"和"{"后,会把整个"${XXXX}xxx"作为value传给lookup.StrSubstitutor的replace方法。 然后进到substitute方法,这里有几个匹配字符的地方,也是后面我们可以绕过利用的点所在。
然后进到substitute方法,这里有几个匹配字符的地方,也是后面我们可以绕过利用的点所在。
嵌套遍历所有的${prefix:name}格式字符串,交给lookup.Interpolator处理。
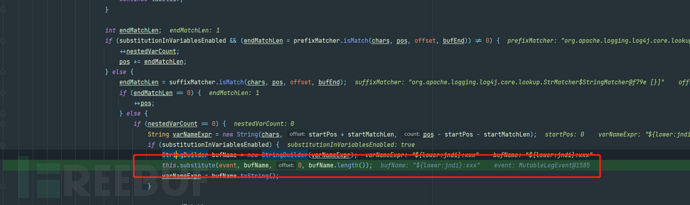 然后在Interpolator的lookup中会找到${prefix:name}格式字符串的prefix和name并对prefix进行全小写转换(由此得知无法通过改变大小写的方式对prefix进行关键字绕过)
然后在Interpolator的lookup中会找到${prefix:name}格式字符串的prefix和name并对prefix进行全小写转换(由此得知无法通过改变大小写的方式对prefix进行关键字绕过)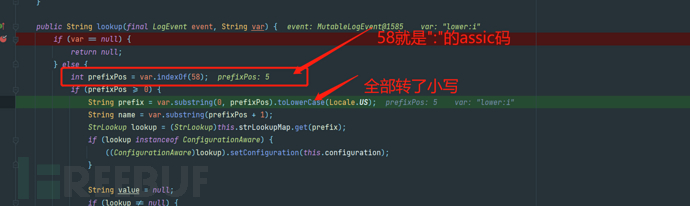 接着把prefix拿来和strLookupMap做比较,找到对应的lookup类。
接着把prefix拿来和strLookupMap做比较,找到对应的lookup类。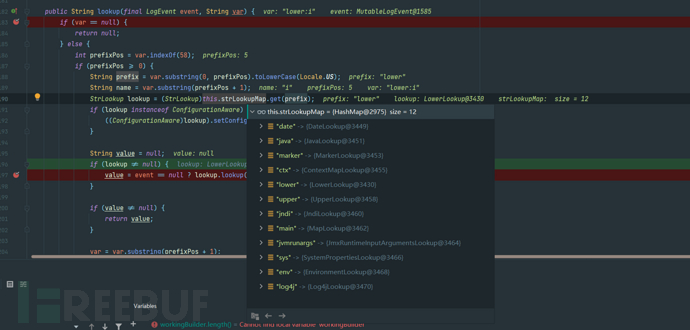 调用如上对应到的类的lookup方法对name做处理。
调用如上对应到的类的lookup方法对name做处理。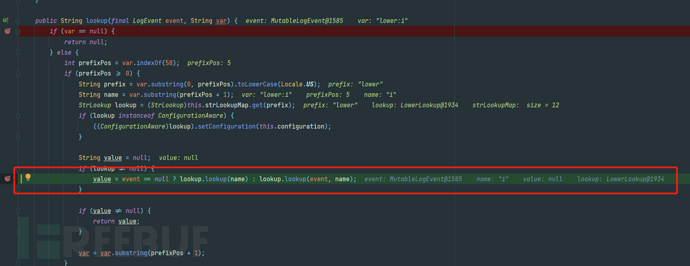 可以看到lower的处理实际上就是toLowerCase了一下
可以看到lower的处理实际上就是toLowerCase了一下 经过一层层的嵌套解析后,解出了我们的目标表达式:
经过一层层的嵌套解析后,解出了我们的目标表达式: 整个调度逻辑没有太大问题,而要做到对该漏洞的全面检测,我们需要知道lookup方法支持对哪些prefix的使用。一是研究除了jndi以外还有哪些方法可以被利用;二是找到除了lower、upper等方法外还有哪些方法是可以去分割payload特征的。
整个调度逻辑没有太大问题,而要做到对该漏洞的全面检测,我们需要知道lookup方法支持对哪些prefix的使用。一是研究除了jndi以外还有哪些方法可以被利用;二是找到除了lower、upper等方法外还有哪些方法是可以去分割payload特征的。
官方手册里对lookup方法中prefix的记录非常零散和混乱,在configuration.html上给出了部分可用方式,大家熟悉的lower等方法并不在里面,反而是多了base64等很有意思的调用方法: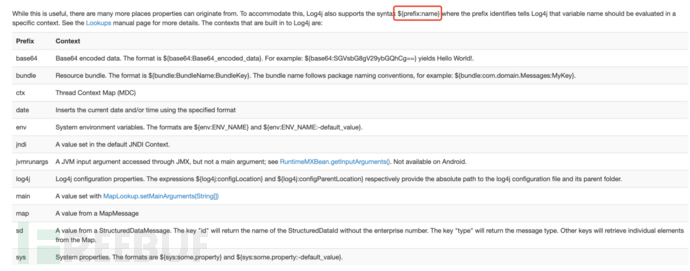 深度检索可以看到一些更多的lookup调用方式,但都没有进行统一的整理:
深度检索可以看到一些更多的lookup调用方式,但都没有进行统一的整理: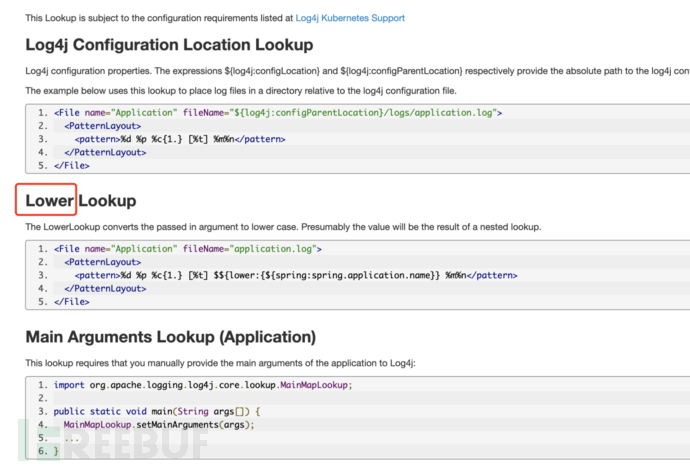 直接从代码层面分析,发现可支持的prefix种类就更少了,下图是2.14.1版本实际支持的prefix方法:
直接从代码层面分析,发现可支持的prefix种类就更少了,下图是2.14.1版本实际支持的prefix方法: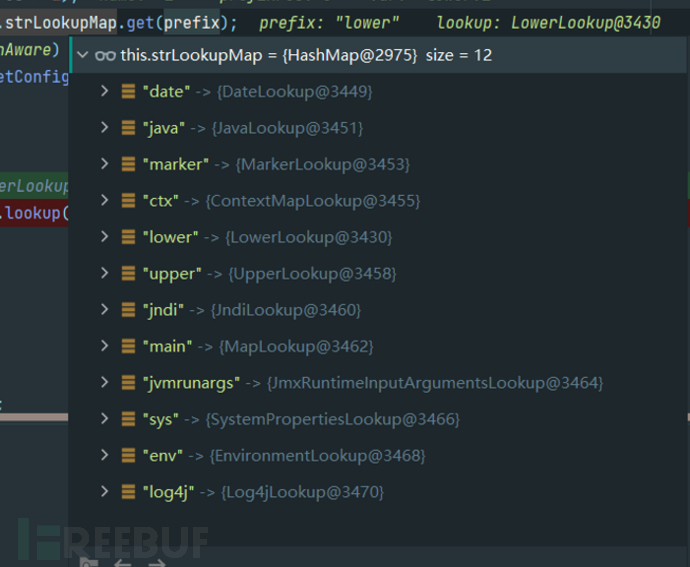 这里并未找到官方文档里所描述的base64调用方法,尝试分析了几个版本都未找到相关定义,实在不清楚手册里描述的功能在实际环境里到底使用了没。
这里并未找到官方文档里所描述的base64调用方法,尝试分析了几个版本都未找到相关定义,实在不清楚手册里描述的功能在实际环境里到底使用了没。
检测特征
回到刚才的两个问题,首先研究除了jndi外还有哪些lookup可以被利用,事实上能实现注入利用的只有jndi,但是其他方法还是会导致一些信息泄漏,如main、env、sys等方法。攻击者可以通过dnslog将敏感信息传出来,下面给出一些敏感信息的lookup案例供参考:
1 ${main:hostName}2 ${env:CLASSPATH}3 ${env:JAVA_HOME}4 ${sys:java.version}5 ${sys:os.name}6 ${sys:os.version}
虽然危害不大,但是作为waf可以考虑进行统一的关键字拦截。
第二个问题是研究哪些lookup方法能够用来分割命令的,首先想到的是拼接空字符的方式来组合。经过测试和分析,当lookup里的prefix去解析错误结构的name值时就会直接返回空字符,如${log4j:123}、${main:123}等,利用这个特性我们期望jnd${log4j:123}i和jndi的输出结果是一致的,但可惜的是log4j并不支持对空字符的拼接。另一个思路是通过关键字索引来替代某个字母,如${sys:os.name}的输出为windows,我们期望能通过输出字母索引的方式(如${sys:os.name}[2:1])来代替字母i,但可惜的是log4j对字符串索引的调用也不支持。
另外就是大家熟知的lower和upper两个lookup方法了,但是经过测试,只有2.13以上的版本支持lower和upper两个lookup方法,实际影响非常有限。针对lower和upper两个lookup,还有一些小技巧供参考。一是进行大小写转换的不一定是字母,后面接字符也不会报错,如${lower::}和:是一个输出,${lower:/}和/也是一个输出;二是某些特殊字符在经过lower或upper后就变成和普通字母一样了,这一点有过ctf经验的小伙伴们应该比较熟悉,例如jndı (这里的 ı(\u0131) 不是小写字母i(\x69)),而是某个特殊字符经过upper后就变成了JNDI了,利用这些特性也可以绕过一些waf规则的预处理和拦截。
那么除了lower和upper外就没有其他切分方式了吗?答案是否定的,上文中提到log4j提供了字符分割符":-",可以理解为此符号会把后边的字符作为纯字符串输入,并且对前面所输内容并无实质要求。 下列表达式均等价于abc:
下列表达式均等价于abc:
1 a${:-b}c2 a${::-b}c3 a${E:-a}c4 a${xxxanycodexxxx:-b}c
这里我们已经可以构造任何字符的插入了,于是就多了更多绕过正则的可能。例如有的waf会对sql注入会做预处理(过滤注释内容),那么就可以用${xxx-- xxx:-b}这类payload实现欺骗和绕过。
:-与lower和upper不同,是全版本覆盖的。利用这个特性很容易就能把snort官方给的bypass规则给bypass了: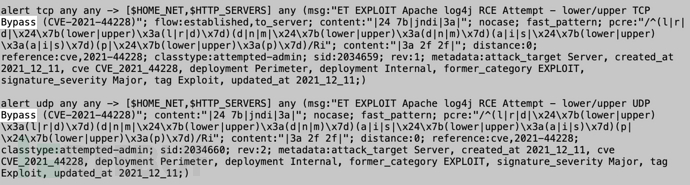 前面提到的都是一些lookup方法里的关键字,我们再来分析哪些jndi注入的协议需要拦截。使用jndi注入的时候对jdk版本有要求,高版本的jdk默认禁止了远程资源加载执行。ldap是我们需要重点检测和防护的对象,rmi其实也能触发漏洞,只是对JDK版本要求更苛刻。但作为waf而言也可以考虑把除ldap以外的其他协议一并拦截以防止探测。
前面提到的都是一些lookup方法里的关键字,我们再来分析哪些jndi注入的协议需要拦截。使用jndi注入的时候对jdk版本有要求,高版本的jdk默认禁止了远程资源加载执行。ldap是我们需要重点检测和防护的对象,rmi其实也能触发漏洞,只是对JDK版本要求更苛刻。但作为waf而言也可以考虑把除ldap以外的其他协议一并拦截以防止探测。
也有小伙伴说整这么多有的没的直接拦截${}不就完事了吗,从实际测试结果来看这种规则非常容易产生误报,特别是在检测上传图片等字节流行为时,因此在写规则时需要做到尽量的宽松和严谨。
关于unicode编码
有分析说通过unicode编码的方式可以对log4j漏洞进行绕过。实际上这并不是log4j漏洞的问题,而是java本身机制的问题。在java里\uxxxx和解码后的字符是可以等价替换的,如\u006fs.name和os.name实质上是一个东西: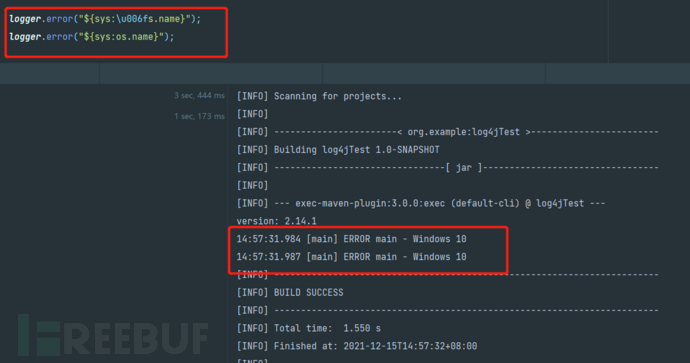 无论是waf还是其他dpi设备,对unicode编码预处理是一项基本工作,否则类似的jndi注入类的漏洞很难有效防范和检测。另外,除了\uxxxx这种格式的unicode预处理外,%uxxxx等格式的编码也需要预处理,如在sqlserver中%uxxxx也和解码后的字符串等价,如果不处理则攻击者可以轻易的构造payload实施sql注入攻击。
无论是waf还是其他dpi设备,对unicode编码预处理是一项基本工作,否则类似的jndi注入类的漏洞很难有效防范和检测。另外,除了\uxxxx这种格式的unicode预处理外,%uxxxx等格式的编码也需要预处理,如在sqlserver中%uxxxx也和解码后的字符串等价,如果不处理则攻击者可以轻易的构造payload实施sql注入攻击。
关于检测点
由于这个漏洞是跟日志输出有关的,因此后端可能接受并打印参数的地方都需要检测和拦截。get、post和cookie肯定是需要重点关注的地方,至于http头里的其他字段并不建议全部监测(当然性能nb的设备当我没说)。可以重点关注useragent、referer以及和ip相关的请求头(X-Forwarded-For、X-Client-Ip、X-Remote-Ip等),这些才是跟后端高交互并可能会记录日志的地方。
文末附一个自研的log4j2漏洞自检工具,有需要的小伙伴可以在本地进行漏洞自检。
下载链接:https://github.com/webraybtl/Log4j
参考链接:
https://logging.apache.org/log4j/2.x/manual/lookups.html
https://logging.apache.org/log4j/2.x/manual/configuration.html
如有侵权请联系:admin#unsafe.sh